kafka的讲解与Linux上安装
目录
1、Kafka背景
2、Kafka应用场景
3、Kafka架构原理
3.1、Producer And Consumer
3.2、Topic
4、安装教程
首先我们先了解一下kafka的作用与背景(如果已非常了解kafka那么请直接跳过)
1、Kafka背景
Kafka它本质上是一个消息系统,由当时从LinkedIn出来创业的三人小组开发,他们开发出了Apache Kafka实时信息队列技术,该技术致力于为各行各业的公司提供实时数据处理服务解决方案。Kafka为LinkedIn的中枢神经系统,管理从各个应用程序的汇聚,这些数据经过处理后再被分发到其他地方。Kafka不同于传统的企业信息队列系统,它是以近乎实时的方式处理流经一个公司的所有数据,目前已经服务于LinkedIn、Netflix、Uber以及Verizon,并为此建立了实时信息处理平台。
流水数据是所有站点对其网站使用情况做报表时都要用到的数据中最常用的一部分,流水数据包括PV,浏览内容信息以及搜索记录等。这些数据通常是先以日志文件的形式存在,然后有周期的去对这些日志文件进行统计分析处理,然后获得需要的KPI指标结果。
2、Kafka应用场景
我们在接触一门新技术或是新语言时,得明白这门技术(或是语言)的应用场景,也就说要明白它能做什么,服务的对象是谁,下面用一个图来说明,如下图所示: 
首先,Kafka可以应用于消息系统,比如,当下较为热门的消息推送,这些消息推送系统的消息源,可以使用Kafka作为系统的核心组建来完成消息的生产和消息的消费。然后是网站的行迹,我们可以将企业的Portal,用户的操作记录等信息发送到Kafka中,按照实际业务需求,可以进行实时监控,或者做离线处理等。最后,一个是日志收集,类似于Flume套件这样的日志收集系统,但Kafka的设计架构采用push/pull,适合异构集群,Kafka可以批量提交消息,对Producer来说,在性能方面基本上是无消耗的,而在Consumer端中,我们可以使用HDFS这类的分布式文件存储系统进行存储。
3、Kafka架构原理
Kafka的设计之初是希望做一个统一的信息收集平台,能够实时的收集反馈信息,并且具有良好的容错能力。Kafka中我们最直观的感受就是它的消费者与生产者,如下图所示:
3.1、Producer And Consumer
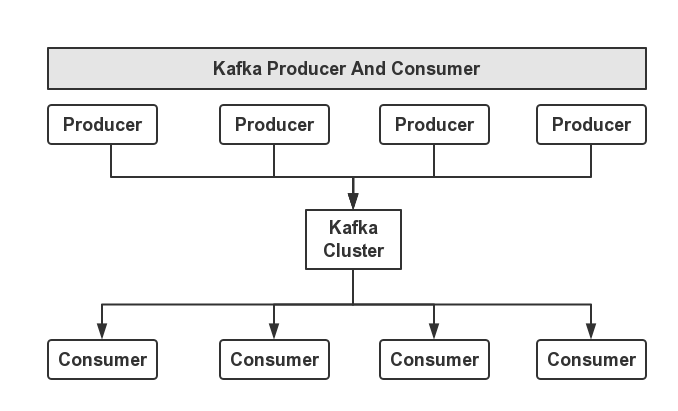
这里Kafka对消息的保存是根据Topic进行归类的,由消息生产者(Producer)和消息消费者(Consumer)组成,另外,每一个Server称为一个Broker。对于Kafka集群而言,Producer和Consumer都依赖于ZooKeeper来保证数据的一致性。
3.2、Topic
在每条消息输送到Kafka集群后,消息都会由一个Type,这个Type被称为一个Topic,不同的Topic的消息是分开存储的。如下图所示:
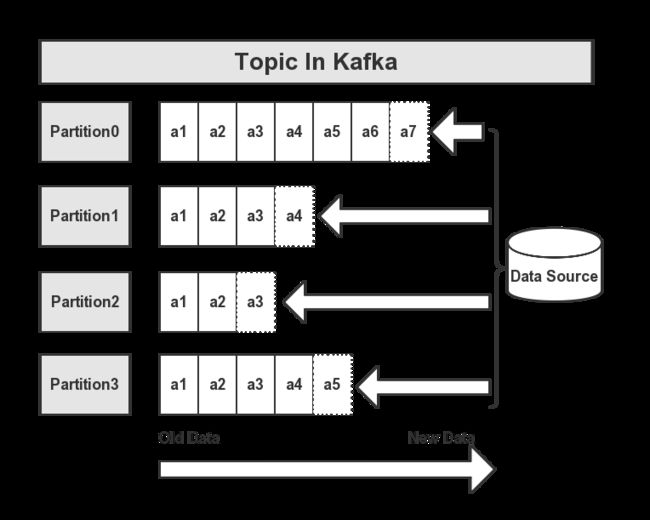
一个Topic会被归类为一则消息,每个Topic可以被分割为多个Partition,在每条消息中,它在文件中的位置称为Offset,用于标记唯一一条消息。在Kafka中,消息被消费后,消息仍然会被保留一定时间后在删除,比如在配置信息中,文件信息保留7天,那么7天后,不管Kafka中的消息是否被消费,都会被删除;以此来释放磁盘空间,减少磁盘的IO消耗。
在Kafka中,一个Topic的多个分区,被分布在Kafka集群的多个Server上,每个Server负责分区中消息的读写操作。另外,Kafka还可以配置分区需要备份的个数,以便提高可用行。由于用到来ZK来协调,每个分区都有一个Server为Leader状态,服务对外响应(如读写操作),若该Leader宕机,会由其他的Follower来选举出新的Leader来保证集群的高可用性。
4、安装教程
使用docker-compose 搭建 kafka集群 + 可视化工具
Docker-compose简介
Docker Compose是一个用来定义和运行复杂应用的Docker工具。
一个使用Docker容器的应用,通常由多个容器组成。使用Docker Compose不再需要使用shell脚本来启动容器。
Compose 通过一个配置文件来管理多个Docker容器,在配置文件中,所有的容器通过services来定义,然后使用docker-compose脚本来启动,停止和重启应用,和应用中的服务以及所有依赖服务的容器,非常适合组合使用多个容器进行开发的场景。
注意:使用 docker-compose 搭建,需要先安装(建议使用国内镜像下载)
# 官方地址
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
# 国内镜像
curl -L https://get.daocloud.io/docker/compose/releases/download/1.29.1/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-composedocker-compose授权
