时间序列预测模型实战案例(五)基于双向LSTM横向搭配单向LSTM进行回归问题解决
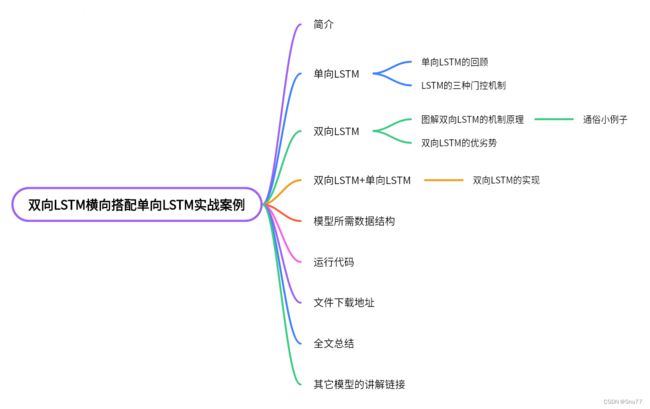
目录
简介
单向LSTM
单向LSTM的回顾
LSTM的三种门控机制
双向LSTM
图解双向LSTM的机制原理
通俗小例子
双向LSTM的优劣势
双向LSTM+单向LSTM
双向LSTM的实现
模型所需数据结构
模型代码
文件下载地址
全文总结
其它时间序列预测模型的讲解!
简介
在之前的文章中我们讲过单向的LSTM进行回归问题的解决,当时提到了双向LSTM但并没有过多的介绍,在这篇文章中我将通过数据集电力变压器油温数据详细的介绍双向LSTM,以及其机制,运行原理,以及如何横向搭配单向的LSTM进行回归问题的解决。
在本次实战案例当中主要分为几大部分,具体流程可看下面的文章结构图。
单向LSTM
单向LSTM的回顾
在开始学习单向的LSTM结构之前我们先来回顾一下单向的LSTM结构,这里我只是简单介绍如果想要详细了解可以观看我之前的文章。
----------------------------------------------------------------单向LSTM回顾-----------------------------------------------------------
时间序列预测模型实战案例(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
-----------------------------------------------------------------------------------------------------------------------------------------------
LSTM(长短期记忆,Long Short-Term Memory)是一种用于处理序列数据的深度学习模型,属于循环神经网络(RNN)的一种变体,其使用一种类似于搭桥术结构的RNN单元。同时相对于普通的RNN,LSTM引入了三种门控机制,能够更有效地处理长期依赖和短期记忆问题,其在处理序列数据时能够有效解决传统RNN所遇到的梯度消失或梯度爆炸的问题,是RNN网络中最常使用的Cell之一。
LSTM的三种门控机制
LSTM的三种门控机制:
-
输入门(Input Gate):输入门负责控制新输入信息对于细胞状态的更新程度。它通过使用sigmoid激活函数将输入信息进行筛选,决定哪些信息将会被记忆。
-
遗忘门(Forget Gate):遗忘门负责控制前一个时间步的细胞状态是否被遗忘,即决定了细胞状态中哪些信息将被保存下来。遗忘门通过使用sigmoid激活函数来确定需要被遗忘的信息,将其与前一个时间步的细胞状态相乘。
