Flink-安装部署及部署模式介绍
Flink支持三大部署模式:
1. Local 本地部署
Flink 可以运行在 Linux、Mac OS X 和 Windows 上。本地模式的安装唯一需要的只是Java 1.7.x或更高版本,本地运行会启动Single JVM,主要用于测试调试代码。
2. Standalone Cluster集群部署
Flink自带了集群模式Standalone,这个模式对软件有些要求:
1.安装Java1.8或者更高版本
2.集群各个节点需要ssh免密登录
3. Flink ON YARN
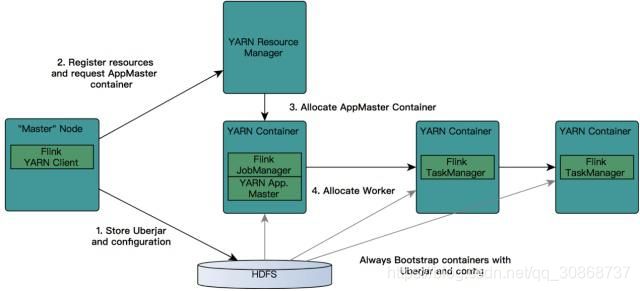
Flink ON YARN工作流程如下所示:
首先提交job给YARN,就需要有一个Flink YARN Client。
第一步:Client将Flink 应用jar包和配置文件上传到HDFS。
第二步:Client向REsourceManager注册resources和请求APPMaster Container。
第三步:REsourceManager就会给某一个Worker节点分配一个Container来启动APPMaster,JobManager会在APPMaster中启动。
第四步:APPMaster为Flink的TaskManagers分配容器并启动TaskManager,TaskManager内部会划分很多个Slot,它会自动从HDFS下载jar文件和修改后的配置,然后运行相应的task。TaskManager也会与APPMaster中的JobManager进行交互,维持心跳等。
Flink的支持以上这三种部署模式,一般在学习研究环节,资源不充足的情况下,采用Local模式就行,生产环境中Flink ON YARN比较常见。
Flink Local模式部署测试
1.jdk的安装和验证
java -version
2.下载安装包 下载地址:https://archive.apache.org/dist/flink

选择自己需要的版本进行下载
2.解压安装包(tar -zxvf flink-*.tgz)
tar xzf flink-*.tgz # 解压文件
cd flink-1.8.0
3.启动单节点flink
$ ./bin/start-cluster.sh # 启动 Flink
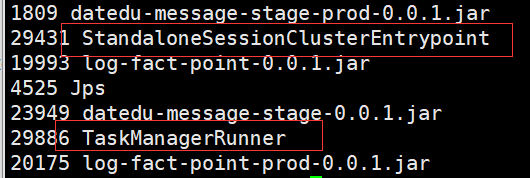
查看进程jps
在ndoe-1上可用看见StandaloneSessionClusterEntrypoint进程即JobManager,在其他的节点上可用看见到TaskManagerRunner 即TaskManager
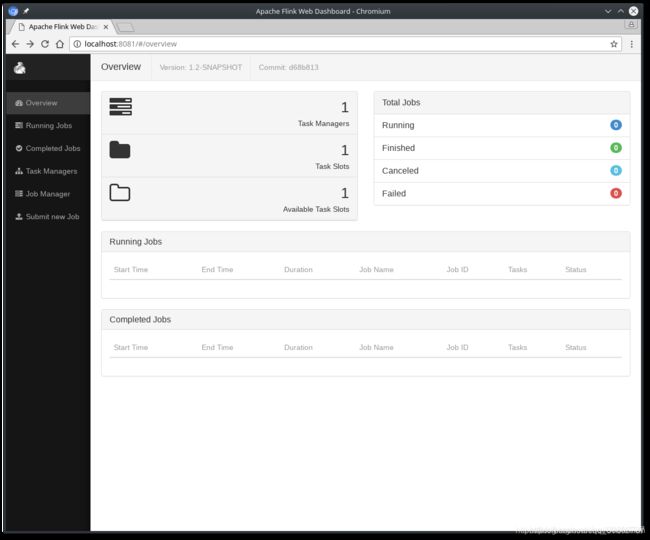
访问localhost:8081,确认监控界面正常启动,Web监控界面会显示有一个可用的TaskManager实例。
4.验证
本文将验证官方给出的SocketWindowWordCount代码,代码将从socket监听中读取数据,并且每5秒打印一次前5秒内每个不同单词的出现次数,即使用windos的滚动时间窗口。
SocketWindowWordCount的scala源码如下:
object SocketWindowWordCount {
def main(args: Array[String]) : Unit = {
// the port to connect to
val port: Int = try {
ParameterTool.fromArgs(args).getInt("port")
} catch {
case e: Exception => {
System.err.println("No port specified. Please run 'SocketWindowWordCount --port '")
return
}
}
// get the execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// get input data by connecting to the socket