# 授权
sudo chmod +x /usr/local/bin/docker-compose
# 查看一下version,显示有版本号那就说明安装成功了
docker-compose version
创建目录
mkdir /usr/local/docker/kafka进入目录
cd /usr/local/docker/kafka创建 docker-compose 文件(:wq!或shift+z+z进行保存)
vim docker-compose.yml配置(只需要zookeeper容器ip和服务器id需要进行替换 “//”不需要删除)
version: '3'
networks:
docker_network:
external: false
services:
zookeeper:
image: wurstmeister/zookeeper
networks:
- docker_network
container_name: zookeeper
ports:
- 12181:2181
environment:
- TZ=Asia/Shanghai
kafka:
image: wurstmeister/kafka
networks:
- docker_network
container_name: kafka00
ports:
- 19090:19090
environment:
- TZ=Asia/Shanghai
- KAFKA_BROKER_ID=0
- KAFKA_ZOOKEEPER_CONNECT=zookeeper容器ip:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://服务器ip:19090
- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:19090
kafka1:
image: wurstmeister/kafka
networks:
- docker_network
container_name: kafka01
ports:
- 19091:19091
environment:
- TZ=Asia/Shanghai
- KAFKA_BROKER_ID=1
- KAFKA_ZOOKEEPER_CONNECT=zookeeper容器ip:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://服务器ip:19091
- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:19091
kafka2:
image: wurstmeister/kafka
networks:
- docker_network
container_name: kafka02
ports:
- 19092:19092
environment:
- TZ=Asia/Shanghai
- KAFKA_BROKER_ID=2
- KAFKA_ZOOKEEPER_CONNECT=zookeeper容器ip:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://服务器ip:19092
- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:19092配置好后先进行下一步操作(查找好zookeeperIp后回来进行修改)
启动zookeeper
docker-compose up -d zookeeper查询容器ip
#查找容器
docker ps
#查看容器id
docker inspect 容器id
/// 运行完 翻到最下面 查看容器ip 并保存备用

获得容器Id后重新编译配置依次修改(:wq!或shift+z+z进行保存)
vim docker-compose.yml全部进行操作完毕后进行启动
kafka00:
docker-compose up -d kafkakafka01:
docker-compose up -d kafka1kafka02:
docker-compose up -d kafka2查看是否成功
docker ps

(如果docker ps查看发现没有,进入docker ps -a后查看有就说明镜像未启动成功,返回查看docker-compose.yml的服务器ID是否对应上,或者粘贴进去时是否缺少东西,或者//有没有被删除)
kafka-map 可视化工具

只需一行命令 (因为我的8080端口被占用 故映射其他端口 根据个人爱好设置)
docker run -d -p 9001:8080 -v /opt/kafka-map/data:/usr/local/kafka-map/data -e DEFAULT_USERNAME=admin -e DEFAULT_PASSWORD=admin --name kafka-map --restart always dushixiang/kafka-map:latest账号密码默认:admin