(七)Python函数和lambda表达式
函数就是一段封装好的,可以重复使用的代码,它使得我们的程序更加模块化,不需要编写大量重复的代码。
函数可以提前保存起来,并给它起一个独一无二的名字,只要知道它的名字就能使用这段代码。函数还可以接收数据,并根据数据的不同做出不同的操作,最后再把处理结果反馈给我们。
本章不仅会介绍 Python 定义和使用函数的基本语法,还有很多高级的函数用法(例如 lambda 匿名函数),都会为你一一详解。
一、Python函数(函数定义、函数调用)用法详解
Python 中函数的应用非常广泛,前面章节中我们已经接触过多个函数,比如 input() 、print()、range()、len() 函数等等,这些都是 Python 的内置函数,可以直接使用。
除了可以直接使用的内置函数外,Python 还支持自定义函数,即将一段有规律的、可重复使用的代码定义成函数,从而达到一次编写、多次调用的目的。
举个例子,前面学习了 len() 函数,通过它我们可以直接获得一个字符串的长度。我们不妨设想一下,如果没有 len() 函数,要想获取一个字符串的长度,该如何实现呢?请看下面的代码:
n=0
for c in "http://c.biancheng.net/python/":
n = n + 1
print(n)程序执行结果为:
30要知道,获取一个字符串长度是常用的功能,一个程序中就可能用到很多次,如果每次都写这样一段重复的代码,不但费时费力、容易出错,而且交给别人时也很麻烦。
所以 Python 提供了一个功能,即允许我们将常用的代码以固定的格式封装(包装)成一个独立的模块,只要知道这个模块的名字就可以重复使用它,这个模块就叫做函数(Function)。
比如,在程序中定义了一段代码,这段代码用于实现一个特定的功能。问题来了,如果下次需要实现同样的功能,难道要把前面定义的代码复制一次?如果这样做实在太傻了,这意味着每次当程序需要实现该功能时,都要将前面定义的代码复制一次。正确的做法是,将实现特定功能的代码定义成一个函数,每次当程序需要实现该功能时,只要执行(调用)该函数即可。
其实,函数的本质就是一段有特定功能、可以重复使用的代码,这段代码已经被提前编写好了,并且为其起一个“好听”的名字。在后续编写程序过程中,如果需要同样的功能,直接通过起好的名字就可以调用这段代码。
下面演示了如何将我们自己实现的 len() 函数封装成一个函数:
#自定义 len() 函数
def my_len(str):
length = 0
for c in str:
length = length + 1
return length
#调用自定义的 my_len() 函数
length = my_len("http://c.biancheng.net/python/")
print(length)
#再次调用 my_len() 函数
length = my_len("http://c.biancheng.net/shell/")
print(length)程序执行结果为:
30
29如果读者接触过其他编程语言中的函数,以上对于函数的描述,肯定不会陌生。但需要注意的一点是,和其他编程语言中函数相同的是,Python 函数支持接收多个( ≥0 )参数,不同之处在于,Python 函数还支持返回多个( ≥0 )值。
比如,上面程序中,我们自己封装的 my_len(str) 函数,在定义此函数时,我们为其设置了 1 个 str 参数,同时该函数经过内部处理,会返回给我们 1 个 length 值。
通过分析 my_len() 函数这个实例不难看出,函数的使用大致分为 2 步,分别是定义函数和调用函数。接下来一一为读者进行详细的讲解。
1、Python函数的定义
定义函数,也就是创建一个函数,可以理解为创建一个具有某些用途的工具。定义函数需要用 def 关键字实现,具体的语法格式如下:
def 函数名(参数列表):
//实现特定功能的多行代码
[return [返回值]]其中,用 [] 括起来的为可选择部分,即可以使用,也可以省略。
此格式中,各部分参数的含义如下:
- 函数名:其实就是一个符合 Python 语法的标识符,但不建议读者使用 a、b、c 这类简单的标识符作为函数名,函数名最好能够体现出该函数的功能(如上面的 my_len,即表示我们自定义的 len() 函数)。
- 形参列表:设置该函数可以接收多少个参数,多个参数之间用逗号( , )分隔。
- [return [返回值] ]:整体作为函数的可选参参数,用于设置该函数的返回值。也就是说,一个函数,可以用返回值,也可以没有返回值,是否需要根据实际情况而定。
注意,在创建函数时,即使函数不需要参数,也必须保留一对空的“()”,否则 Python 解释器将提示“invaild syntax”错误。另外,如果想定义一个没有任何功能的空函数,可以使用 pass 语句作为占位符。
例如,下面定义了 2 个函数:
#定义个空函数,没有实际意义
def pass_dis():
pass
#定义一个比较字符串大小的函数
def str_max(str1,str2):
str = str1 if str1 > str2 else str2
return str虽然 Python 语言允许定义个空函数,但空函数本身并没有实际意义。
另外值得一提的是,函数中的 return 语句可以直接返回一个表达式的值,例如修改上面的 str_max() 函数:
def str_max(str1,str2):
return str1 if str1 > str2 else str2该函数的功能,和上面的 str_max() 函数是完全一样的,只是省略了创建 str 变量,因此函数代码更加简洁。
2、Python函数的调用
调用函数也就是执行函数。如果把创建的函数理解为一个具有某种用途的工具,那么调用函数就相当于使用该工具。
函数调用的基本语法格式如下所示:
[返回值] = 函数名([形参值])其中,函数名即指的是要调用的函数的名称;形参值指的是当初创建函数时要求传入的各个形参的值。如果该函数有返回值,我们可以通过一个变量来接收该值,当然也可以不接受。
需要注意的是,创建函数有多少个形参,那么调用时就需要传入多少个值,且顺序必须和创建函数时一致。即便该函数没有参数,函数名后的小括号也不能省略。
例如,我们可以调用上面创建的 pass_dis() 和 str_max() 函数:
pass_dis()
strmax = str_max("http://c.biancheng.net/python","http://c.biancheng.net/shell");
print(strmax)首先,对于调用空函数来说,由于函数本身并不包含任何有价值的执行代码,也没有返回值,应该调用空函数不会有任何效果。
其次,对于上面程序中调用 str_max() 函数,由于当初定义该函数为其设置了 2 个参数,因此这里在调用该参数,就必须传入 2 个参数。同时,由于该函数内部还使用了 return 语句,因此我们可以使用 strmax 变量来接收该函数的返回值。
因此,程序执行结果为:
http://c.biancheng.net/shell3、为函数提供说明文档
前面章节讲过,通过调用 Python 的 help() 内置函数或者 __doc__ 属性,我们可以查看某个函数的使用说明文档。事实上,无论是 Python 提供给我们的函数,还是自定义的函数,其说明文档都需要设计该函数的程序员自己编写。
其实,函数的说明文档,本质就是一段字符串,只不过作为说明文档,字符串的放置位置是有讲究的,函数的说明文档通常位于函数内部、所有代码的最前面。
以上面程序中的 str_max() 函数为例,下面演示了如何为其设置说明文档:
#定义一个比较字符串大小的函数
def str_max(str1,str2):
'''
比较 2 个字符串的大小
'''
str = str1 if str1 > str2 else str2
return str
help(str_max)
#print(str_max.__doc__)程序执行结果为:
Help on function str_max in module __main__:
str_max(str1, str2)
比较 2 个字符串的大小上面程序中,还可以使用 __doc__ 属性来获取 str_max() 函数的说明文档,即使用最后一行的输出语句,其输出结果为:
比较 2 个字符串的大小二、Python函数值传递和引用传递(包括形式参数和实际参数的区别)
通常情况下,定义函数时都会选择有参数的函数形式,函数参数的作用是传递数据给函数,令其对接收的数据做具体的操作处理。
在使用函数时,经常会用到形式参数(简称“形参”)和实际参数(简称“实参”),二者都叫参数,之间的区别是:
- 形式参数:在定义函数时,函数名后面括号中的参数就是形式参数,例如:
#定义函数时,这里的函数参数 obj 就是形式参数 def demo(obj): print(obj) - 实际参数:在调用函数时,函数名后面括号中的参数称为实际参数,也就是函数的调用者给函数的参数。例如:
a = "C语言中文网" #调用已经定义好的 demo 函数,此时传入的函数参数 a 就是实际参数 demo(a)
实参和形参的区别,就如同剧本选主角,剧本中的角色相当于形参,而演角色的演员就相当于实参。
明白了什么是形参和实参后,再来想一个问题,那就是实参是如何传递给形参的呢?