val text = env.socketTextStream("localhost", port, '\n')
// parse the data, group it, window it, and aggregate the counts
val windowCounts = text
.flatMap { w => w.split("\\s") }
.map { w => WordWithCount(w, 1) }
.keyBy("word")
.timeWindow(Time.seconds(5), Time.seconds(1))
.sum("count")
// print the results with a single thread, rather than in parallel
windowCounts.print().setParallelism(1)
env.execute("Socket Window WordCount")
}
// Data type for words with count
case class WordWithCount(word: String, count: Long)
}
首先,我们使用netcat来启动本地服务器
nc -l 9000
提交Flink计划:
./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000
启动运行方式:
flink run -c SocketWindowWordCount examples/streaming/SocketWindowWordCount.jar --port 9000
解析:-c指的是jar包主函数类名, 后面跟着具体位置的jar包 ,再跟着jar里需要的入参
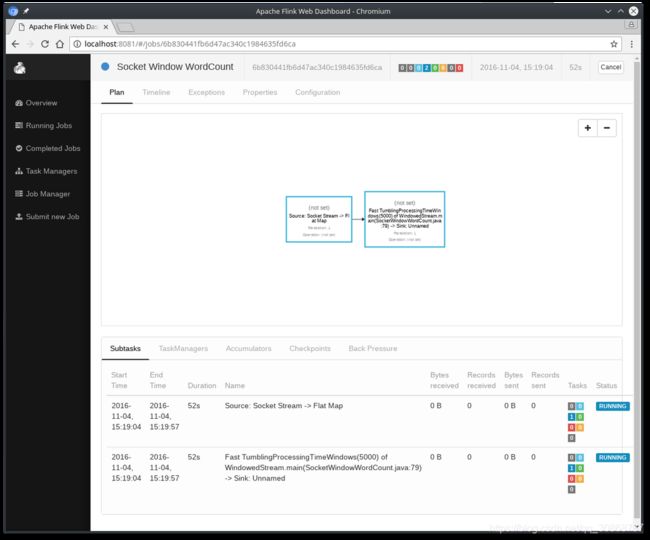
此时程序等待socket输入。可以在web监控页面查看作业启动情况:
在nc窗口输入数据:
nc -l 9000
lorem ipsum
ipsum ipsum ipsum
bye
查看计算结果
tail -f log/flink-*-taskexecutor-*.out
lorem : 1
bye : 1
ipsum : 4
5.关闭单节点flink
$ ./bin/stop-cluster.sh # 关闭 Flink
Flink StandAlone 模式
基于standalone的flink集群规划(基于standalone模式)【平时练习使用该模式,生产环境基本上都使用YARN模式】
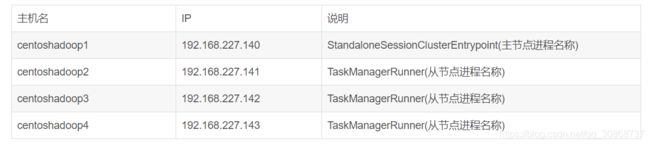
解压flink-1.9.0-bin-scala_2.11.tgz 到/home/hadoop/flink目录
tar -zxvf flink-1.9.0-bin-scala_2.11.tgz -C ~/flink
配置基本参数(结合机器情况调整)
cd /home/hadoop/flink/flink-1.9.0/conf
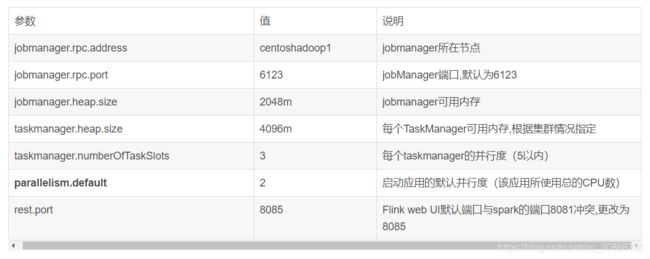
配置flink-conf.yaml,根据如下表格进行调整相应的参数
基础配置
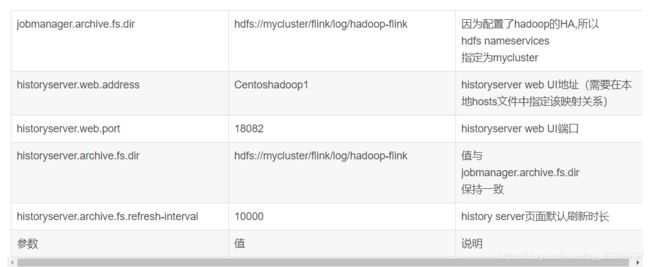
history server配置
Flink配置文件——slaves
修改 /conf/slaves(有的版本是workers) 文件
vi slaves
centoshadoop2
centoshadoop3
centoshadoop4
修改 /conf/masters 文件
vim masters
centoshadoop1:8081
添加环境变量
export FLNK_HOME=/opt/program/flink-1.9.0
export PATH=$FLINK_HOME/bin:$PATH
分发到其他节点
cd ~
scp -r flink/ hadoop@centoshadoop2:~/
scp -r flink/ hadoop@centoshadoop3:~/