-
输出门(Output Gate):输出门根据当前的输入信息和细胞状态来计算当前时间步的隐藏状态。输出门通过使用sigmoid激活函数来决定细胞状态的哪些部分将被输出。然后,输出门的输出将与一个tanh激活的细胞状态相乘,得到当前时间步的隐藏状态。
通过这三种门控机制和相应的激活函数,LSTM能够有效地控制信息的流动和更新,从而解决了传统循环神经网络(RNN)中长期依赖问题。输入门和遗忘门允许选择性地更新和遗忘信息,输出门则根据当前的输入和细胞状态生成隐藏状态。这样,LSTM可以捕捉和利用时间序列中复杂的模式和依赖关系,从而更好地处理时间序列相关的任务。
双向LSTM
图解双向LSTM的机制原理
双向LSTM(Bidirectional LSTM)顾名思义就是有两个方向的单向LSTM,由正向和反向的单向LSTM组成,相对于传统的LSTM模型只考虑了当前时刻之前的上文信息,而双向LSTM则在此基础上引入了前向和后向两个方向的信息流,它们分别处理时间序列数据的正向和逆向顺序。
正向LSTM按照时间步的顺序处理数据,而反向LSTM按照时间步的逆序处理数据。这意味着它能够分别从序列的起始和结束位置捕捉到关键的上下文特征。这种前向-后向的结构使得双向LSTM更富有表达能力,能够更好地理解序列数据中的整体语义和信息流动。这样,模型可以从过去和未来时间步中获得更全面的上下文信息。
简单的双向LSTM示例图
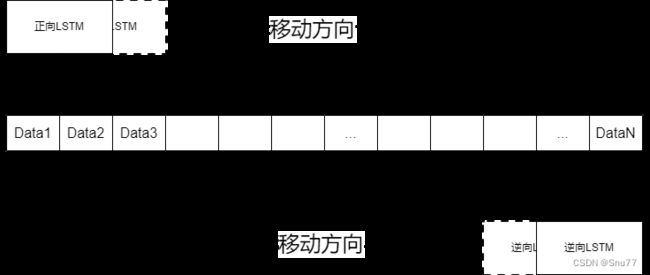
在正向LSTM中,当前时间步的输入信息会通过输入门、遗忘门和输出门的计算,更新当前时间步的细胞状态和隐藏状态。而在反向LSTM中,相应的计算会按照逆序进行。最后,正向和反向LSTM的隐藏状态会被连接在一起,形成双向LSTM的最终输出。
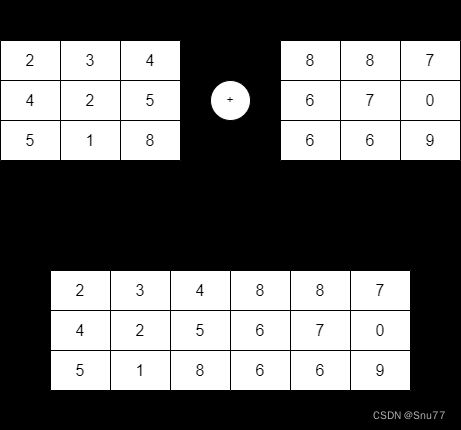
【PS:在其中正向和反向的LSTM结果进行拼接假设正向LSTM的隐藏状态为h_forward,维度是(batch_size, hidden_size),反向LSTM的隐藏状态为h_backward,也是(batch_size, hidden_size)。这两个隐藏状态会在每个时间步上进行拼接,得到最终连接后的隐藏状态h_concat,维度为(batch_size, 2 * hidden_size)具体过程可以看下图】
通过正向和反向的处理,双向LSTM能够同时考虑过去和未来时间步的信息,从而更好地捕捉时间序列中的长期依赖关系和模式。这对于许多任务,如语音识别、自然语言处理、股票预测等具有重要意义,因为这些任务中的当前输出往往取决于过去和未来的输入。
