微服务学习系列14:分库分表ShardingSphere
系列文章目录
目录
系列文章目录
前言
一、什么是 ShardingSphere
二、ShardingSphere-JDBC独立部署
三、ShardingSphere-Proxy独立部署
四、混合部署架构
五、数据分片
垂直分片
水平分片
六、ShardingSphere 基础知识
表
逻辑表
真实表
编辑
编辑
七、ShardingSphere-JDBC 入门案例
单库多表
多库多表
集成mybatis-plus
引入POM
application.yml 配置
Order 定义
OrderMapper 定义
单元测试
八、ShardingSphere-JDBC 经典案例
十亿用户的系统
表结构怎么设计
十亿用户系统的登录流程
总结
前言
传统的将数据集中存储至单一节点的解决方案,在性能、可用性和运维成本这三方面已经难于满足海量数据的场景。
从性能方面来说,由于关系型数据库大多采用 B+ 树类型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降; 同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。 除此之外,分库还能够用于有效的分散对数据库单点的访问量;分表虽然无法缓解数据库压力,但却能够提供尽量将分布式事务转化为本地事务的可能,一旦涉及到跨库的更新操作,分布式事务往往会使问题变得复杂。 使用多主多从的分片方式,可以有效的避免数据单点,从而提升数据架构的可用性。
一、什么是 ShardingSphere
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
Apache ShardingSphere 设计哲学为 Database Plus,旨在构建异构数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。 它站在数据库的上层视角,关注它们之间的协作多于数据库自身。
https://shardingsphere.apache.org/
二、ShardingSphere-JDBC独立部署
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC;
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。

三、ShardingSphere-Proxy独立部署
ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。 目前提供 MySQL 和 PostgreSQL 协议,透明化数据库操作,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;
- 兼容 MariaDB 等基于 MySQL 协议的数据库,以及 openGauss 等基于 PostgreSQL 协议的数据库;
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端,如:MySQL Command Client, MySQL Workbench, Navicat 等。

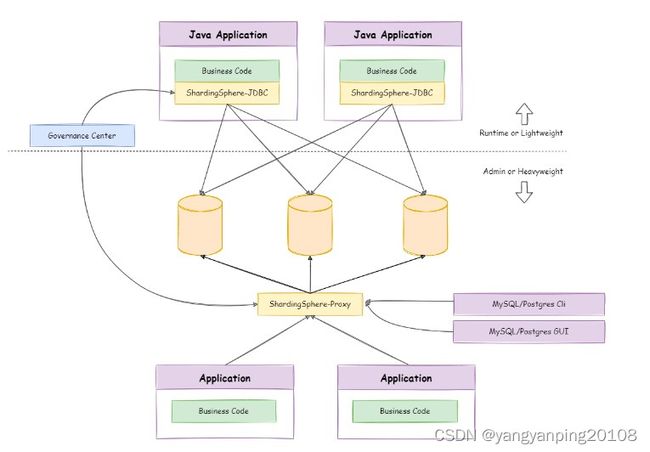
四、混合部署架构
ShardingSphere-JDBC 采用无中心化架构,与应用程序共享资源,适用于 Java 开发的高性能的轻量级 OLTP 应用; ShardingSphere-Proxy 提供静态入口以及异构语言的支持,独立于应用程序部署,适用于 OLAP 应用以及对分片数据库进行管理和运维的场景。
Apache ShardingSphere 是多接入端共同组成的生态圈。 通过混合使用 ShardingSphere-JDBC 和 ShardingSphere-Proxy,并采用同一注册中心统一配置分片策略,能够灵活的搭建适用于各种场景的应用系统,使得架构师更加自由地调整适合于当前业务的最佳系统架构。
五、数据分片
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。 除此之外,分库还能够用于有效的分散对数据库单点的访问量;分表虽然无法缓解数据库压力,但却能够提供尽量将分布式事务转化为本地事务的可能,一旦涉及到跨库的更新操作,分布式事务往往会使问题变得复杂。 使用多主多从的分片方式,可以有效的避免数据单点,从而提升数据架构的可用性。
通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量,是应对高并发和海量数据系统的有效手段。 数据分片的拆分方式又分为垂直分片和水平分片。
垂直分片
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。
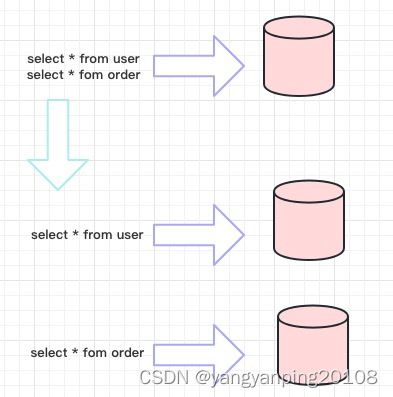
垂直分片往往需要对架构和设计进行调整。通常来讲,是来不及应对互联网业务需求快速变化的;而且,它也并无法真正的解决单点瓶颈。 垂直拆分可以缓解数据量和访问量带来的问题,但无法根治。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。
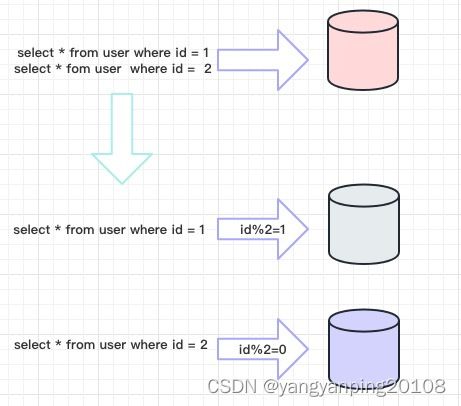
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是数据分片的标准解决方案。
六、ShardingSphere 基础知识