scp -r flink/ hadoop@centoshadoop4:~/
cd /home/hadoop/flink/flink-1.9.0
bin/start-cluster.sh – 启动集群
访问集群,界面如下(部分的参数配置)
http://centoshadoop1:8085/

bin/stop-cluster.sh --停止集群
jps参考各个节点的进程
[hadoop@centoshadoop1 flink-1.9.0]$ jps
StandaloneSessionClusterEntrypoint
[hadoop@centoshadoop2 flink-1.9.0]$ jps
TaskManagerRunner
[hadoop@centoshadoop2 flink-1.9.0]$ jps
TaskManagerRunner
[hadoop@centoshadoop2 flink-1.9.0]$ jps
TaskManagerRunner
如果集群中Master节点的jobManager进程停止,或者机器重启导致进程停止,可以通过下面的命令启动或者停止
bin/jobmanager.sh start|stop
同理,如果想要手工停止TaskManager进程停止,或者想要向正在运行的集群中增加行的Slave节点,则可以使用如下命令
bin/taksmanager.sh start|stop
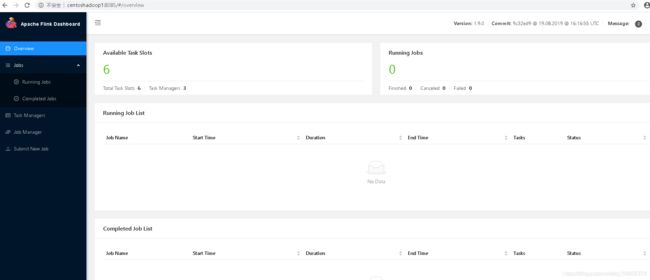
启动正常后,部分界面截图
测试
../../bin/flink run WordCount.jar

flink-on-yarn 模式
Flink提供了两种在yarn上运行的模式,分别为Session-Cluster和Per-Job-Cluster模式,本文分析两种模式及启动流程。
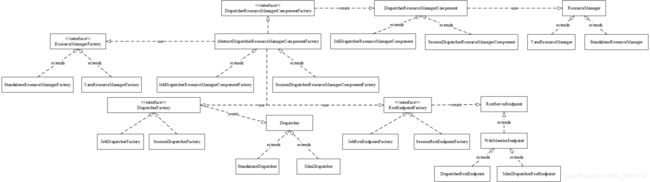
下图展示了Flink-On-Yarn模式下涉及到的相关类图结构

Session-Cluster模式
Session-Cluster模式需要先启动集群,然后再提交作业,接着会向yarn申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享Dispatcher和ResourceManager;共享资源;适合规模小执行时间短的作业。
1. 启动集群
运行bin/yarn-session.sh即可默认启动包含一个TaskManager(内存大小为1024MB,包含一个Slot)、一个JobMaster(内存大小为1024MB),当然可以通过指定参数控制集群的资源,如-n指定TaskManager个数,-s指定每个TaskManager中Slot的个数;其他配置项,可参考
下面以bin/yarn-session.sh为例,分析Session-Cluster启动流程。
2.流程分析
下面分为本地和远程分析启动流程,其中本地表示在客户端的启动流程,远端则表示通过Yarn拉起Container的流程;
本地流程
- Session启动入口为FlinkYarnSessionCli#main
- 根据传入的参数确定集群的资源信息(如多少个TaskManager,Slot等)
- 部署集群AbstractYarnClusterDescriptor#deploySessionCluster -> AbstractYarnClusterDescriptor#deployInternal
- 进行资源校验(如内存大小、vcore大小、队列)
- 通过YarnClient创建Application
- 再次校验资源
- AbstractYarnClusterDescriptor#startAppMaster启动AppMaster
1.初始化文件系统(HDFS)
2.将log4j、logback、flink-conf.yaml、jar包上传至HDFS
3.构造AppMaster的Container(确定Container进程的入口类YarnSessionClusterEntrypoint),构造相应的Env
