c语言入门-程序运行的过程
目录
程序运行的过程
1.编译
预编译
编译:
汇编
2.链接
1.段表的合并
2.符号表的合并和重定位
3.运行
预处理
#define
宏实现计算
#define和typedef
#define的替换规则
#和##---将参数插入代码中
带有副作用的宏
宏和函数比较
#undef---移除被定义的宏
#if---条件编译
#if defined---判断是否被定义
程序运行的过程
编译可以分为三个部分:预编译,编译, 汇编。
 我们写的代码是文本文件(.c文件),.c文件通过编译转换为.obj文件,.obj文件通过链接转换为.exe文件(可执行文件)。可执行文件在运行环境中运行。
我们写的代码是文本文件(.c文件),.c文件通过编译转换为.obj文件,.obj文件通过链接转换为.exe文件(可执行文件)。可执行文件在运行环境中运行。
.obj文件---二进制目标文件 .exe---二进制可执行文件
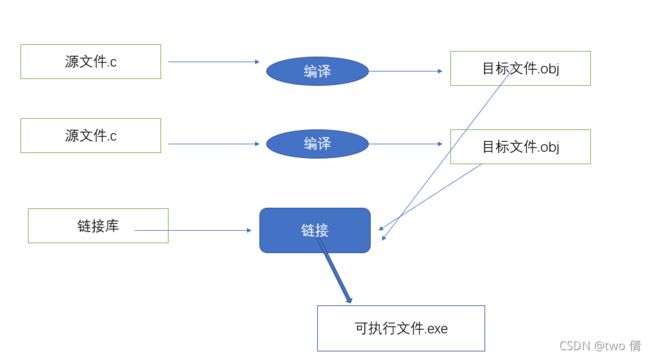
1.编译
由于vs是集成开发环境,所以使用linux来观察过程。
编译可以分为三个部分:预编译,编译, 汇编。
预编译
执行操作:
处理预处理指令(#include,#if……)
去掉注释
#define---宏展开
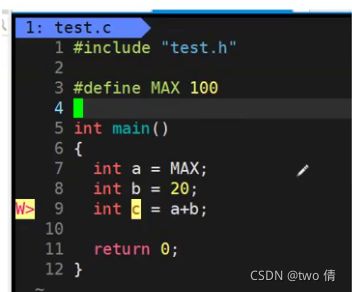
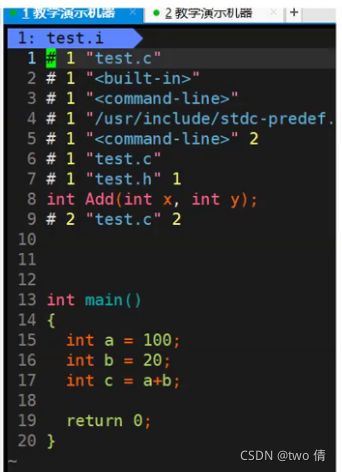
宏展开: MAX改成了100
编译:
将文本文件转化为汇编代码
词法分析
语法分析
语义分析
符号汇总
词法分析:
编译器将代码的字符序列自动转化为一系列的记号。
例如:array=(i+2)*j;
经过词法分析,得到以下这几个记号:
array ---标识符 = ---赋值
(---左圆括号 i---标识符
+---加号 2---数字
*---乘号 j---标识符
除了识别记号的同时,扫描器也完成了其他工作,例如,将标识符存放到符号表中,将数字,字符串常量放到文字表中。
语法分析:
语法分析器对词法分析得到的记号进行语法分析,将其化为各种表达式、或者语句等。同时进行判断,如果出现结构错误(例如:括号不匹配,逗号中英文格式……),编译器就会报告语句分析阶段错误。
语义分析:
编译器进行语义分析的是静态语义(编译期间确定),静态语义通常包括声明和类型的匹配,类型的转化。
例如:浮点型数据传给整形,发生隐式类型转化,而浮点型数据给指针,报错。
符号汇总:
汇总全局符号
汇编
形成符号表。在符号表中,程序中的每个标识符都和它的声明或使用信息绑定在一起,比如其数据类型、作用范围以及内存地址。
将汇编代码转为二进制文件目标文件(.obj)
2.链接
.obj文件转化为.exe文件
1.段表的合并
一个二进制文件按照段表来存储各种信息,例如:

这样的每一个段表对应每一个.o文件(linux下的可执行文件)
段表合并:例如text.o和add.o文件,将两者的段表按照某种规则可以合并到一起,完成代码实现。
2.符号表的合并和重定位
段表合并,其内的符号表也会合并。合并过程中,无效的符号表信息会被有效信息代替,这就是重定位。
3.运行
1.程序载入内存,有操作系统的情况下,由操作系统进行代码运行。没有时,程序根据别的方式进入内存。
2.代码从main函数开始运行
3.调用别的函数,开辟函数栈帧。
4.代码从main函数正常结束或者异常结束。
预处理
#include
int main()
{
printf("%s\n ", __FILE__);//代码文件名
printf("%d\n ", __LINE__);//行号
printf("%s \n", __TIME__);//代码运行时间
return 0;
} #define
定义宏 定义符号
#include
#define MAX 100
int main()
{
int m = MAX;
return 0;
} 预处理阶段---处理预处理指令---展开#include
预处理阶段---#define直接替换---代码里的MAX都被替换为100,MAX替换后消失
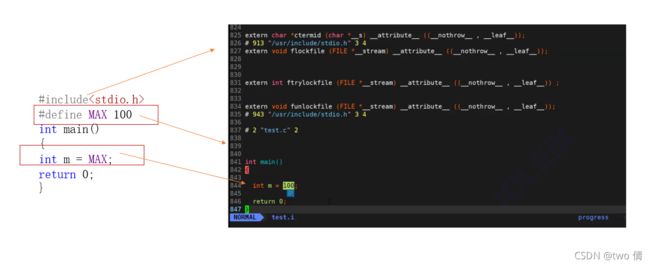
宏实现计算
#include
#define ADD(x,y) ((x)+(y))
int main()
{
printf("%d ", ADD(3, 4));
//x被替换为(3),y被替换为(4)
return 0;
} 括号的重要性---运算符的优先顺序,可能会影响值的结果
#include
#define MUL(x,y) x*y
#define FUN(x,y)((x)*(y))
int main()
{
printf("%d ", MUL(3+4, 4));
//结果19 x替换为3+4,y替换为4 计算式:3+4*4=19
printf("%d ", FUN(3 + 4, 4));
//结果28 x替换为(3+4),y替换为(4) 计算式:(3+4)*4=28
return 0;
} #define和typedef
#include
#define INT1 int //INT1定义为int,INT1是标识符,预编译被替换为int
typedef int INT2;//int被重命名为INT2,INT2是类型
int main()
{
int m = 10;
printf("%d ", m);
INT1 a = 20;
printf("%d ", a);
INT2 b = 30;
printf("%d ", b);
return 0;
} #include
typedef int* type1;//int*被重命名为type1,type1是类型
#define type2 int*//type2是标识符,内容是int*,预编译产生替换
int main()
{
type2 a, b;
//type2被替换为int*,int*a,b ---a是int类型的指针,b是int类型的变量
type1 c, d;
//type1是一种类型---c,d都是int类型的指针
return 0;
} #define的替换规则
#define在预编译期间替换
宏不可以实现递归,但是可以嵌套使用,例如:ADD(ADD(3,4),5)
#和##---将参数插入代码中
在C语言中宏定义中,#的功能是将其后面的宏参数进行字符串化操作。
#include
#define print( ch) printf(""#ch"的值%d\n", ch)
#define fun(ch) printf(""#ch"")
int main()
{
int a = 10;
printf("%c的值%d\n", 'a', 10);
int b = 20;
printf("%c的值%d\n",'b',b);
print(a);
//相当于printf("%c的值%d\n", 'b', b);
print(b);
fun(ch);//打印ch
//相当于 printf("%s",ch)
return 0;
} ##是连接符,前加##或后加##,将标记作为一个合法的标识符的一部分,不是字符串.多用于多行的宏定义中。
#include
#define fun(x,y) x##y
int main()
{
int arr = 10;
printf("%d ", fun(ar, r));//ar r在fun里面连接成为arr
return 0;
} 带有副作用的宏
替换过程中,例如下列代码的自增操作,使变量的值方式改变
#include
#define MAX(x,y) ((x)>(y)?(x):(y))
int main()
{
printf("%d ", MAX(3 + 2, 1));
int a = 2;
int b = 3;
printf("%d ", MAX(a++, b++));
//((a++) > (b++) ? (x) : (y));
// 2>3判断,a变为3,b变为4
return 0;
} #include
int MAX(x, y)
{
int m = x > y ? x : y;
return m;
}
int main()
{
printf("%d ", MAX(3 + 2, 1));
int a = 2;
int b = 3;
printf("%d ", MAX(a++, b++));
// 函数传入2,3 打印结束之后a为3,b为4
printf("%d ", a);
printf("%d ", b);
return 0;
} 宏和函数比较
宏优点:
- 函数调用,每一次都要开辟函数栈帧,时间占用多,宏在预编译时直接替换,时间性能上更好,运算速度快。
- 函数有参数的类型要求,宏没有类型要求
宏缺点:
- 不进行类型检查,容易出错
- 宏代码在每一次调用,都要插入调用函数中,如果宏内容十分长,空间占用多。而函数调用的代码就那一个,不会插入进调用函数。
- 宏不能调试,函数可以调试
- 宏在计算上有可能产生错误(运算符优先级,副作用的参数……)
- 宏不能递归,函数可以递归
#undef---移除被定义的宏
#include
#define ADD(x,y) ( (x)+(y))
int main()
{
printf("%.2lf ", ADD(2.4 , 0.9));
#undef ADD//ADD被移除
printf("%.2lf ", ADD(2.4 , 0.9));//error :无法引用的外部符号
return 0;
} #if---条件编译
#if开始,#endif结束
#if的条件为真,#if和#endif之间的代码参与编译,为假时,不进行编译
在预编译期间进行,#if条件满足,预编译期间让代码参入了后续编译,不满足,则后续代码不会出现#if和#endif的中间代码内容。
#include
int main()
{
#if 0//为假
printf("hi");
#endif
printf("hello");//打印hello
return 0;
}
多分支的条件编译
#include
#define a 1
int main()
{
//int a = 1;
//#if 在预编译期间运行,int a=1在编译进行,预编译时期没有a
//可以使用宏定义
#if a<1
printf("hi");
#elif a==1
printf("hello");
#else
printf("he");
#endif
} #if defined---判断是否被定义
#include
#define MAX 2
int main()
{
#if defined MAX
printf("yes");
#else
printf("no");
#endif
return 0;
}