PostgreSQL基础语法
截取字符串
select id,split_part(standard_name,'《',1) ,'《' || split_part(standard_name,'《',2)as standard_name,standard_name,mandatory_clause from t_standard_outcome limit 1;
结果
![]()
聚合,正则去掉开头不是1-9数字的数据
select * from (select string_agg(cell_text,'^') as table_vaule,cell_line_no from prop_cad_table where fileid = 'attach-45772983-ecdb-4fa6-a011-ff0ca6671030-1' and table_no = '23' group by cell_line_no order by cell_line_no asc) a where a.table_vaule ~ '^[1-9]'
如果是null返回0
COALESCE(t1.count,0)
替换字符串
select replace(字段名,'替换前的内容','替换后的内容') from 表名 where 字段名 like '%替换前的内容%';
update 表名 set 字段名=replace(字段名,'替换前的内容','替换后的内容') where 字段名 like '%替换前的内容%';
关联两张表查询
SELECT * FROM res_quota
inner join 入库1
on res_quota.code=入库1.定额编号
where res_quota.status='0';
关联两张表更新
update res_quota_condition a
set remark ='0'
from res_quota b
where a.quota_id=b.id and b.status='0'
关联两张表插入
insert into res_quota_condition(id,quota_id,attr_name,attr_label,quota_value,predication)
select id2,quota_id,attr_name,attr_label,quota_value,predication
from 入库2
关联两张表删除
delete from res_quota_condition a
using res_quota b
where a.quota_id = b.id
and b.quota_type='2' and b.res_type='54'
去重
select code from res_quota group by code having count(code)>1
select count(uid),uid from "新会区2"group by uid having count(uid)>1
select distinct uid from "新会区2"
获取前几条数据
select id , date_id , name
from
(select * , row_number() over(partition by date_id order by id ) as row_id from dddd ) as t
where t.row_id <= 2 ;
获取最大id
select coalesce(cast(max(id) as integer),0) from nc_sales_flow_chart
获取最大号
select coalesce(cast(substr(max(salesorderoumber),9)as integer),0)
from nc_sales_flow_chart
where to_char(now(), 'yyyyMMdd') = substr(salesorderoumber,0,9);
比较时间
select count(1) from nc_basic_information
where to_timestamp(time,'YYYY-MM-DD HH24:MI:SS') > '2021-5-1 00:00:00'
截取当前月份
SELECT date_part('month',now())
字段转换为数值
cast(字段1 as numeric)
postgresql锁表
select oid from pg_class where relname='bearing_segs_4pgr_vertices_pgr';
select pid from pg_locks where relation='1461942';
select pg_cancel_backend(11631)
对时间进行加减运算:
SELECT now()::timestamp + '1 year'; --当前时间加1年
SELECT now()::timestamp + '1 month'; --当前时间加一个月
SELECT now()::timestamp + '1 day'; --当前时间加一天
SELECT now()::timestamp + '1 hour'; --当前时间加一个小时
SELECT now()::timestamp + '1 min'; --当前时间加一分钟
SELECT now()::timestamp + '1 sec'; --加一秒钟
select now()::timestamp + '1 year 1 month 1 day 1 hour 1 min 1 sec'; --加1年1月1天1时1分1秒
SELECT now()::timestamp + (col || ' day')::interval FROM table --把col字段转换成天 然后相加
忽略所有字符串中非数字字符
SELECT to_number(' ab ,1,2a3,4b5', '9999999999999999999')//12345
创建视图
drop VIEW COMPANY_VIEW;
CREATE VIEW basic_personnel_information AS
SELECT a.*,substr(in_no,7,4) || '-' || substr(in_no,11,2) || '-' || substr(in_no,13,2) as date_of_birth
FROM nc_worker_archives a;
-- 创建视图
CREATE VIEW "public"."v_user_tab"
AS
select * from pg_class where relnamespace != '11' and relnamespace != '13887' and relkind = 'r';
select * from v_user_tab;
-- 删除视图
drop view v_user_tab;
-- 创建物化视图
CREATE MATERIALIZED VIEW "public"."mv_user_tab"
AS
select * from pg_class where relnamespace != '11' and relnamespace != '13887' and relkind = 'r';
-- 创建唯一索引
create unique index idx_mv_user_tab_oid on mv_user_tab using btree (oid);
--刷新物化视图
refresh materialized view mv_user_tab;
-- 删除物化视图
drop materialized view mv_user_tab;
创建索引
--单列索引
CREATE INDEX index_name ON table_name (column_name);
--多列索引
CREATE INDEX index_name ON table_name (column1_name, column2_name);
--唯一索引(不允许重复的值插入)
CREATE UNIQUE INDEX index_name on table_name (column_name);
--查看某张表的所有索引
select * from pg_indexes where tablename='t_fg_cm_topo_point';
select * from pg_statio_all_indexes where relname='t_fg_cm_topo_point';
--重置索引
REINDEX INDEX index_name;//重置单个索引
REINDEX TABLE table_name;//重置整个表的索引
REINDEX DATABASE db_name;//终⽌整个数据库的索引
物化视图
1、普通视图
--数据库中的视图(view)是从一张或多张数据库表查询导出的虚拟表,反映基础表中数据的变化,且本身不存储数据。
2、物化视图【materialized view】
--概念: 物化视图是查询结果集的一份持久化存储,所以它与普通视图完全不同,而非常趋近于表。 可以是基础表中部分数据的一份简单拷贝,也可以是多表join之后产生的结果或其子集,或者原始数据的聚合指标等等。所以,物化视图不会随着基础表的变化而变化,所以它也称为快照(snapshot)。
--如果要更新数据的话,需要用户手动进行,如周期性执行SQL,或利用触发器等机制。
--产生物化视图的过程就叫做“物化”(materialization)。广义地讲,物化视图是数据库中的预计算逻辑+显式缓存,典型的空间换时间思路。
--所以用得好的话,它可以避免对基础表的频繁查询并复用结果,从而显著提升查询的性能。它当然也可以利用一些表的特性,如索引。
3、--刷新物化视图:refresh
refresh materialized view mv_t;
4、--删除物化视图:drop
drop materialized view mv_t;
Postgresql中删除大量数据优化表空间
步骤一
-- 禁用触发器
ALTER TABLE 表名 DISABLE TRIGGER ALL;
--删除表记录
delete from 表名 where id in(select id from ha_movhis_temp);
--启用触发器
ALTER TABLE 表名 ENABLE TRIGGER ALL;
步骤二
--查看表空间大小
select pg_size_pretty(pg_relation_size('表名'));
-- 优化表空间
-- 维护数据库磁盘,释放空间
vacuum FULL 表名;
步骤三
-- 重建索引,替换查询效率
REINDEX TABLE 表名;
其他
--查看数据库大小,不计算索引
select pg_size_pretty(pg_database_size('mydb'));
--查看数据库大小,包含索引
select pg_size_pretty(pg_total_size('mydb'));
--查看表中索引大小
select pg_size_pretty(pg_indexes_size('test_1'));
--查看表大小,不包括索引
select pg_size_pretty(pg_relation_size('test_1'));
--查看表大小,包括索引
select pg_size_pretty(pg_total_relation_size('test_1'));
--查看某个模式大小,包括索引。不包括索引可用pg_relation_size
select schemaname,round(sum(pg_total_relation_size(schemaname||'.'||tablename))/1024/1024) "Mb" from pg_tables where schemaname='mysch' group by 1;
--查看表空间大小
select pg_size_pretty(pg_tablespace_size('pg_global'));
--查看表对应的数据文件
select pg_relation_filepath('test_1');
--切换log日志文件到下一个
select pg_rotate_logfile();
--切换日志
select pg_switch_xlog();
checkpoint
创建uuid自动生成
1.创建uuid
create extension "uuid-ossp"
2.设置字段默认 uuid_generate_v4()

– 设置id自增
CREATE SEQUENCE gx_t_joint_box_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
alter table gx_t_joint_box alter gid set default nextval(‘gx_t_joint_box_id_seq’);
-- 当前日期减去一天
to_char(CURRENT_DATE - INTERVAL'1 day','yyyy-mm-dd')
-- 当前时间
now()
去掉非法字符
UPDATE table set name = trim(name);//用来删除数据前后的空格
UPDATE table set name = rtrim(name);//用来删除数据前的空格
UPDATE table set name = ltrim(name);//用来删除数据后的空格
UPDATE table set name = REPLACE(name," ","");//用来删除数据中的空格
UPDATE table set name =REPLACE(name, CHR(10), "") //替换换行符
UPDATE table set name =REPLACE(name, CHR(13), "") //替换回车符
bigint类型字段 = int8等等