4.YarnClient向Yarn提交Container申请
5.跟踪ApplicationReport状态(确定是否启动成功,可能会由于资源不够,一直等待) - 启动成功后将对应的ip和port写入flinkConfiguration中
- 创建与将集群交互的ClusterClient
1.根据flink-conf的HA配置创建对应的服务(如StandaloneHaServices、ZooKeeperHaServices等)
2.创建基于Netty的RestClient;
3.创建/rest_server_lock、/dispatcher_lock节点(以ZK为例)
4.启动监听节点的变化(主备切换) - 通过ClusterClient获取到appId信息并写入本地临时文件
经过上述步骤,整个客户端的启动流程就结束了,下面分析yarn拉起Session集群的流程,入口类在申请Container时指定为YarnSessionClusterEntrypoint。
远端流程
- 远端宿主在Container中的集群入口为YarnSessionClusterEntrypoint#main
- ClusterEntrypoint #runClusterEntrypoint -> ClusterEntrypoint#startCluster启动集群
- 初始化文件系统
- 初始化各种Service(如:创建RpcService(AkkaRpcService)、创建HAService、创建并启动BlobServer、创建HeartbeatServices、创建指标服务并启动、创建本地存储ExecutionGraph的Store)
- 创建DispatcherResourceManagerComponentFactory(SessionDispatcherResourceManagerComponentFactory),用于创建DispatcherResourceManagerComponent(用于启动Dispatcher、ResourceManager、WebMonitorEndpoint)
- 通过DispatcherResourceManagerComponentFactory创建DispatcherResourceManagerComponent
1.创建/dispatcher_lock节点,/resource_manager_lock节点
2.创建DispatcherGateway、ResourceManagerGateway的Retriever(用于创建RpcGateway)
3.创建DispatcherGateway的WebMonitorEndpoint并启动
4.创建JobManager的指标组
5.创建ResourceManager、Dispatcher并启动进行ZK选举
6.返回SessionDispatcherResourceManagerComponent
经过上述步骤就完成了集群的启动;
3.启动任务
当启动集群后,即可使用./flink run -c mainClass /path/to/user/jar向集群提交任务。
4.流程分析
同样,下面分为本地和远程分析启动流程,其中本地表示在客户端提交任务流程,远端则表示集群收到任务后的处理流程。
本地流程
- 程序入口为CliFrontend#main
- 解析处理参数
- 根据用户jar、main、程序参数、savepoint信息生成PackagedProgram
- 获取session集群信息
- 执行用户程序
- 设置ClassLoader
- 设置Context
- 执行用户程序main方法(当执行用户业务逻辑代码时,会解析出StreamGraph然后通过ClusterClient#run来提交任务),其流程如下:
1.获取任务的JobGraph
2.通过RestClusterClient#submitJob提交任务
3.创建本地临时文件存储JobGraph
4.通过RestClusterClient向集群的rest接口提交任务
5.处理请求响应结果 - 重置Context
- 重置ClassLoader
