炫“库”行动-人大金仓有奖征文-金仓分析型数据库KADB分区表的使用
KADB 是北京人大金仓信息技术股份有限公司基于开源的greenplum数据库研发的一款分布式关系型数据库,全称是KingbaseAnalyticsDataBase。
分区表在KADB中一种重要的功能,一种好的分区策略可以通过只读取满足查询所需的分区来降低被扫描的数据量。每个分区在每一个计算节点上都是一个单独的物理文件或文件集合(这种情况出现在列寸表上)。就像在 宽列存表中读取一整行比从堆表读取同一行需要更多时间一样,在分区表中读取所有分区比从非分区表中读取相同 的数据要求更多的时间。同时KADB还可以利用分区表来创建行列混合存储的表,不同的分区使用不同的存储方式,还可以利用分区表来做冷热数据的压缩存储,提高查询速度的同时有效的利用的存储空间。总之利用好分区表对整个数据库系统来说都会有一定的提升。
KADB支持多种分区策略:支持rang和list以及两者混合的分区选项,无限制子分区层级数量。
rang分区键只能有一个,适用于时间、数字范围的分区
list可以有多个分区键,适用于字符值的分区。
- 创建一个rang分区表
CREATE TABLE t10 (
ID INT,
DATE DATE,
amt DECIMAL (10, 2)
) DISTRIBUTED BY (ID) PARTITION BY RANGE (DATE)(
PARTITION Jan21 START (DATE '2021-01-01') INCLUSIVE,
PARTITION Feb21 START (DATE '2021-02-01') INCLUSIVE,
PARTITION Mar21 START (DATE '2021-03-01') INCLUSIVE,
PARTITION Apr21 START (DATE '2021-04-01') INCLUSIVE,
PARTITION May21 START (DATE '2021-05-01') INCLUSIVE,
PARTITION Jun21 START (DATE '2021-06-01') INCLUSIVE,
PARTITION Jul21 START (DATE '2021-07-01') INCLUSIVE,
PARTITION Aug21 START (DATE '2021-08-01') INCLUSIVE,
PARTITION Sep21 START (DATE '2021-09-01') INCLUSIVE,
PARTITION Oct21 START (DATE '2021-10-01') INCLUSIVE,
PARTITION Nov21 START (DATE '2021-11-01') INCLUSIVE,
PARTITION Dec21 START (DATE '2021-12-01') INCLUSIVE END (DATE '2022-01-01') EXCLUSIVE
); 也可以是用every的方式快速创建分区
也可以是用every的方式快速创建分区
CREATE TABLE t11 (
ID INT,
DATE DATE,
amt DECIMAL (10, 2)
) DISTRIBUTED BY (ID) PARTITION BY RANGE (DATE)
(start (date '2021-01-01') end (date '2022-01-01') every (interval '1 month')
)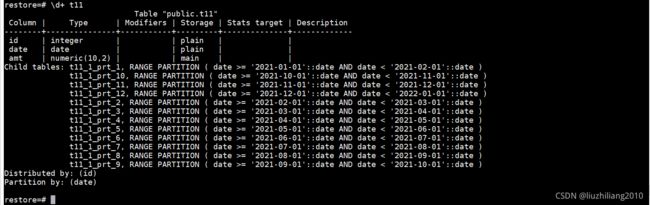
使用every会根据interval 中定义的跨越基数来自动创建分区, every 中interval 后的参数可以是 day 、 month、year 等根据需求来确定间隔,创建出的分区表命名时按照数字增量来命的,也可以使用关键字来定义分区表的名字。
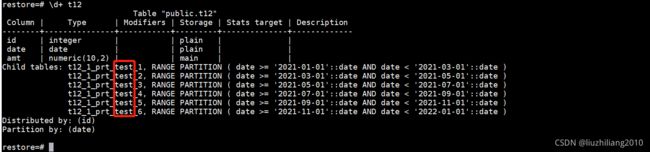
CREATE TABLE t12 (
ID INT,
DATE DATE,
amt DECIMAL (10, 2)
) DISTRIBUTED BY (ID) PARTITION BY RANGE (DATE)
(partition test start (date '2021-01-01') end (date '2022-01-01') every (interval '2 month')
)
- 创建一个list分区表
create table t13 (id int,sex char) distributed by (id) partition by list (sex) (partition p_boy values('b'), partition p_girl values('g'),default partition uknow);