Python 中,根据实际参数的类型不同,函数参数的传递方式可分为 2 种,分别为值传递和引用(地址)传递:
- 值传递:适用于实参类型为不可变类型(字符串、数字、元组);
- 引用(地址)传递:适用于实参类型为可变类型(列表,字典);
值传递和引用传递的区别是,函数参数进行值传递后,若形参的值发生改变,不会影响实参的值;而函数参数继续引用传递后,改变形参的值,实参的值也会一同改变。
例如,定义一个名为 demo 的函数,分别为传入一个字符串类型的变量(代表值传递)和列表类型的变量(代表引用传递):
def demo(obj) :
obj += obj
print("形参值为:",obj)
print("-------值传递-----")
a = "C语言中文网"
print("a的值为:",a)
demo(a)
print("实参值为:",a)
print("-----引用传递-----")
a = [1,2,3]
print("a的值为:",a)
demo(a)
print("实参值为:",a)运行结果为:
-------值传递-----
a的值为: C语言中文网
形参值为: C语言中文网C语言中文网
实参值为: C语言中文网
-----引用传递-----
a的值为: [1, 2, 3]
形参值为: [1, 2, 3, 1, 2, 3]
实参值为: [1, 2, 3, 1, 2, 3]分析运行结果不难看出,在执行值传递时,改变形式参数的值,实际参数并不会发生改变;而在进行引用传递时,改变形式参数的值,实际参数也会发生同样的改变。
对于初学者来说,本节只需要了解形参和实参,值传递和引用传递的区别即可。
三、Python函数参数传递的内部机制(超级详细)
通过学习《Python函数值传递和引用传递》一节我们知道,根据实际参数的类型不同,函数参数的传递方式分为值传递和引用传递(又称为地址传递),Python 底层是如何实现它们的呢?Python 中函数参数由实参传递给形参的过程,是由参数传递机制来控制的。
本节将围绕值传递和引用传递,深度剖析它们的底层实现。
1、Python函数参数的值传递机制
Python 函数参数的值传递,其本质就是将实际参数值复制一份,将其副本传给形参。这意味着,采用值传递方式的函数中,无论其内部对参数值进行如何修改,都不会影响函数外部的实参。
值传递的方式,类似于《西游记》里的孙悟空,它复制一个假孙悟空,假孙悟空具有的能力和真孙悟空相同,可除妖或被砍头。但不管这个假孙悟空遇到什么事,真孙悟空都不会受到任何影响。与此类似,传入函数的是实际参数值的复制品,不管在函数中对这个复制品如何操作,实际参数值本身不会受到任何影响。
下面程序演示了函数参数进行值传递的效果:
def swap(a , b) :
'''下面代码实现a、b变量的值交换'''
a, b = b, a
print("swap函数里,a =", a, " b =", b)
a = 6
b = 9
swap(a , b)
print("函数外部 a =", a ," b =", b)运行上面程序,将看到如下运行结果:
swap函数里,a = 9 b = 6
函数外部 a = 6 b = 9从上面的运行结果来看,在 swap() 函数里,经过交换形参 a 和 b 的值,它们的值分别变成了 9 和 6,但函数外部变量 a 和 b 的值依然是 6 和 9。这也证实了,swap() 函数的参数传递机制,采用的是值传递,函数内部使用的形参 a 和 b,和实参 a、b 没有任何关系。
swap() 函数中形参 a 和 b,各自分别是实参 a、b 的复制品。
如果读者依旧不是很理解,下面通过示意图来说明上面程序的执行过程。
上面程序开始定义了 a、b 两个局部变量,这两个变量在内存中的存储示意图如图 1 所示。
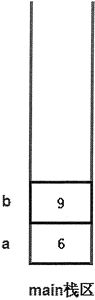
图 1 主栈区中 a、b 变量存储示意图
当程序执行 swap() 函数时,系统进入 swap() 函数,并将主程序中的 a、b 变量作为参数值传入 swap() 函数,但传入 swap() 函数的只是 a、b 的副本,而不是 a、b 本身。进入 swap() 函数后,系统中产生了 4 个变量,这 4 个变量在内存中的存储示意图如图 2 所示。
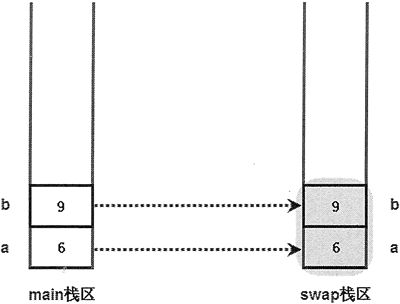
图 2 主栈区的变量作为参数值传入 swap() 函数后存储示意图
当在主程序中调用 swap() 函数时,系统分别为主程序和 swap() 函数分配两块栈区,用于保存它们的局部变量。将主程序中的 a、b 变量作为参数值传入 swap() 函数,实际上是在 swap() 函数栈区中重新产生了两个变量 a、b,并将主程序栈区中 a、b 变量的值分别赋值给 swap() 函数栈区中的 a、b 参数(就是对 swap() 函数的 a、b 两个变量进行初始化)。此时,系统存在两个 a 变量、两个 b 变量,只是存在于不同的栈区中而己。
程序在 swap() 函数中交换 a、b 两个变量的值,实际上是对图 2 中灰色区域的 a、b 变量进行交换。交换结束后,输出 swap() 函数中 a、b 变量的值,可以看到 a 的值为 9,b 的值为 6,此时在内存中的存储示意图如图 3 所示。
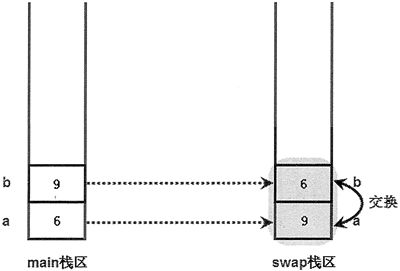
图 3 swap() 函数中 a、b 交换之后的存储示意图
对比图 3 与图 1,可以看到两个示意图中主程序栈区中 a、b 的值并未有任何改变,程序改变的只是 swap() 函数栈区中 a、b 的值。这就是值传递的实质:当系统开始执行函数时,系统对形参执行初始化,就是把实参变量的值赋给函数的形参变量,在函数中操作的并不是实际的实参变量。
2、Python函数参数的引用传递
如果实际参数的数据类型是可变对象(列表、字典),则函数参数的传递方式将采用引用传递方式。
下面程序示范了引用传递参数的效果:
def swap(dw):
# 下面代码实现dw的a、b两个元素的值交换
dw['a'], dw['b'] = dw['b'], dw['a']
print("swap函数里,a =", dw['a'], " b =", dw['b'])
dw = {'a': 6, 'b': 9}
swap(dw)
print("外部 dw 字典中,a =", dw['a']," b =",dw['b'])运行上面程序,将看到如下运行结果:
swap 函数里,a = 9 b = 6
外部 dw 字典中,a = 9 b = 6从上面的运行结果来看,在 swap() 函数里,dw 字典的 a、b 两个元素的值被交换成功。不仅如此,当 swap() 函数执行结束后,主程序中 dw 字典的 a、b 两个元素的值也被交换了。
注意,这里这很容易造成一种错觉,读者可能认为,在此 swap() 函数中,使用 dw 字典,就是外界的 dw 字典本身,而不是他的复制品。这只是一种错觉,实际上,引用传递的底层实现,依旧使用的是值传递的方式。下面还是结合示意图来说明程序的执行过程。
程序开始创建了一个字典对象,并定义了一个 dw 引用变量(其实就是一个指针)指向字典对象,这意味着此时内存中有两个东西:对象本身和指向该对象的引用变量。此时在系统内存中的存储示意图如图 4 所示:
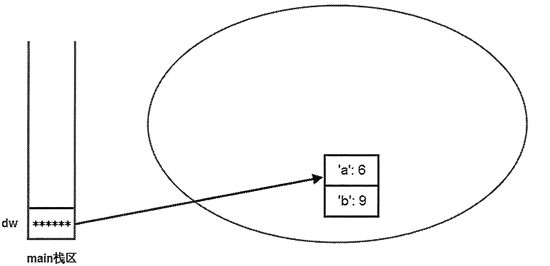
图 4 主程序创建了字典对象后存储示意图
接下来主程序开始调用 swap() 函数,在调用 swap() 函数时,dw 变量作为参数传入 swap() 函数,这里依然采用值传递方式:把主程序中 dw 变量的值赋给 swap() 函数的 dw 形参,从而完成 swap() 函数的 dw 参数的初始化。值得指出的是,主程序中的 dw 是一个引用变量(也就是一个指针),它保存了字典对象的地址值,当把 dw 的值赋给 swap() 函数的 dw 参数后,就是让 swap() 函数的 dw 参数也保存这个地址值,即也会引用到同一个字典对象。图 5 显示了 dw 字典传入 swap() 函数后的存储示意图。

图 5 dw 字典传入 swap() 函数后存储示意图
从图 5 来看,这种参数传递方式是不折不扣的值传递方式,系统一样复制了dw 的副本传入 swap() 函数。但由于 dw 只是一个引用变量,因此系统复制的是 dw 变量,并未复制字典本身。
当程序在 swap() 函数中操作 dw 参数时,由于 dw 只是一个引用变量,故实际操作的还是字典对象。此时,不管是操作主程序中的 dw 变量,还是操作 swap() 函数里的 dw 参数,其实操作的都是它们共同引用的字典对象,它们引用的是同一个字典对象。因此,当在 swap() 函数中交换 dw 参数所引用字典对象的 a、b 两个元素的值后,可以看到在主程序中 dw 变量所引用字典对象的 a、b 两个元素的值也被交换了。
为了更好地证明主程序中的 dw 和 swap() 函数中的 dw 是两个变量,在 swap() 函数的最后一行增加如下代码:
#把dw 直接赋值为None,让它不再指向任何对象
dw = None运行上面代码,结果是 swap() 函数中的 dw 变量不再指向任何对象,程序其他地方没有任何改变。主程序调用 swap() 函数后,再次访问 dw 变量的 a、b 两个元素,依然可以输出 9、6。可见,主程序中的 dw 变量没有受到任何影响。实际上,当在 swap() 函数中增加“dw =None”代码后,在内存中的存储示意图如图 6 所示。

图 6 将 swap() 函数中的 dw 赋值为 None 后存储示意图
从图 6 来看,把 swap() 函数中的 dw 赋值为 None 后,在 swap() 函数中失去了对字典对象的引用,不可再访问该字典对象。但主程序中的 dw 变量不受任何影响,依然可以引用该字典对象,所以依然可以输出字典对象的 a、b 元素的值。
通过上面介绍可以得出如下两个结论:
- 不管什么类型的参数,在 Python 函数中对参数直接使用“=”符号赋值是没用的,直接使用“=”符号赋值并不能改变参数。
- 如果需要让函数修改某些数据,则可以通过把这些数据包装成列表、字典等可变对象,然后把列表、字典等可变对象作为参数传入函数,在函数中通过列表、字典的方法修改它们,这样才能改变这些数据。
四、什么是位置参数,Python位置参数
位置参数,有时也称必备参数,指的是必须按照正确的顺序将实际参数传到函数中,换句话说,调用函数时传入实际参数的数量和位置都必须和定义函数时保持一致。
1、实参和形参数量必须一致
在调用函数,指定的实际参数的数量,必须和形式参数的数量一致(传多传少都不行),否则 Python 解释器会抛出 TypeError 异常,并提示缺少必要的位置参数。
例如:
def girth(width , height):
return 2 * (width + height)
#调用函数时,必须传递 2 个参数,否则会引发错误
print(girth(3))运行结果为:
Traceback (most recent call last):
File "C:\Users\mengma\Desktop\1.py", line 4, in
print(girth(3))
TypeError: girth() missing 1 required positional argument: 'height' 可以看到,抛出的异常类型为 TypeError,具体是指 girth() 函数缺少一个必要的 height 参数。
同样,多传参数也会抛出异常:
def girth(width , height):
return 2 * (width + height)
#调用函数时,必须传递 2 个参数,否则会引发错误
print(girth(3,2,4))运行结果为:
Traceback (most recent call last):
File "C:\Users\mengma\Desktop\1.py", line 4, in
print(girth(3,2,4))
TypeError: girth() takes 2 positional arguments but 3 were given 通过 TypeErroe 异常信息可以知道,girth() 函数本只需要 2 个参数,但是却传入了 3 个参数。
2、实参和形参位置必须一致
在调用函数时,传入实际参数的位置必须和形式参数位置一一对应,否则会产生以下 2 种结果:
- 抛出 TypeError 异常
当实际参数类型和形式参数类型不一致,并且在函数中,这两种类型之间不能正常转换,此时就会抛出 TypeError 异常。
例如:
输出结果为:def area(height,width): return height*width/2 print(area("C语言中文网",3))
以上显示的异常信息,就是因为字符串类型和整形数值做除法运算。Traceback (most recent call last): File "C:\Users\mengma\Desktop\1.py", line 3, inprint(area("C语言中文网",3)) File "C:\Users\mengma\Desktop\1.py", line 2, in area return height*width/2 TypeError: unsupported operand type(s) for /: 'str' and 'int' - 产生的结果和预期不符
