acclerator和tensorboard共同使用采坑记录
acclerator和tensorboard共同使用采坑记录
- 问题描述
- 可采用的方案
-
- 可采用的方案1
- 可采用的方案2
- 其他可采用方案
- 可采用方案的总结
- 建议的最终方案
问题描述
最近在做用多个GPU训练,我选择的是hugging face开源团队的acclerate库中的accelerator类来实现的,在这种情况下,使用tensorboard来记录追踪训练情况,需要对代码进行相应的调整。
可采用的方案
在使用了accelerator类的情况下,使用tensorboard进行训练追踪,可参考官方文档给出的一些方案来进行。以下列举一些
可采用的方案1
一种方案是直接使用tensorboard,如下述代码所示,在这种方法中,tensorboard和accelerator是分别初始化的。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from accelerate import Accelerator
from torch.utils.tensorboard import SummaryWriter
import os
# 1. 初始化 Accelerator
accelerator = Accelerator()
# 2. 使用tensorboard追踪训练
tbwriter = SummaryWriter(log_dir=os.path.join('testfolder', 'test'))
# 3. 定义一个简单的模型和优化器
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 2)
def forward(self, x):
return self.fc(x)
model = SimpleModel()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 4. 定义虚拟数据
x = torch.randn(100000, 10)
y = (torch.randn(100000) > 0.5).long()
dataset = TensorDataset(x, y)
loader = DataLoader(dataset, batch_size=2048, shuffle=True)
# 5. 使用 accelerator.prepare 函数准备模型和优化器
model, optimizer, loader = accelerator.prepare(model, optimizer, loader)
# 6. 训练循环
iter = 1
for epoch in range(10000):
for batch in loader:
inputs, targets = batch
outputs = model(inputs)
loss = nn.CrossEntropyLoss()(outputs, targets)
optimizer.zero_grad()
accelerator.backward(loss)
optimizer.step()
print(f"Loss: {loss.item()}")
tbwriter.add_scalar('loss', loss.item(), iter)
iter += 1
print("Training completed!")
看一下结果,在testfolder文件夹下的test文件夹中,竟然有两个文件

再使用–logdir=来查看训练情况,发现loss曲线很奇怪,貌似是一个横坐标对应了两个值

出现这种情况,原因其实在于accelerator是通过多进程来实现多GPU计算的,所以代码中tbwriter = SummaryWriter(log_dir=os.path.join('testfolder', 'test'))和tbwriter.add_scalar('loss', loss.item(), epoch)语句都被两个进程执行了两次。所以才会产生两个文件,在可视化窗口一个横坐标也对应了两个值。
解决方案就是在这些语句前加一句判断语句,如下所示:
if accelerator.is_main_process:
tbwriter = SummaryWriter(log_dir=os.path.join('testfolder', 'test'))
if accelerator.is_main_process:
tbwriter.add_scalar('loss', loss.item(), iter)
这样运行的结果就是正确的,而且仅会产生一个文件
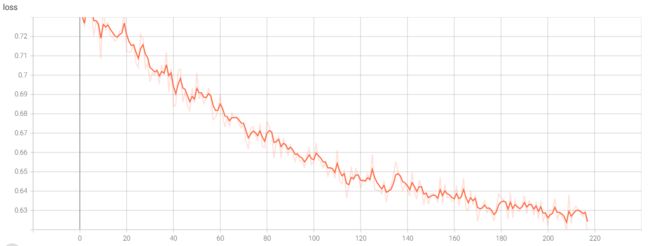
总结:这种该方法简单,改动小,但是每次向tensorboard添加数据的时候都需要判断一次是否是主程序,很麻烦
可采用的方案2
根据官方文档的内容,使用accelerator的情况下用tensorboard记录训练情况还可以这么写:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from accelerate import Accelerator
from accelerate.utils import ProjectConfiguration
from torch.utils.tensorboard import SummaryWriter
import os
# 1. 初始化 Accelerator的同时使用启用tensorbaord
config = ProjectConfiguration(project_dir=".", logging_dir="testfolder")
accelerator = Accelerator(log_with="tensorboard", project_config=config)
accelerator.init_trackers("test")
# 2. 定义一个简单的模型和优化器
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 2)
def forward(self, x):
return self.fc(x)
model = SimpleModel()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 3. 定义虚拟数据
x = torch.randn(100000, 10)
y = (torch.randn(100000) > 0.5).long()
dataset = TensorDataset(x, y)
loader = DataLoader(dataset, batch_size=2048, shuffle=True)
# 4. 使用 accelerator.prepare 函数准备模型和优化器
model, optimizer, loader = accelerator.prepare(model, optimizer, loader)
# 5. 训练循环
iter = 1
for epoch in range(10000):
for batch in loader:
inputs, targets = batch
outputs = model(inputs)
loss = nn.CrossEntropyLoss()(outputs, targets)
optimizer.zero_grad()
accelerator.backward(loss)
optimizer.step()
print(f"Loss: {loss.item()}")
accelerator.log({"training_loss": loss}, step=iter)
iter += 1
print("Training completed!")
这样也能出来正确的结果

这种方法优点在于不用每次都去判断是否是主进程。
然而,这种方案仅添加数值,无法添加figure,也无法使用tensorboard中丰富的方法来记录训练过程。
将上述代码稍微更改下,能够使用log和log_images两种方法,但是也只能使用这两种方法来追踪训练过程,仍然不够自由。
初始化代码改为:
# 1. 初始化 Accelerator的同时使用启用tensorbaord
config = ProjectConfiguration(project_dir=".", logging_dir="testfolder")
accelerator = Accelerator(log_with="tensorboard", project_config=config)
accelerator.init_trackers("test")
tensorboard_tracker = accelerator.get_tracker("tensorboard")
在训练循环中追踪训练的代码改为:
tensorboard_tracker.log({"training_loss": loss}, step=epoch)
其他可采用方案
除此之外,还有其他类似的方案,比如访问内部追踪器之类的,这些方法和上面提到的大同小异,没有明显区别,所以在这里不再赘述。
可采用方案的总结
通过上述研究不难发现,在使用accelerator在多GPU上训练的时候,使用tensorboard进行训练追踪存在“鱼和熊掌不能兼得”的情况:
如果使用accelerator类封装包裹好的方法,那么无法使用tensorboard中的add_figure等方法来添加图片;
如果直接使用tensorboard来记录,则需要在每次记录的时候都判断一次目前是否是主进程,让代码变的很冗长。
通过查阅官方文档,我发现还有一种方法可以解决上述问题,就是使用自定义的追踪器来实现:

建议的最终方案
官方文档给出了使用wandb用作自定义追踪器的方法:
from accelerate.tracking import GeneralTracker, on_main_process
from typing import Optional
import wandb
class MyCustomTracker(GeneralTracker):
name = "wandb"
requires_logging_directory = False
@on_main_process
def __init__(self, run_name: str):
self.run_name = run_name
run = wandb.init(self.run_name)
@property
def tracker(self):
return self.run.run
@on_main_process
def store_init_configuration(self, values: dict):
wandb.config(values)
@on_main_process
def log(self, values: dict, step: Optional[int] = None):
wandb.log(values, step=step)
我们可以以此为参考,并参考accelerator中已写好的关于tensorboard的追踪器,写一个基于tensorboard的自定义追踪器,并使用这个自定义追踪器来追踪训练过程,完整代码如下所示
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from accelerate import Accelerator
from torch.utils.tensorboard import SummaryWriter
from accelerate.tracking import GeneralTracker, on_main_process
import os
from typing import Union
import numpy as np
import matplotlib.pyplot as plt
# 0. 自定义追踪器
class MyCustomTracker(GeneralTracker):
"""
my custom `Tracker` class that supports `tensorboard`. Should be initialized at the start of your script.
Args:
run_name (`str`):
The name of the experiment run
logging_dir (`str`, `os.PathLike`):
Location for TensorBoard logs to be stored.
kwargs:
Additional key word arguments passed along to the `tensorboard.SummaryWriter.__init__` method.
"""
name = "tensorboard"
requires_logging_directory = True
@on_main_process
def __init__(self, run_name: str, logging_dir: Union[str, os.PathLike],
**kwargs):
super().__init__()
self.run_name = run_name
self.logging_dir = os.path.join(logging_dir, run_name)
self.writer = SummaryWriter(self.logging_dir, **kwargs)
@property
def tracker(self):
return self.writer
@on_main_process
def add_scalar(self, tag, scalar_value, **kwargs):
self.writer.add_scalar(tag=tag, scalar_value=scalar_value, **kwargs)
@on_main_process
def add_text(self, tag, text_string, **kwargs):
self.writer.add_text(tag=tag, text_string=text_string, **kwargs)
@on_main_process
def add_figure(self, tag, figure, **kwargs):
self.writer.add_figure(tag=tag, figure=figure, **kwargs)
# 1. 初始化 Accelerator,并使用自定义的tensorbaord追踪器
mycustomtracker = MyCustomTracker(run_name='test', logging_dir='testfolder')
accelerator = Accelerator(log_with=mycustomtracker)
# 2. 定义一个简单的模型和优化器
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 2)
def forward(self, x):
return self.fc(x)
model = SimpleModel()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 3. 定义虚拟数据
x = torch.randn(100000, 10)
y = (torch.randn(100000) > 0.5).long()
dataset = TensorDataset(x, y)
loader = DataLoader(dataset, batch_size=2048, shuffle=True)
# 4.画图demo
fig1, ax1 = plt.subplots()
xplot1 = np.array([1, 2, 3, 4, 5])
yplot1 = np.array([1, 2, 3, 4, 5])
ax1.plot(xplot1, yplot1)
fig2, ax2 = plt.subplots()
xplot2 = np.array([1, 2, 3, 4, 5])
yplot2 = np.array([5, 4, 3, 2, 1])
ax2.plot(xplot2, yplot2)
mycustomtracker.add_figure(tag="test_plot", figure=fig1, global_step=1, close=True, walltime=None)
mycustomtracker.add_figure(tag="test_plot", figure=fig2, global_step=2, close=True, walltime=None)
# 5.添加textdemo
mycustomtracker.add_text(tag="test_text", text_string='This is a test string')
# 5. 使用 accelerator.prepare 函数准备模型和优化器
model, optimizer, loader = accelerator.prepare(model, optimizer, loader)
# 6. 训练循环
iter = 1
for epoch in range(10000):
for batch in loader:
inputs, targets = batch
outputs = model(inputs)
loss = nn.CrossEntropyLoss()(outputs, targets)
optimizer.zero_grad()
accelerator.backward(loss)
optimizer.step()
print(f"Loss: {loss.item()}")
mycustomtracker.add_scalar(tag='training loss',
scalar_value=loss.item(),
global_step=iter)
iter += 1
print("Training completed!")
上述代码的核心就在于第一部分,自定义了一个追踪器,自定义的追踪器可以将tensoboard中丰富的方法都添加进来,并且用@on_main_process修饰,保证了仅有主进程可以访问方法,这样就不用每次在追踪前判断if accelerator.is_main_process:了,效果如下:
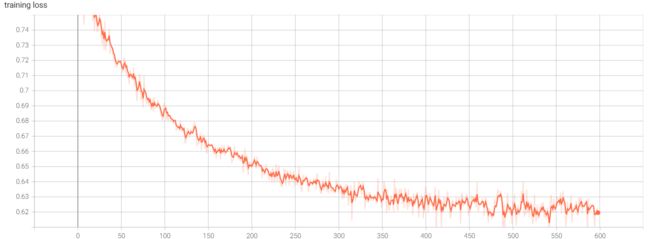
画图和添加文本也是能够使用的:
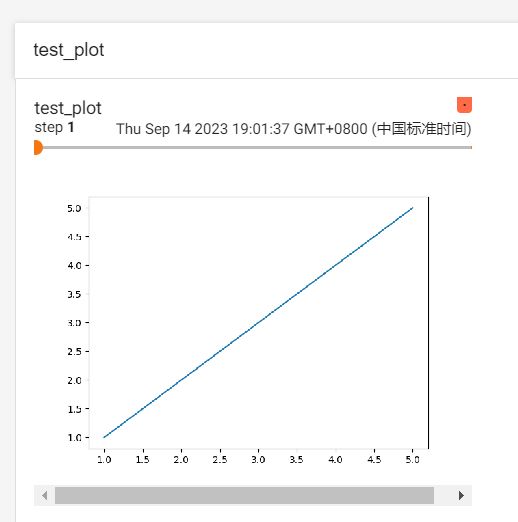


成功达到目标!