day10 【迭代器 数据结构】上课
1.Iterator迭代器(掌握)
介绍
1.Iterator是一个接口,属于java.util包下,需要导包
2.属于jdk1.2开始有的,之前使用迭代器Enumeration
3.Iterator在java中我们称为该接口是迭代器接口,专门用来迭代集合的
4.迭代:从容器(集合)中一个一个获取数据,获取数据之前先判断有没有数据,如果有数据,则获取,如果没有数据则不获取,这就是迭代的思想。
使用Iterator迭代器
1.获取迭代器接口Iterator的对象
使用集合Collection中的方法:
Iterator<E> iterator() 返回在此 collection 的元素上进行迭代的迭代器。
说明:使用集合类的对象调用上述方法就可以获取迭代器对象了。
2.Iterator迭代器中的方法
| 方法 | 说明 |
|---|---|
| E next() | 获取集合中的元素 |
| boolean hasNext() | 判断集合中有没有下一个元素,如果仍有元素可以迭代,则返回 true。 |
| void remove() | 删除当前元素 |
-
代码演示没有这个元素异常
package com.itheima.sh.iterator_01; import java.util.ArrayList; import java.util.Collection; import java.util.Iterator; /* Iterator迭代器的使用讲解: 1.获取迭代器对象:Iteratoriterator() 返回在此 collection 的元素上进行迭代的迭代器。 2.Iterator方法: E next()获取集合中的元素 boolean hasNext()判断集合中有没有下一个元素,如果仍有元素可以迭代,则返回 true。 */ public class IteratorDemo01 { public static void main(String[] args) { //1.创建集合对象 Collection<String> coll = new ArrayList<>(); //2.向集合中添加数据 coll.add("柳岩"); coll.add("马蓉"); coll.add("杨幂"); coll.add("范冰冰"); //3.根据集合对象调用方法获取迭代器对象 Iterator<String> it = coll.iterator(); //4.获取数据并输出 String s1 = it.next();//柳岩 System.out.println("s1 = " + s1); System.out.println(it.next());//马蓉 System.out.println(it.next());//杨幂 System.out.println(it.next());//范冰冰 System.out.println(it.next()); } }

-
避免产生没有这个元素异常
package com.itheima.sh.iterator_01; import java.util.ArrayList; import java.util.Collection; import java.util.Iterator; /* Iterator迭代器的使用讲解: 1.获取迭代器对象:Iteratoriterator() 返回在此 collection 的元素上进行迭代的迭代器。 2.Iterator方法: E next()获取集合中的元素 boolean hasNext()判断集合中有没有下一个元素,如果仍有元素可以迭代,则返回 true。 */ public class IteratorDemo01 { public static void main(String[] args) { //1.创建集合对象 Collection<String> coll = new ArrayList<>(); //2.向集合中添加数据 coll.add("柳岩"); coll.add("马蓉"); coll.add("杨幂"); coll.add("范冰冰"); //3.根据集合对象调用方法获取迭代器对象 Iterator<String> it = coll.iterator(); //4.获取数据并输出 //判断 /* if(it.hasNext()){//it.hasNext()判断集合中有没有下个元素 表示条件 String s1 = it.next();//柳岩 System.out.println("s1 = " + s1); } System.out.println(it.next());//马蓉 System.out.println(it.next());//杨幂 System.out.println(it.next());//范冰冰 System.out.println(it.next());*/ /* 为了避免没有这个元素异常,我们在调用next()方法之前先判断有没有元素,如果有在获取。这样就可以避免上述异常 并且上述代码如果使用if判断,那么会比较重复,所以我们这里使用循环来实现 */ while(it.hasNext()){//it.hasNext()表示循环条件 如果有下一个元素,则hasNext()方法返回true,没有返回false //获取数据 String s = it.next(); //输出 System.out.println("s = " + s); } System.out.println("coll = " + coll); } }小结:
我们在调用next()方法之前,必须先调用hasNext()方法,判断有没有下一个元素,防止报没有这个元素异常。代码比较重复,我们建议使用循环替代。
3.迭代器原理
package com.itheima.sh.iterator_01;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/*
Iterator迭代器的使用讲解:
1.获取迭代器对象:Iterator iterator() 返回在此 collection 的元素上进行迭代的迭代器。
2.Iterator方法:
E next()获取集合中的元素
boolean hasNext()判断集合中有没有下一个元素,如果仍有元素可以迭代,则返回 true。
*/
public class IteratorDemo02 {
public static void main(String[] args) {
//1.创建集合对象
Collection<String> coll = new ArrayList<>();
//2.向集合中添加数据