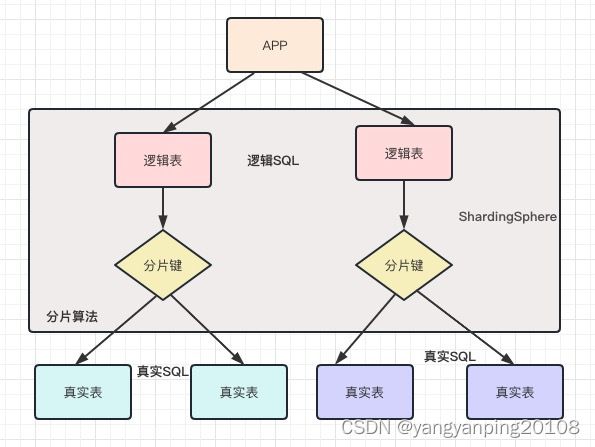
表
表是透明化数据分片的关键概念。 Apache ShardingSphere 通过提供多样化的表类型,适配不同场景下的数据分片需求。
逻辑表
相同结构的水平拆分数据库(表)的逻辑名称,是 SQL 中表的逻辑标识。 例:订单数据根据主键尾数拆分为 3 张表,分别是 t_order_0 ,t_order_2, t_order_3,他们的逻辑表名为 t_order。
真实表
在水平拆分的数据库中真实存在的物理表。 即上个示例中的 t_order_0 ,t_order_2, t_order_3

七、ShardingSphere-JDBC 入门案例
单库多表

数据库设计
数据库:test
订单表:t_order_0,t_order_1,t_order_2
CREATE TABLE `t_order_0` (
`order_id` bigint(200) NOT NULL,
`order_no` varchar(100) DEFAULT NULL,
`create_name` varchar(50) DEFAULT NULL,
`price` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `t_order_1` (
`order_id` bigint(200) NOT NULL,
`order_no` varchar(100) DEFAULT NULL,
`create_name` varchar(50) DEFAULT NULL,
`price` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `t_order_2` (
`order_id` bigint(200) NOT NULL,
`order_no` varchar(100) DEFAULT NULL,
`create_name` varchar(50) DEFAULT NULL,
`price` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;application.yml配置
spring:
main:
allow-bean-definition-overriding: true #当遇到同样名字的时候,是否允许覆盖注册
profiles:
active: sharding-master-slave
server:
port: 8808
mybatis:
mapper-locations: classpath:mapper/*.xml
typeAliasesPackage: org.example.test.entity
configuration:
map-underscore-to-camel-case: trueapplication-sharding-master-slave.yml配置
spring:
shardingsphere:
datasource:
names: m1 #配置库的名字,随意
m1: #配置目前m1库的数据源信息
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/test?useUnicode=true
username: root
password: 123456
sharding:
tables:
t_order: # 指定t_order表的数据分布情况,配置数据节点
actualDataNodes: m1.t_order_$->{0..2}
tableStrategy:
inline: # 指定t_order表的分片策略,分片策略包括分片键和分片算法
shardingColumn: order_id
algorithmExpression: t_order_$->{order_id % 3}
keyGenerator: # 指定t_order表的主键生成策略为SNOWFLAKE
type: SNOWFLAKE #主键生成策略为SNOWFLAKE
column: order_id #指定主键
props:
sql:
show: trueOrder实体类代码如下
@Data
public class Order {
private Long orderId;
private String orderNo;
private String createName;
private BigDecimal price;
}
OrderMapper
@Mapper
public interface OrderMapper {
/**
* 新增数据
*/
int insert(Order order);
Order queryById(Long orderId);
}
insert into t_order(order_no,create_name, price)
values (#{orderNo},#{createName},#{price})
OrderTest 单元测试
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest(classes = ExampleWeb.class)
public class OrderTest {
@Resource
private OrderMapper orderMapper;
@Test
public void insert() {
for (int i = 1; i <= 30; i++) {
Order order = new Order();
order.setOrderNo(i + "");
order.setCreateName("test" + i);