双向LSTM的设计使得模型可以在时间序列中双向地探索和学习信息,提高了模型的表达能力和预测准确性。
下面是一个简单的沿着时间展开的双向LSTM结构图
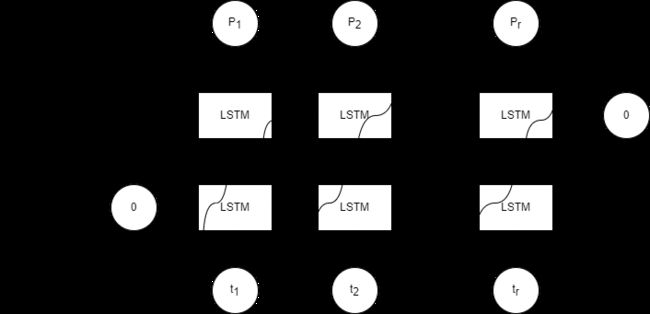
下图是一个在神经网络里的时序图,我们通过它来帮助大家来理解双向LSTM的工作流程
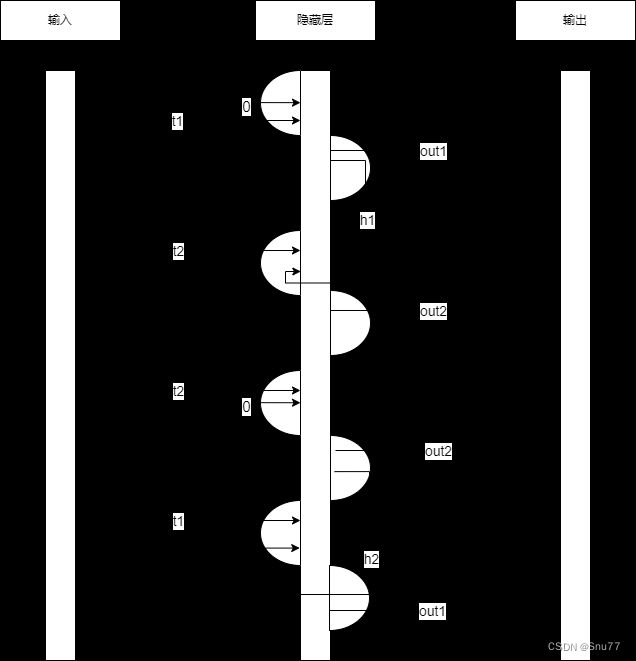
在按照时间序列正向运算之后,网络又从时间的最后一项反向的运算一遍,即把t2时刻的输入与默认值0一起反向生成out1。
通俗小例子
下面我们来通过一个生活中的通俗小例子来具体的了解一下双向LSTM的机制
当我们阅读一篇文章时,我们会按照自然的顺序逐句阅读,从头到尾理解整个故事。这个过程就可以用双向LSTM来解释。
假设我们正在阅读一篇小说,文中描述了一个人的一天。双向LSTM可以帮助我们更好地理解这个故事。
在这个例子中,前向LSTM会从文章的开头开始处理。它首先会读取到主人公早上起床的描写,了解他慢慢地从床上爬起来、穿衣、洗漱的情节。前向LSTM通过记忆和学习这些上文信息,掌握主人公早晨的状态和活动。
与此同时,后向LSTM会从文章的结尾开始处理。它会读取到主人公一天中最后的描述,例如他晚上入睡前的情景。后向LSTM通过逆序处理,了解主人公的一天是如何结束的,是否有什么特殊事件或感受。
最后,前向和后向的信息会在双向LSTM中合并。通过结合前向和后向处理的结果,双向LSTM能够更好地把握文章的整体情节和主人公的发展变化。它可以理解主人公从早上到晚上的起伏变化,捕捉到故事中的重要事件,以及人物之间的相互关系。
通过双向LSTM的处理,我们能够更全面、更深入地理解整个故事。它不仅关注文章的局部细节,还能够将上下文和时间的关联作为考量因素,帮助我们获得更准确和丰富的阅读体验。
这个例子展示了双向LSTM在阅读理解领域的应用。类似地,双向LSTM可以在其他时间序列,自然语言处理任务中帮助我们更好地理解和处理序列数据。
双向LSTM的优劣势
双向LSTM相较于传统的单向LSTM模型有以下几个优势:
1. 上下文信息捕捉:双向LSTM能够同时利用过去和未来的信息,分别通过前向和后向处理,从而更全面地捕捉到序列数据中的上下文信息。这使得模型能够更好地理解整个序列的语义和关联,对于语言理解和序列建模任务非常有益。
2. 预测性能提升:通过结合前向和后向处理的结果,双向LSTM能够提升预测性能。由于模型可以同时考虑到过去和未来的信息,它在预测任务中能够更好地理解序列数据的动态变化和趋势,提高了模型的准确性和泛化能力。