coll.add("柳岩");
coll.add("马蓉");
coll.add("杨幂");
//3.获取迭代器对象
Iterator<String> it = coll.iterator();
//4.使用循环迭代集合 itit回车自动生成while循环
while (it.hasNext()) {
String s = it.next();
System.out.println("s = " + s);
}
}
}

小结:
1.游标即指针最开始在0索引位置,每次获取数据不是根据游标,是根据变量i获取的
4.迭代器的问题:并发修改异常
我们使用迭代器迭代集合的时候,如果对集合长度修改(添加数据,删除数据),不要使用集合中的方法修改,如果修改就会引发并发修改异常。
代码演示:
package com.itheima.sh.iterator_01;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/*
并发修改异常:
我们使用迭代器迭代集合的时候,如果对集合**长度**修改(添加数据,删除数据),
不要使用集合中的方法修改,如果修改就会引发并发修改异常。
*/
public class IteratorDemo03 {
public static void main(String[] args) {
//1.创建集合对象
Collection<String> coll = new ArrayList<>();
//2.添加数据
coll.add("aaa");
coll.add("bbb");
coll.add("ccc");
coll.add("ddd");
//3.迭代集合
Iterator<String> it = coll.iterator();
while (it.hasNext()) {
String s = it.next();
//需求:如果取出的数据s是bbb那么就删除
//判断s是否等于bbb
if("bbb".equals(s)){
//删除s 使用集合中的删除方法
/*
这使用集合对象调用集合中的删除方法那么就会报并发修改异常:
ConcurrentModificationException
*/
// coll.remove(s);
/*
我们可以使用Iterator迭代器中的删除方法:void remove()
*/
it.remove();
}
}
//打印集合coll
System.out.println("coll = " + coll);
}
}
小结:
1.如果使用迭代器迭代集合的时候,想删除集合中的某个数据,千万不要使用集合中的删除方法,否则就会报并发修改异常ConcurrentModificationException
2.解决上述方案:使用迭代器Iterator接口中的删除方法:void remove()即可 就不会报并发修改异常了
5.迭代器的问题:并发修改异常产生的原因和解决办法的原因的原理(扩展,有时间看)
package com.itheima.sh.iterator_01;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/*
并发修改异常:
我们使用迭代器迭代集合的时候,如果对集合**长度**修改(添加数据,删除数据),
不要使用集合中的方法修改,如果修改就会引发并发修改异常。
*/
public class IteratorDemo04 {
public static void main(String[] args) {
//1.创建集合对象
Collection<String> coll = new ArrayList<>();
//2.添加数据
coll.add("aaa");
coll.add("bbb");
coll.add("ccc");
coll.add("ddd");
//3.迭代集合
Iterator<String> it = coll.iterator();
while (it.hasNext()) {
String s = it.next();
//需求:如果取出的数据s是bbb那么就删除
//判断s是否等于bbb
if("bbb".equals(s)){
//删除s 使用集合中的删除方法
/*
这使用集合对象调用集合中的删除方法那么就会报并发修改异常:
ConcurrentModificationException
*/
// coll.remove(s);
/*
我们可以使用Iterator迭代器中的删除方法:void remove()
*/
it.remove();
}
}
//打印集合coll
System.out.println("coll = " + coll);
}
}
源码:
public class ArrayList
{
//获取迭代器的方法
public Iterator<E> iterator() {
//创建迭代器类的对象
return new Itr();
}
//成员内部类
private class Itr implements Iterator<E> {
//内部类的成员位置
//游标 成员变量 默认值是0
//在创建Itr类的对象时初始化值的
//return new Itr();
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
//modCount :表示集合长度的修改次数 每次修改集合该变量都会+1
//expectedModCount 表示期望集合修改的次数
//将集合被修改的次数赋值给期望 变量expectedModCount
int expectedModCount = modCount;
//成员方法
public boolean hasNext() {
//cursor初始化值是0 表示游标即指针
//size表示集合中的元素个数,这里想集合添加几个元素,size就是几
//如果添加三个元素,那么size是3
return cursor != size;
}
//获取集合中的数据方法
public E next() {
//检测是否有并发修改异常的
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
//检测是否有并发修改异常的
final void checkForComodification() {
//如果使用集合中的删除方法,那么modCount+1,而expectedModCount没加1
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
//内部类Itr迭代器中的删除方法
public void remove() {
.............
