2进程概念和状态
文章目录
- 前言
- 1. 何为进程?
- 2. 进程PCB
- 3. PCB内容
-
- 3.1 标识符PID
- 3.2 程序计数器
- 3.3 上下文数据
- 4. 创建子进程---fork()
-
- 4.1 理解fork的工作原理
- 5. 进程状态
-
- 5.1 R (running) 运行状态
- 5.2 S(sleeping) 可中断睡眠状态
- 5.3 D (Disk sleep) 不可中断的睡眠状态
- 5.4 T (stopped) 停止状态
- 5.5 Z (zombie) 僵尸状态 和 X (dead) 死亡状态
- 5.6 孤儿进程
- 6 小解惑
-
- 什么样的状态无法被杀死:?
- 7. 进程优先级
-
- 7.1 概念
- 7.2 优先级量化表示
- 7.3 优先级的调整
- 7.4 优先级三问
前言
上一章节博主讲解了操作系统的发展历程,以及其和硬件之间的连接关系,那么读者们有没有思考过一个问题呢,OS到底是怎么管理软硬件程序的呢? 没错,我们今天的主角就是—进程.
1. 何为进程?
简单来说就是某个程序任务的执行实例.
譬如目前电脑需要执行播放音乐,打开Word文件,播放简单动画,那它们都会对应三个程序,也可以说成电脑将会执行三个进程
2. 进程PCB
上一小节,博主用校长和学生的关系类比了管理者和被管理之间的关系,那么大家是否想过一个问题: 管理者和被管理者并不直接接触,那是通过什么进行管理的呢?答案是数据信息.
我们刚开学时候,都会给学校录入自己的学籍信息(姓名,籍贯,年龄),而管理者就会通过你的信息进行管理,即使你们并不认识,比如你犯错被开除,管理者就只需要删除你的学籍信息,也就是说,管理的本质其实是管理信息.
同样的,在计算机中,操作系统对各个进程的管理,本质上是对不同进程进行了不同的数据信息描述,然后通过这些信息进行管理.
而对不同进程进行的数据描述存储在一个名为task_struct的结构体中,我们习惯叫做PCB(Processing Control Block)进程控制块,当有多个PCB时候,它们会以双链表形式连接在一起.
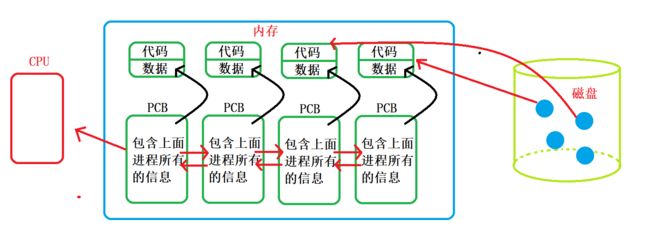
而由上面的图示可以明白,进程 = 代码数据 + PCB
3. PCB内容
PCB的信息内容如下:
- 标识符
PID: 不同进程控制块的身份ID - 进程状态(后面单独拿出来讲解): 用符号描述进程当前的状态(是否在运行,是否已经退出等)
- 优先级: 决定哪一个进程先执行,后执行
- 程序计数器: 存放下一条即将被执行的指令地址
- 内存指针: 指向程序代码以及进程相关的数据的指针(例如上面进程图的黑色箭头)