order.setPrice(BigDecimal.valueOf(i));
orderMapper.insert(order);
System.out.println(JSON.toJSONString(order));
}
}
}多库多表

application-sharding.yml 配置信息
spring:
shardingsphere:
datasource:
names: ds0,ds1 #配置库的名字,随意
ds0: #配置目前m1库的数据源信息
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds_0?useUnicode=true
username: root
password: 123456
ds1: #配置目前m1库的数据源信息
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds_1?useUnicode=true
username: root
password: 123456
sharding:
tables:
t_order: # 指定t_order表的数据分布情况,配置数据节点
actualDataNodes: ds$->{0..1}.t_order_$->{0..3}
database-strategy:
inline: # 指定t_order表的分片策略,分片策略包括分片键和分片算法
shardingColumn: order_no
algorithmExpression: ds$->{order_no % 2}
tableStrategy:
inline: # 指定t_order表的分片策略,分片策略包括分片键和分片算法
shardingColumn: order_no
algorithmExpression: t_order_$->{order_no % 4}
keyGenerator: # 指定t_order表的主键生成策略为SNOWFLAKE
type: SNOWFLAKE #主键生成策略为SNOWFLAKE
column: order_id #指定主键
props:
sql:
show: true集成mybatis-plus
引入POM
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.3.4.RELEASE
org.example
sharding
1.0-SNAPSHOT
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-configuration-processor
mysql
mysql-connector-java
runtime
org.projectlombok
lombok
true
com.alibaba
druid
1.2.1
mysql
mysql-connector-java
5.1.44
com.github.pagehelper
pagehelper
5.2.0
org.apache.commons
commons-lang3
3.11
com.baomidou
mybatis-plus-boot-starter
3.4.3.3
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
4.1.0
org.springframework.boot
spring-boot-starter-test
2.7.9
junit
junit
4.13.1
test
com.alibaba
fastjson
2.0.14
application.yml 配置
spring:
shardingsphere:
datasource:
names: ds0,ds1 #配置库的名字,随意
ds0: #配置目前m1库的数据源信息
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds_0?useUnicode=true
username: root
password: 123456
ds1: #配置目前m1库的数据源信息
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds_1?useUnicode=true
username: root
password: 123456
sharding:
tables:
myOrder: # 指定t_order表的数据分布情况,配置数据节点
actualDataNodes: ds$->{0..1}.t_order_$->{0..3}
database-strategy:
inline: # 指定t_order表的分片策略,分片策略包括分片键和分片算法
shardingColumn: order_id
algorithmExpression: ds$->{order_id % 2}
tableStrategy:
inline: # 指定t_order表的分片策略,分片策略包括分片键和分片算法
shardingColumn: order_id
algorithmExpression: t_order_$->{order_id % 4}
keyGenerator: # 指定t_order表的主键生成策略为SNOWFLAKE
type: SNOWFLAKE #主键生成策略为SNOWFLAKE
column: order_id #指定主键
props:
sql:
show: true
server:
port: 8808Order 定义
@Data
@TableName("myOrder")