//将修改后集合的次数重新赋值给期望修改的次数expectedModCount
expectedModCount = modCount;
.............
}
}
//ArrayList集合中的删除方法
public boolean remove(Object o) {
...................
fastRemove(index);
....................
}
private void fastRemove(int index) {
//modCount :表示集合长度的修改次数 每次修改集合该变量都会+1
modCount++;//modCount变为5
.........
}
}
小结:
1.如果使用迭代器迭代集合时,使用集合中的方法修改集合则会报并发修改异常,使用迭代器中的删除方法就可以解决
2.发生并发修改异常的原因:在底层有一个变量modCount每次修改集合长度都会+1,还有一个变量expectedModCount表示期望修改集合的次数,刚开始创建内部类Itr对象时,执行代码
expectedModCount = modCount
如果使用集合中的删除方法,那么modCount+1,但是expectedModCount并没有改变,下次调用next()方法时,执行底层的代码: checkForComodification();
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
如果modCount和expectedModCount不相等就会报并发修改异常
3.为什么使用迭代器中的删除方法不报异常呢?
因为迭代器中的删除方法执行了:
expectedModCount = modCount;
将modCount修改后的值重新赋值给expectedModCount,这样他们就会相等了,下次执行next()方法在判断就不会报异常了
6.自学
删除集合倒数第二个数据没有报并发修改异常。
没有执行next()所以没有报异常。
2.增强for循环(掌握)
是jdk5以后诞生的技术,原理是Iterator迭代器。简化迭代器使用的。
格式:
for(数组或者集合的数据类型 变量名:数组或者集合名){
}
注意:增强for循环只能用来迭代集合或者数组在迭代的时候不能对数据进行修改,否则就会报并发修改异常。
代码演示:
package com.itheima.sh.foreach_02;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/*
for(数组或者集合的数据类型 变量名:数组或者集合名){
}
*/
public class ForDemo01 {
public static void main(String[] args) {
//调用方法
method_2();
}
//迭代集合
private static void method_2() {
//创建集合对象
Collection<Integer> coll = new ArrayList<>();
//添加数据
coll.add(10);
coll.add(20);
coll.add(10);
//使用迭代器迭代集合
/*for(Iterator it = coll.iterator();it.hasNext();){
//获取数据
Integer s = it.next();
System.out.println("s = " + s);
}*/
//使用增强for循环快捷键:数组或者集合名.for回车
for (Integer i : coll) {//i就是集合中的数据
System.out.println("i = " + i);
}
}
//迭代数组
private static void method_1() {
//定义数组
int[] arr = {10, 20, 30};
//使用之前学习的for循环遍历
/* for (int i = 0; i < arr.length; i++) {//i表示索引
System.out.println(arr[i]);
}*/
//使用增强for循环遍历数组
for (int x : arr) {//x表示数组中的数据
System.out.println("x = " + x);
}
}
}
小结:
1.增强for循环格式:
for(数组或者集合的数据类型 变量名:数组或者集合名){
}
2.使用增强for循环快捷键:数组或者集合名.for回车或者iter
3.增强for循环只能用来迭代集合或者数组在迭代的时候不能对数据进行修改,否则就会报并发修改异常。
3.泛型(掌握)
引入
1.泛型也属于一种数据类型,但是不能单独使用。
int a =10这个是可以的
b;不可以
2.泛型格式:<标识符>这里定义的泛型只要满足标识符范围即可,一般建议是大写字母。举例:
3.为什么使用泛型?