- 上下文数据: 进程执行时,处理器中寄存器的数据
- I/O状态信息: 显示IO请求,以及查询哪些设备对该进程开放等信息
- 记账信息:包括处理器处理该进程时间总和,使用的时钟总数等
3.1 标识符PID
PID是进程的身份ID,那么可否用程序进行检验呢? 答案是肯定的,系统提供了getpid和getppid两个函数用于获取当前进程的和父进程的PID
#include 结果:
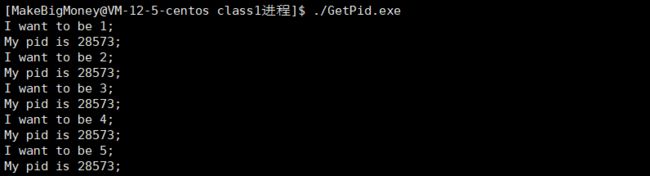
可以看到该进程的pid是28573
3.2 程序计数器
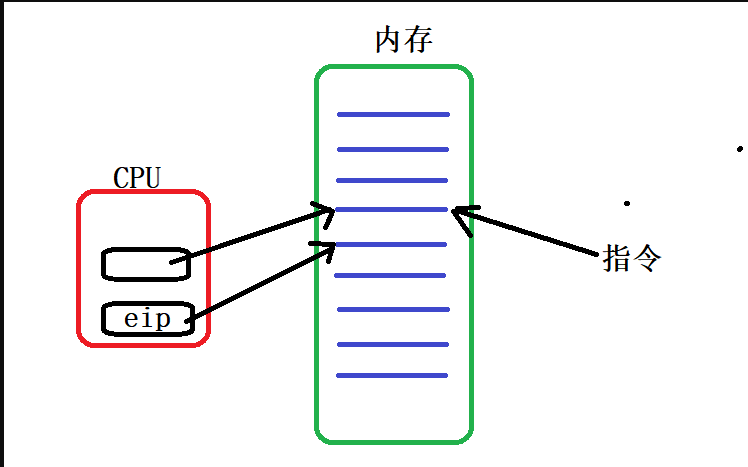
了解PCB后,我们知道,CPU所执行的代码实际是进程的代码,而其核心工作流程是取指令,分析指令,执行指令.那么CPU是如何得知应该取进程中的哪些指令呢? 这就归功于 程序计数器
CPU的一块指令寄存器,用于存放下一条即将被执行的指令地址,作用是为了保证CPU连续不间断的工作
也就是说当前CPU正在执行着某个程序代码时候,其内寄存器eip已经存了下一条即将执行的指令的地址,以此周而复始.
3.3 上下文数据
上下文数据是为了进程可以正常恢复,这里博主用休学例子类比CPU和进程关系;
如果有一天我们因为家里有事情无法正常上学或因为意愿去当兵,这个时候我们就可以向学校申请保留学籍,等事情解决完毕或退伍归来再恢复学籍.
保留学籍的目的是让学校知道你因为有事而离开学校,而记录下你此时已经学习的进度
恢复学籍的目的是让学校知道你解决完毕可以继续上学,而恢复李离校时候的学习进度
而进程就相当于我们,CPU类比于学校,当进程从CPU上脱离下来时,需要保存进程在CPU上执行的一切信息,以待该进程下一次进行恢复
4. 创建子进程—fork()
fork()是系统函数,用于创建子进程,有两个返回值.
分别给父进程返回子进程的PID,给子进程返回0PID
#include 结果:
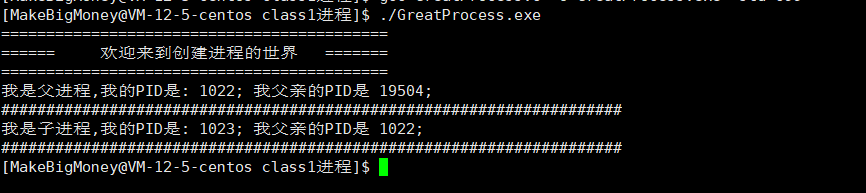
通过上面可以看到,当fork创建子进程成功以后,如果被分流(有if分支),那么父子进程各执行各自的;
如果未被分流,那么代码将公共享有
4.1 理解fork的工作原理
为什么fork()可以返回两个不同的值呢?
这里先明确一个观点: fork仅仅只是一个函数 ; 那么函数的返回值会由于数据的不同而不同;
那么根据当子进程创建成功以后,后面的代码共享原则,return语句就会被两个进程共享然后执行(如图),因此可以返回两个值;
又由于父子进程都有各自的不同数据,那么调用一次fork也就可以返回不同值了.