public class Order {
@TableId(type = IdType.ASSIGN_ID)
private Long orderId;
private Integer orderNo;
private String createName;
private BigDecimal price;
}OrderMapper 定义
public interface OrderMapper extends BaseMapper {
} 单元测试
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest(classes = ExampleWeb.class)
public class OrderTest {
@Resource
private OrderMapper orderMapper;
@Test
public void insert() throws Exception {
ExecutorService executorService = Executors.newFixedThreadPool(30);
for (int i = 1; i <= 30; i++) {
executorService.execute(() -> {
Order order = new Order();
order.setOrderNo(111);
order.setCreateName("test" );
order.setPrice(BigDecimal.valueOf(1));
orderMapper.insert(order);
System.out.println(String.format(">>>>>>>>>>>>>>>>>>>>>>>>>>%s,%s", order.getOrderId(), order.getOrderId() % 4));
});
}
Thread.sleep(10000);
}
}八、ShardingSphere-JDBC 经典案例
十亿用户的系统
十亿用户的系统,用户有多种登录方式,可以使用手机号、账号、邮箱、昵称等登录,这样的表结构应该怎样设计?登录流程大致是怎样的?
表结构怎么设计
当出现多种登录方式的时候,就意味着一个用户对应的账号可能会有若干个。现在可能用手机和昵称登录,以后就可能用邮箱登录,甚至将来还可能通过微信、QQ、微博等第三方渠道登录。
我们最先想到的是每增加一种登录方式就新增一个字端,
| 字段 | 字段描述 |
| id | Long |
| name | 登录名 |
| mobile | 手机号码 |
| 电子邮箱 |
但这样会产生以下问题:
-
当用户登录的时候,我们需要根据用户的登录类型,先要知道去查找用户表的哪个字段才可以进行登录逻辑判断。例如,用户登录用手机号了,我们就要知道去表里查找对应的 mobile 字段去校验登录;登录用邮箱了,我们就要知道去表里查找对应的 email 字段才可以。这样做,代码逻辑会很复杂。
-
再增加一种登录方式的时候,我们还得给数据库的表里再增加一个字段,同时还得修改登录的代码。这显然违反了我们设计模式中的开闭原则。而且这种修改很容易造成线上 bug。每增加一种登录方式,就新增一种流程,成本有点过高了。
我们设计的表,必须易扩展
加记录比加字段要更容易扩展
因此方案如下:
创建一张用户登录 user_login表,专门用来处理登录。当新增登录类型的时候,只需要考虑增加一条记录即可:记录登录类型、登录名称以及相关密码,同时有个 user_id 字段,去和用户表做关联。
| 字段名称 | 字段描述 |
| id | Long |
| name | 用户名 |
| type | 1:登录名 2:手机号码 3:邮箱 |
| password | 密码(多个用户名可共用一个密码,也可以存储token) |
| user_id | 用户表ID |
用户表user存储基础信息
| 字段名称 | 字段描述 |
| id | 用户ID主键 |
| nick_name | 用户昵称 |
| user_logo | 用户头像 |
| user_names | 存储和user_id关联的账号 |
这样设计后,很明显就做到了易扩展。
假如我自己有两种登录方式,user_login 表的数据:
| id | name | type | password | user_id |
| 1 | xiyangyang | 1 | 123456 | 1 |
| 2 | [email protected] | 3 | 123456 | 1 |
用户表(User)的数据:
| id | nick_name | user_logo | user_names |
| 1 | 喜 | xiyangyang,[email protected] |
十亿用户系统的登录流程
因为十亿用户,哪怕有百分之一的活跃用户,也是千万级别的。所以,在这样的情况下,必然需要考虑分库分表。分库是为了应对高并发,分表则是为了应对大数据。
以 MYSQL 为例, 一般来讲,在 4 核CPU/8G 内存/RAID10 的普通硬盘的服务器配置下,一台 MYSQL 库能一直可靠运行的可承载压力是 1000TPS 左右。一张通常的 20 个字段以内的表,能保证查询性能没有大的下降的话,可承载的数据量大致是 1000 万条数据左右。
所以,咱们分表的时候就要尽量控制表数据不超过一千万条数据。也因此,十亿用户,分表就是分 100 张表。
同时呢,咱们说了,一台库大概能承载的可靠运行并发数是 1000TPS 左右。分库一般来说,100 张表分 10 个库,每个库 10 张表,就很绰绰有余了。
好,现在问题来了,分库分表的策略是什么呢?就是按什么分呢?