3. 抑制信息丢失:传统的单向LSTM在处理长序列时,可能会因为距离较远的上下文信息遗忘而导致信息丢失的问题。而双向LSTM能够通过前向和后向处理,避免了这样的问题,保留了更多有用的上下文信息,提高了模型对于远距离依赖关系的建模能力。
4. 特征表达丰富:双向LSTM通过前向和后向处理,可以获得丰富的特征表达。前向LSTM关注上文信息,抓住序列的局部模式和依赖关系;而后向LSTM关注下文信息,捕捉序列的整体趋势和全局上下文。结合两者的结果能够提供更丰富、更准确的特征表示,有助于模型更好地学习序列数据的特性。
总的来说,双向LSTM通过利用前向和后向的处理,增强了对序列数据的建模能力和表达能力。它能够更好地捕捉上下文信息、提升预测性能、抑制信息丢失,并且提供丰富的特征表达,使得在自然语言处理、时间序列分析等领域取得更好的结果。
尽管双向LSTM在处理序列数据方面具有很多优势,但也存在一些限制和缺点:
1. 计算成本高:由于双向LSTM需要同时运行前向和后向处理,它的计算成本比传统的单向LSTM更高。这是因为需要处理两次序列数据并合并结果,增加了模型的计算复杂度和训练时间。
2. 内存消耗大:在某些情况下,双向LSTM可能需要占用更多的内存空间。除了前向和后向的隐状态和记忆状态外,还需要额外存储两个方向的处理结果。这可能对内存资源造成限制,并增加模型的内存消耗。
3. 未来信息泄露:双向LSTM在训练时可以同时访问过去和未来的信息,但在实际应用中,模型只能使用已有的历史数据进行预测。这就意味着模型可能会从未来的信息中学习到某些特征,从而降低了模型对真实场景的泛化能力。
4. 序列长度限制:由于计算和内存的限制,双向LSTM在处理长序列数据时可能会受到限制。较长的序列可能导致模型的训练时间增加并消耗更多的内存资源。此外,较长的序列也可能会导致双向LSTM在建模远距离依赖关系时遇到困难。
5. 过拟合风险:在某些情况下,双向LSTM可能容易过拟合训练数据。由于模型的参数量较大,特别是在处理大规模数据集时,模型可能过度学习到训练数据的噪声或特定的局部模式,导致对新数据的泛化能力下降。
双向LSTM+单向LSTM
在上面回顾了单向LSTM并介绍了双向LSTM那么它们是如何组合在一起的?为什么组合在一起?
首先为什么要将双向LSTM和单向的LSTM进行横向连接呢?
在其中双向 LSTM 可以捕获时间序列中的前后依赖关系,而单向 LSTM 能够进行顺序建模。将两者横向连接后,模型可以同时学习到时间序列的前后信息以及动态变化,从而获得更丰富的序列表示。在某些情况下,双向 LSTM 可能对过去和未来的信息更敏感,而单向 LSTM 则专注于当前时刻之前的信息。将两者结合可以使模型在面对不同类型的时间序列时具有更好的适应性
双向LSTM和单向的LSTM是如何组合在一起?