经过上述步骤,客户端提交任务过程就完成了,主要就是通过RestClusterClient将用户程序的JobGraph通过Rest接口提交至集群中。
远端流程
远端响应任务提交请求的是RestServerEndpoint,其包含了多个Handler,其中JobSubmitHandler用来处理任务提交的请求;
- 处理请求入口:JobSubmitHandler#handleRequest
- 进行相关校验
- 从文件中读取出JobGraph
- 通过BlobClient将jar及JobGraph文件上传至BlobServer中
- 通过Dispatcher#submitJob提交JobGraph
- 通过Dispatcher#runJob运行任务
- 创建JobManagerRunner(处理leader选举)
- 创建JobMaster(实际执行任务入口,包含在JobManagerRunner)
- 启动JobManagerRunner(会进行leader选举,ZK目录为leader/${jobId}/job_manager_lock)
- 当为主时会调用JobManagerRunner#grantLeadership方法
1.启动JobMaster
2.将任务运行状态信息写入ZK(/ A p p I D / r u n n i n g j o b r e g i s t r y / {AppID}/running_job_registry/ AppID/runningjobregistry/{jobId})
3.启动JobMaster的Endpoint
4.开始调度任务JobMaster#startJobExecution
接下来就进行任务具体调度(构造ExecutionGraph、申请Slot等)流程,本篇文章不再展开介绍。
Per-Job-Cluster模式
一个任务会对应一个Job,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
1.启动任务
启动Per-Job-Cluster任务,可通过./bin/flink run -m yarn-cluster -d -c mainClass /path/to/user/jar命令使用分离模式启动一个集群,即单任务单集群;
2.流程分析
与Session-Cluster类似,我们对Per-Job-Cluster模式也分为本地和远端。
本地流程
- 与Session-Cluster模式类似,入口也为CliFrontend#main
- 解析处理参数
- 根据用户jar、main、程序参数、savepoint信息生成PackagedProgram
- 根据PackagedProgram创建JobGraph(对于非分离模式还是和Session模式一样,模式Session-Cluster)
- 获取集群资源信息
- 部署集群YarnClusterDesriptor#deployJobCluster -> AbstractYarnClusterDescriptor#deployInternal;后面流程与Session-Cluster类似,值得注意的是在AbstractYarnClusterDescriptor#startAppMaster中与Session-Cluster有一个显著不同的就是其会将任务的JobGraph上传至Hdfs供后续服务端使用
经过上述步骤,客户端提交任务过程就完成了,主要涉及到文件(JobGraph和jar包)的上传。
远端流程
- 远端宿主在Container中的集群入口为YarnJobClusterEntrypoint#main
- ClusterEntrypoint#runClusterEntrypoint -> ClusterEntrypoint#startCluster启动集群
- 创建JobDispatcherResourceManagerComponentFactory(用于创建JobDispatcherResourceManagerComponent)
- 创建ResourceManager(YarnResourceManager)、Dispatcher(MiniDispatcher),其中在创建MiniDispatcher时会从之前的JobGraph文件中读取出JobGraph,并启动进行ZK选举