一般是按照 user_id 分。假如我们要分 10 个库 100 张表是吧, 一般来说就是先通过 user_id mod 10去定义好库,再通过 user_id mod 100 定义好表。
比如 user_id mod 10 = 3,user_id mod 100 = 33,那么这个用户的数据就被定位到了数据库 3 中的 33 号表。
注意,这里又来了一个问题。
假设一个 user_id = 100 会怎么样?user_id mod 10 = 0,user_id mod 100 = 0。它会被分在 0 号库,0 号表。
那如果我想分到 1 号库,0 号表呢,有对应的 user_id 吗?是没有的。为什么呢?
因为当一个 user_id mod 100 = 0 时,这个 user_id mod 10 也一定为 0 。所以,不会存在 1 号库,0 号表的情况。
所以,我们还需要对库进行调整,要把库变成 11 个库,然后呢,每个库有 10 张表。原因就是:
库数和表数之间不能存在公约数,也就是他们需要互质,只有这样,我们分配数据的时候,才会尽量均匀。
好了,当 user_id 分完之后,你会发现,按照咱们的设计,只能解决 User 表的问题。那登录在哪里?该怎么办?
咱们继续看,前面说了,登录逻辑是靠 user_login 表来验证。那 user_login 表数据大,也得分库分表啊?它怎么分?
其实挺简单,分库分表的时候,我们根据 user_login 表的 name 的 Hash 去分。
假设有个用户的 name 是 abc,然后将这个 abc 进行下 hash,再除以库的数量。现在是 11 个库,所以就是 hash(abc) mod 11 这样得到库的编号,然后再 hash(abc) mod 100 得到表的编号。
于是,当我们登录的时候,流程如下:
-
输入 abc 和密码;
-
验证出账号类型;
-
将信息传递给服务器;
-
服务器在数据库层之上会有一个路由层,根据 hash(abc) mod 11/100 定位数据库和表;
-
查询 user_login 表验证。
实际上,很多这种高并发、大数据的登录,我们根据手头的资源,虽然依然会使用分库分表,但是,往往还会采用 ElasticSearch 缓存一些用户基本信息和用户数据所在的数据库和表的地址信息,将他们作为索引,去真正的做相关登录业务行为。并根据用户字段的使用热度,会在登录时,把一些用户关键字段读取出来,放到外置的 Redis 缓存中,供以后重用。
这样做的好处就是,分库分表我们可以根据资源随意增加减少,只需要到时候修改下 ElasticSearch 中的索引信息即可。同时,有了 Redis,也能减少后面分库分表资源的消耗。
总结
参考:
数据分片 :: ShardingSphere
登录 - Gitee.com
十亿用户的系统!
分库分表经典15连问_摩杜云论坛
高并发系统设计:MySQL存储海量数据的最后一招---分库分表_mysql海量数据存储_OceanStar的学习笔记的博客-CSDN博客