5. 进程状态
5.1 R (running) 运行状态
处于运行队列 或者 正在CPU中执行的进程都可以是R状态,比如一个死循环代码:
#include 当运行此代码以后,在Linux中执行以下命令,发现状态为R:
ps ajx | head -1 && ps ajx | grep StatR.exe //StatR.c是上面死循环代码的文件
![]()
5.2 S(sleeping) 可中断睡眠状态
处于这个状态的进程因为等待某事件的发生而被挂起,当这些事件发生以后,这些进程可以被重新唤醒(变成R状态),即S状态进程睡眠时候可以接收外部信号
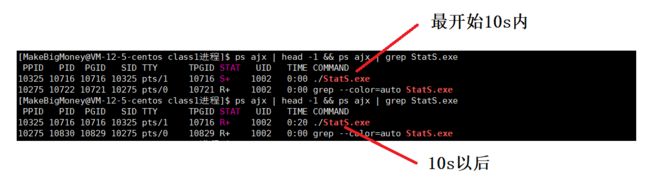
例如下面程序,让其先暂停10秒钟,这时候其状态为S,当10秒钟以后状态为R
#include 当运行该程序以后,在Linux下执行以下命令,发现状态由S–>R
ps ajx | head -1 && ps ajx | grep StatS.exe //StatS.c是上面死循环代码的文件
5.3 D (Disk sleep) 不可中断的睡眠状态
这个状态和S状态很像,因为他们都可以睡眠等待;
但是他们又有非常显著的区别,那就是D状态不能够被OS杀死,即D状态进程不接收外部信号;
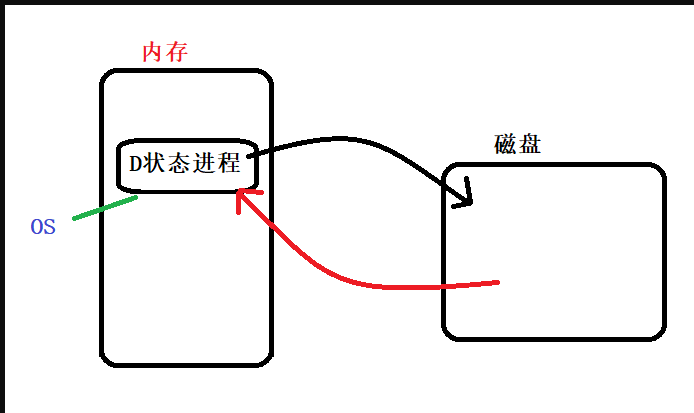
比如这里有个普通进程在内存中,它正向磁盘发送数据以让其存储起来,而在向磁盘发送数据的过程中该进程需要等待磁盘发回是否存储成功的信号,但是OS的功能是什么呢,他是进行管理系统资源的,这时候他发现该进程正在睡眠等待接收磁盘的信息,于是把他给杀死了.
这样麻烦就大了: 当磁盘存储失败或成功时候,需要发回信息,但是此时进程已经被干掉了,磁盘将不知道该怎么办,然后计算机就将从此崩溃;
那么为了处理这种情况,就给这种睡眠状态的进程赋予D状态,即你可以等待休眠且无法被OS杀死
5.4 T (stopped) 停止状态
可以通过发送SIGSTOP(标号19)信号进行暂停状态T.也可以通过SIGCONT(标号18)信号让进程继续运行
比如我们执行下面程序:
#include 当执行上面程序后,我们查询该进程的PID并通过kill命令向该进程发送SIGTOP信号,然后查询其状态:
kill -19 18154 //18154是该进程的PID
ps ajx | head -1 && ps ajx | grep StatT.exe

