RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one.
pytorch多GPU(单机多卡)训练采坑:RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one.
- 问题描述
- 问题探究
-
- forward输出多个参数但不参与loss计算并不会导致报错
- 在模型的__init__方法中定义了某些层但是没有使用才是发生报错的关键
- 解决方案
问题描述
由于我的模型参数较多,且训练时发现大的batchsize效果更好,这就导致单个GPU的显存可能不够用,所以需要使用多GPU训练。
我使用的是hugging face开源的accelerate库中的accelerate.Accelerator类来进行的多GPU训练。
训练中出现如下报错:
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your module has parameters that were not used in producing loss. You can enable unused parameter detection by passing the keyword argument find_unused_parameters=True to torch.nn.parallel.DistributedDataParallel, and by
making sure all forward function outputs participate in calculating loss.
If you already have done the above, then the distributed data parallel module wasn’t able to locate the output tensors in the return value of your module’s forward function. Please include the loss function and the structure of the return value of forward of your module when reporting this issue (e.g. list, dict, iterable).
Parameter indices which did not receive grad for rank 1: 40 41 42 43 44 45 46 47 48 49 50 51
In addition, you can set the environment variable TORCH_DISTRIBUTED_DEBUG to either INFO or DETAIL to print out information about which particular parameters did not receive gradient on this rank as part of this error
翻译成中文是:
RuntimeError: 在开始新的迭代之前,预期上一个迭代已完成归约。此错误表明您的模块有未用于产生损失的参数。您可以通过向 torch.nn.parallel.DistributedDataParallel 传递关键字参数 find_unused_parameters=True 来启用未使用的参数检测,并确保所有的 forward 函数输出都参与计算损失。
如果您已经这样做了,那么分布式数据并行模块无法定位您模块的 forward 函数返回值中的输出张量。在报告此问题时,请包含损失函数和您模块的 forward 函数的返回值结构(例如,列表,字典,迭代器)。
未为排名1接收梯度的参数索引为: 40 41 42 43 44 45 46 47 48 49 50 51
此外,您可以将环境变量 TORCH_DISTRIBUTED_DEBUG 设置为 INFO 或 DETAIL,以打印有关此排名上哪些特定参数未收到梯度的信息作为此错误的一部分。
报错完整的截图如下
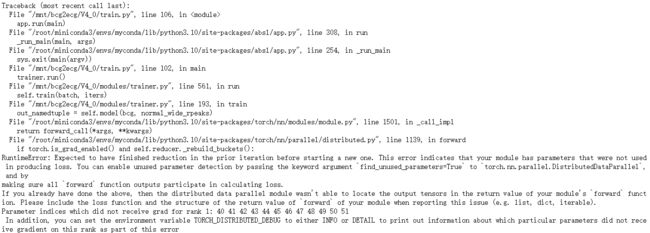
这似乎再说我定义了一些模块没有使用,或者输出了一些参数但是没有参与loss计算,导致这个问题
问题探究
forward输出多个参数但不参与loss计算并不会导致报错
一开始我看到这句话making sure all forward function outputs participate in calculating loss
以为是我的模型输出的值没有参与loss计算,导致报错,但是我后来经过研究发现:
模型的forward输出多个值,但是没有参与loss计算并不会导致报错!!
例如在有多个GPU的设备上运行下列代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from accelerate import Accelerator
from accelerate.utils import write_basic_config
from collections import namedtuple
def main():
# write_basic_config() # Write a config file
# 1. 初始化 Accelerator
accelerator = Accelerator()
# 2. 定义一个简单的模型和优化器
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(10, 10)
self.fc2 = nn.Linear(10, 2)
def forward(self, x):
fc1 = self.fc1(x)
fc2 = self.fc2(fc1)
fc3 = self.fc2(fc1) * 2 + 1
return_namedtuple = namedtuple('return_namedtuple', ['fc1', 'fc2', 'fc3'])
return return_namedtuple(fc1=fc1, fc2=fc2, fc3=fc3)
model = SimpleModel()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 3. 定义虚拟数据
x = torch.randn(10000, 10)
y = (torch.randn(10000) > 0.5).long()
dataset = TensorDataset(x, y)
loader = DataLoader(dataset, batch_size=512, shuffle=True)
# 4. 使用 accelerator.prepare 函数准备模型和优化器
model, optimizer, loader = accelerator.prepare(model, optimizer, loader)
# 5. 训练循环
for epoch in range(10000):
for batch in loader:
inputs, targets = batch
loss = 0
outputnamedtuple = model(inputs)
loss1 = nn.CrossEntropyLoss()(outputnamedtuple.fc1, targets)
loss2 = nn.CrossEntropyLoss()(outputnamedtuple.fc2, targets)
loss = loss1 + loss2
optimizer.zero_grad()
accelerator.backward(loss)
optimizer.step()
print(f"Loss: {loss.item()}")
print("Training completed!")
if __name__ == "__main__":
main()
注意看,我这里计算并输出一个值名称叫fc3,但是后续计算loss的时候只使用了fc1和fc2,这样设置代码是可以正常运行不会报错的。


在模型的__init__方法中定义了某些层但是没有使用才是发生报错的关键
我们现在将如上述代码的定义模型部分修改一下,就会发生报错
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(10, 10)
self.fc2 = nn.Linear(10, 2)
self.fc3 = nn.Linear(10, 2)
def forward(self, x):
fc1 = self.fc1(x)
fc2 = self.fc2(fc1)
fc3 = self.fc3(fc1)
return_namedtuple = namedtuple('return_namedtuple', ['fc1', 'fc2', 'fc3'])
return return_namedtuple(fc1=fc1, fc2=fc2, fc3=fc3)
这一代码与上面的区别就在于定义了一个self.fc3 = nn.Linear(10, 2)这个层,但是这个层所计算出来的fc3结果没有参与loss计算,就会导致报错。
如果定义了某个层,但是也没有输出计算结果,同样会导致报错,比如将代码改成如下所示,也会报错:
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(10, 10)
self.fc2 = nn.Linear(10, 2)
self.fc3 = nn.Linear(10, 2)
def forward(self, x):
fc1 = self.fc1(x)
fc2 = self.fc2(fc1)
return_namedtuple = namedtuple('return_namedtuple', ['fc1', 'fc2'])
return return_namedtuple(fc1=fc1, fc2=fc2)
注意这里是说如果用self.xx的语句定义了层会报错,如果去掉self则不会报错,如下所示。
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(10, 10)
self.fc2 = nn.Linear(10, 2)
fc3 = nn.Linear(10, 2)
def forward(self, x):
fc1 = self.fc1(x)
fc2 = self.fc2(fc1)
return_namedtuple = namedtuple('return_namedtuple', ['fc1', 'fc2'])
return return_namedtuple(fc1=fc1, fc2=fc2)
总结:在使用nn.Module的__init__方法时,如果使用self.xx这样的语句定义了层,但是这个层的计算结果后续没有用老计算loss,或者这个层没有使用,都会导致标题所述的报错
解决方案
上面只是一个用于排查错误的例子,那么我的模型哪里出现了这样的问题呢?我通过寻找,最终找到了问题所在,我发现是我使用的transformer模型中的问题,具体是nn.TransformerEncoderLayer和nn.TransformerEncoder的使用出现了问题。具体如下:
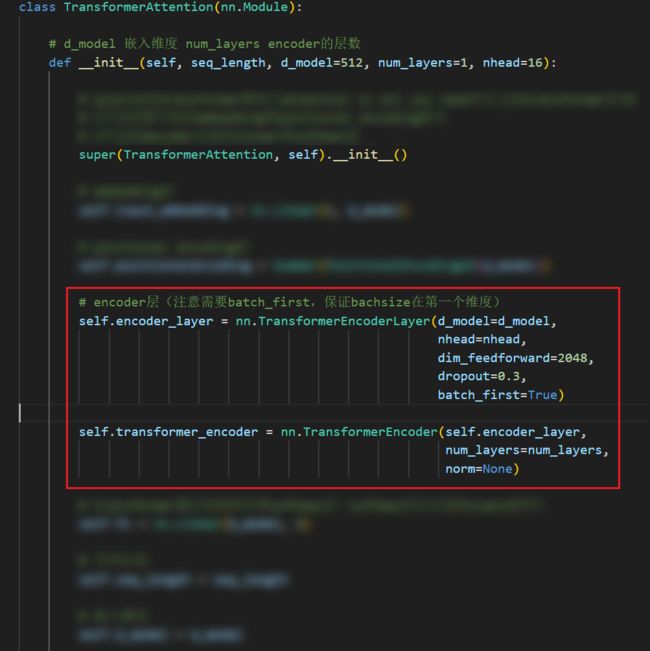
在使用transformer模型中的encoder的时候,通常需要使用nn.TransformerEncoderLayer先定义一层encoder,然后使用nn.TransformerEncoder将之前定义的一层encoder串联起来,形成一个多层的encoder。
那么问题来了,后面在进行forward的时候,我们是使用self.transformer_encoder来进行的,并没有使用self.encoder_layer,这就导致出现了先前分析所说的“使用self.xx语句定义了层但是并没有使用的情况”。解决方案就是去掉encoder_layer前面的self即可,如下图所示