package com.itheima.sh.generic_03;
import com.sun.org.apache.xerces.internal.xs.StringList;
import java.util.ArrayList;
import java.util.Collection;
/*
泛型引入
*/
public class Test01 {
public static void main(String[] args) {
//创建集合对象
Collection<String> coll = new ArrayList<String>();
//向集合添加数据
coll.add("abc");
coll.add("abcd");
// coll.add(123);
// coll.add(true);
/*
如果创建集合不使用泛型,那么默认是Object类型,此时可以向集合中添加任意类型的数据
如果我们知道某个需求之后,不加泛型会有问题:
需求:求上述集合中所有字符串的长度
问题:既然已经知道求字符串的长度了,那么为什么向集合中添加数据的时候不限制只能添加字符串呢,如果不限制
那么添加数据可以添加任意类型,导致取出的时候还得判断类型和强制转换,这样太麻烦了,有可能引发类转换异常。
所以我们先知道需求之后,我们可以限制集合只能存储String类型,这里使用泛型就可以限制
*/
//遍历取出每个元素并输出长度
//Object obj = "abc"
/*for (Object obj : coll) {
//强制转换Stirng子类
String s = (String) obj;
System.out.println(s.length());
}*/
for (String s : coll) {
System.out.println(s.length());
}
}
}
小结:
1.开发中我们都是先知道需求,根据需求操作集合。所以我们可以通过泛型来限制集合存储的数据类型,这样可以避免没有必要的麻烦(强制转换 判断类型等)。从jdk5后,泛型已经成为了一种开发习惯
2.泛型可以将以前运行时的错误变为编译时的错误
概述和注意事项
1.格式:<标识符> 定义的时候使用大写字母
2.注意事项
-
泛型不支持基本数据类型
Collection<int> coll = new ArrayList<int>();错误的写法 -
泛型不支持继承写法
Collection<Object> coll = new ArrayList<Integer>();错误的写法 -
从jdk7后支持如下写法
Collection<String> coll = new ArrayList<>();
自定义泛型
我们以前对于泛型都是在使用别人定义好的,我们使用。就是在集合中。我们也可以自己定义泛型。
自定义泛型有三种:
1.自定义泛型类
2.自定义泛型方法
3.自定义泛型接口
1.自定义泛型类(掌握)
格式:
public class 类名<标识符>{
}
代码演示:
package com.itheima.sh.generic_04;
/*
自定义泛型类
*/
public class Demo<ABC> {
//成员变量
int age;
ABC name;//这里还不知道ABC的具体数据类型
//定义成员方法
public void show(ABC name){
this.name = name;
System.out.println("name = " + this.name);
}
}
package com.itheima.sh.generic_04;
import java.util.ArrayList;
public class Test01 {
public static void main(String[] args) {
//创建对象
Demo<String> d = new Demo<>();
//使用对象d调用show方法
d.show("锁哥");
//再次创建对象
Demo<Integer> d1 = new Demo<>();
d1.show(10);
Demo d2 = new Demo();
d2.show(true);
}
}
小结:
1.自定义泛型类格式:
public class 类名<标识符>{
}
2.自定义泛型类何时确定泛型?
在创建对象时确定,如果创建对象不指定泛型的具体数据类型,那么就是Object
Demo<String> d = new Demo<>();
2.自定义泛型方法(掌握)
格式:
方法修饰符 <标识符> 方法返回值类型 方法名(参数列表){
}
说明:
1. <标识符>表示定义的泛型
代码演示:
package com.itheima.sh.generic_05;
/*
自定义泛型类
*/
public class Demo<ABC> {
//成员变量
int age;
ABC name;//这里还不知道ABC的具体数据类型
//定义成员方法
public void show(ABC name){
this.name = name;
System.out.println("name = " + this.name);
}
/*
自定义泛型方法:
方法修饰符 <标识符> 方法返回值类型 方法名(参数列表){
}
说明:
1. <标识符>表示定义的泛型
*/
//1.定义泛型 2.IT it 使用泛型IT
public <IT> void method(IT it){
System.out.println("it = " + it);
}
}
package com.itheima.sh.generic_05;
public class Test01 {
public static void main(String[] args) {
//创建对象
Demo<String> d = new Demo<>();
//使用对象调用方法
d.method(10);
d.method(true);
}
}
小结:
1.自定义泛型方法是在调用方法时确定泛型
2.格式:
方法修饰符 <标识符> 方法返回值类型 方法名(参数列表){
}
3.自定义泛型接口(掌握)
格式:
public interface 接口名<标识符>{
}
代码演示:
public interface Inter<T> {
//定义抽象方法
void show(T t);
}
package com.itheima.sh.generic_06;
/*
接口的泛型确定具体的数据类型由两种方式:
1.是实现类实现接口时确定
public class InterImpl implements Inter{}
2.泛型的传递
public interface Inter {}
public class InterImpl implements Inter{}
InterImpl ip = new InterImpl<>();//创建对象时确定自定义泛型类的数据类型
补充:集合使用的就是泛型传递的方式确定泛型的具体数据类型
public interface Collection{}
public interface List extends Collection {}
public class ArrayList implements List{}
ArrayList list = new ArrayList();
*/
//public class InterImpl implements Inter{
public class InterImpl<E> implements Inter<E>{
@Override
public void show(E e) {
System.out.println(e);
}
}
package com.itheima.sh.generic_06;
public class Test01 {
public static void main(String[] args) {
//创建实现类对象
/* InterImpl ip = new InterImpl();
ip.show("abc");*/
//创建实现类对象
InterImpl<Integer> ip = new InterImpl<>();
ip.show(10);
}
}
小结:
1.自定义泛型接口格式:
public interface 接口名<标识符>{
}
2.何时确定泛型接口的具体的数据类型?
