医学分析专业名词解释
甲基化:
真核生物基因表达受多种机制、多层面的综合调控。基因的DNA序列不发生改变的情况下,基因的表达水平与功能发生改变,并可遗传现象,称为表观遗传(epigenetic)现象。
表观遗传学:调控机体基因表达的最重要途径之一。
表观遗传学的调节机制主要包括DNA甲基化、组蛋白修饰、非编码RNA作用等多种形式,其中,DNA甲基化是目前研究的比较清楚的表观遗传修饰方式。DNA高度甲基化首先会影响DNA结构,进而阻遏基因转录,引起基因沉默。
DNA甲基化与基因表达调控
DNA甲基化为非编码区(如内含子等)的长期沉默提供了一种有效的抑制机制。基因启动区域内CpG位点的甲基化通过三种方式影响基因转录活性:DNA序列甲基化直接阻碍转录因子的结合;甲基CpG结合蛋白结合到甲基化CpG位点与其他转录抑制因子相互作用;染色质结构的凝集阻碍了转录因子与其调控序列的结合。
DNA甲基化与肿瘤发生
肿瘤中普遍存在DNA甲基化状态的改变,其特点是总体甲基化水平的降低与局部甲基化水平的升高。在肿瘤细胞中,癌基因处于低甲基化状态而被激活,抑癌基因处于高甲基化状态而被抑制。
RNA甲基化修饰
mRNA的内部修饰则用于维持mRNA的稳定性。一旦参与m6A修饰的酶出现异常将会引起一系列疾病,包括肿瘤、神经性疾病、胚胎发育迟缓等。
已知绝大部分真核生物中,mRNA在5’ Cap处存在甲基化修饰,作用包括维持mRNA稳定性、mRNA前体剪切、多腺苷酸化、mRNA运输与翻译起始等。而3’ polyA发生的修饰有助于出核转运、翻译起始以及与polyA结合蛋白一起维持mRNA的结构稳定。
但是这些修饰只发生mRNA的头部和尾部,关于RNA的内部修饰(internal modification)在许多种类的RNA中都有发生。无论是mRNA还是lncRNA,都大量存在m6A修饰。m6A能够加速mRNA前体的加工时间,加快mRNA在细胞中的转运速度和出核速度。
什么叫m6A修饰
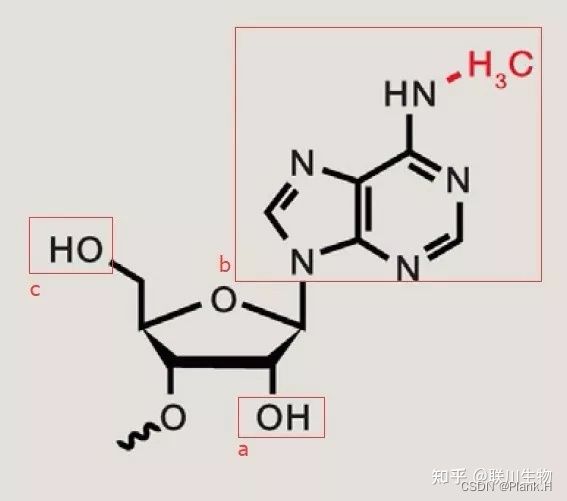
从图中我们可以看到,这是一个已经发生甲基化的核糖核苷酸,确切地说叫N6-methyladenosine。左下角的是五碳糖,图中a框部分也就是五碳糖的第二位C处的羟基发生脱氧就会变成脱氧核糖核苷酸(从RNA变成DNA)。图中c框部分标注的,也就是第四位的C处通常会带有磷酸基,如果此处带有2个磷酸基团那么就叫ADP,如果带有3个磷酸基团那就是大名鼎鼎的ATP了。图中b框部分通常就是我们所说的含氮碱基。这里特指腺苷酸(A),当腺苷酸的第六位N处发生甲基化时,就是我们所说的m6A。
肿瘤免疫微环境(TIME)
肿瘤免疫微环境(Tumor immune microenvironment)是指肿瘤细胞存在的周围微环境,包括周围的血管、免疫细胞、成纤维细胞、骨髓源性炎性细胞、各种信号分子和细胞外基质。肿瘤和周围环境密切相关,不断进行交互作用,肿瘤可以通过释放细胞信号分子影响其微环境,促进肿瘤的血管生成和诱导免疫耐受,而微环境中的免疫细胞可影响癌细胞增长和发育。
对于免疫微环境有一个流行的学说——“种子与土壤”学说,肿瘤的发生发展是肿瘤细胞与其微环境相互影响、共同进化的结果。肿瘤微环境由不同种类的间质细胞和炎性介质以及细胞外基质(ECM)组成。其中肿瘤相关成纤维细胞是最主要的间质细胞;血管内皮细胞介导的血管新生为肿瘤生长和转移提供必需的营养;免疫浸润包括树突状细胞、巨噬细胞、NK细胞及不同亚型的T细胞等等。肿瘤相关巨噬细胞与肿瘤细胞可以通过分泌特殊的细胞因子形成正反馈循环促进肿瘤恶性表型的形成和维持。肿瘤微环境在肿瘤恶性进展、免疫逃逸和治疗抵抗中发挥重要作用。
肿瘤细胞和基质成分之间相互作用,形成了功能复杂的TIME。肿瘤相关成纤维细胞(CAFs)主要分布于血管周围或肿瘤外周纤维间质内,分泌细胞因子、ECM成分*(细胞外基质(ECM)是组成间质和上皮血管中基质的不溶性结构成分,主要有胶原蛋白、弹性蛋白、蛋白多糖和糖蛋白等。研究表明, ECM可影响细胞分化、增殖、黏附、形态发生和表型表达等生物学过程。)及相关酶分子。TIME中有多种免疫浸润细胞,其中CD8+或细胞毒性T淋巴细胞(CTL)发挥肿瘤杀伤功能,而调节型T细胞(Treg细胞是淋巴细胞的主要组分,它具有多种生物学功能,如直接杀伤靶细胞,辅助或抑制B细胞产生抗体,对特异性抗原和 促有丝分裂原 的应答反应以及产生 细胞因子 等,是身体中为抵御疾病感染、肿瘤而形成的英勇斗士。)减弱T细胞活性,促进TIME免疫抑制。一般M1型巨噬细胞发挥促炎和抗瘤作用,但TIME中的肿瘤相关巨噬细胞(TAM)为M2型,通过分泌Th2细胞因子促进血管生成和肿瘤侵袭。我们所熟知的NK细胞会释放颗粒酶和穿孔素杀伤靶细胞,但在TIME中富集的TGF-β会抑制其杀伤活性。而树突状细胞(DC调节对当前环境刺激的先天和后天免疫反应。 它的其中一个最重要的功能就是将抗原处理后展示给免疫系统的其他白细胞,故是一种抗原呈递细胞。)也*会受到TME中的缺氧和炎症影响消弱其抗原呈递活性。基质细胞类型和富集程度决定了TIME特性,进一步影响着肿瘤进展和免疫应答情况。
TIME的异质性使得个体间肿瘤进展存在很大差异;肿瘤的免疫微环境一般分为豁免型和炎症型。炎症型肿瘤微环境中富集有活化的T细胞和髓系细胞,并由趋化因子、I型干扰素信号表达。相反“冷肿瘤”,既是免疫豁免型TIME中,仅存在少量免疫细胞或抑制性亚群,如Treg、MDSC和TAM,而效应型免疫细胞无法有效浸润至肿瘤微环境。仅分布在外周基质,难以发挥抑癌作用。
肿瘤微环境是肿瘤细胞所处的细胞环境,其组成包括细胞外基质、可溶性分子和肿瘤基质细胞。肿瘤微环境一旦形成,众多面会议细胞,如T细胞、髓源抑制细胞、巨噬细胞等,都被催化至此,构成肿瘤的微环境。
在肿瘤微环境中,免疫细胞和基质细胞是两种主要类型的非肿瘤组分,并且已被提出对于肿瘤的诊断和预后评估具有价值的。
肿瘤微环境细胞和肿瘤中浸润免疫和基质细胞的程度对预后有显着贡献,在肿瘤微环境中,免疫和基质细胞是两种主要类型的非肿瘤组分,并且已被提出对于肿瘤的诊断和预后评估是有价值的;
基于ESTIMATE算法计算的免疫评分和基质评分可以促进肿瘤中免疫和基质成分的定量;在该算法中,通过分析免疫和基质细胞的特定基因表达特征来计算免疫和基质评分以预测非肿瘤细胞的浸润。
单因素Cox回归
取某一自变量系数为e的幂数,得到的值即为HR值。考虑HR值在临床研究中的实际意义,则当系数大于0(HR>1)时,该自变量为危险因素;当系数小于0(HR<1)时,该自变量为保护因素。
多因素Cox回归
pValue<0.05代表能作为独立预后因子
LASSO回归
约束参数防止过度拟合,达到筛选重要特征的作用
生存分析
情形1:只记录三年后两组患者的病发情况,检验不同药物对于病发情况是否存在显著差异。
显然,卡方检验即可实现这一研究目标。但该实验本身存在一个巨大缺陷——没有考虑患者的病发时间这一变量。
情形2:只记录两组患者在三年内的病发时间(此时假设所有患者在观察期内均会病发),检验不同药物对于病发时间是否存在显著差异。
同样,使用Wilcox秩和检验可完成这一比较分析。但该实验同样存在问题,即病发情况过于理想了,所有患者不一定会在三年内病发。
情形3:同时记录两者患者在三年内的病发情况和病发时间(未病发则时间记录为三年),考虑药物对于病发情况和病发时间的综合影响。
现在来看,使用卡方检验或Wilcox秩和检验就不太适合了,而生存分析则是实现这一研究目标的首选方法。
此外,在对患者的随访调查中,很大概率存在失访的现象,在这种情形下,如何正确处理失访数据则显得尤为重要。而生存分析不仅没有将失访数据直接剔除,反而最大程度上利用了失访者的已有随访时间(生存时间),使得研究结果更可靠。
知识点补充:
生存资料:包含结局变量,时间变量和因素变量,分别指结局发生情况(如病发,死亡等)、结局未发生前的随访时间以及待检验因素。
在临床研究中,结局变量通常为二值型变量,包括结局发生和删失两种情况。
删失值:若在指定随访期限内未观察到结局发生,则该类数据均被认为是删失值。数据删失包含以下三种情况:中途失访、实验范围外结局发生(如意外死亡)、结局最终未发生。
Kaplan-Meier 生存概率估计法
作为一种非参数估计法,KM方法本质上是往期生存概率的不断累乘,其核算公式如下:

通过KM估计法,我们就可以求得生存曲线上对应时间点的生存概率
根据KM估计法求得生存概率后,我们只需要找到当生存概率为50%所对应的时间点,该点值即为中位生存时间。
Log-Rank检验法
Log-Rank检验法可用于比较不同组别生存曲线或生存函数,从而确定某一待检验因素对于事件结局的发生情况是否存在显著影响。
风险概率:在指定时间点tn尚未发生事件结局情况下,在该时间点事件发生的概率。

累积风险概率:从初始时刻到t的风险概率的累积,与生存概率概念相反。

NMF非负矩阵分解算法(Non-negative Matrix Factorization)
NMF的基本思想可以简单描述为:对于任意给定的一个非负矩阵V,NMF算法能够寻找到一个非负矩阵W和一个非负矩阵H,使得满足 ,从而将一个非负的矩阵分解为左右两个非负矩阵的乘积。如下图所示,其中要求分解后的矩阵H和W都必须是非负矩阵。
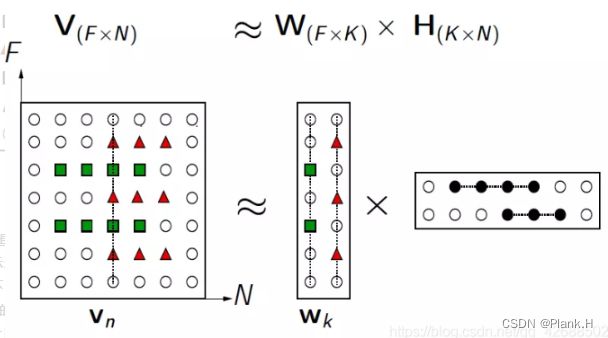
原矩阵V中的一列向量可以解释为对左矩阵W中所有列向量(称为基向量)的加权和,而权重系数为右矩阵H中对应列向量中的元素。这种基于基向量组合的表示形式具有很直观的语义解释,它反映了人类思维中“局部构成整体”的概念。
个人感性的理解见下
左边的V是所有图像的合集,每一列都是一副图像的按列展开,每副图像中的每一个点都是由各个特征分量中的对应点加权而成。具体在公式上理解就是如上图第二行第4列的三角形是Wk的第二行与H的第四列点积而成,而Wk每一列都是一副特征图像,所以原图的每一个对应点都是所有特征图像中的对应像素点加权而成。总体来理解就是V中每一列(即每一张原图)都可以由Wk的每一列(即特征图像)加权二成。
ConsensusClusterPlus 包对基因表达数据进行一致性聚类
从原数据集不同的子类中提取出的样本构成一个新的数据集,并且从同一个子类中有不同的样本被提取出来,那么在新数据集上聚类分析之后的结果,无论是聚类的数目还是类内样本都应该和原数据集相差不大。因此所得到的聚类相对于抽样变异越稳定,我们越可以相信这一样的聚类代表了一个真实的子类结构。重采样的方法可以打乱原始数据集,这样对每一次重采样的样本进行聚类分析然后再综合评估多次聚类分析的结果给出一致性(Consensus)的评估。
富集分析
基因组可以算突变率、转录组可以算基因表达水平、表观组可以观察甲基化水平、蛋白质组/代谢组可以看蛋白/代谢物丰度,甚至是宏基因组也可以比较菌群的丰度。最终,在分子水平的出口都是在生物学中心法则的核酸水平,确切的说是在基因水平,但是基因的种类有很多,包括蛋白编码基因(mRNA)、非编码基因(miRNA、lncRNA、snRNA等),理解这些基因所代表的生物学意义的最佳途径就是基因富集分析。
富集分析的原理。一个生物过程通常是由一组基因共同参与,而不是由单个基因独自完成。富集分析的基本前提假设是,如果一个生物学过程在已知的研究中发生异常,则共同发挥功能的基因极可能被选择出来作为一个与这一过程相关的基因集合。富集分析(Gene Set Enrichment Analysis, GSEA)通常是分析一组基因在某个功能节点上是否相比于随机水平过于出现(over-presentation)。富集分析原理可以由单个基因的简单注释扩展到多个基因集合的成组分析。
富集分析的作用。一组基因直接注释的结果是得到大量的功能节点,这些功能具有概念上的交叠现象,导致分析结果冗余,不利于进一步的精细分析,所以研究人员希望对得到的功能节点加以过滤和筛选,以便获得更有意义的功能信息。目前最常用的方法是基于GO和KEGG的富集分析。首先通过多种方法多的大量的感兴趣的基因,例如差异表达基因集、共表达基因模块、蛋白质复合物基因簇等,然后寻找这些感兴趣基因集显著富集的GO节点或者KEGG通路,这有助于进一步深入细致的实验研究。总而言之,富集分析是用来解读一组基因背后所代表的生物学知识,揭示其在细胞内或细胞外扮演了什么样的角色。
富集分析中常用的统计方法有累计超几何分布、Fisher精确检验等。由于在进行富集分析时通常需要同时进行大量检验(多重检验),所以需要采用多重检验校正的方法对检验结果进行校正,常用的校正方法包括Bonferroni校正、Benjiamini false discovery rate校正。
GO term功能富集
基因本体,即 Gene Ontology,是对所有基因的功能进行描述的本体数据库。该数据库将收录的基因本体按照术语描述的内容不同,将所有基因本体分为三大类,分别是描述分子功能的本体,描述细胞组分的本体以及描述生物过程的本体。
- 分子功能(Molecular Function):描述发生在分子水平上的活性,这种活性一般都是由单个基因产物进行的活性,比如“催化活性”、“结合活性”、“转运蛋白活性”等。当然,还有小部分活性是通过基因产物的复合物进行的活性,比如“腺苷酸环化酶活性”、“Toll 受体结合”等。
- 细胞组分(Cellular Component):描述某些大分子在执行某项分子功能时占据细胞的结构和位置。细胞的位置描述如“质膜的细胞质侧”,细胞的结构描述如“线粒体”,“核糖体”等。
- 生物过程(Biological Process):描述了由一个或多个有组织的分子功能集合共同完成的一系列事件。广泛的生物过程术语如“细胞生理过程”、“信号传导”等。具体的生物过程术语如“嘧啶代谢过程”、“α-葡萄糖苷转运”等。
GO的注释体系是一个有向无环图,包含三个分支,注释系统中每一个节点都是基因或蛋白质的一种描述,节点之间保持严格的“父子”关系。因此,一个基因或蛋白质可以从三个层面得到注释。
富集的含义
这里pathway富集的含义与GO富集的含义相同,也是表示差异基因中注释到某个代谢通路的基因数目在所有差异基因中的比例显著大于背景基因中注释到某个代谢通路的基因数目在所有背景基因中的比例。因此,做pathway富集分析,也是涉及到前景基因和背景基因。前景基因就是你关注的要重点研究的基因集,背景基因就是所有的基因集。
单基因富集
单基因富集分析并不是说拿单个基因来进行富集分析,一个基因根本没法进行统计检验。而是基于单个基因来抓取与其相关的基因,然后用这些相关的基因来进行功能富集,有两种方法:差异法和相关法。
差异法:根据给定的一个基因的表达值对样本进行分组,然后计算组间的差异表达基因,进而利用差异基因进行富集分析。
相关法:计算给定的一个基因的表达值与其他基因之间的相关性,将具有显著相关的基因作为一个集合进行富集分析。
免疫组化分析
抗体和抗原之间的结合具有高度的特异性,免疫组织化学正是利用了这一原理。先将组织或细胞中的某种化学物质提取出来,以此作为抗原或半抗原,通过免疫动物后获得特异性的抗体,再以此抗体去探测组织或细胞中的同类的抗原物质。由于抗原与抗体的复合物是无色的,因此还必须借助于组织化学的方法将抗原抗体结合的部位显示出来,以期达到对组织或细胞中的未知抗原进行定性,定位或定量的研究。
免疫组化(immunohistochemistry,IHC)是应用免疫学基本原理——抗原抗体特异性反应原理,通过化学反应使标记抗体的显色剂(荧光素、酶、金属离子、同位素)显色来确定组织细胞内抗原(多肽和蛋白质),对其进行定位、定性及相对定量的研究。
免疫组化具有特异性强、敏感性高、定位准确、形态与功能相结合等多种优点,可应用于确定细胞类型、发现微小转移灶、了解分化程度、临床应用、肿瘤起源与分化 、指导治疗与预后等多个方面。根据抗原抗体反应和化学显色的原理,组织切片或细胞样本中的抗原先和一抗结合,再利用一抗与生物素、荧光素等标记的二抗反应,从而可确定组织中某种抗原的定位,进而进行显色分析。
IHC将免疫反应的特异性和组织化学的可见性巧妙的结合起来,借助荧光显微镜和电子显微镜的呈像和放大,在细胞和亚细胞水平检测各种抗原物质。这种实验的独特之处在于它既直观的显示了蛋白在组织及细胞或细胞亚结构的定位,又保留了组织样品的结构特征,广泛应用于生物医学研究及临床诊断中。
CD8、CD68
CD8分子是一种白细胞分化抗原,为部分T细胞表面所具有的一种糖蛋白,用以辅助T细胞受体(TCR)识别抗原并参与T细胞活化信号的转导,又称为TCR的共受体。表达CD8的T细胞(CD8+T细胞)通常在活化后分化为细胞毒性T细胞(CTL),能够特异性地杀伤靶细胞。
CD68是一种可以在单核细胞和巨噬细胞中高表达的跨膜糖蛋白。 虽然在造血细胞系中低表达,但可通过PMA/TPA对CD68进行诱导。与溶酶体颗粒有关,是巨噬细胞最可靠的标记。
CD68表达于以下细胞中:单核细胞、巨噬细胞、粒细胞(只表达KP1,不表达PG-M1)、嗜碱性粒细胞、大淋巴细胞、破骨细胞、肥大细胞(只表达PG-M1,不表达KP1)、滑膜细胞(只表达PG-M1,不表达KP1)、朗格汉斯巨细胞、树突状网织细胞肉瘤和黑色素瘤。此抗体可用于真性组织细胞淋巴瘤、AML、粒细胞肉瘤(但注意B细胞淋巴瘤胞浆弱阳性)、Kikucki病中浆样单核细胞和肥大细胞增多症的诊断。
巨噬细胞
巨噬细胞(Macrophage, M)是一类位于外周血,炎症组织中的白细胞。在动物体内主要通过吞噬细菌,死亡细胞及细胞残片等作用参与非特异性免疫调节(先天性免疫)而随后将吞噬的物质消化并将其特征递呈倒后续淋巴细胞及其他免疫细胞参与特异性免疫调节(后天性免疫)。
Spearman相关性分析
- Spearman相关,又称秩相关、等级相关,是对两变量的秩次大小作线性相关分析,对原始变量的分布不作要求,属于非参数统计方法,适用范围较广。对于服从Pearson相关的数据亦可计算Spearman相关系数,但统计效能更低。
- Spearman相关系数(rs)介于-1与1之间,rs >0为正相关,rs <0为负相关。rs的绝对值(|rs|)越大,变量间的相关性越强
Pearson相关性分析
Pearson相关性分析,需要满足5个条件:
条件1:两变量均为连续变量。
条件2:两变量应当是配对的,即来源于同一个个体。
条件3:两变量之间存在线性关系,通常绘制散点图检验。
条件4:两变量没有明显的异常值,通常绘制箱线图检验。异常值会对相关性分析的结果造成很大影响,如果存在异常值,应修改为正确值或进行变换去除,并在报告中指出。
条件5:两变量符从正态(或近似正态)分布,通常绘制Q-Q图或进行正态性检验。
CIBERSORT
CIBERSORT这款软件利用反卷积的方法,利用单细胞RNA-seq的数据,提取特征后,反推Bulk-seq各类细胞成分所占比例。