调用函数时,如果指定的实际参数和形式参数的位置不一致,但它们的数据类型相同,那么程序将不会抛出异常,只不过导致运行结果和预期不符。
例如,设计一个求梯形面积的函数,并利用此函数求上底为 4cm,下底为 3cm,高为 5cm 的梯形的面积。但如果交互高和下低参数的传入位置,计算结果将导致错误:
运行结果为:def area(upper_base,lower_bottom,height): return (upper_base+lower_bottom)*height/2 print("正确结果为:",area(4,3,5)) print("错误结果为:",area(4,5,3))
因此,在调用函数时,一定要确定好位置,否则很有可能产生类似示例中的这类错误,还不容易发现。正确结果为: 17.5 错误结果为: 13.5
五、Python函数关键字参数及用法
目前为止,我们使用函数时所用的参数都是位置参数,即传入函数的实际参数必须与形式参数的数量和位置对应。而本节将介绍的关键字参数,则可以避免牢记参数位置的麻烦,令函数的调用和参数传递更加灵活方便。
关键字参数是指使用形式参数的名字来确定输入的参数值。通过此方式指定函数实参时,不再需要与形参的位置完全一致,只要将参数名写正确即可。
因此,Python 函数的参数名应该具有更好的语义,这样程序可以立刻明确传入函数的每个参数的含义。
例如,在下面的程序中就使用到了关键字参数的形式给函数传参:
(注意:在这一块要明确地区分位置参数和关键字参数)
def dis_str(str1,str2):
print("str1:",str1)
print("str2:",str2)
#位置参数
dis_str("http://c.biancheng.net/python/","http://c.biancheng.net/shell/")
#关键字参数
dis_str("http://c.biancheng.net/python/",str2="http://c.biancheng.net/shell/")
dis_str(str2="http://c.biancheng.net/python/",str1="http://c.biancheng.net/shell/")程序执行结果为:
str1: http://c.biancheng.net/python/
str2: http://c.biancheng.net/shell/
str1: http://c.biancheng.net/python/
str2: http://c.biancheng.net/shell/
str1: http://c.biancheng.net/shell/
str2: http://c.biancheng.net/python/可以看到,在调用有参函数时,既可以根据位置参数来调用,也可以使用关键字参数(程序中第 8 行)来调用。在使用关键字参数调用时,可以任意调换参数传参的位置。
当然,还可以像第 7 行代码这样,使用位置参数和关键字参数混合传参的方式。但需要注意,混合传参时关键字参数必须位于所有的位置参数之后。也就是说,如下代码是错误的:
# 位置参数必须放在关键字参数之前,下面代码错误
dis_str(str1="http://c.biancheng.net/python/","http://c.biancheng.net/shell/")Python 解释器会报如下错误:
SyntaxError: positional argument follows keyword argument六、Python函数默认参数设置(超级详细)
我们知道,在调用函数时如果不指定某个参数,Python 解释器会抛出异常。为了解决这个问题,Python 允许为参数设置默认值,即在定义函数时,直接给形式参数指定一个默认值。这样的话,即便调用函数时没有给拥有默认值的形参传递参数,该参数可以直接使用定义函数时设置的默认值。
Python 定义带有默认值参数的函数,其语法格式如下:
def 函数名(...,形参名,形参名=默认值):
代码块注意,在使用此格式定义函数时,指定有默认值的形式参数必须在所有没默认值参数的最后,否则会产生语法错误。
下面程序演示了如何定义和调用有默认参数的函数:
#str1没有默认参数,str2有默认参数
def dis_str(str1,str2 = "http://c.biancheng.net/python/"):
print("str1:",str1)
print("str2:",str2)
dis_str("http://c.biancheng.net/shell/")
dis_str("http://c.biancheng.net/java/","http://c.biancheng.net/golang/")运行结果为:
str1: http://c.biancheng.net/shell/
str2: http://c.biancheng.net/python/
str1: http://c.biancheng.net/java/
str2: http://c.biancheng.net/golang/上面程序中,dis_str() 函数有 2 个参数,其中第 2 个设有默认参数。这意味着,在调用 dis_str() 函数时,我们可以仅传入 1 个参数,此时该参数会传给 str1 参数,而 str2 会使用默认的参数,如程序中第 6 行代码所示。
当然在调用 dis_str() 函数时,也可以给所有的参数传值(如第 7 行代码所示),这时即便 str2 有默认值,它也会优先使用传递给它的新值。
同时,结合关键字参数,以下 3 种调用 dis_str() 函数的方式也是可以的:
dis_str(str1 = "http://c.biancheng.net/shell/")
dis_str("http://c.biancheng.net/java/",str2 = "http://c.biancheng.net/golang/")
dis_str(str1 = "http://c.biancheng.net/java/",str2 = "http://c.biancheng.net/golang/")再次强调,当定义一个有默认值参数的函数时,有默认值的参数必须位于所有没默认值参数的后面。因此,下面例子中定义的函数是不正确的:
#语法错误
def dis_str(str1="http://c.biancheng.net/python/",str2,str3):
pass显然,str1 设有默认值,而 str2 和 str3 没有默认值,因此 str1 必须位于 str2 和 str3 之后。
有读者可能会问,对于自己自定义的函数,可以轻易知道哪个参数有默认值,但如果使用 Python 提供的内置函数,又或者其它第三方提供的函数,怎么知道哪些参数有默认值呢?
Pyhton 中,可以使用“函数名.__defaults__”查看函数的默认值参数的当前值,其返回值是一个元组。以本节中的 dis_str() 函数为例,在其基础上,执行如下代码:
print(dis_str.__defaults__)程序执行结果为:
('http://c.biancheng.net/python/',)七、Python函数如何传入任意个参数? 可变参数(*args,**kwargs)详解
Python 在定义函数时也可以使用可变参数,即允许定义参数个数可变的函数。这样当调用该函数时,可以向其传入任意多个参数。
可变参数,又称不定长参数,即传入函数中的实际参数可以是任意多个。Python 定义可变参数,主要有以下 2 种形式。
1、可变参数:形参前添加一个 '*'
此种形式的语法格式如下所示:
*argsargs 表示创建一个名为 args 的空元组,该元组可接受任意多个外界传入的非关键字实参。
下面程序演示了如何定义一个参数可变的函数:
# 定义了支持参数收集的函数
def dis_str(home, *str) :
print(home)
# 输出str元组中的元素
print("str=",str)
for s in str :
print(s)
#可传入任何多个参数
dis_str("http://c.biancheng.net","http://c.biancheng.net/python/","http://c.biancheng.net/shell/")程序执行结果为:
http://c.biancheng.net
str= ('http://c.biancheng.net/python/', 'http://c.biancheng.net/shell/')
http://c.biancheng.net/python/
http://c.biancheng.net/shell/上面程序中,dis_str() 函数的最后一个参数就是 str 元组,这样在调用该函数时,除了前面位置参数接收对应位置的实参外,其它非关键字参数都会由 str 元组接收。
当然,可变参数并不一定必须为最后一个函数参数,例如修改 dis_str() 函数为:
# 定义了支持参数收集的函数
def dis_str(*str,home) :
print(home)
# 输出str元组中的元素
print("str=",str)
for s in str :
print(s)
dis_str("http://c.biancheng.net","http://c.biancheng.net/python/",home="http://c.biancheng.net/shell/")可以看到,str 可变参数作为 dis_str() 函数的第一个参数。但需要注意的是,在调用该函数时,必须以关键字参数的形式给普通参数传值,否则 Python 解释器会把所有参数都优先传给可变参数,如果普通参数没有默认值,就会报错。
也就是说,下面代码调用上面的 dia_str() 函数,是不对的:
dis_str("http://c.biancheng.net","http://c.biancheng.net/python/","http://c.biancheng.net/shell/")Python 解释器会提供如下报错信息:
TypeError: dis_str() missing 1 required keyword-only argument: 'home'翻译过来就是我们没有给 home 参数传值。当然,如果 home 参数有默认参数,则此调用方式是可行的。
2、可变参数:形参前添加两个'*'
这种形式的语法格式如下:
**kwargs**kwargs 表示创建一个名为 kwargs 的空字典,该字典可以接收任意多个以关键字参数赋值的实际参数。
例如如下代码:
# 定义了支持参数收集的函数
def dis_str(home,*str,**course) :
print(home)
print(str)
print(course)
#调用函数
dis_str("C语言中文网",\
"http://c.biancheng.net",\
"http://c.biancheng.net/python/",\
shell教程="http://c.biancheng.net/shell/",\
go教程="http://c.biancheng.net/golang/",\
java教程="http://c.biancheng.net/java/")程序输出结果为:
C语言中文网
('http://c.biancheng.net', 'http://c.biancheng.net/python/')
{'shell教程': 'http://c.biancheng.net/shell/', 'go教程': 'http://c.biancheng.net/golang/', 'java教程': 'http://c.biancheng.net/java/'}上面程序在调用 dis_str() 函数时,第 1 个参数传递给 home 参数,第 2、3 个非关键字参数传递给 str 元组,最后 2 个关键字参数将由 course 字典接收。
注意,*args 可变参数的值默认是空元组,**kwargs 可变参数的值默认是空字典。因此,在调用具有可变参数的函数时,不一定非要给它们传值。以调用 dis_str(home, *str, **course) 为例,下面的调用方式也是正确的:
dis_str(home="http://c.biancheng.net/shell/")程序执行结果为:
http://c.biancheng.net/shell/
()
{}八、Python如何用序列中元素给函数传递参数 逆向参数收集详解(进阶必读)
前面章节中介绍了,Python 支持定义具有可变参数的函数,即该函数可以接收任意多个参数,其中非关键字参数会集中存储到元组参数(*args)中,而关键字参数则集中存储到字典参数(**kwargs)中,这个过程可称为参数收集。
不仅如此,Python 还支持逆向参数收集,即直接将列表、元组、字典作为函数参数,Python 会将其进行拆分,把其中存储的元素按照次序分给函数中的各个形参。
在以逆向参数收集的方式向函数参数传值时,Pyhon 语法规定,当传入列表或元组时,其名称前要带一个 * 号,当传入字典时,其名称前要带有 2 个 * 号。
举个例子:
def dis_str(name,add) :
print("name:",name)
print("add",add)
data = ["Python教程","http://c.biancheng.net/python/"]
#使用逆向参数收集方式传值
dis_str(*data)程序执行结果为:
name: Python教程
add http://c.biancheng.net/python/再举个例子:
def dis_str(name,add) :
print("name:",name)
print("add:",add)
data = {'name':"Python教程",'add':"http://c.biancheng.net/python/"}
#使用逆向参数收集方式传值
dis_str(**data)程序执行结果为:
name: Python教程
add: http://c.biancheng.net/python/此外,以逆向参数收集的方式,还可以给拥有可变参数的函数传参,例如:
def dis_str(name,*add) :
print("name:",name)
print("add:",add)
data = ["http://c.biancheng.net/python/",\
"http://c.biancheng.net/shell/",\
"http://c.biancheng.net/golang/"]
#使用逆向参数收集方式传值
dis_str("Python教程",*data)程序执行结果为:
name: Python教程
add: ('http://c.biancheng.net/python/', 'http://c.biancheng.net/shell/', 'http://c.biancheng.net/golang/')上面程序中,也同样可以用逆向参数收集的方式给 name 参数传值,只需要将 "python教程" 放到 data 列表中第一个位置即可。也就是说,上面程序中,以下面代码调用 dis_str() 函数的方式也是可行的:
data = ["Python教程",\
"http://c.biancheng.net/python/",\
"http://c.biancheng.net/shell/",\
"http://c.biancheng.net/golang/"]
#使用逆向参数收集方式传值
dis_str(*data)执行此程序,会发现其输出结果和上面一致。
再次强调,如果使用逆向参数收集的方式,必须注意 * 号的添加。以逆向收集列表为例,如果传参时其列表名前不带 * 号,则 Python 解释器会将整个列表作为参数传递给一个参数。例如:
def dis_str(name,*add) :
print("name:",name)
print("add:",add)
data = ["Python教程",\
"http://c.biancheng.net/python/",\
"http://c.biancheng.net/shell/",\
"http://c.biancheng.net/golang/"]
dis_str(data)程序执行结果为:
name: ['Python教程', 'http://c.biancheng.net/python/', 'http://c.biancheng.net/shell/', 'http://c.biancheng.net/golang/']
add: ()九、Python None(空值)及用法
在 Python 中,有一个特殊的常量 None(N 必须大写)。和 False 不同,它不表示 0,也不表示空字符串,而表示没有值,也就是空值。
这里的空值并不代表空对象,即 None 和 []、“” 不同:
>>> None is []
False
>>> None is ""
FalseNone 有自己的数据类型,我们可以在 IDLE 中使用 type() 函数查看它的类型,执行代码如下:
>>> type(None)
可以看到,它属于 NoneType 类型。
需要注意的是,None 是 NoneType 数据类型的唯一值(其他编程语言可能称这个值为 null、nil 或 undefined),也就是说,我们不能再创建其它 NoneType 类型的变量,但是可以将 None 赋值给任何变量。如果希望变量中存储的东西不与任何其它值混淆,就可以使用 None。
除此之外,None 常用于 assert、判断以及函数无返回值的情况。举个例子,在前面章节中我们一直使用 print() 函数输出数据,其实该函数的返回值就是 None。因为它的功能是在屏幕上显示文本,根本不需要返回任何值,所以 print() 就返回 None。
>>> spam = print('Hello!')
Hello!
>>> None == spam
True另外,对于所有没有 return 语句的函数定义,Python 都会在末尾加上 return None,使用不带值的 return 语句(也就是只有 return 关键字本身),那么就返回 None。
十、Python return函数返回值详解
到目前为止,我们创建的函数都只是对传入的数据进行了处理,处理完了就结束。但实际上,在某些场景中,我们还需函数将处理的结果反馈回来,就好像主管向下级员工下达命令,让其去打印文件,员工打印好文件后并没有完成任务,还需要将文件交给主管。
Python中,用 def 语句创建函数时,可以用 return 语句指定应该返回的值,该返回值可以是任意类型。需要注意的是,return 语句在同一函数中可以出现多次,但只要有一个得到执行,就会直接结束函数的执行。
函数中,使用 return 语句的语法格式如下:
return [返回值]其中,返回值参数可以指定,也可以省略不写(将返回空值 None)。
【例 1】
def add(a,b):
c = a + b
return c
#函数赋值给变量
c = add(3,4)
print(c)
#函数返回值作为其他函数的实际参数
print(add(3,4))运行结果为:
7
7本例中,add() 函数既可以用来计算两个数的和,也可以连接两个字符串,它会返回计算的结果。
通过 return 语句指定返回值后,我们在调用函数时,既可以将该函数赋值给一个变量,用变量保存函数的返回值,也可以将函数再作为某个函数的实际参数。
【例 2】
def isGreater0(x):
if x > 0:
return True
else:
return False
print(isGreater0(5))
print(isGreater0(0))运行结果为:
True
False可以看到,函数中可以同时包含多个 return 语句,但需要注意的是,最终真正执行的做多只有 1 个,且一旦执行,函数运行会立即结束。
以上实例中,我们通过 return 语句,都仅返回了一个值,但其实通过 return 语句,可以返回多个值,读者可以阅读《Python函数返回多个值》一节做详细了解。
十一、Python函数返回多个值的方法(入门必读)
通常情况下,一个函数只有一个返回值,实际上 Python 也是如此,只不过 Python 函数能以返回列表或者元组的方式,将要返回的多个值保存到序列中,从而间接实现返回多个值的目的。
因此,实现 Python 函数返回多个值,有以下 2 种方式:
- 在函数中,提前将要返回的多个值存储到一个列表或元组中,然后函数返回该列表或元组;
- 函数直接返回多个值,之间用逗号( , )分隔,Python 会自动将多个值封装到一个元组中,其返回值仍是一个元组。
下面程序演示了以上 2 种实现方法:
def retu_list() :
add = ["http://c.biancheng.net/python/",\
"http://c.biancheng.net/shell/",\
"http://c.biancheng.net/golang/"]
return add
def retu_tuple() :
return "http://c.biancheng.net/python/",\
"http://c.biancheng.net/golang/",\
"http://c.biancheng.net/golang/"
print("retu_list = ",retu_list())
print("retu_tuple = ",retu_tuple())程序执行结果为:
retu_list = ['http://c.biancheng.net/python/', 'http://c.biancheng.net/shell/', 'http://c.biancheng.net/golang/']
retu_tuple = ('http://c.biancheng.net/python/', 'http://c.biancheng.net/golang/', 'http://c.biancheng.net/golang/')在此基础上,我们可以利用 Python 提供的序列解包功能,之间使用对应数量的变量,直接接收函数返回列表或元组中的多个值。这里以 retu_list() 为例:
def retu_list() :
add = ["http://c.biancheng.net/python/",\
"http://c.biancheng.net/shell/",\
"http://c.biancheng.net/golang/"]
return add
pythonadd,shelladd,golangadd = retu_list()
print("pythonadd=",pythonadd)
print("shelladd=",shelladd)
print("golangadd=",golangadd)程序执行结果为:
pythonadd= http://c.biancheng.net/python/
shelladd= http://c.biancheng.net/shell/
golangadd= http://c.biancheng.net/golang/十二、Python partial偏函数及用法
简单的理解偏函数,它是对原始函数的二次封装,是将现有函数的部分参数预先绑定为指定值,从而得到一个新的函数,该函数就称为偏函数。相比原函数,偏函数具有较少的可变参数,从而降低了函数调用的难度。
定义偏函数,需使用 partial 关键字(位于 functools 模块中),其语法格式如下:
偏函数名 = partial(func, *args, **kwargs)其中,func 指的是要封装的原函数,*args 和 **kwargs 分别用于接收无关键字实参和关键字实参。
下面举几个例子,让大家可以直观感受一下偏函数的用法和功能。
【例 1】
from functools import partial
#定义个原函数
def display(name,age):
print("name:",name,"age:",age)
#定义偏函数,其封装了 display() 函数,并为 name 参数设置了默认参数
GaryFun = partial(display,name = 'Gary')
#由于 name 参数已经有默认值,因此调用偏函数时,可以不指定
GaryFun(age = 13)运行结果为:
name: Gary age: 13注意,此程序的第 8 行代码中,必须采用关键字参数的形式给 age 形参传参,因为如果以无关键字参数的方式,该实参将试图传递给 name 形参,Python解释器会报 TypeError 错误。
【例 2】
from functools import partial
def mod( n, m ):
return n % m
#定义偏函数,并设置参数 n 对应的实参值为 100
mod_by_100 = partial( mod, 100 )
print(mod( 100, 7 ))
print(mod_by_100( 7 ))运行结果为:
2
2结合以上示例不难分析出,偏函数的本质是将函数式编程、默认参数和冗余参数结合在一起,通过偏函数传入的参数调用关系,与正常函数的参数调用关系是一致的。
偏函数通过将任意数量(顺序)的参数,转化为另一个带有剩余参数的函数对象,从而实现了截取函数功能(偏向)的效果。在实际应用中,可以使用一个原函数,然后将其封装多个偏函数,在调用函数时全部调用偏函数,一定程序上可以提高程序的可读性。
十三、Python函数递归(带实例演示)
一个函数在它的函数体内调用它自身称为递归调用,这种函数称为递归函数。执行递归函数将反复调用其自身,每调用一次就进入新的一层,当最内层的函数执行完毕后,再一层一层地由里到外退出。
递归函数不是 Python 语言的专利,C/C++、Java、C#、JavaScript、PHP 等其他编程语言也都支持递归函数。
下面我们通过一个实例,看看递归函数到底是如何运作的。
有这样一个数学题。己知有一个数列:f(0) = 1,f(1) = 4,f(n + 2) = 2*f(n+ 1) +f(n),其中 n 是大于 0 的整数,求 f(10) 的值。这道题可以使用递归来求得。下面程序将定义一个 fn() 函数,用于计算 f(10) 的值。
def fn(n) :
if n == 0 :
return 1
elif n == 1 :
return 4
else :
# 函数中调用它自身,就是函数递归
return 2 * fn(n - 1) + fn(n - 2)
# 输出fn(10)的结果
print("fn(10)的结果是:", fn(10))在上面的 fn() 函数体中再次调用了 fn() 函数,这就是函数递归。注意在 fn() 函数体中调用 fn 的形式:
return 2 * fn(n - 1) + fn(n - 2)对于 fn(10),即等于 2*fn(9)+fn(8),其中 fn(9) 又等于 2*fn(8)+fn(7)……依此类推,最终会计算到 fn(2) 等于 2*fn(1)+fn(0),即 fn(2) 是可计算的,这样递归带来的隐式循环就有结束的时候,然后一路反算回去,最后就可以得到 fn(10) 的值。
仔细看上面递归的过程,当一个函数不断地调用它自身时,必须在某个时刻函数的返回值是确定的,即不再调用它自身:否则,这种递归就变成了无穷递归,类似于死循环。因此,在定义递归函数时有一条最重要的规定: 递归一定要向已知方向进行。
例如,如果把上面数学题改为如此。己知有一个数列:f(20)=1,f(21)=4,f(n + 2)=2*f(n+1)+f(n),其中 n 是大于 0 的整数,求 f(10) 的值。那么 f(10) 的函数体应该改为如下形式:
def fn(n) :
if n == 20 :
return 1
elif n == 21 :
return 4
else :
# 函数中调用它自身,就是函数递归
return fn(n + 2) - 2*fn(n + 1)从上面的 fn() 函数来看,当程序要计算 fn(10) 的值时,fn(10) 等于 fn(12)-2*fn(11),而 fn(11) 等于 fn(13)-2*fn(12)……依此类推,直到 fn(19) 等于 fn(21)-2*fn(20),此时就可以得到 fn(19) 的值,然后依次反算到 fn(10) 的值。这就是递归的重要规则:对于求 fn(10) 而言,如果 fn(0) 和 fn(1) 是已知的,则应该采用 fn(n)=2*fn(n-1)+fn(n-2) 的形式递归,因为小的一端已知;如果 fn(20) 和 fn(21) 是已知的,则应该采用 fn(n)=fn(n+2)-2*fn(n+1) 的形式递归,因为大的一端已知。
递归是非常有用的,例如程序希望遍历某个路径下的所有文件,但这个路径下的文件夹的深度是未知的,那么就可以使用递归来实现这个需求。系统可定义一个函数,该函数接收一个文件路径作为参数,该函数可遍历出当前路径下的所有文件和文件路径,即在该函数的函数体中再次调用函数自身来处理该路径下的所有文件路径。
总之,只要在一个函数的函数体中调用了函数自身,就是函数递归。递归一定要向已知方向进行。
十四、Python变量作用域(全局变量和局部变量)
所谓作用域(Scope),就是变量的有效范围,就是变量可以在哪个范围以内使用。有些变量可以在整段代码的任意位置使用,有些变量只能在函数内部使用,有些变量只能在 for 循环内部使用。
变量的作用域由变量的定义位置决定,在不同位置定义的变量,它的作用域是不一样的。本节我们只讲解两种变量,局部变量和全局变量。
1、Python局部变量
在函数内部定义的变量,它的作用域也仅限于函数内部,出了函数就不能使用了,我们将这样的变量称为局部变量(Local Variable)。
要知道,当函数被执行时,Python 会为其分配一块临时的存储空间,所有在函数内部定义的变量,都会存储在这块空间中。而在函数执行完毕后,这块临时存储空间随即会被释放并回收,该空间中存储的变量自然也就无法再被使用。
举个例子:
def demo():
add = "http://c.biancheng.net/python/"
print("函数内部 add =",add)
demo()
print("函数外部 add =",add)程序执行结果为:
函数内部 add = http://c.biancheng.net/python/
Traceback (most recent call last):
File "C:\Users\mengma\Desktop\file.py", line 6, in
print("函数外部 add =",add)
NameError: name 'add' is not defined 可以看到,如果试图在函数外部访问其内部定义的变量,Python 解释器会报 NameError 错误,并提示我们没有定义要访问的变量,这也证实了当函数执行完毕后,其内部定义的变量会被销毁并回收。
值得一提的是,函数的参数也属于局部变量,只能在函数内部使用。例如:
def demo(name,add):
print("函数内部 name =",name)
print("函数内部 add =",add)
demo("Python教程","http://c.biancheng.net/python/")
print("函数外部 name =",name)
print("函数外部 add =",add)程序执行结果为:
函数内部 name = Python教程
函数内部 add = http://c.biancheng.net/python/
Traceback (most recent call last):
File "C:\Users\mengma\Desktop\file.py", line 7, in
print("函数外部 name =",name)
NameError: name 'name' is not defined 由于 Python 解释器是逐行运行程序代码,由此这里仅提示给我“name 没有定义”,实际上在函数外部访问 add 变量也会报同样的错误。
2、Python全局变量
除了在函数内部定义变量,Python 还允许在所有函数的外部定义变量,这样的变量称为全局变量(Global Variable)。
和局部变量不同,全局变量的默认作用域是整个程序,即全局变量既可以在各个函数的外部使用,也可以在各函数内部使用。
定义全局变量的方式有以下 2 种:
- 在函数体外定义的变量,一定是全局变量,例如:
运行结果为:add = "http://c.biancheng.net/shell/" def text(): print("函数体内访问:",add) text() print('函数体外访问:',add)函数体内访问: http://c.biancheng.net/shell/ 函数体外访问: http://c.biancheng.net/shell/ - 在函数体内定义全局变量。即使用 global 关键字对变量进行修饰后,该变量就会变为全局变量。例如:
运行结果为:def text(): global add add= "http://c.biancheng.net/java/" print("函数体内访问:",add) text() print('函数体外访问:',add)
注意,在使用 global 关键字修饰变量名时,不能直接给变量赋初值,否则会引发语法错误。函数体内访问: http://c.biancheng.net/java/ 函数体外访问: http://c.biancheng.net/java/
3、获取指定作用域范围中的变量
在一些特定场景中,我们可能需要获取某个作用域内(全局范围内或者局部范围内)所有的变量,Python 提供了以下 3 种方式:
(1)globals()函数
globals() 函数为 Python 的内置函数,它可以返回一个包含全局范围内所有变量的字典,该字典中的每个键值对,键为变量名,值为该变量的值。
举个例子:
#全局变量
Pyname = "Python教程"
Pyadd = "http://c.biancheng.net/python/"
def text():
#局部变量
Shename = "shell教程"
Sheadd= "http://c.biancheng.net/shell/"
print(globals())程序执行结果为:
{ ...... , 'Pyname': 'Python教程', 'Pyadd': 'http://c.biancheng.net/python/', ......}注意,globals() 函数返回的字典中,会默认包含有很多变量,这些都是 Python 主程序内置的,读者暂时不用理会它们。
可以看到,通过调用 globals() 函数,我们可以得到一个包含所有全局变量的字典。并且,通过该字典,我们还可以访问指定变量,甚至如果需要,还可以修改它的值。例如,在上面程序的基础上,添加如下语句:
print(globals()['Pyname'])
globals()['Pyname'] = "Python入门教程"
print(Pyname)程序执行结果为:
Python教程
Python入门教程(2)locals()函数
locals() 函数也是 Python 内置函数之一,通过调用该函数,我们可以得到一个包含当前作用域内所有变量的字典。这里所谓的“当前作用域”指的是,在函数内部调用 locals() 函数,会获得包含所有局部变量的字典;而在全局范文内调用 locals() 函数,其功能和 globals() 函数相同。
举个例子:
#全局变量
Pyname = "Python教程"
Pyadd = "http://c.biancheng.net/python/"
def text():
#局部变量
Shename = "shell教程"
Sheadd= "http://c.biancheng.net/shell/"
print("函数内部的 locals:")
print(locals())
text()
print("函数外部的 locals:")
print(locals())程序执行结果为:
函数内部的 locals:
{'Sheadd': 'http://c.biancheng.net/shell/', 'Shename': 'shell教程'}
函数外部的 locals:
{...... , 'Pyname': 'Python教程', 'Pyadd': 'http://c.biancheng.net/python/', ...... }当使用 locals() 函数获取所有全局变量时,和 globals() 函数一样,其返回的字典中会默认包含有很多变量,这些都是 Python 主程序内置的,读者暂时不用理会它们。
注意,当使用 locals() 函数获得所有局部变量组成的字典时,可以向 globals() 函数那样,通过指定键访问对应的变量值,但无法对变量值做修改。例如:
#全局变量
Pyname = "Python教程"
Pyadd = "http://c.biancheng.net/python/"
def text():
#局部变量
Shename = "shell教程"
Sheadd= "http://c.biancheng.net/shell/"
print(locals()['Shename'])
locals()['Shename'] = "shell入门教程"
print(Shename)
text()程序执行结果为:
shell教程
shell教程显然,locals() 返回的局部变量组成的字典,可以用来访问变量,但无法修改变量的值。
(3)vars(object)
vars() 函数也是 Python 内置函数,其功能是返回一个指定 object 对象范围内所有变量组成的字典。如果不传入object 参数,vars() 和 locals() 的作用完全相同。
由于目前读者还未学习 Python 类和对象,因此初学者可先跳过该函数的学习,等学完 Python 类和对象之后,再回过头来学习该函数。
举个例子:
#全局变量
Pyname = "Python教程"
Pyadd = "http://c.biancheng.net/python/"
class Demo:
name = "Python 教程"
add = "http://c.biancheng.net/python/"
print("有 object:")
print(vars(Demo))
print("无 object:")
print(vars())程序执行结果为:
有 object:
{...... , 'name': 'Python 教程', 'add': 'http://c.biancheng.net/python/', ......}
无 object:
{...... , 'Pyname': 'Python教程', 'Pyadd': 'http://c.biancheng.net/python/', ...... }十五、Python如何在函数中使用同名的全局变量?
上一节中提到,全局变量可以在程序中任何位置被访问甚至修改,但是,当函数中定义了和全局变量同名的局部变量时,那么在当前函数中,无论是访问还是修改该同名变量,操作的都是局部变量,而不再是全局变量。
当函数内部的局部变量和函数外部的全局变量同名时,在函数内部,局部变量会“遮蔽”同名的全局变量。
有读者可能并不能完全理解上面这段话,没关系,这里举个实例:
name = "Python教程"
def demo ():
#访问全局变量
print(name)
demo()程序执行结果为:
Python教程上面程序中,第 4 行直接访问 name 变量,这是允许的。在上面程序的基础上,在函数内部添加一行代码,如下所示:
name = "Python教程"
def demo ():
#访问全局变量
print(name)
name = "shell教程"
demo()执行此程序,Python 解释器报如下错误:
UnboundLocalError: local variable 'name' referenced before assignment该错误直译过来的意思是:所访问的 name 变量还未定义。这是什么原因呢?就是我们添加第 5 行代码导致的。
Python 语法规定,在函数内部对不存在的变量赋值时,默认就是重新定义新的局部变量。上面程序中,第 5 行就定义了一个新的 name 局部变量,由于该局部变量名和全局变量名 name 同名,局部 name 变量就会“遮蔽”全局 name 变量,再加上局部变量 name 在 print(name) 后才被初始化,违反了“先定义后使用”的原则,因此程序会报错。
那么,如果就是想在函数中访问甚至修改被“遮蔽”的变量,怎么办呢?可以采取以下 2 中方法:
- 直接访问被遮蔽的全局变量。如果希望程序依然能访问 name 全局变量,且在函数中可重新定义 name 局部变量,也就是在函数中可以访问被遮蔽的全局变量,此时可通过 globals() 函数来实现,将上面程序改为如下形式即可:
程序执行结果为:name = "Python教程" def demo (): #通过 globals() 函数访问甚至修改全局变量 print(globals()['name']) globals()['name']="Java教程" #定义局部变量 name = "shell教程" demo() print(name)Python教程 Java教程 - 在函数中声明全局变量。为了避免在函数中对全局变量赋值(不是重新定义局部变量),可使用 global 语句来声明全局变量。因此,可将程序改为如下形式:
程序执行结果为:name = "Python教程" def demo (): global name #访问全局name变量 print(name) #修改全局name变量的值 name = "shell教程" demo() print(name)
增加了“global name”声明之后,程序会把 name 变量当成全局变量,这意味着 demo() 函数后面对 name 赋值的语句只是对全局变量赋值,而不是重新定义局部变量。Python教程 shell教程
十六、Python局部函数及用法(包含nonlocal关键字)
通过前面的学习我们知道,Python 函数内部可以定义变量,这样就产生了局部变量,有读者可能会问,Python 函数内部能定义函数吗?答案是肯定的。Python 支持在函数内部定义函数,此类函数又称为局部函数。
那么,局部函数有哪些特征,在使用时需要注意什么呢?接下来就给读者详细介绍 Python 局部函数的用法。
首先,和局部变量一样,默认情况下局部函数只能在其所在函数的作用域内使用。举个例子:
#全局函数
def outdef ():
#局部函数
def indef():
print("http://c.biancheng.net/python/")
#调用局部函数
indef()
#调用全局函数
outdef()程序执行结果为:
http://c.biancheng.net/python/就如同全局函数返回其局部变量,就可以扩大该变量的作用域一样,通过将局部函数作为所在函数的返回值,也可以扩大局部函数的使用范围。例如,修改上面程序为:
#全局函数
def outdef ():
#局部函数
def indef():
print("调用局部函数")
#调用局部函数
return indef
#调用全局函数
new_indef = outdef()
调用全局函数中的局部函数
new_indef()程序执行结果为:
调用局部函数因此,对于局部函数的作用域,可以总结为:如果所在函数没有返回局部函数,则局部函数的可用范围仅限于所在函数内部;反之,如果所在函数将局部函数作为返回值,则局部函数的作用域就会扩大,既可以在所在函数内部使用,也可以在所在函数的作用域中使用。
以上面程序中的 outdef() 和 indef() 为例,如果 outdef() 不将 indef 作为返回值,则 indef() 只能在 outdef() 函数内部使用;反之,则 indef() 函数既可以在 outdef() 函数内部使用,也可以在 outdef() 函数的作用域,也就是全局范围内使用。
有关函数返回函数,更详细的讲解,可阅读《Python函数高级方法》一节。
另外值得一提的是,如果局部函数中定义有和所在函数中变量同名的变量,也会发生“遮蔽”的问题。例如:
#全局函数
def outdef ():
name = "所在函数中定义的 name 变量"
#局部函数
def indef():
print(name)
name = "局部函数中定义的 name 变量"
indef()
#调用全局函数
outdef()执行此程序,Python 解释器会报如下错误:
UnboundLocalError: local variable 'name' referenced before assignment此错误直译过来的意思是“局部变量 name 还没定义就使用”。导致该错误的原因就在于,局部函数 indef() 中定义的 name 变量遮蔽了所在函数 outdef() 中定义的 name 变量。再加上,indef() 函数中 name 变量的定义位于 print() 输出语句之后,导致 print(name) 语句在执行时找不到定义的 name 变量,因此程序报错。
由于这里的 name 变量也是局部变量,因此前面章节讲解的 globals() 函数或者 globals 关键字,并不适用于解决此问题。这里可以使用 Python 提供的 nonlocal 关键字。
例如,修改上面程序为:
#全局函数
def outdef ():
name = "所在函数中定义的 name 变量"
#局部函数
def indef():
nonlocal name
print(name)
#修改name变量的值
name = "局部函数中定义的 name 变量"
indef()
#调用全局函数
outdef()程序执行结果为:
所在函数中定义的 name 变量十七、Python函数使用方法(高级用法)
前面章节,已经介绍了 Python 函数的所有基本用法和使用注意事项。但是,Python 函数的用法还远不止此,Python 函数还支持赋值、作为其他函数的参数以及作为其他函数的返回值。
首先,Python 允许直接将函数赋值给其它变量,这样做的效果是,程序中也可以用其他变量来调用该函数,更加灵活。例如:
def my_def ():
print("正在执行 my_def 函数")
#将函数赋值给其他变量
other = my_def
#间接调用 my_def() 函数
other()程序执行结果为:
正在执行 my_def 函数不仅如此,Python 还支持将函数以参数的形式传入其他函数中。例如:
def add (a,b):
return a+b
def multi(a,b):
return a*b
def my_def(a,b,dis):
return dis(a,b)
#求 2 个数的和
print(my_def(3,4,add))
#求 2 个数的乘积
print(my_def(3,4,multi))程序执行结果为:
7
12通过分析上面程序不难看出,通过使用函数作为参数,可以在调用函数时动态传入函数,从而实现动态改变函数中的部分实现代码,在不同场景中赋予函数不同的作用。
与此同时,Python 还支持函数的返回值也为函数。例如:
def my_def ():
#局部函数
def indef():
print("调用局部函数")
#调用局部函数
return indef
other_def = my_def()
#调用局部的 indef() 函数
other_def()程序执行结果为:
调用局部函数可以看到,通过返回值为函数的形式,可以扩大局部函数的作用域。
十八、什么是闭包,Python闭包(初学者必读)
前面章节中,已经对 Python 闭包做了初步的讲解,本节将详解介绍到底什么是闭包,以及使用闭包有哪些好处。
闭包,又称闭包函数或者闭合函数,其实和前面讲的嵌套函数类似,不同之处在于,闭包中外部函数返回的不是一个具体的值,而是一个函数。一般情况下,返回的函数会赋值给一个变量,这个变量可以在后面被继续执行调用。
例如,计算一个数的 n 次幂,用闭包可以写成下面的代码:
#闭包函数,其中 exponent 称为自由变量
def nth_power(exponent):
def exponent_of(base):
return base ** exponent
return exponent_of # 返回值是 exponent_of 函数
square = nth_power(2) # 计算一个数的平方
cube = nth_power(3) # 计算一个数的立方
print(square(2)) # 计算 2 的平方
print(cube(2)) # 计算 2 的立方运行结果为:
4
8在上面程序中,外部函数 nth_power() 的返回值是函数 exponent_of(),而不是一个具体的数值。
需要注意的是,在执行完 square = nth_power(2) 和 cube = nth_power(3) 后,外部函数 nth_power() 的参数 exponent 会和内部函数 exponent_of 一起赋值给 squre 和 cube,这样在之后调用 square(2) 或者 cube(2) 时,程序就能顺利地输出结果,而不会报错说参数 exponent 没有定义。
看到这里,读者可能会问,为什么要闭包呢?上面的程序,完全可以写成下面的形式:
def nth_power_rewrite(base, exponent):
return base ** exponent上面程序确实可以实现相同的功能,不过使用闭包,可以让程序变得更简洁易读。设想一下,比如需要计算很多个数的平方,那么读者觉得写成下面哪一种形式更好呢?
# 不使用闭包
res1 = nth_power_rewrite(base1, 2)
res2 = nth_power_rewrite(base2, 2)
res3 = nth_power_rewrite(base3, 2)
# 使用闭包
square = nth_power(2)
res1 = square(base1)
res2 = square(base2)
res3 = square(base3)显然第二种方式表达更为简洁,在每次调用函数时,都可以少输入一个参数。
其次,和缩减嵌套函数的优点类似,函数开头需要做一些额外工作,当需要多次调用该函数时,如果将那些额外工作的代码放在外部函数,就可以减少多次调用导致的不必要开销,提高程序的运行效率。
Python闭包的__closure__属性
闭包比普通的函数多了一个 __closure__ 属性,该属性记录着自由变量的地址。当闭包被调用时,系统就会根据该地址找到对应的自由变量,完成整体的函数调用。
以 nth_power() 为例,当其被调用时,可以通过 __closure__ 属性获取自由变量(也就是程序中的 exponent 参数)存储的地址,例如:
def nth_power(exponent):
def exponent_of(base):
return base ** exponent
return exponent_of
square = nth_power(2)
#查看 __closure__ 的值
print(square.__closure__)输出结果为:
(| ,) | 可以看到,显示的内容是一个 int 整数类型,这就是 square 中自由变量 exponent 的初始值。还可以看到,__closure__ 属性的类型是一个元组,这表明闭包可以支持多个自由变量的形式。
十九、Python lambda表达式(匿名函数)及用法
对于定义一个简单的函数,Python 还提供了另外一种方法,即使用本节介绍的 lambda 表达式。
lambda 表达式,又称匿名函数,常用来表示内部仅包含 1 行表达式的函数。如果一个函数的函数体仅有 1 行表达式,则该函数就可以用 lambda 表达式来代替。
lambda 表达式的语法格式如下:
name = lambda [list] : 表达式其中,定义 lambda 表达式,必须使用 lambda 关键字;[list] 作为可选参数,等同于定义函数是指定的参数列表;value 为该表达式的名称。
该语法格式转换成普通函数的形式,如下所示:
def name(list):
return 表达式
name(list)显然,使用普通方法定义此函数,需要 3 行代码,而使用 lambda 表达式仅需 1 行。
举个例子,如果设计一个求 2 个数之和的函数,使用普通函数的方式,定义如下:
def add(x, y):
return x+ y
print(add(3,4))程序执行结果为:
7由于上面程序中,add() 函数内部仅有 1 行表达式,因此该函数可以直接用 lambda 表达式表示:
add = lambda x,y:x+y
print(add(3,4))程序输出结果为:
7可以这样理解 lambda 表达式,其就是简单函数(函数体仅是单行的表达式)的简写版本。相比函数,lamba 表达式具有以下 2 个优势:
- 对于单行函数,使用 lambda 表达式可以省去定义函数的过程,让代码更加简洁;
- 对于不需要多次复用的函数,使用 lambda 表达式可以在用完之后立即释放,提高程序执行的性能。
二十、Python eval()和exec()函数详解
eval() 和 exec() 函数都属于 Python 的内置函数,由于这两个函数在功能和用法方面都有相似之处,所以将它们放到一节进行介绍。
eval() 和 exec() 函数的功能是相似的,都可以执行一个字符串形式的 Python 代码(代码以字符串的形式提供),相当于一个 Python 的解释器。二者不同之处在于,eval() 执行完要返回结果,而 exec() 执行完不返回结果(文章后续会给出详细示例)。
1、eval()和exec()的用法
eval() 函数的语法格式为:
eval(expression, globals=None, locals=None, /)而 exec() 函数的语法格式如下:
exec(expression, globals=None, locals=None, /)可以看到,二者的语法格式除了函数名,其他都相同,其中各个参数的具体含义如下:
- expression:这个参数是一个字符串,代表要执行的语句 。该语句受后面两个字典类型参数 globals 和 locals 的限制,只有在 globals 字典和 locals 字典作用域内的函数和变量才能被执行。
- globals:这个参数管控的是一个全局的命名空间,即 expression 可以使用全局命名空间中的函数。如果只是提供了 globals 参数,而没有提供自定义的 __builtins__,则系统会将当前环境中的 __builtins__ 复制到自己提供的 globals 中,然后才会进行计算;如果连 globals 这个参数都没有被提供,则使用 Python 的全局命名空间。
- locals:这个参数管控的是一个局部的命名空间,和 globals 类似,当它和 globals 中有重复或冲突时,以 locals 的为准。如果 locals 没有被提供,则默认为 globals。
注意,__builtins__ 是 Python 的内建模块,平时使用的 int、str、abs 都在这个模块中。通过 print(dic["__builtins__"]) 语句可以查看 __builtins__ 所对应的 value。
首先,通过如下的例子来演示参数 globals 作用域的作用,注意观察它是何时将 __builtins__ 复制 globals 字典中去的:
dic={} #定义一个字典
dic['b'] = 3 #在 dic 中加一条元素,key 为 b
print (dic.keys()) #先将 dic 的 key 打印出来,有一个元素 b
exec("a = 4", dic) #在 exec 执行的语句后面跟一个作用域 dic
print(dic.keys()) #exec 后,dic 的 key 多了一个运行结果为:
dict_keys(['b'])
dict_keys(['b', '__builtins__', 'a'])上面的代码是在作用域 dic 下执行了一句 a = 4 的代码。可以看出,exec() 之前 dic 中的 key 只有一个 b。执行完 exec() 之后,系统在 dic 中生成了两个新的 key,分别是 a 和 __builtins__。其中,a 为执行语句生成的变量,系统将其放到指定的作用域字典里;__builtins__ 是系统加入的内置 key。
locals参数的用法就很简单了,举个例子:
a=10
b=20
c=30
g={'a':6, 'b':8} #定义一个字典
t={'b':100, 'c':10} #定义一个字典
print(eval('a+b+c', g, t)) #定义一个字典 116输出结果为:
1162、exec()和eval()的区别
前面已经讲过,它们的区别在于,eval() 执行完会返回结果,而 exec() 执行完不返回结果。举个例子:
a = 1
exec("a = 2") #相当于直接执行 a=2
print(a)
a = exec("2+3") #相当于直接执行 2+3,但是并没有返回值,a 应为 None
print(a)
a = eval('2+3') #执行 2+3,并把结果返回给 a
print(a)运行结果为:
2
None
5可以看出,exec() 中最适合放置运行后没有结果的语句,而 eval() 中适合放置有结果返回的语句。
如果 eval() 里放置一个没有结果返回的语句会怎样呢?例如下面代码:
a= eval("a = 2")这时 Python 解释器会报 SyntaxError 错误,提示 eval() 中不识别等号语法。
3、eval() 和 exec() 函数的应用场景
在使用 Python 开发服务端程序时,这两个函数应用得非常广泛。例如,客户端向服务端发送一段字符串代码,服务端无需关心具体的内容,直接跳过 eval() 或 exec() 来执行,这样的设计会使服务端与客户端的耦合度更低,系统更易扩展。
另外,如果读者以后接触 TensorFlow 框架,就会发现该框架中的静态图就是类似这个原理实现的:
- TensorFlow 中先将张量定义在一个静态图里,这就相当将键值对添加到字典里一样;
- TensorFlow 中通过 session 和张量的 eval() 函数来进行具体值的运算,就当于使用 eval() 函数进行具体值的运算一样。
需要注意的是,在使用 eval() 或是 exec() 来处理请求代码时,函数 eval() 和 exec() 常常会被黑客利用,成为可以执行系统级命令的入口点,进而来攻击网站。解决方法是:通过设置其命名空间里的可执行函数,来限制 eval() 和 exec() 的执行范围。
二十一、Python exec()和eval()的使用注意事项
使用 exec() 和 eval() 函数时,一定要记住,它们的第一个参数是字符串,而字符串的内容一定要是可执行的代码。
以 eval() 函数为例,用代码演示常犯的错误:
s="hello"
print(eval(s))输出结果为:
Traceback (most recent call last):
File "C:\Users\mengma\Desktop\demo.py", line 2, in
print(eval(s))
File "", line 1, in
NameError: name 'hello' is not defined 上面例子出错的地方在于,字符串的内容是 hello,而 hello 并不是可执行的代码(除非定义了一个变量叫作 hello)。
如果要将字符串 hello 通过 print 函数打印出来,可以写成如下的样子:
s="hello"
print(eval('s'))输出结果为:
hello这种写法是要 eval() 执行 "hello" 这句代码。这个 hello 是有引号的,在代码中代表字符串的意思,所以可以执行。
同理,也可以写成这样:
s='"hello"' #s 是个字符串,字符串的内容是带引号的 hello
print(eval(s))输出结果为:
hello这种写法的意思是 s 是个字符串,并且其内容是个带引号的 hello。所以直接将 s 放入到函数 eval() 中也可以执行。
除了以上这种方式,还可以不去改变原有字符串 s 的写法,直接使用 repr() 函数来进行转化,也可以得到同样的效果。例如:
s="hello"
print(eval(repr(s))) #使用函数 repr() 进行转化输出结果为:
hello注意,虽然函数 eval() 与 str() 的返回值都是字符串。但是使用 str() 函数对 s 进行转化,程序同样会报错,例如:
s="hello"
print(eval(str(s)))输出结果为:
Traceback (most recent call last):
File "C:\Users\mengma\Desktop\demo.py", line 2, in
print(eval(str(s)))
File "", line 1, in
NameError: name 'hello' is not defined 为什么会有这个区别呢?同样对带字符串 s 的转化,使用 repr() 与 str() 得到的结果是有差别的,直接将二者的结果打印出来,就可以很明显地看出不同。见下面代码:
s="hello"
print(repr(s))
print(str(s))输出结果为:
'hello'
hello可见使用 repr() 返回的内容,输出后会在两边多一个单引号。
注意,在编写代码时,一般会使 repr() 函数来生成动态的字符串,再传入到 eval() 或 exec() 函数内,实现动态执行代码的功能。
二十二、Python函数式编程(map()、filter()和reduce())详解
所谓函数式编程,是指代码中每一块都是不可变的,都由纯函数的形式组成。这里的纯函数,是指函数本身相互独立、互不影响,对于相同的输入,总会有相同的输出。
除此之外,函数式编程还具有一个特点,即允许把函数本身作为参数传入另一个函数,还允许返回一个函数。
例如,想让列表中的元素值都变为原来的两倍,可以使用如下函数实现:
def multiply_2(list):
for index in range(0, len(list)):
list[index] *= 2
return list需要注意的是,这段代码不是一个纯函数的形式,因为列表中元素的值被改变了,如果多次调用 multiply_2() 函数,那么每次得到的结果都不一样。
而要想让 multiply_2() 成为一个纯函数的形式,就得重新创建一个新的列表并返回,也就是写成下面这种形式:
def multiply_2_pure(list):
new_list = []
for item in list:
new_list.append(item * 2)
return new_list函数式编程的优点,主要在于其纯函数和不可变的特性使程序更加健壮,易于调试和测试;缺点主要在于限制多,难写。
注意,纯粹的函数式编程语言(比如 Scala),其编写的函数中是没有变量的,因此可以保证,只要输入是确定的,输出就是确定的;而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出。
Python 允许使用变量,所以它并不是一门纯函数式编程语言。Python 仅对函数式编程提供了部分支持,主要包括 map()、filter() 和 reduce() 这 3 个函数,它们通常都结合 lambda 匿名函数一起使用。接下来就对这 3 个函数的用法做逐一介绍。
1、Python map()函数
map() 函数的基本语法格式如下:
map(function, iterable)其中,function 参数表示要传入一个函数,其可以是内置函数、自定义函数或者 lambda 匿名函数;iterable 表示一个或多个可迭代对象,可以是列表、字符串等。
map() 函数的功能是对可迭代对象中的每个元素,都调用指定的函数,并返回一个 map 对象。
注意,该函数返回的是一个 map 对象,不能直接输出,可以通过 for 循环或者 list() 函数来显示。
【例 1】还是对列表中的每个元素乘以 2。
listDemo = [1, 2, 3, 4, 5]
new_list = map(lambda x: x * 2, listDemo)
print(list(new_list))运行结果为:
[2, 4, 6, 8, 10]【例 2】map() 函数可传入多个可迭代对象作为参数。
listDemo1 = [1, 2, 3, 4, 5]
listDemo2 = [3, 4, 5, 6, 7]
new_list = map(lambda x,y: x + y, listDemo1,listDemo2)
print(list(new_list))运行结果为:
[4, 6, 8, 10, 12]注意,由于 map() 函数是直接由用 C 语言写的,运行时不需要通过 Python 解释器间接调用,并且内部做了诸多优化,所以相比其他方法,此方法的运行效率最高。
2、Python filter()函数
filter()函数的基本语法格式如下:
filter(function, iterable)此格式中,funcition 参数表示要传入一个函数,iterable 表示一个可迭代对象。
filter() 函数的功能是对 iterable 中的每个元素,都使用 function 函数判断,并返回 True 或者 False,最后将返回 True 的元素组成一个新的可遍历的集合。
【例 3】返回一个列表中的所有偶数。
listDemo = [1, 2, 3, 4, 5]
new_list = filter(lambda x: x % 2 == 0, listDemo)
print(list(new_list))运行结果为:
[2, 4]3、Python reduce()函数
reduce() 函数通常用来对一个集合做一些累积操作,其基本语法格式为:
reduce(function, iterable)其中,function 规定必须是一个包含 2 个参数的函数;iterable 表示可迭代对象。
注意,由于 reduce() 函数在 Python 3.x 中已经被移除,放入了 functools 模块,因此在使用该函数之前,需先导入 functools 模块。
【例 5】计算某个列表元素的乘积。
import functools
listDemo = [1, 2, 3, 4, 5]
product = functools.reduce(lambda x, y: x * y, listDemo)
print(product)运行结果为:
1204、总结
通常来说,当对集合中的元素进行一些操作时,如果操作非常简单,比如相加、累积这种,那么应该优先考虑使用 map()、filter()、reduce() 实现。另外,在数据量非常多的情况下(比如机器学习的应用),一般更倾向于函数式编程的表示,因为效率更高。
当然,在数据量不多的情况下,使用 for 循环等方式也可以。不过,如果要对集合中的元素做一些比较复杂的操作,考虑到代码的可读性,通常会使用 for 循环。
二十三、Python 3函数注解:为函数提供类型提示信息
函数注解是 Python 3 最独特的功能之一,关于它的介绍,官方文档是这么说的,“函数注解是关于用户自定义函数使用类型的完全可选的元信息”。也就是说,官方将函数注解的用途归结为:为函数中的形参和返回值提供类型提示信息。
下面是对 Python 官方文档中的示例稍作修改后的程序,可以很好的展示如何定义并获取函数注解:
def f(ham:str,egg:str='eggs')->str:
pass
print(f.__annotations__)输出结果为:
{'ham': , 'egg': , 'return': } 如上所示,给函数中的参数做注解的方法是在形参后添加冒号“:”,后接需添加的注解(可以是类(如 str、int 等),也可以是字符串或者表示式);给返回值做注解的方法是将注解添加到 def 语句结尾的冒号和 -> 之间。
注意,如果参数有默认值,参数注解位于冒号和等号之间。比如 eggs:str='eggs',它表示 eggs 参数的默认值为 'eggs',添加的注解为 str。
给函数定义好注解之后,可以通过函数对象的 __annotations__ 属性获取,它是一个字典,在应用运行期间可以获取。这里再举一个例子:
def square(number:"一个数字")->"返回number的平方":
return number**2
print(square(10))
print(square.__annotations__)运行结果为:
100
{'number': '一个数字', 'return': '返回number的平方'}事实上,函数注解并不局限于类型提示,而且在 Python 及其标准库中也没有单个功能可以利用这种注解,这也是这个功能独特的原因。
注意,函数注解没有任何语法上的意义,只是为函数参数和返回值做注解,并在运行获取这些注解,仅此而已。换句话说,为函数做的注解,Python不做检查,不做强制,不做验证,什么操作都不做,函数注解对Python解释器没任何意义。
函数注解可能的用法
PEP 3107 作为提议函数注解的官方文档,其中列出了以下可能的使用场景:
- 提供类型信息:包括类型检查、让 IDE 显示函数接受和返回的类型、适配、与其他语言的桥梁、数据库查询映射、RPC参数编组等;
- 其他信息:函数参数和返回值的文档。
总之,虽然函数注解存在的时间和 Python 3 一样长,但目前仍未找到任一常见且积极维护的包,将函数注解用作类型检查之外的功能。Python 3 最初发布时包含函数注解的最初目的也仅是用于试验和玩耍。
二十四、提高代码可读性和颜值的几点建议(初学者必读)
学习过程中,我们经常会阅读他人写的代码,如果注意观察就会发现,好的代码本身就是一份文档,解决同样的问题,不同的人编写的代码,其可读性千差万别。
有些人的设计风格和代码风格犹如热刀切黄油,从顶层到底层的代码看下来酣畅淋漓,注释详尽又精简;深入到细节代码,无需注释也能理解清清楚楚。而有些人,代码勉勉强强能跑起来,遇到稍微复杂的情况就会出崩溃,且代码中处处都是堆积在一起的变量、函数和类,很难理清代码的实现思路。
Python 创始人 Guido van Rossum(吉多·范罗苏姆)说过,代码的阅读频率远高于编写代码的频率。毕竟是在编写代码的时候,我们自己也需要对代码进行反复阅读和调试,来确认代码能够按照期望运行。
本节,在读者学会如何使用 Puython 函数的基础上,教大家怎么才能合理分解代码,提高代码的可读性。
首先,大家在编程过程中,一定要围绕一个中心思想:不写重复性的代码。因为,重复代码往往是可以通过使用条件、循环、构造函数和类(后续章节会做详细介绍)来解决的。
例如,仔细观察下面的代码:
if i_am_rich:
money = 100
send(money)
else:
money = 10
send(money)这段代码中,同样的 send 语句出现了两次,其实它完全可以进行合并,把代码改造成下面这样:
if i_am_rich:
money = 100
else:
money = 10
send(money)与此同时,还要学会刻意地减少代码的迭代层数,尽可能让 Python 代码扁平化。例如:
def send(money):
if is_server_dead:
LOG('server dead')
return
else:
if is_server_timed_out:
LOG('server timed out')
return
else:
result = get_result_from_server()
if result == MONEY_IS_NOT_ENOUGH:
LOG('you do not have enough money')
return
else:
if result == TRANSACTION_SUCCEED:
LOG('OK')
return
else:
LOG('something wrong')
return上面这段代码层层缩进,如果我们没有比较强的逻辑分析能力,理清这段代码是比较困难。其实,这段代码完全可以改成如下这样:
def send(money):
if is_server_dead:
LOG('server dead')
return
if is_server_timed_out:
LOG('server timed out')
return
result = get_result_from_server()
if result == MONET_IS_NOT_ENOUGH:
LOG('you do not have enough money')
return
if result == TRANSACTION_SUCCEED:
LOG('OK')
return
LOG('something wrong')可以看到,所有的判断语句都位于同一层级,同之前的代码格式相比,代码层次清晰了很多。
另外,在使用函数时,函数的粒度应该尽可能细,不要让一个函数做太多的事情。往往一个复杂的函数,我们要尽可能地把它拆分成几个功能简单的函数,然后合并起来。
如何拆分函数呢?这里,举一个二分搜索的例子。给定一个非递减整数数组,和一个 target 值,要求你找到数组中最小的一个数 x,满足 x*x > target,如果不存在,则返回 -1。
大家不妨先独立完成,写完后再对照着来看下面的代码,找出自己的问题:
def solve(arr, target):
l, r = 0, len(arr) - 1
ret = -1
while l <= r:
m = (l + r) // 2
if arr[m] * arr[m] > target:
ret = m
r = m - 1
else:
l = m + 1
if ret == -1:
return -1
else:
return arr[ret]
print(solve([1, 2, 3, 4, 5, 6], 8))
print(solve([1, 2, 3, 4, 5, 6], 9))
print(solve([1, 2, 3, 4, 5, 6], 0))
print(solve([1, 2, 3, 4, 5, 6], 40))对于上面这样的写法,应付算法比赛和面试已经绰绰有余。但如果从工程的角度考虑,还需要进行深度优化:
def comp(x, target):
return x * x > target
def binary_search(arr, target):
l, r = 0, len(arr) - 1
ret = -1
while l <= r:
m = (l + r) // 2
if comp(arr[m], target):
ret = m
r = m - 1
else:
l = m + 1
return ret
def solve(arr, target):
id = binary_search(arr, target)
if id != -1:
return arr[id]
return -1
print(solve([1, 2, 3, 4, 5, 6], 8))
print(solve([1, 2, 3, 4, 5, 6], 9))
print(solve([1, 2, 3, 4, 5, 6], 0))
print(solve([1, 2, 3, 4, 5, 6], 40))在这段代码中,我们把不同功能的代码单独提取出来作为独立的函数。其中,comp() 函数作为核心判断,提取出来之后,可以让整个程序更清晰;同时,还把二分搜索的主程序提取了出来,只负责二分搜索;最后的 solve() 函数拿到结果,决定返回不存在,还是返回值。这样一来,每个函数各司其职,阅读性也能得到一定提高。