HA-Flink集群环境搭建(Yarn模式)
前置准备
CentOS7、jdk1.8、flink-1.10.1、hadoop-2.7.7、zookeeper-3.5.7
想要完成本期视频中所有操作,需要以下准备:
Linux下jdk的安装
Scala环境搭建-视频教程
大数据常用shell脚本之分发脚本编写-视频教程
大数据常用shell脚本之ha-hadoop脚本编写-视频教程
大数据常用shell脚本之zk脚本编写-视频教程
Hadoop单机伪分布式-视频教程
Hadoop完全分布式集群环境搭建-视频教程
HA(高可用)-Hadoop集群环境搭建视频+图文教程
Flink集群环境搭建(Standalone模式)-视频教程
HA-Flink集群环境搭建(Standalone模式)-视频教程
一、集群规划

二、集群配置
2.1 yarn-site.xml
<property>
<name>yarn.resourcemanager.am.max-attemptsname>
<value>4value>
property>
2.2 flink-conf.yaml
# 配置使用zookeeper来开启高可用模式
high-availability: zookeeper
# 配置zookeeper的地址,采用zookeeper集群时,可以使用逗号来分隔多个节点地址
high-availability.zookeeper.quorum: hadoop01:2181,hadoop02:2181,hadoop03:2181
# 在zookeeper上存储flink集群元信息的路径
high-availability.zookeeper.path.root: /ha-flink
# 持久化存储JobManager元数据的地址,zookeeper上存储的只是指向该元数据的指针信息
high-availability.storageDir: hdfs://hacluster:8020/flink/recovery
# 将已完成的作业上传到此目录中,让任务历史服务器进行监控
jobmanager.archive.fs.dir: hdfs://hacluster:8020/flink-jobhistory
historyserver.web.address: hadoop01
historyserver.web.port: 18082
# 任务历史服务器监控目录中已存档的作业
historyserver.archive.fs.dir: hdfs://hacluster:8020/flink-jobhistory
historyserver.web.refresh-interval: 10000
yarn.application-attempts: 10
2.3 masters
hadoop01:8081
hadoop02:8081
2.4 slaves
hadoop01
hadoop02
hadoop03
2.5 上传hadoop依赖包
作业归档需要记录在hdfs上,但是当前版本的flink把hadoop的一些依赖删除了,需要手动将jar包放到lib目录下 ,这里我用的是flink-shaded-hadoop-2-uber-2.7.5-10.0.jar
jar包(hadoop依赖包和wordcount依赖包)给大家提供下载地址:https://lanzous.com/b02b6wnfa密码:2oby
2.6 分发
[xiaokang@hadoop01 ~]$ distribution.sh /opt/software/flink-1.10.1
[xiaokang@hadoop01 ~]$ distribution.sh /opt/software/hadoop-2.7.7/etc/hadoop/yarn-site.xml
三、启动集群
3.1 启动ha-hadoop集群
[xiaokang@hadoop01 ~]$ ha-hadoop.sh start
# 创建作业归档目录
[xiaokang@hadoop01 ~]$ hdfs dfs -mkdir /flink-jobhistory
3.2 启动Flink集群和任务历史服务器
[xiaokang@hadoop01 ~]$ start-cluster.sh
[xiaokang@hadoop01 ~]$ historyserver.sh start
四、查看集群
4.1 jps进程查看
[xiaokang@hadoop01 ~]$ call-cluster.sh jps
--------hadoop01--------
10369 QuorumPeerMain
11297 NodeManager
12241 TaskManagerRunner
10885 JournalNode
10551 NameNode
12599 Jps
12538 HistoryServer
11083 DFSZKFailoverController
11211 JobHistoryServer
10669 DataNode
11823 StandaloneSessionClusterEntrypoint
--------hadoop02--------
8977 TaskManagerRunner
7459 QuorumPeerMain
7956 ResourceManager
7542 NameNode
7623 DataNode
8616 StandaloneSessionClusterEntrypoint
9066 Jps
7821 DFSZKFailoverController
7726 JournalNode
8047 NodeManager
--------hadoop03--------
7456 QuorumPeerMain
7636 JournalNode
7764 ResourceManager
7878 NodeManager
8345 TaskManagerRunner
8410 Jps
7532 DataNode
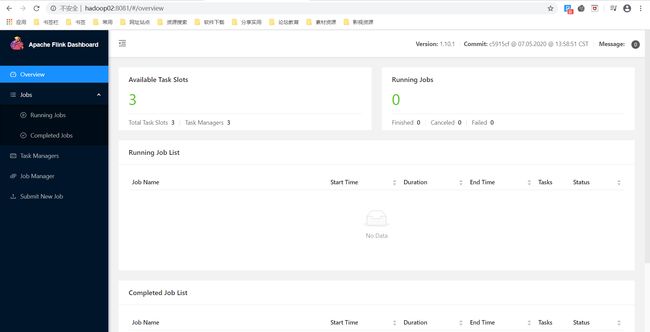
4.2 Web UI查看
两个 JobManager 和 任务历史服务器的端口号分别为 8081 、8081和 18082,界面应该如下:


五、提交任务
流计算词频统计案例源码:
package cool.xiaokang.wordcount
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/**
* TODO: Flink流计算WordCount
*
* @author: xiaokang
* @date: 2020/6/8 14:19
* 微信公众号:小康新鲜事儿
* 小康个人文档:https://www.xiaokang.cool/
*/
object FlinkStreamingWordCount1 {
def main(args: Array[String]): Unit = {
if(args==null || args.length!=2){
println("缺少参数,使用方法:flink run FlinkStreamingWordCount-1.0.jar -c cool.xiaokang.wordcount.FlinkStreamingWordCount hadoop 1124")
System.exit(1)
}
val host=args(0)
val port=args(1)
//1.初始化流计算环境
val streamEnv:StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//2.导入隐式转换
import org.apache.flink.streaming.api.scala._
//3.读取数据(Socket流)
val lines:DataStream[String] = streamEnv.socketTextStream(host, port.toInt)
//4.转换和处理数据并打印结果
val result=lines.flatMap(_.split(" "))
.map((_,1))
.keyBy(0) //分组算子 0或1代表前面的DataStream[(String,Int)]的下标,0代表单词,1代表词频
.sum(1) //聚合累加算子
result.print("Result:")
//5.启动流计算程序
streamEnv.execute("FlinkSteamWordCount-微信公众号:小康新鲜事儿")
}
}
提交作业:
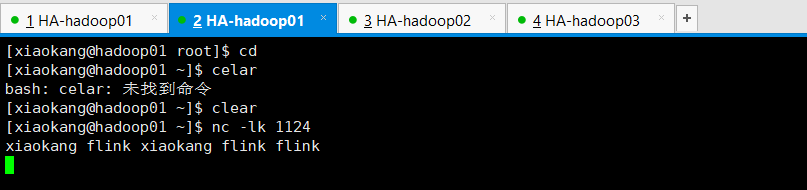
# 1.虚拟机内开启端口
[xiaokang@hadoop01 ~]$ nc -lk 1124
# 2.提交作业
[xiaokang@hadoop01 ~]$ flink run -m yarn-cluster -ys 1 -ynm flink-wordcount-xiaokang -c cool.xiaokang.wordcount.FlinkStreamingWordCount -d ~/FlinkStreamingWordCount-1.0.jar hadoop01 1124

输入数据以及结果(点击ApplicationMaster 查看):

运行过程中将正在服务的JobManager(进程为YarnJobClusterEntrypoint)给kill掉,测试是否高可用
[xiaokang@hadoop01 ~]$ kill -9 14840
此时hadoop01的8081无法访问,hadoop02会进行接管(重新提交刚才被中断的作业),这个过程需要稍等一会儿

再次输入数据后可以从结果看出是一个新作业:


结束任务后可以在任务历史服务器WebUI中进行查看:
