docker namespaces详解
首先我们先理解一下虚拟化隔离的实际应用场景
就是在一台电脑上运行两个完全相同的程序,但是这两个之间没有冲突。比如说我们如果在同一台机器上启动Nginx的时候,第二个就会启动失败,因为会报一个端口被占用的错误。
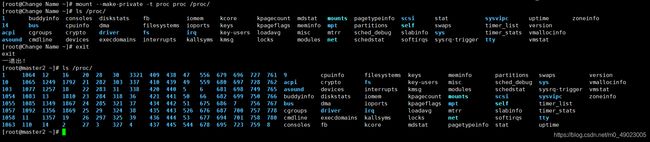
先理解一下Linux的proc目录,这个目录是伪文件系统,我们Linux下有两个伪文件系统,一个是proc,一个是sys,sys目录下是系统下的,proc下装的是内存下的。这里我们着重分析proc这个目录,随便打开一下系统ls查看一下这个目录

那些数字其实就是进程的pid编号。随便进入到一个目录下,查看里面的ns目录,不明思议其实就是namespace的缩写
[root@master1 ns]# ls
ipc mnt net pid user uts
[root@master1 ns]#
[root@master1 ns]# ls -al
总用量 0
dr-x--x--x 2 root root 0 6月 27 20:49 .
dr-xr-xr-x 9 root root 0 6月 27 14:18 ..
lrwxrwxrwx 1 root root 0 6月 27 20:49 ipc -> ipc:[4026531839]
lrwxrwxrwx 1 root root 0 6月 27 20:49 mnt -> mnt:[4026531840]
lrwxrwxrwx 1 root root 0 6月 27 20:49 net -> net:[4026531956]
lrwxrwxrwx 1 root root 0 6月 27 20:49 pid -> pid:[4026531836]
lrwxrwxrwx 1 root root 0 6月 27 20:49 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 6月 27 20:49 uts -> uts:[4026531838]
[root@master1 ns]# 那些4026531xxx就是namespace的编号。。。。
要想实现隔离的话,我们采用的是编号的方式进行隔离,如果两个进程的namespace的编号是相等的,那么证明在同一个namespace下,证明有冲突,不会隔离。
这里我们再看一个进程编号里面的ns
[root@master1 ns]# ls -al ../../32/ns/
总用量 0
dr-x--x--x 2 root root 0 6月 27 20:53 .
dr-xr-xr-x 9 root root 0 6月 27 14:18 ..
lrwxrwxrwx 1 root root 0 6月 27 20:53 ipc -> ipc:[4026531839]
lrwxrwxrwx 1 root root 0 6月 27 20:53 mnt -> mnt:[4026531842]
lrwxrwxrwx 1 root root 0 6月 27 20:53 net -> net:[4026531956]
lrwxrwxrwx 1 root root 0 6月 27 20:53 pid -> pid:[4026531836]
lrwxrwxrwx 1 root root 0 6月 27 20:53 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 6月 27 20:53 uts -> uts:[4026531838]
[root@master1 ns]#跟上面的那个进程比较,发现ipc,net,pid等等都在同一个namespace下,则可能发生冲突,mnt不在同一个namespace下,则表示不会发生冲突,就产生隔离。
需要注意的是,只有这几项都不相同,则两个进程可以产生隔离,不然就只是隔离其中的某个项。
现在介绍一下这几项在内核中的解释:

总结:隔离的方式也很简单,就是通过namespace编号。。。
下面演示各个隔离的实现
我们的全程演示原生的代码如下:test.c
#define _GNU_SOURCE
#include
#include
#include
#include
#include
#define STACK_SIZE (1024 * 1024)
static char child_stack[STACK_SIZE];
char* const child_args[] = {
"/bin/bash",
NULL
};
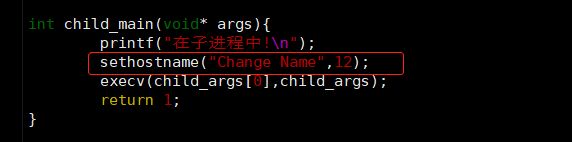
int child_main(void* args){
printf("在子进程中!\n");
execv(child_args[0],child_args);
return 1;
}
int main(){
printf("程序开始: \n");
int child_pid = clone(child_main,child_stack + STACK_SIZE, SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
printf("已退出!\n");
return 0;
} 分析:这个代码的主要的作用是在当前的shell下再开启一个子进程,而这个子进程也是以shell的方式,那么意味着我们开启了两个相同的shell。同时在使用的过程中fork子进程的方法是通过clone,clone是继承父进程,它有很多的调用子进程的方法。

我们等会测试要改的就是clone那个地方。
我先直接测试一下,看代码有没有错误,通过ps命令也能看出父子进程的关系


补充:父进程在系统的pid比子进程要大1(16219比16220大)
现在我们退出子进程,因为两个进程空间的shell的hostname都是一样的,所以看不出来,我们exit退出即可
[root@master1 ~]# exit
exit
已退出!
[root@master1 ~]#这里我们模拟的是开了两个空间,一个空间是本身的shell,另外一个是我们新打开的shell,那么这两个空间能用什么方法让他们彻底隔离开来呢,这就是我们接下来要试验的。
注意:接下来的试验都是在clone那个函数里面加对应的参数即可。。。
为了区别父子进程,我们给子进程设置一个别名,在下面的地方加代码:
实验一:隔离UTS
直接在clone加CLONE_NEWUTS这个参数,
int child_pid = clone(child_main,child_stack + STACK_SIZE, CLONE_NEWUTS | SIGCHLD, NULL);然后执行
[root@master2 ~]# gcc -Wall test.c -o uts.o
[root@master2 ~]# ./uts.o
程序开始:
在子进程中!
[root@Change Name ~]# hostname
Change Name
[root@Change Name ~]# exit
exit
已退出!
[root@master2 ~]# hostname
master2
[root@master2 ~]# 实验二:隔离IPC
int child_pid = clone(child_main,child_stack + STACK_SIZE, CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);这里我们先在物理机上安装一个Apache服务,然后启动它,yum install httpd -y ,systemctl start httpd

上面是通过Apache服务创建的消息列队,我们也可以自己手动创建消息列队,
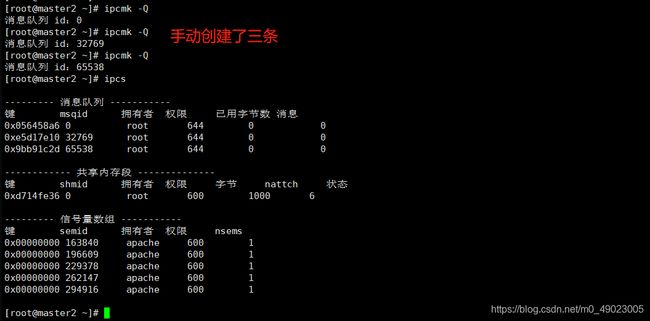
我们在试验的过程中也可以看一下/proc/[PID]/ns/目录下的各个namespace编号

试验三:PID隔离--------CLONE_NEWPID
这个比较重要
PID有个特殊的地方,就是每一个PID的namespace中的第一个进程的PID都要等于1,1号进程一定是巨头特殊权限的进程。
int child_pid = clone(child_main,child_stack + STACK_SIZE, CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);[root@master2 ~]# gcc -Wall test.c -o pid.o
[root@master2 ~]# ./pid.o
程序开始:
在子进程中!
[root@Change Name ~]# echo $$ ##### $$是脚本运行的当前进程ID号
1
[root@Change Name ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.2 125504 4012 ? Ss 20:41 0:01 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 0.0 0.0 0 0 ? S 20:41 0:00 [kthreadd]
root 4 0.0 0.0 0 0 ? S< 20:41 0:00 [kworker/0:0H]
root 6 0.0 0.0 0 0 ? S 20:41 0:00 [ksoftirqd/0]
root 7 0.0 0.0 0 0 ? S 20:41 0:00 [migration/0]
root 8 0.0 0.0 0 0 ? S 20:41 0:00 [rcu_bh]
root 9 0.0 0.0 0 0 ? S 20:41 0:00 [rcu_sched]
root 10 0.0 0.0 0 0 ? S< 20:41 0:00 [lru-add-drain]
root 11 0.0 0.0 0 0 ? S 20:41 0:00 [watchdog/0]
root 12 0.0 0.0 0 0 ? S 20:41 0:00 [watchdog/1]
root 13 0.0 0.0 0 0 ? S 20:41 0:00 [migration/1]
root 14 0.0 0.0 0 0 ? S 20:41 0:00 [ksoftirqd/1]
...........虽然当前的进程号是1,但是我们ps aux看到的却是宿主机上所有的进程。这样就不对了,解释一下,虽然我们的pid编号改变了,但是proc目录没有被改变,我们ps aux查看到的是proc目录里面的内容。

这样其实是不合理的,虽然我们pid编号重新编排,从1开始,但是proc目录出错了,有很大的隐患。
那么如何解决这个问题呢,接下来我们就要学习mnt隔离,文件系统隔离可以帮我们实现。
实验四:mnt隔离------CLONE_NEWMNT
前言:我们进行PID测试的时候发现,我们的子进程的proc目录和我们的父进程的proc目录是完全一样的,这样导致我们在子进程中ps aux能看到的跟父进程一模一样,这样就会导致我们的不同的主机的内容如果内存读的内容是相同的,那么就会出现我们互相影响的状态。接下来我们要做的就是隔离proc目录
我们通过上面的几个测试得知,一般就是在clone添加宏值即可,如下的

这里我们试一下,通过加CLONE_NEWNS看看可不可以
int child_pid = clone(child_main,child_stack + STACK_SIZE, CLONE_NEWNS| CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);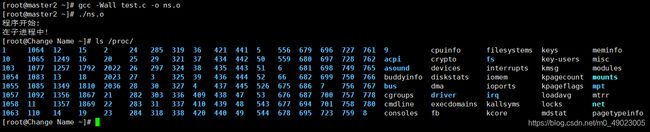
哎,然而并没有什么用处啊,这是怎么回事呢?
虽然我们用这种方式无法隔离,但是还有一种方式,继续在文件系统上进行隔离,主要靠的是mount来进行隔离。
先看看mount的man手册,搜索share这个关键字
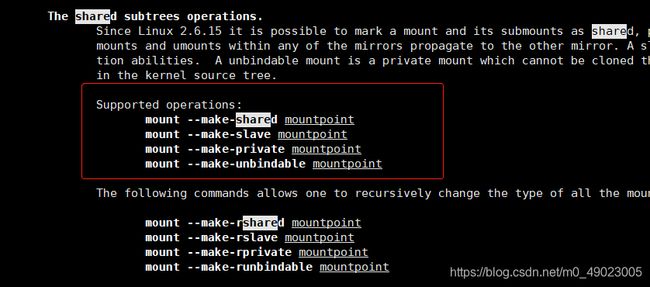
默认我们使用挂载,它有这几个选项(默认的挂载方式是share)
mount --make-shared mountpoint //共享的
mount --make-slave mountpoint //跟我们的master端对应
mount --make-private mountpoint //私有的
mount --make-unbindable mountpoint //不可以绑定的上面的意思表示传播方向,即数据可以传播哪一端的意思。

共享挂载:为了文件数据的共享。
从属挂载(slave):更大的意义在于某些只读的场景。
私有挂载:只是单纯的隔离,即两个目录里面名字相同,但是里面的数据是不相同的。
不可以绑定挂载:有效的防止没有必要的文件被拷贝。
好了,我们现在在子进程中使用私有挂载的参数来挂载proc目录

[root@Change Name ~]# ps -aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 115676 2188 pts/0 S 21:06 0:00 /bin/bash
root 73 0.0 0.0 155472 1856 pts/0 R+ 21:29 0:00 ps -aux子进程中已经看不到父进程的相关信息了,但是我们退出子进程,在父进程上看看我们的proc目录,发现出问题了。

我们的父进程受影响了。
这里我们需要一个在父进程中重新挂载一下,即可恢复正常

然后在去子进程中执行挂载命令,也就是说,正确的操作应该是在子进程中执行mount命令之前,必须先把父进程的proc目录挂载了。
实验五:network隔离
网络隔离是唯一一个跟我们之前的隔离相反的,它不在我们的程序内进行隔离,而是需要自己独立创建一个空间来进行隔离的。这个独立空间叫做我们namespace中独立的设备。
我们知道,创建容器相当于创建一个空间,在物理机上创建了一个空间,容器内又创建了一个空间,要想把这两个空间链接在一起,这个就叫做网络隔离。
通过ip netns add命令可以增加一个网络空间
[root@master2 ~]# ip netns add test_ns
[root@master2 ~]# ip netns
test_ns
[root@master2 ~]# ip netns exec test_ns ip link ls //这个是进入到test_ns这个网络空间中执行ip link ls 命令
1: lo: mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
[root@master2 ~]# 注意:
1. ip netns exec 进入的网络空间里面一些网络命令是跟宿主机同步的,也就说说我们想要用到什么命令,直接在宿主机安装相应安装包即可。
2. 关于网络空间的存储路径,我们ip netns 查找的路径是宿主机 /var/run/netns,而我们docker创建的网络空间存储在 /var/run/docker/netns/下,我们想要使用命令ip netns进去操作的话,只需要挂载 ln -s /var/run/docker/netns/ /var/run/netns。
新创建的网络空间test_ns的状态是down,这个时候是无法ping 通127.0.0.1
[root@master2 ~]# ip netns exec test_ns ping 127.0.0.1
connect: 网络不可达要是127.0.0.1可以通的话,那么证明可以完成osi七层模型的封装,到解封装的过程。我们需要打开它,才能完成osi七层的。
[root@master2 ~]# ip netns exec test_ns ip link set dev lo up
[root@master2 ~]# ip netns exec test_ns ip link ls
1: lo: mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
[root@master2 ~]# ip netns exec test_ns ping 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.024 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.027 ms
64 bytes from 127.0.0.1: icmp_seq=3 ttl=64 time=0.026 ms
64 bytes from 127.0.0.1: icmp_seq=4 ttl=64 time=0.032 ms
^C
--- 127.0.0.1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 2999ms
rtt min/avg/max/mdev = 0.024/0.027/0.032/0.004 ms
[root@master2 ~]# 能完成osi七层模型的封装,接下来就需要把这个网络空间(test_ns)和我们当前的连接在一起。
这个连接的东西叫做veth pair网卡
[root@master2 ~]# ip link add veth0 type veth peer name veth1分析:type后面接类型,这里就是veth
对端的类型是peer,名字叫做veth1
这里我们创建了两块网卡,然后是相连的。
4: veth1@veth0: mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 56:bb:b8:78:c4:8b brd ff:ff:ff:ff:ff:ff
5: veth0@veth1: mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 9a:af:16:58:32:3c brd ff:ff:ff:ff:ff:ff 两块网卡相连是通过@符号来表示,上面的就是有一端网卡veth1连到了veth0,有一端网卡veth0连这个veth1。。。前面的数字表示全局编号,为了避免大家在不同的空间内使用不同的网卡名,我们要有唯一的编号才能区分开来谁是谁,前面的数字编号也叫做interface ID。
但是上面的两块网卡(这里用数字4和5代表了)都在物理机上,我们只需要把其中一块放到另外的一个空间里即可

查看我们网络空间test_ns里面的网卡,发现我们的4号网卡在里面了
[root@master2 ~]# ip netns exec test_ns ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
4: veth1@if5: mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 56:bb:b8:78:c4:8b brd ff:ff:ff:ff:ff:ff link-netnsid 0
[root@master2 ~]# 由于跨了空间,只能通过编号来显示了,即veth0@if4和veth1@if5
现在我们给我们test_ns空间里面的网卡配个ip
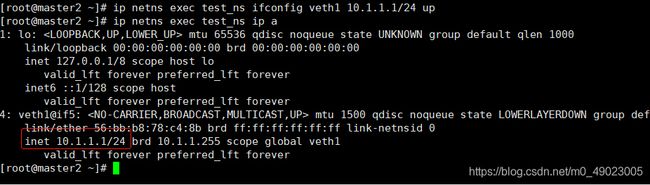
然后给物理机也配个ip,然后互相ping一下
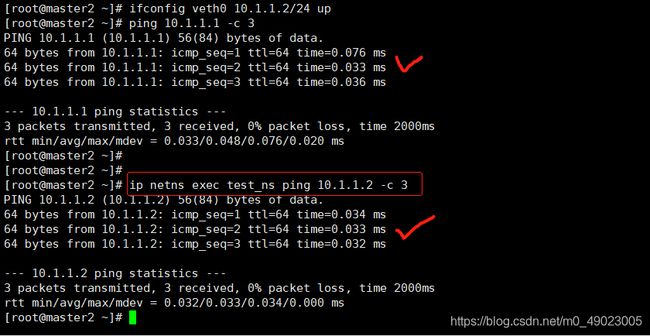
当然不只是网络隔离了,协议栈,防火墙等跟网路相关的都隔离了。
参考资料:《Docker 容器与容器云(第2版)》