- 当为主时会调用Dispatcher#grantLeadership方法
- Dispatcher#recoverJobs恢复任务,获取JobGraph
- Dispatcher#tryAcceptLeadershipAndRunJobs确认获取主并开始运行任务
Dispatcher#runJob开始运行任务(创建JobManagerRunner并启动进行ZK选举),后续流程与Session-Cluster相同,不再赘述
总结
Flink提供在Yarn上两种运行模式:Session-Cluster和Per-Job-Cluster,其中Session-Cluster的资源在启动集群时就定义完成,后续所有作业的提交都共享该资源,作业可能会互相影响,因此比较适合小规模短时间运行的作业,对于Per-Job-Cluster而言,所有作业的提交都是单独的集群,作业之间的运行不受影响(可能会共享CPU计算资源),因此比较适合大规模长时间运行的作业。
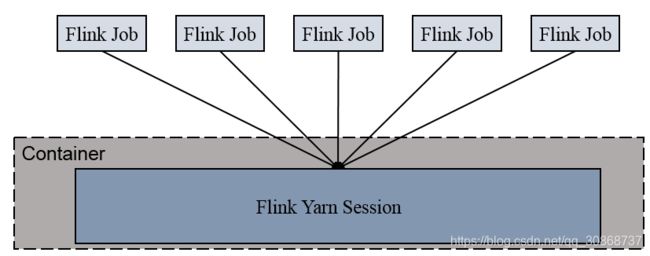
1.第一种yarn seesion(Start a long-running Flink cluster on YARN)这种方式需要先启动集群,然后在提交作业,接着会向yarn申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,那下一个作业才会正常提交.
2.第二种Flink run直接在YARN上提交运行Flink作业(Run a Flink job on YARN),这种方式的好处是一个任务会对应一个job,即没提交一个作业会根据自身的情况,向yarn申请资源,直到作业执行完成,并不会影响下一个作业的正常运行,除非是yarn上面没有任何资源的情况下。
综合以上这2种的示意图如下:
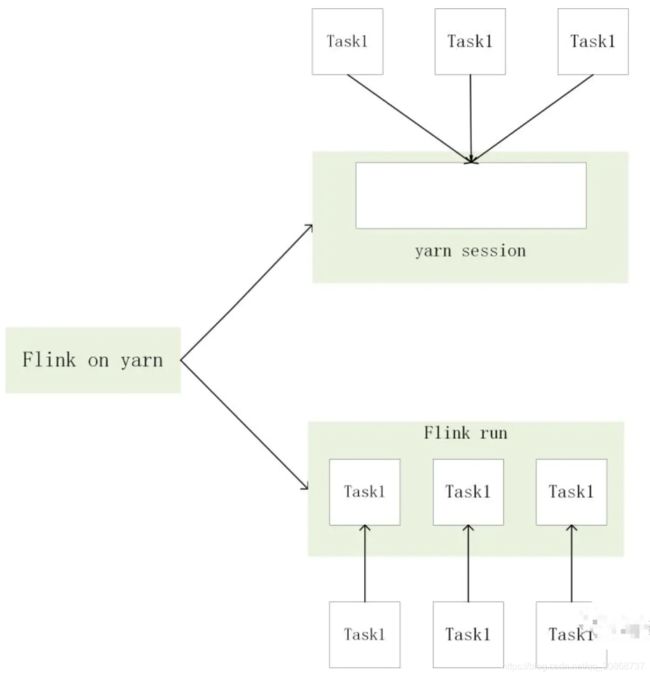
注意事项:如果是平时的本地测试或者开发,可以采用第一种方案;如果是生产环境推荐使用第二种方案;
Flink on yarn模式部署时,不需要对Flink做任何修改配置,只需要将其解压传输到各个节点之上。但如果要实现高可用的方案,这个时候就需要到Flink相应的配置修改参数,具体的配置文件是FLINK_HOME/conf/flink-conf.yaml。
对于Flink on yarn模式,我们并不需要在conf配置下配置 masters和slaves。因为在指定TM的时候可以通过参数“-n”来标识需要启动几个TM;Flink on yarn启动后,如果是在分离式模式你会发现,在所有的节点只会出现一个 YarnSessionClusterEntrypoint进程;如果是客户端模式会出现2个进程一个YarnSessionClusterEntrypoint和一个FlinkYarnSessionCli进程。
Flink On Yarn安装部署
第一步安装
配置了NTP时间同步
安装 jdk、zookeeper、hadoop
根据下面连接选择合适版本对应
https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/
具体步骤参考
https://www.cnblogs.com/quchunhui/p/7411389.html
https://www.cnblogs.com/quchunhui/p/12463455.html
第二步安装flink
下载并配置环境变量

配置文件
可以参考官网提供的example
https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/jobmanager_high_availability.html
相关配置文件:
flink-conf.yaml
masters
slaves
zoo.cfg
flink-conf.xml
jobmanager.rpc.address: rexel-ids001
jobmanager.rpc.port: 6123