pg库其他函数介绍:https://blog.csdn.net/weixin_41191813/article/details/118522836
– hash index
CREATE INDEX g_aoi_rk_geom ON g_aoi_rk_20230411 USING hash(geom);
删除数据库时,pgsql有用户正在连接,无法删除用的的情况
SELECT pg_terminate_backend(pg_stat_activity.pid) FROM pg_stat_activity WHERE datname=‘test’ AND pid<>pg_backend_pid();
–查看数据库版本
select version();
– 更新字段名
alter table “25d5” rename “Position Id” to position_id;
– 增加geom字段
ALTER TABLE “transmitter” ADD COLUMN “geom” “public”.“geometry”;
– geometry转geojson
SELECT ST_AsGeoJSON ( geom ) FROM warning_products LIMIT 1
– xy坐标转geometry
update “byc” set geom = ST_SetSRID(ST_Point(replace(x,‘E’,‘’)::float8,replace(y,‘N’,‘’)::float8),4326)
– wkt转geometry
update rsrp set geom =ST_GeomFromText(wkt,4326)
– ①wkt转geometry
update pv_building_20230313 set geom =st_geomfromtext(wkt,4326)
– ②先获取多边形中心点坐标
update pv_building_20230313 set centroid_geom =st_centroid(geom)
– ③然后geom 转经纬度
update pv_building_20230313 set longitude=st_x(centroid_geom)
update pv_building_20230313 set latitude=st_y(centroid_geom)
–计算wkt多边形面积
select st_area(st_transform(st_geometryfromtext(wkt,4326),4527)),area from “pv_building_20230313” limit 50
ALTER TABLE “cy_标准地址已处理_火星_7级” ADD COLUMN “geom100m” “public”.“geometry”;
ALTER TABLE “cy1_标准地址已处理_火星_8级” ADD COLUMN “geom100m” “public”.“geometry”;
select count(1) from cy1_标准地址已处理_火星_8级 where geom10m is not null
select * from cy1_标准地址已处理_火星_8级 where latitude > longitude
select * from cy1_标准地址已处理_火星_8级 where joinid=‘11474666’
– a的geom扩散5m
update cy1_标准地址已处理_火星_8级 set geom100m = st_transform(st_buffer(st_transform(原始geom,3857),100),4326) where (classify is null or classify=‘’) and joinid<>‘11474666’
–创建索引
CREATE INDEX index_name_100m_8j ON cy1_标准地址已处理_火星_8级 (geom100m);
– 查询出来a包含b的
select count(b.classify),b.classify,a.joinid into 处理八级地址100m from cy1_标准地址已处理_火星_8级 a
, g_admin_addr b
where st_intersects(a.geom100m,b.geom)=‘t’
and (a.classify is null or a.classify=‘’) and (b.classify is not null and b.classify<>‘’)
group by b.classify,a.joinid
– 删除次数不是最多的数据
delete from 处理八级地址100m a where a.count<> (select max(count) from 处理八级地址100m b where a.joinid=b.joinid)
– 更新数据
update cy1_标准地址已处理_火星_8级 a set classify =b.classify from 处理八级地址100m b where a.joinid =b.joinid and (a.classify is null or a.classify=‘’)
–查询数据库表中字段及类型 (这种方式没有字段备注信息)
SELECT table_catalog,table_schema,column_name,ordinal_position,is_nullable,data_type,character_maximum_length,numeric_precision,udt_name
FROM information_schema.columns As c
WHERE table_name = '表名'
– with用法
(1)生成1-5序列
with t as
(select generate_series(1, 5))
select * from t;
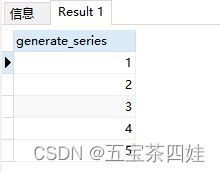
(2)计算
with T as(
select 1234 ::numeric A, 10 ::numeric R)
select R/100 as expr1 from T
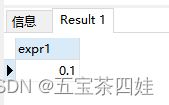
–正则使用
select * from 表名 where 字段名 ~‘[\u2e80-\ua4cf]|[\uf900-\ufaff]|[\ufe30-\ufe4f]|[^A-Z]|[^a-z]|[^0-9]|[^a-z0-9A-Z]’
注释:
[^a-z0-9A-Z]: a-z:小写字母、0-9数字、A-Z大写字母 ^ 表示从开头开始匹配,\表示原义匹配
[^A-Z]:表示匹配大写字母
[^a-z]:表示匹配小写字母
[^0-9]:表示匹配数字
[\u2e80-\ua4cf]|[\uf900-\ufaff]|[\ufe30-\ufe4f]:表示匹配当前字段内容中的特殊符号,如:
