别再使用循环的方式筛选元素了!开发常用的Stream流+Lambda表达式过滤元素了解过吗?10000字超详细解析
目录
1. Stream 流的简单展示
1.1 抛出问题
1.2 传统解决问题的编码方式
1.3 Stream 流的方式过滤元素
2. Stream 流的核心思想
3. Stream 流的使用
3.1 获取 stream 流
3.1.1 单列集合获取 stream 流
3.1.2 双列集合获取 stream 流
3.1.3 数组获取 stream 流
3.1.4 零散数据获取 stream 流
3.2 处理加工 stream 流
3.2.1 stream 流常用的方法
3.2.2 filter 方法代码演示
3.2.3 limit 方法代码演示
3.2.4 skip 方法代码演示
3.2.5 distinct 方法代码演示
3.2.6 concat 方法代码演示
3.2.7 map 方法代码演示
3.3 stream 流终结方法
3.3.1 stream 终结流常用方法
3.3.2 toArray 方法解析
3.3.3 collect 方法解析
1. Stream 流的简单展示
1.1 抛出问题
现创建一个集合并添加元素,如下代码,完成以下两个需求
需求1:把所有以 "张" 开头的元素添加到一个新的集合,输出结果;
需求2:把所有以 "张" 开头且长度为3的元素添加到另一个新的集合,输出结果;
public class Test6 {
public static void main(String[] args) {
List list = new ArrayList();
list.add("张阳光");
list.add("张三");
list.add("李四");
list.add("赵六");
list.add("张大炮");
}
}1.2 传统解决问题的编码方式
拿到这个题的时候,按照我们的惯性思维,大多数人应该都想着遍历数组,然后拿出数组中的每个元素做比对,满足要求就存放到另一个新的数组中去,这是大多数人的常见解决思路。
代码我已经写好了,如下所示,逻辑比较简单,就不做过多说明了
public class Test6 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("张阳光");
list.add("张三");
list.add("李四");
list.add("赵六");
list.add("张大炮");
// 需求1解决方案
// 创建一个新数组 list2
ArrayList list2 = new ArrayList();
// for 循环遍历 list
for (String name : list) {
// 调用API startWith
if (name.startsWith("张")){
// 将满足条件的加入到新的数组
list2.add(name);
}
}
System.out.println(list2);
// 需求2解决方案
// 创建一个新数组 list3
ArrayList list3 = new ArrayList<>();
// 遍历刚才的 list2 集合
for (String name : list2) {
// 判断长度是否为3
if (name.length() == 3){
// 满足条件则加入到 list3 中
list3.add(name);
}
}
System.out.println(list3);
}
} 我运行一下上面的代码,就可以在控制台得到结果,是我们期望的输出结果
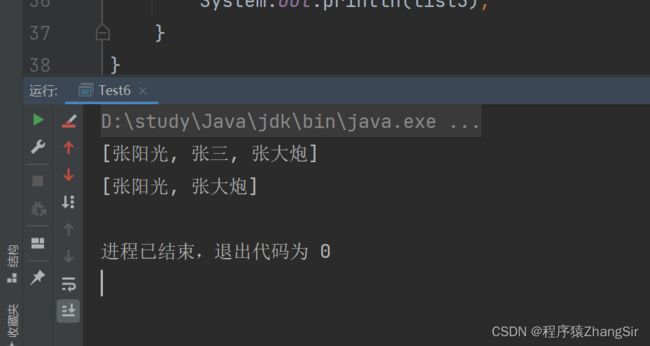
1.3 Stream 流的方式过滤元素
刚才的普遍解决方案想必大家都已经知道了,下面我来给大家展示一下使用 Stream 流如何做到上面同样的效果。
代码如下
通过使用 stream 流,调用它里面已经定义好的 filter 过滤器方法,通过链式编程的方式一行代码就可以搞定
public class Test6 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("张阳光");
list.add("张三");
list.add("李四");
list.add("赵六");
list.add("张大炮");
// 需求1解决方案
// list.stream()获取 list 集合的 stream 流
// filter 为过滤方法。参数列表中通过 Lambda 表达式书写过滤规则
// 过滤完毕 forEach 循环打印
list.stream().filter(name -> name.startsWith("张")).forEach(name -> System.out.println(name));
System.out.println("--------------------------");
// 需求2解决方案
// 这里两次 filter 过滤两次,如果还有过滤条件可以继续链式添加 filter ,无限套娃
list.stream().filter(name -> name.startsWith("张")).filter(name -> name.length() == 3).forEach(name -> System.out.println(name));
}
} 运行上述代码,仍然可以在控制台得到期望结果
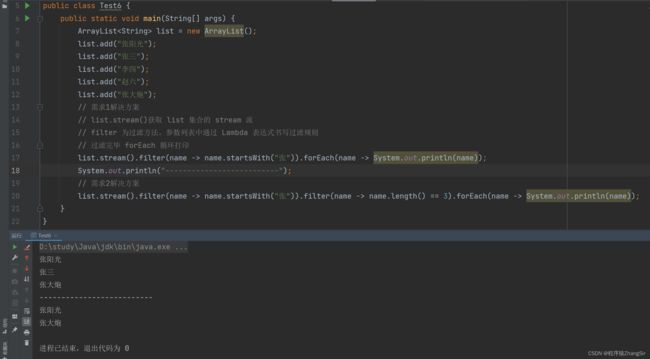
2. Stream 流的核心思想
同学们可以把 stream 流看作是一个流水线,我们待处理的数据就是一个待加工的零件,这个零件(要处理的数据)就会经过流水线的加工(stream 流),成为一个合格的产品(最终得到我们想要的数据)。
每次 filter 过滤就好比是一次加工过滤,或许我们需要过滤一次,又或许需要过滤多次。
我们对于 stream 流的操作基本可以分为"中间方法" 和 "终结方法" 两种,中间方法就是我们要对 stream 流中的数据做的各种操作,上述的过滤只是其中最为常用的一种,终结方法就是对 stream 流中的数据已经处理完毕,需要做打印输出,此时就不能再调用其他的方法。
3. Stream 流的使用
使用 stream 流处理数据,一般可以分为三个重要步骤;
第一步:获取到 stream 流,并把数据放上去;
第二步:对数据做一系列中间方法做加工;
第三步:对数据使用终结方法做最后的出炉成品;
3.1 获取 stream 流
在 Java 在,不同的对象获取流的方式也是不相同的,下图列举了几种非常常用的对象获取 stream流的方式

3.1.1 单列集合获取 stream 流
单列集合获取 stream 非常简单,在 Collection 中已经为我们提供好了方法,直接通过 "." 的方式调用即可,上面的例子中也已经写过了,这里就不再作演示了,
3.1.2 双列集合获取 stream 流
双列集合,例如常用的 Map 虽然不能直接获取 stream 流,但是我们可以调用其他方法将双列集合转化成单列集合的方式间接获取 stream流,如下代码
// 创建单列集合
Map map = new HashMap();
// 调用 keySet 方法得到所有的键集合,键集合为单列集合,再获取 stream流
map.keySet().stream();
// 调用 entrySet 获取到所有键值对对象的单列集合,再获取 stream流
map.entrySet().stream(); 3.1.3 数组获取 stream 流
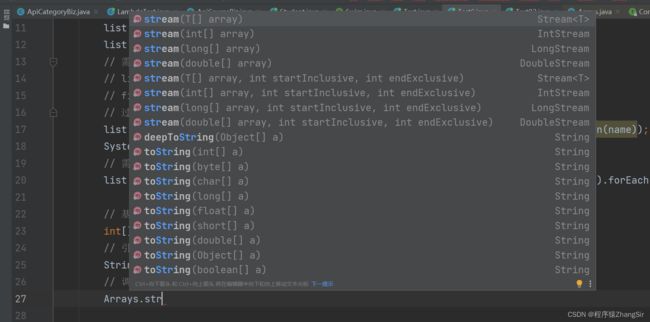
数组我们又可以分为存放基本数据类型的数组和存放引用数据类型的数组,他们在获取 stream 流时可以通过工具类 Arrays 中的方法获取 stream 流,调用方法时会发生重载;
我给大家看一下
// 基本数据类型数组
int[] arr = {1,2,3,4,5};
// 引用数据类型数组
String[] arr2 = {"abd","dec","qqq"};
// 调用 Arrays 类中的 stream 方法获取 stream 流
Arrays.stream(arr);
Arrays.stream(arr2);上面的连行代码看似一样,但他们只是方法名相同,实际在运行的时候会发生重载,如下图所示,可以看到,Arrays 类中有好几个stream 方法针对于不同的数据类型
3.1.4 零散数据获取 stream 流
零散的数据也可以获取 stream 流,可以通过调用 Stream 类中的 of 方法,
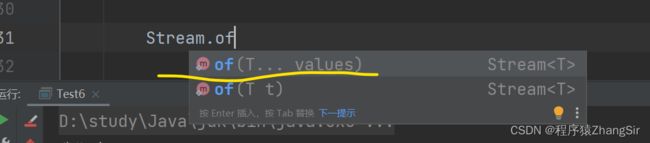
大家可以看到,在调用的时候,方法的参数中显示的是可变参数,所以也就是说参数的底层其实还是一个数组;
如下所示,参数可以为 字符串,整型,浮点型,这些零散不统一的数据,但是,这种方式几乎在开发中根本不会用,我们不会吧数据类型不一致的数据放在一起,所以自己敲代码的时候玩玩就可以了,这种 获取 stream 流的方式了解即可,主要记住前面三种方式,单列集合,双列集合,数组这三个获取 stream 流的方式是重点。
Stream.of("1",2,3.4).forEach(s -> System.out.println(s));3.2 处理加工 stream 流
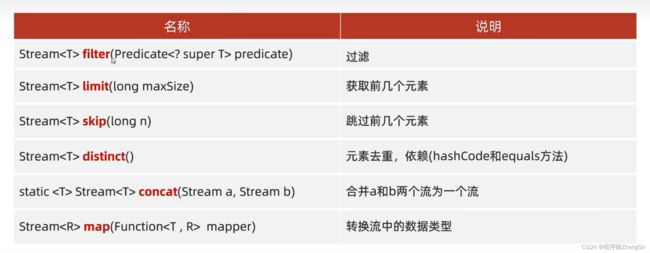
3.2.1 stream 流常用的方法
stream 流对数据进行加工有以下常用的六个方法,而最最最为常用的就是 filter 过滤,实际开发过程中,我们通常会将数据存放在集合中,然后给予一些业务场景,就需要对集合进行过滤,就需要使用到 filter 过滤。
3.2.2 filter 方法代码演示
filter 方法我们在上面已经演示过了,所以这里就不再重复啰嗦了。
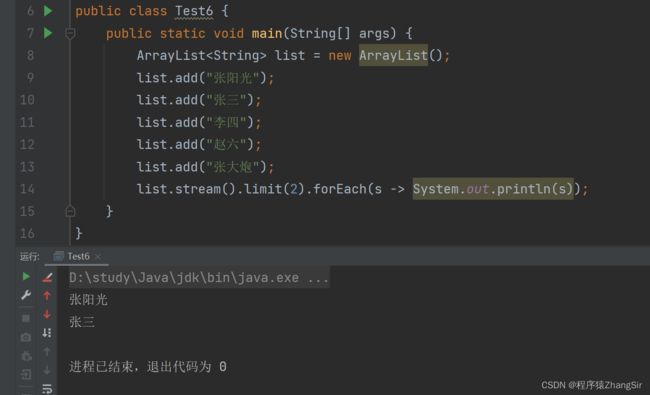
3.2.3 limit 方法代码演示
limit 表示获取前几个元素,方法参数类型为 Long,代码如下所示
public class Test6 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("张阳光");
list.add("张三");
list.add("李四");
list.add("赵六");
list.add("张大炮");
list.stream().limit(2).forEach(s -> System.out.println(s));
}
} 运行,我们就可以在控制台得到,前两个元素,也就是 "张阳光","张三",如下图所示
3.2.4 skip 方法代码演示
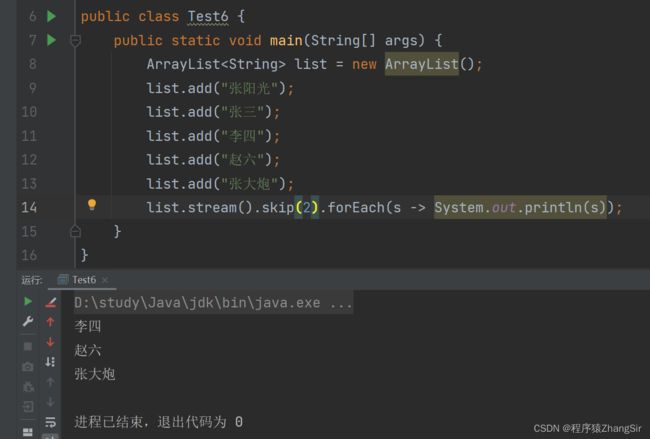
skip 方法,表示跳过几个元素,方法参数类型为 Long,代码如下所示
public class Test6 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("张阳光");
list.add("张三");
list.add("李四");
list.add("赵六");
list.add("张大炮");
list.stream().skip(2).forEach(s -> System.out.println(s));
}
} 运行,跳过前两个元素,我们就可以在控制台得到后三个元素,也就是 "李四","赵六","张大炮",如下图所示
3.2.5 distinct 方法代码演示
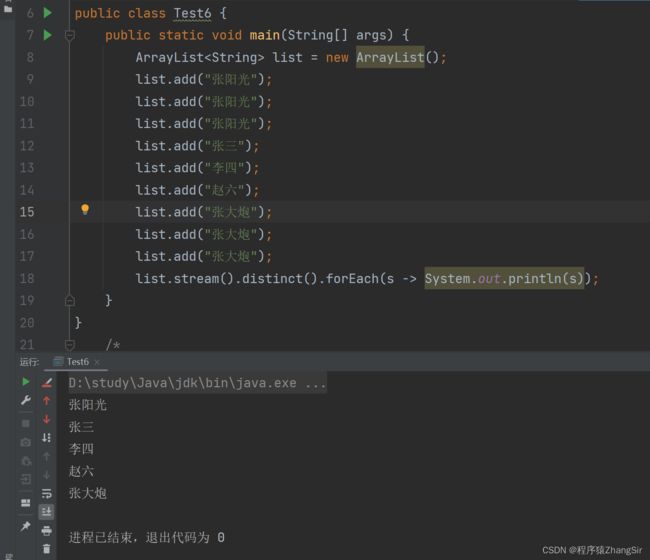
distinct 去重方法,方法没有参数,和数据库中的去重是同样的作用,这里它底层去重是依据 equals 和 hashCode 方法,所以如果集合中添加的是自定义类型数据,请务必在类中重写 equals 和 hashCode 方法;
演示代码如下,我多添加几个相同的元素,打印输出
public class Test6 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("张阳光");
list.add("张阳光");
list.add("张阳光");
list.add("张三");
list.add("李四");
list.add("赵六");
list.add("张大炮");
list.add("张大炮");
list.add("张大炮");
list.stream().distinct().forEach(s -> System.out.println(s));
}
} 运行,去掉相同的元素,我们预期在控制台得到五个元素,如下图所示
3.2.6 concat 方法代码演示
concat 合并两个流的方法,调用此方法的时候,建议两个要合并的流存放相同类型的数据,如果存放的不相同,那么合并后的流存放的类型就两个流数据类型的父类,可能会导致原来自己独有的方法无法被调用,这一点要注意。
演示代码如下
我们综合前面的方法一并使用
public class Test6 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("张阳光");
list.add("张阳光");
list.add("张三");
list.add("李四");
list.add("赵六");
list.add("张大炮");
list.add("张大炮");
list.add("张大炮");
// list.stream().distinct().limit(2) 先去重然后取前两个数据
// list.stream().distinct().skip(2) 先去重跳过前两个数据
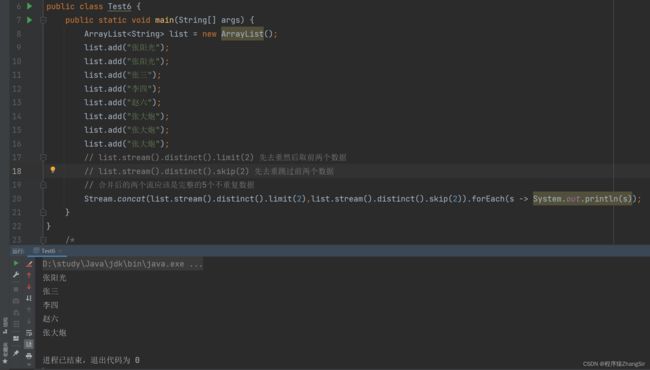
// 合并后的两个流应该是完整的5个不重复数据
Stream.concat(
list.stream().distinct().limit(2),
list.stream().distinct().skip(2)
).forEach(s -> System.out.println(s));
}
} 运行上述代码,期望值应该是完整的5个不重复的数据,如下图
3.2.7 map 方法代码演示
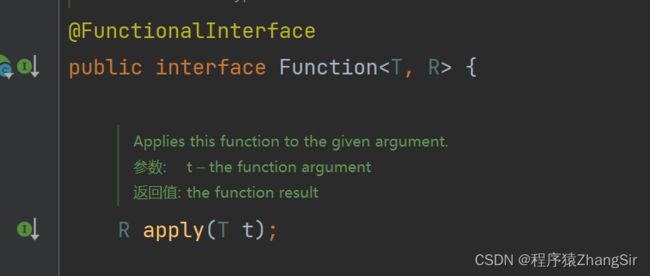
我们先来看一下 map 方法的参数,参数为 Function。
Stream map(Function mapper); 我们点击 Function 查看一下,它是一个函数式接口,那么它就可以简化成 Lambda 表达式的写法,接口中有一个 apply 方法,
map 方法可以用来转换流中数据的类型,我将之前集合中的元素内容修改一下,在每个元素的后面加上 "-年龄" ,
ArrayList list = new ArrayList();
list.add("张阳光-21");
list.add("张三-22");
list.add("李四-20");
list.add("赵六-19");
list.add("张大炮-18"); 现在我提出问题:要将他们的年龄从集合中取出来并转化成 Integer 类型输出,该怎么做?
(1)匿名内部类的写法
因为直接采用 Lambda 表达式的写法部分同学可能会不太能看懂,我先从匿名内部类的方式开始写,如下图,在参数中采用匿名内部类的形式书写,第一个泛型 String 是流中原本存放的数据类型,第二个泛型则是想要转为成的参数类型,这里应写为 Integer 我还没有改各位同学知道即可,

然后我们就可以再重写方法中编写具体逻辑了,如下代码
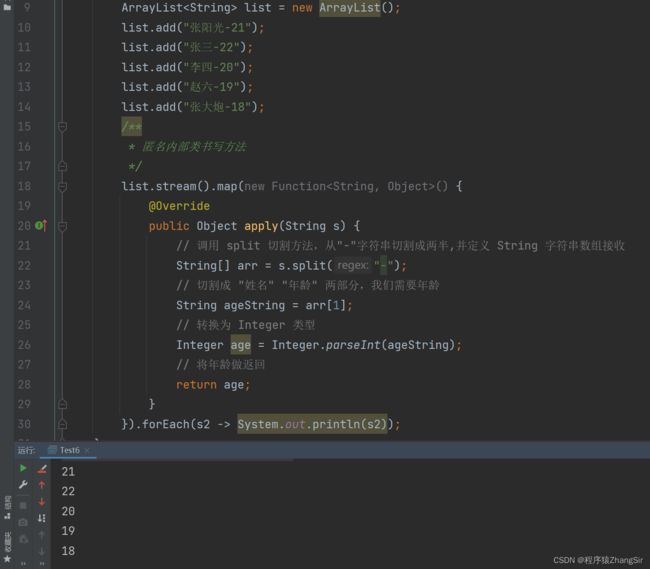
public class Test6 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("张阳光-21");
list.add("张三-22");
list.add("李四-20");
list.add("赵六-19");
list.add("张大炮-18");
/**
* 匿名内部类书写方法
*/
list.stream().map(new Function() {
@Override
public Object apply(String s) {
// 调用 split 切割方法,从"-"字符串切割成两半,并定义 String 字符串数组接收
String[] arr = s.split("-");
// 切割成 "姓名" "年龄" 两部分,我们需要年龄
String ageString = arr[1];
// 转换为 Integer 类型
Integer age = Integer.parseInt(ageString);
// 将年龄做返回
return age;
}
}).forEach(s2 -> System.out.println(s2));
}
} 运行代码,在控制台就可以得到5个年龄数据,如下
(2)Lambda 表达式的方式书写
现在我们再来采用 Lambda 表达式的书写方法优化上述逻辑代码,上面的匿名内部类代码我并没有删除,各位同学可以对比观看,
如下,采用 Lambda 表达式,一行代码就可以搞定,完全不需要想匿名内部类那么复杂
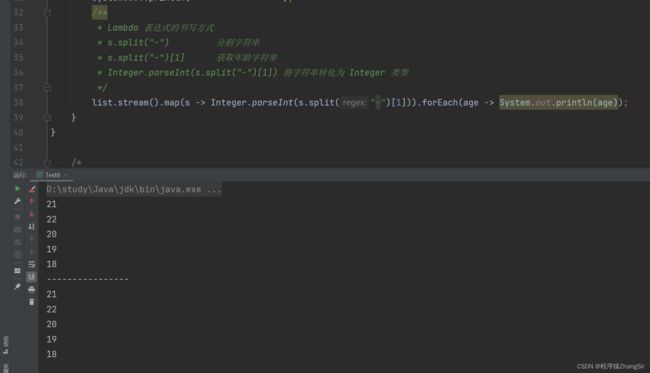
public class Test6 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("张阳光-21");
list.add("张三-22");
list.add("李四-20");
list.add("赵六-19");
list.add("张大炮-18");
/**
* 匿名内部类书写方法
*/
list.stream().map(new Function() {
@Override
public Object apply(String s) {
// 调用 split 切割方法,从"-"字符串切割成两半,并定义 String 字符串数组接收
String[] arr = s.split("-");
// 切割成 "姓名" "年龄" 两部分,我们需要年龄
String ageString = arr[1];
// 转换为 Integer 类型
Integer age = Integer.parseInt(ageString);
// 将年龄做返回
return age;
}
}).forEach(s2 -> System.out.println(s2));
System.out.println("----------------");
/**
* Lambda 表达式的书写方式
* s.split("-") 分割字符串
* s.split("-")[1] 获取年龄字符串
* Integer.parseInt(s.split("-")[1]) 将字符串转化为 Integer 类型
*/
list.stream().map(s -> Integer.parseInt(s.split("-")[1])).forEach(age -> System.out.println(age));
}
} 运行上述代码,得出结果,Lambda 表达式同样可以得到相同的效果。
3.3 stream 流终结方法
3.3.1 stream 终结流常用方法
经过了 stream 流的加工操作,我们就得到我符合我们条件的数据,然后我们就可以对数据进行最后的封装,有常用的四种方式,如下图所示
这里的话 forEach方法和 count 方法就不展示了,比较简单,重点来说一下 toArray 方法和 collect 方法

3.3.2 toArray 方法解析
toArray 方法一共有两个,一个空参方法,一个带参方法;
(1)toArray 空参方法
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("张阳光-21");
list.add("张三-22");
list.add("李四-20");
list.add("赵六-19");
list.add("张大炮-18");
// toArray 空参方法,方法返回值是一个确定的 Object 数组
Object[] objects = list.stream().toArray();
// 直接打印输出的是 objects 的内存地址
System.out.println(objects);
// 调用 Arrays 类中的 toString 方法
System.out.println(Arrays.toString(objects));
} 运行得出结果

(2)toArray 带参方法
toArray 无参方法的返回值只能是 Object 类型的数组,当我们业务中想要的不是 Object 类型数组时,就可以使用带参 toArray 方法自定义返回的数组类型。
如下为 toArray 方法的源码,方法的参数为 IntFunction
A[] toArray(IntFunction generator); 而它是一个函数式接口,所以可以采用匿名内部类或 Lambda 表达式的形式传入参数

采用匿名内部类的写法代码如下
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("张阳光-21");
list.add("张三-22");
list.add("李四-20");
list.add("赵六-19");
list.add("张大炮-18");
// IntFunction 的泛型指具体类型的数组
// apply 方法的参数指数组的长度,即流中元素的个数
// 整个方法的目的就是返回一个指定聚类数据类型的且长度为流中数据元素个数的数组
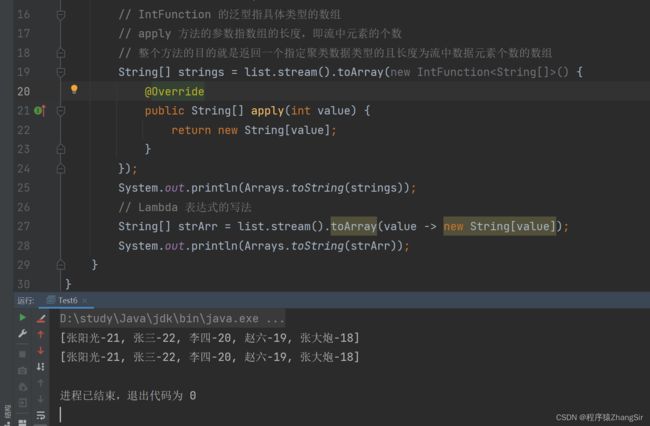
String[] strings = list.stream().toArray(new IntFunction() {
@Override
public String[] apply(int value) {
return new String[value];
}
});
System.out.println(Arrays.toString(strings));
} 优化匿名内部类采用 Lambda 表达式代码如下,两行代码搞定
// Lambda 表达式的写法
String[] strArr = list.stream().toArray(value -> new String[value]);
System.out.println(Arrays.toString(strArr));运行结果如下,两种方式都能得到期望的结果
3.3.3 collect 方法解析
开发时通常会把数据存放到List,Set,Map集合中。针对于三种不同的集合,自然需要对应不同的方法。
(1)针对于 List 集合
直接调用 collectors.toList 即可
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("张阳光-21");
list.add("张三-22");
list.add("李四-20");
list.add("赵六-19");
list.add("张大炮-18");
// 过滤所有不为 "张" 开头的元素
List collect = list.stream().filter(name -> name.startsWith("张")).collect(Collectors.toList());
System.out.println(collect);
} (2)针对于 Set 集合
直接调用 collectors.toSet 即可
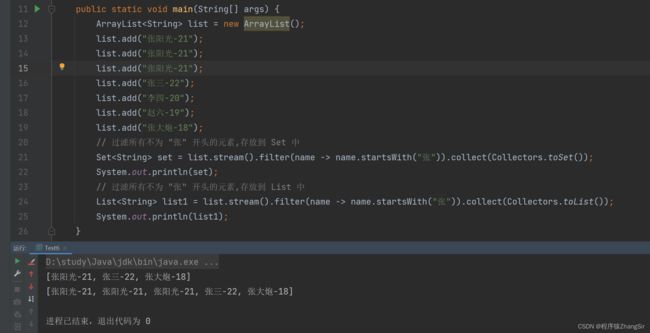
// 过滤所有不为 "张" 开头的元素,存放到 Set 中
Set set = list.stream().filter(name -> name.startsWith("张")).collect(Collectors.toSet());
System.out.println(set); toList 方法和 toSet 方法有什么区别?
这两个方法的区别就和 List,Set 两个集合本身的区别差不多,toList 方法返回的集合有序可重复,而 toSet 方法返回的集合无需不可重复,一个例子即可验证
我们在上面的集合中添加一个重复的数据,分别调用两个方法,看运行结果
(3)针对于 Map 集合
调用 toMap 方法即可,但不同于 toList,toSet 的是,Map 是双列集合,K和V,所以我们需要确定键和值的数据类型。
对上面的题目做改变,现在我们把 List 集合中的元素拆开,让名字作为 Key,年龄作为 Value 存放到 Map 集合中,该怎么做?
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("张阳光-21");
list.add("张三-22");
list.add("李四-20");
list.add("赵六-19");
list.add("张大炮-18");
// k.split("-")[0] 分割字符串并获取0索引处的数据类型作为 Key 的泛型
// Integer.parseInt(v.split("-")[1]) 分割字符串取1索引处的字符串再转化为 Integer 作为value的泛型
Map collect = list.stream().
collect(Collectors.toMap(k -> k.split("-")[0], v -> Integer.parseInt(v.split("-")[1])));
} 这里有一个点需要注意,当我们要把数据存放到 Map 集合中的时候,键是不能重复的,否则代码会报错,我在上面的代码中再添加一个("张三-22"),运行如下

因为在 Map 中,不允许有重复的 key ,所以如果想要存放到 Map 集合中的时候,请先使用 filter 过滤器过滤掉相同的 key 元素。