1)是实现类实现接口时确定
public class InterImpl implements Inter<String>{}
2)泛型的传递
public interface Collection<E>{}
public interface List<E> extends Collection<E> {}
public class ArrayList<E> implements List<E>{}
ArrayList<String> list = new ArrayList<String>();
总结:
- 自定义泛型类是在创建对象时确定具体的数据类型
- 自定义泛型方法是在调用方法时确定数据类型
- 自定义泛型接口:
- 实现类实现接口时确定
- 泛型传递确定
泛型通配符和限定(掌握)
- 泛型通配符符号是:使用问号**?**表示泛型通配符
package com.itheima.sh.generic_07;
import java.util.ArrayList;
import java.util.Collection;
/*
泛型通配符
*/
public class Test01 {
public static void main(String[] args) {
//创建集合对象
Collection<String> coll = new ArrayList<>();
coll.add("aaa");
coll.add("bbb");
coll.add("ccc");
Collection<Integer> coll2 = new ArrayList<>();
coll2.add(10);
coll2.add(20);
//调用自定义方法打印上述两个集合内容
printColl(coll);
printColl(coll2);
}
/*
Collection
// private static void printColl(Collection coll) {
private static void printColl(Collection<?> coll) {
//遍历集合
for (Object o : coll) {
System.out.println(o);
}
}
}
-
泛型限定
-
上限限定:? extends E 这里的?可以是E类型本身以及子类类型
? extends Person :?通配符的类型可以是Person,或者Person的子类代码演示:
package com.itheima.sh.generic_07; public class Person { } package com.itheima.sh.generic_07; public class Student extends Person { } package com.itheima.sh.generic_07; import java.util.ArrayList; /* 上限限定:? extends E 这里的?可以是E类型本身以及子类类型 举例:? extends Person :?通配符的类型可以是Person,或者Person的子类 */ public class Test02 { public static void main(String[] args) { //创建集合 ArrayList<Person> list = new ArrayList<>(); ArrayList<Student> list2 = new ArrayList<>(); //调用方法打印集合 printList(list); printList(list2); } private static void printList(ArrayList<? extends Person> list) { } } -
下限限定:? super E 那么通配符?的数据类型可以是E本身以及父类