然后再通过发送SIGCONT信号进行恢复:
kill -18 18154 ;
ps ajx | head -1 && ps ajx | grep StatT.exe

5.5 Z (zombie) 僵尸状态 和 X (dead) 死亡状态
表现出死亡,但是还没回收称为僵尸状态;
生活中也有这种例子,比如一个人突然在家突然死亡,这个时候警察会来检验死亡原因,等一切弄清楚以后,再对外宣布死亡.
而父进程就扮演了警察角色,子进程结束后扮演表现死亡,对外宣布才是X(dead)死亡状态,而在表现死亡到对外宣布这个时间段是僵尸状态
#include 运行结果

状态查看,可以发现子进程在10秒内为Z僵尸状态

而通过僵尸状态我们可以得到结论:
进程创建的目的是为了完成某种任务,退出之前也不是立即让OS回收资源,而是退出前将自己信息写进PCB以供父进程或OS进行读取!!
5.6 孤儿进程
5.5小节我们说到了僵尸进程,产生原因是表现死亡后,需要等待父进程的回收.
但如果父进程比子进程先死亡然后被系统回收,那子进程此时就是孤儿进程了,它将会被PID为1的系统进程领养.
#include 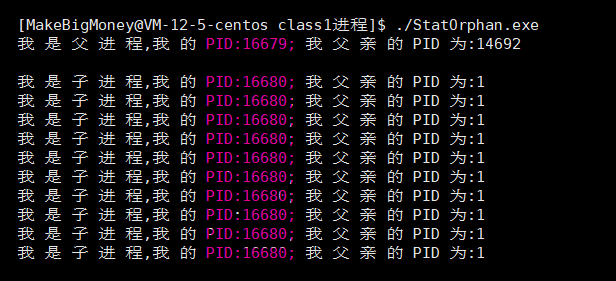
可以看到,子进程的
PID是16680,而父进程的PID为16679,刚好差1,说明父进程没退出之前,他们是父子关系,但是父进程比子进程先死,子进程就变成了孤儿进程,由PID为1系统进程领养
6 小解惑
细心读者可能会发现,我们的状态有些后面有个
+,而有些没有,他们什么区别呢?
例如S状态和S+有什么区别:
S+属于前台程序,可以在运行中被其他命令终止,如Ctrl C
S状态属于后台程序,不可以被终止,如在运行程序./test语句后面加上 &)
小伙伴们最好用一个死循环代码进行上面的测试进行感受带+和不带+的状态
什么样的状态无法被杀死:?
D状态 Z状态
7. 进程优先级
7.1 概念
表示不同进程之间相对优先执行的一种度量,即进程优先级越高代表越重要,相对于其他进程来说就先执行,进程优先级越低代表越不重要,相对于其他进程来说就后执行.
因此,配置进程优先级对多任务环境的Linux来说比较重要,比较重要的进程先执行,不重要的后执行;
7.2 优先级量化表示
优先级在Linux系统中一般有两个值构成–PRI和NI (分别对应priority和nice)
PRI默认值为80,NI的值默认为0,但是其调整范围为[-20,19],作用是进行修正PRI,调整后的PRI就等于原值加上NI,因此其范围为[60,99];
其中PRI的值越小代表优先级更高,值越大代表优先级越低–(类似我们成绩排名)
用命令ps -l可以看到一些进程的优先级如下(默认值确实分别为80和0)

其中可以用ps -l -p PID命令进行查看确切进程的优先级;
7.3 优先级的调整
Linux系统为我们提供了一个top命令,用于改变进程的NI值来修正PRI.
操作步骤为输入top—>回车然后输入r—>想修改进程的PID,再输入NI值,最后按q退出;
博主这里运行了一个名为StatR.exe的进程,其PID为5120,现在博主修改NI为10,可以看到前后变化:
(top前)

(top后)

7.4 优先级三问
第一问
如果一个进程像上图一样,PRI由80变为了90,当我们再次调整其NI值为-10时,请问其PRI和 NI值分别为多少?
PRI每次调整前都是以80为基础,所以当再次调整NI值为-10时候,两者的值为``PRI:70 , NI:-10;
第二问
如果用户不按照规定进行,调整NI值超过其界限,PRI和NI为多少?
当NI值超过界限时,按照其被超过的值计算,例如NI调整为50时超过了19那么其值为19,反之NI为-20;
第三问
为什么每次调整NI时候,PRI都是按照80来计算,而不是上次的PRI计算?
80用来作为基准值,方便进行调整;,不然每次调整NI时候都要查看上一次的
PRI值防止优先级无限大,即使NI的范围都是-20到19,有些用户也可能会通过多次调整NI进行恶意破坏优先级
第四问
为什么NI值只有四十个级别:
保证各个进程之间相对来说比较公平,不至于某一个基础的优先级特别大,即OS的调度器要保证公平且高效
上一章