双向LSTM和单向LSTM的连接并没有什么特殊的,就是将双向LSTM的输出输入到单向的LSTM层即可,
双向LSTM的实现
input_size = 10 # 输入特征的维度
hidden_size = 20 # 隐藏层神经元的数量
num_layers = 2 # LSTM 层的数量
batch_first = True # 输入和输出张量的形状是否以 batch_size 为第一维度
dropout = 0.5 # 多层 LSTM 之间的 dropout 概率
bidirectional = True # 是否使用双向 LSTM
lstm = nn.LSTM(input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=batch_first,
dropout=dropout,
bidirectional=bidirectional)下面我们通过举例的形式来了解每个参数的含义:假设我们有一个时间序列数据集,包含了过去一段时间内的股票价格。我们的目标是使用双向 LSTM 预测未来的股票价格。以下是针对这个例子的每个参数的详细解释:
1. `input_size`(int):在这个例子中,`input_size` 可能取决于我们使用的特征数量。例如,如果我们仅使用历史股票价格(即单变量时间序列),那么 `input_size` 为 1。如果我们还使用其他特征,如交易量、市值等,则 `input_size` 等于特征数量。
2. `hidden_size`(int):这是 LSTM 隐藏层神经元的数量。较大的 `hidden_size` 可能有助于捕捉更复杂的时间序列模式,但可能导致过拟合和更长的训练时间。例如,我们可以设置 `hidden_size` 为 64 或 128,具体取决于问题的复杂性和可用计算资源。
3. `num_layers`(int):这是堆叠的 LSTM 层数。在时间序列预测中,可能需要多层 LSTM 来捕捉更复杂的模式。例如,我们可以设置 `num_layers` 为 2 或 3,具体取决于问题的复杂性。
4. `batch_first`(bool):这个参数确定输入和输出张量的形状。对于时间序列预测问题,我们通常将 `batch_first` 设置为 `True`,这样输入和输出张量的形状为 (batch_size, seq_length, input_size) 和 (batch_size, seq_length, hidden_size * num_directions)。例如,如果我们有一个批次大小为 32 的数据集,时间序列长度为 50(即过去 50 个时间点的数据),则输入张量的形状为 (32, 50, 1)(假设我们只使用单变量时间序列)。
5. `dropout`(float):在多层 LSTM 之间应用的 dropout 概率。这有助于防止过拟合。例如,可以设置 `dropout` 为 0.5,表示在每个 LSTM 层之间应用 50% 的 dropout 概率。
6. `bidirectional`(bool):是否使用双向 LSTM。
模型所需数据结构
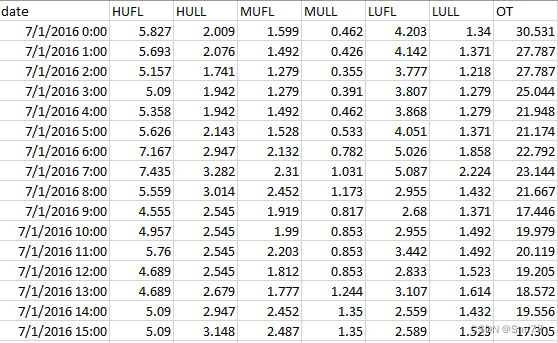
在本次的模型所需的数据是电力变压器油温数据,由国家电网提供,该数据集是来自中国同一个省的两个不同县的变压器数据,时间跨度为2年,原始数据每分钟记录一次(用 m 标记),每个数据集包含2年 * 365天 * 24小时 * 60分钟 = 1,051,200数据点。
每个数据点均包含8维特征,包括数据点记录日期,预测目标值OT(oil temperature)和6个不同类型功率负载特征。
(PS:如果你使用你自己的数据进行预测需要将时间列和官方数据集保持一致,因为在数据处理部分我添加了一部分特征工程操作,提取了一些时间信息,因为LSTM不支持时间格式的数据输入,需要转化为数字)
模型代码
(PS:以下代码仅仅是一个简单的实现版本,并没有涉及到什么复杂的模型,适合初学者进行一个学习,本文的双向LSTM搭配单向LSTM进行时间序列处理仅仅是一个创意和想法)
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader, TensorDataset
import torch
import torch.nn as nn
from sklearn.preprocessing import StandardScaler
import torch.nn.functional as F
def create_sliding_window_data(data, input_window, output_window, output_column):
X, y = [], []
for i in range(len(data) - input_window - output_window + 1):
X.append(data[i:i + input_window])
y.append(data[i + input_window:i + input_window + output_window, output_column])
return np.array(X), np.array(y)
# 读取 CSV 文件
data = pd.read_csv('ETTh1.csv')
# 数据预处理
# 特征工程
data['date'] = pd.to_datetime(data['date'])
data['year'] = data['date'].dt.year
data['month'] = data['date'].dt.month
data['day'] = data['date'].dt.day
data['hour'] = data['date'].dt.hour
data.drop('date', axis=1, inplace=True)
# 参数设置
input_window = 126
output_window = 1
output_column = 1
test_ratio = 0.2
# 划分训练集和测试集
data_len = len(data)
test_size = int(data_len * test_ratio)
X_train, X_test = data[:-test_size], data[-test_size:]
feature_data = X_train[['OT']]
feature_test_data = X_test[['OT']].reset_index(drop=True)
# 数据归一化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
feature_scaler = StandardScaler()
feature = feature_scaler.fit_transform(feature_test_data)
# feature_test = feature_scaler.transform(feature_test_data)
# 创建滑动窗口数据
X_train_sliding, y_train_sliding = create_sliding_window_data(X_train, input_window, output_window, output_column)
X_test_sliding, y_test_sliding = create_sliding_window_data(X_test, input_window, output_window, output_column)
# 转换为 PyTorch 张量
X_train_tensor = torch.tensor(X_train_sliding, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train_sliding, dtype=torch.float32)
X_test_tensor = torch.tensor(X_test_sliding, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test_sliding, dtype=torch.float32)
# 创建数据加载器
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 定义模型
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, bidirectional):
super(LSTMModel, self).__init__()
self.bidirectional_lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, bidirectional=bidirectional)
self.unidirectional_lstm = nn.LSTM(hidden_size * (2 if bidirectional else 1), hidden_size, num_layers, batch_first=True, bidirectional=False)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# Pass the input through the bidirectional LSTM
out_bidirectional, _ = self.bidirectional_lstm(x)
# Pass the output of the bidirectional LSTM through the unidirectional LSTM
out_unidirectional, _ = self.unidirectional_lstm(out_bidirectional)
# Apply ReLU activation on the output of the unidirectional LSTM
out = F.relu(out_unidirectional[:, -1, :])
# Pass the activated output through the fully connected layer
out = self.fc(out)
return out
# 初始化模型、优化器和损失函数
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
input_size = X_train.shape[1]
hidden_size = 64
num_layers = 2
output_size = output_window
bidirectional = True
model = LSTMModel(input_size, hidden_size, num_layers, output_size, bidirectional).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.005)
criterion = nn.MSELoss()