举例: ? super Student: ?的类型是Student或者Student的父类package com.itheima.sh.generic_07; import java.util.ArrayList; /* 下限限定:? super E 那么通配符?的数据类型可以是E本身以及父类 举例: ? super Student: ?的类型是Student或者Student的父类 */ public class Test03 { public static void main(String[] args) { //创建集合 ArrayList<Person> list = new ArrayList<>(); ArrayList<Student> list2 = new ArrayList<>(); //调用方法打印集合 printList(list); printList(list2); } private static void printList(ArrayList<? super Student> list) { } }小结:
1.通配符使用?表示
2.泛型上限限定:? extends Person ?可以是Person以及子类
3.泛型下限限定:? super Student ?可以是Student以及父类
-
4.数据结构(掌握)
概念介绍
就是存储数据的方式,不同的数据结构存储数据的特点是不一样。
数据结构包括:链表 数组 树 堆栈 队列。。。
栈数据结构
英文是stack,又称堆栈,它是运算受限的线性表,其限制是仅允许一端进行插入和删除操作,不允许在其他任何位置进行添加、查找、删除等操作。
举例:类似于生活中子弹弹夹。放子弹和打出子弹都是一端。
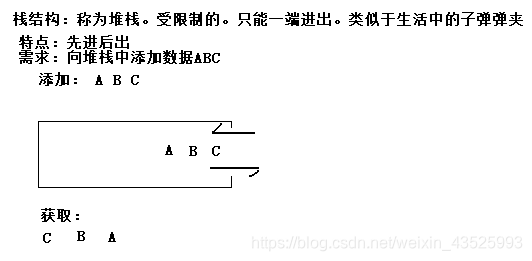
小结:
1.堆栈数据结构只能一端进和出
2.特点:先进后出
3.这里两个名词需要注意:
- 压栈:就是存元素。即,把元素存储到栈的顶端位置,栈中已有元素依次向栈底方向移动一个位置。
- 弹栈:就是取元素。即,把栈的顶端位置元素取出,栈中已有元素依次向栈顶方向移动一个位置。
队列数据结构
也是受限制的数据结构,只允许一端进,另一端出。
特点:先进先出。类似于生活中排队买票,火车进山洞等
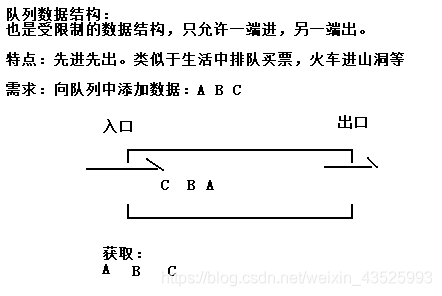
小结:
1.也是受限制的数据结构,只允许一端进,另一端出。
2.特点:先进先出。
数组数据结构
在内存中一串连续的空间,类似于生活中的监狱。楼房,火车车厢 。
特点:查询快,增删慢。

小结:
1.数组在内存中是开辟连续的的空间
2.数组数据结构特点:查询快,增删慢。ArrayList 底层就是数组数据结构,查询使用,增删不建议使用。
链表数据结构
我们后续学习的集合LinkedList底层是双链表数据结构。链表数据结构有两种:
- 单向链表
- 双向链表
**链表:**链表由多个节点组成。然后由一个链子将多个节点连接起来。
节点:每个节点由多部分组成,一部分用来存储数据的称为数据域,其他部分用来存储其他节点的地址值的,称为指针域。

小结:链表数据结构查询慢,增删快。后期学习的LKinkedList底层是链表数结构,开发时只要增删使用LinkedList
树基本结构介绍
概念介绍:
计算机中的树数据结构是生活中倒立的树。就是在计算机中树根在上面。
名词解释:
| 名词 | 含义 |
|---|---|
| 节点 | 指树中的一个元素(数据) |
| 节点的度 | 节点拥有的子树(儿子节点)的个数,二叉树的度不大于2,例如:下面二叉树A节点的度是2,E节点的度是1,F节点的度是0 |
| 叶子节点 | 度为0的节点,也称之为终端结点,就是没有儿子的节点。 |
| 高度 | 叶子结点的高度为1,叶子结点的父节点高度为2,以此类推,根节点的高度最高。例如下面二叉树ACF的高度是3,ACEJ的高度是4,ABDHI的高度是5. |
| 层 | 根节点在第一层,以此类推 |
| 父节点 | 若一个节点含有子节点,则这个节点称之为其子节点的父节点 |
| 子节点 | 子节点是父节点的下一层节点 |
| 兄弟节点 | 拥有共同父节点的节点互称为兄弟节点 |
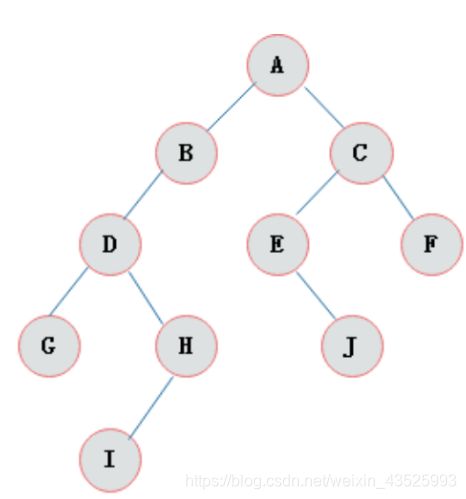
二叉查找树
1. 【左子树】上所有的节点的值均【小于】他的【根节点】的值
2. 【右子树】上所有的节点值均【大于】他的【根节点】的值
3. 每一个子节点最多有两个子树
4. 二叉查找树中没有相同的元素

平衡二叉树
为了提高查找效率的。
规则:它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树

小结:平衡二叉树查找效率高于非平衡二叉树。
总结:
二叉树:每个节点的子节点不超过2个
二叉查找树:
1)左子树小于根节点,右子树大于根节点
2)没有相等的数据
平衡二叉树:每个节点的左右子树的度的绝对值不能超过1.