jobmanager.heap.size: 512
taskmanager.memory.flink.size: 512m
taskmanager.numberOfTaskSlots: 4
parallelism.default: 1
high-availability: zookeeper
high-availability.storageDir: hdfs://ns/flink/recovery
high-availability.zookeeper.quorum: rexel-ids001:2181,rexel-ids002:2181,rexel-ids003:2181
high-availability.zookeeper.path.root: /flink
state.backend: filesystem
state.savepoints.dir: hdfs://ns/flink/savepoints
jobmanager.execution.failover-strategy: region
rest.port: 9081
rest.bind-port: 9100-9124
web.submit.enable: false
io.tmp.dirs: /home/radmin/data/flink/tmp
env.log.dir: /home/radmin/data/flink/logs
fs.hdfs.hadoopconf: /home/radmin/hadoop-2.10.0/etc/hadoop/
jobmanager.archive.fs.dir: hdfs://ns/flink/completed_jobs/
historyserver.web.address: 0.0.0.0
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://ns/flink/completed_jobs/
historyserver.archive.fs.refresh-interval: 10000
masters
rexel-ids001:8081
rexel-ids002:8081
slaves
rexel-ids001
rexel-ids002
rexel-ids003
zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/radmin/data/zk/dataDir
dataLogDir=/home/radmin/data/zk/dataLogDir
clientPort=2181
server.0=rexel-ids001:2888:3888
server.1=rexel-ids002:2888:3888
server.2=rexel-ids003:2888:3888
集群启动
启动命令:./start-cluster.sh
启动Web页面
Web页面的端口号是8081。
提交程序
提交官方提供的WordCount程序试试
启动命令:flink run -m yarn-cluster /home/radmin/package/WordCount.jar
参考连接
https://www.cnblogs.com/quchunhui/p/12463455.html
https://www.cnblogs.com/quchunhui/p/7411389.html
https://mp.weixin.qq.com/s?__biz=MzIxMjI3NTI5OQ==&mid=2650461709&idx=1&sn=b6f027e02ae9632a38766b5243c4ed32&chksm=8f46ef01b831661733e1c2f78e7f50fd2d806b9032a1b110b60692dd242700f41e90b7d6f474&scene=21#wechat_redirect
https://www.jianshu.com/p/1b05202c4fb6
https://blog.csdn.net/xu470438000/article/details/79576989