losses = []
# 训练模型
num_epochs = 50
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for inputs, targets in train_loader:
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs).squeeze()
loss = criterion(outputs, targets.squeeze())
loss.backward()
optimizer.step()
running_loss += loss.item()
losses.append(loss.item())
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {running_loss/len(train_loader)}')
results = []
plt.figure()
plt.plot(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.savefig('lossPhoto')
# 滑窗预测
model.eval()
with torch.no_grad():
X_test_tensor = X_test_tensor.to(device)
predictions = model(X_test_tensor).squeeze().cpu().numpy()
# print(results)
predictions = feature_scaler.inverse_transform(predictions.reshape(1, -1)).tolist()[0]
# results.append(predictions)
print(predictions)
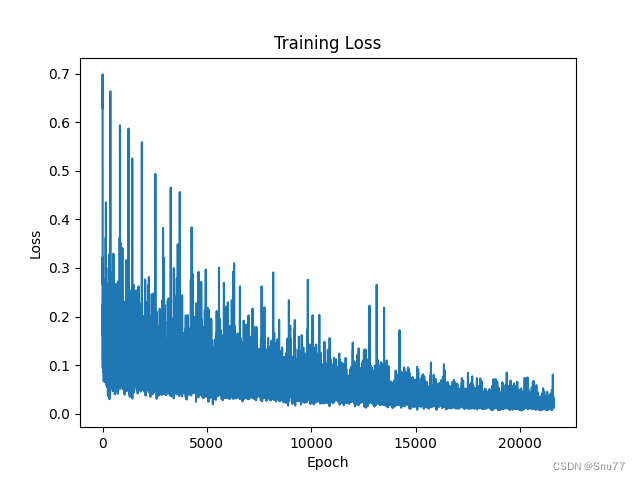
我们先来看训练损失epoch次数为50
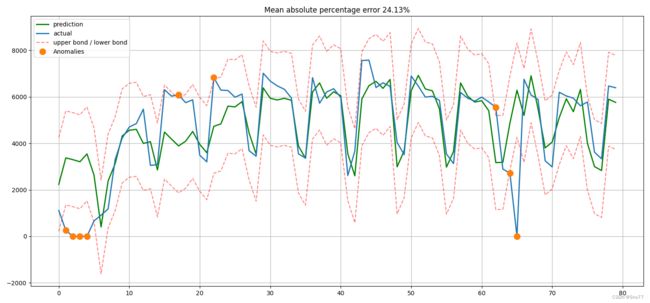
通过以上代码处理数据这里的(数据用的并不是油温的数据图)之后我们得到预测值和分析值之间的一个对比大家可以看出预测的效果,在高级的双向LSTM算法中,我提供了一些绘图的功能,其中的圆点标注了一些异常值点,还有上边界和下边界的范围。
文件下载地址
我提供了一个简单运行代码版本文件以及所需数据全部打包为zip文件放到了以下地址大家有需要的可以自行下载!(大家如果需要复杂的版本可以评论区留言)
时间序列预测模型实战案例基于双向LSTM横向搭配合单向LSTM进行回归问题的解决
全文总结
双向的LSTM横向配合单向的LSTM可以算作为一次尝试,其在时间预测方面可能效果不一定会好(具体针对于你自己的数据),但是在其他一些文本分析的方面表现应该会很好,LSTM作为最常用的RNN结构单元,其依靠自身的门机制在许多领域应用方面都取得了良好的效果,其能搭配的其它方法也很多,大家可以自己进行尝试后期我也会进行更多的讲解。
后期我也会讲一些最新的预测模型包括Informer,TPA-LSTM,ARIMA,Attention-LSTM,LSTM-Xgboost,移动平均法,加权移动平均,指数平滑等等一系列关于时间序列预测的模型,包括深度学习和机器学习方向的模型我都会讲,你可以根据需求选取适合你自己的模型进行预测,如果有需要可以+个关注,文章最后放一个投票连接针对于下一次的模型讲解进行投票!!
其它时间序列预测模型的讲解!
-----------------------------------------------------------------Xgboost-机器学习------------------------------------------------------
时间序列预测模型实战案例(四)(Xgboost)(Python)(机器学习)图解机制原理实现时间序列预测和分类(附一键运行代码资源下载和代码讲解)
-----------------------------------------------------------------LSTM-深度学习---------------------------------------------------------
时间序列预测模型实战案例(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
----------------------------------------------------------------MTS-Mixers---------------------------------------------------------------
【全网首发】(MTS-Mixers)(Python)(Pytorch)最新由华为发布的时间序列预测模型实战案例(一)(包括代码讲解)实现企业级预测精度包括官方代码BUG修复Transform模型
--------------------------------------------------------------Holt-Winters----------------------------------------------------------------
时间序列预测模型实战案例(二)(Holt-Winter)(Python)结合K-折交叉验证进行时间序列预测实现企业级预测精度(包括运行代码以及代码讲解)
如果大家有不懂的也可以评论区留言一些报错什么的大家可以讨论讨论看到我也会给大家解答如何解决!