default partition 为默认分区,即不符合分区规则的数据会进入到该分区。
- 创建一个多级分区
create table t14 (id int,date date,region text) distributed by (id)
partition by range (date)
subpartition by list (region)
subpartition template
(
subpartition prtregionusa values ('usa'),
subpartition prtregionchn values ('china'),
default subpartition prtregionother
)
(start (date '2021-01-01') end (date '2022-01-01') every (interval '1 month'),default partition prtdataother);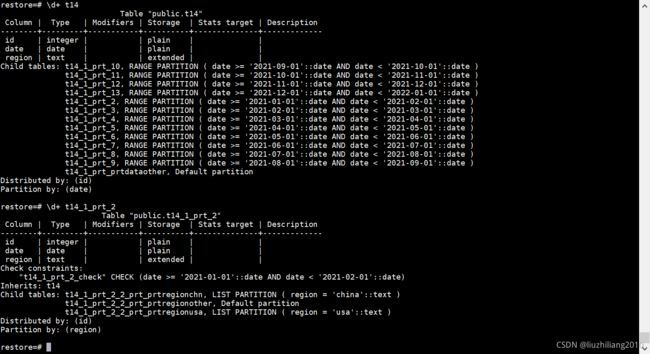
该表为二级分区表,即先用rang的方式按date分区,每个按时间分区的子分区再用list的方式按region分区,同时每级分区都有自己default分区。
- 现有分区表新增分区
alter table t10 add partition jan22 start (date '2022-01-01') end (date '2022-02-01');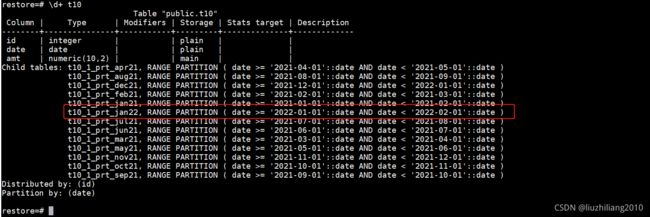
- 添加默认分区
alter table t10 add default partition prtdef;
- 重命名分区
alter table t10 rename partition for ('2021-01-01') to prt202101;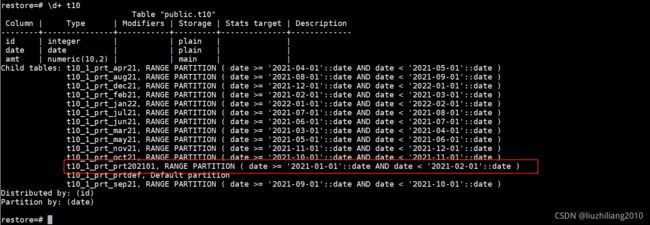
- 删除分区
alter table t10 drop partition for ('2022-01-01');- 删除默认分区
alter table t10 drop default partition;- 删除分区表数据
alter table t10 truncate partition for('2021-01-01');- 拆分分区,将202101的数据当中的1-15日的数据拆分到新的分区,16-31的数据拆分到新的分区
alter table t10 split partition for ('2021-01-01') at ('2021-01-16') into (partition prt202101a,partition prt202101b);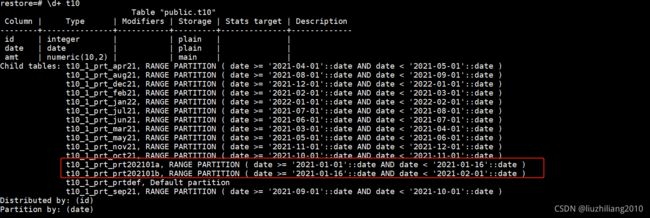
- 创建一个行列混合的分区表
create table t15 (id int,sex char) distributed by (id)
partition by list (sex) (partition p_boy values('b') with(appendonly=true,orientation=column),
partition p_girl values('g') with(appendonly=true,orientation=row)
);
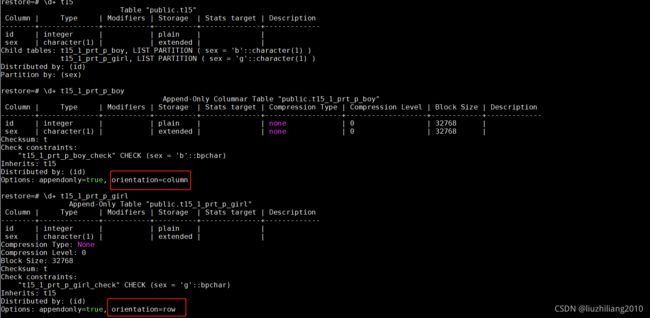
t15是一个list分区表,不同的分区存储方式不同,boy分区是列存,girl分区是行存。
- 创建一个压缩级别不同的分区表
CREATE TABLE t16 (
ID INT,
DATE DATE,
amt DECIMAL (10, 2)
) DISTRIBUTED BY (ID) PARTITION BY RANGE (DATE)(
PARTITION Jan21 START (DATE '2021-01-01') INCLUSIVE with (appendonly=true,compresstype=zlib,compresslevel=9),
PARTITION Feb21 START (DATE '2021-02-01') INCLUSIVE with (appendonly=true,compresstype=zlib,compresslevel=9),
PARTITION Mar21 START (DATE '2021-03-01') INCLUSIVE with (appendonly=true,compresstype=zlib,compresslevel=9),
PARTITION Apr21 START (DATE '2021-04-01') INCLUSIVE with (appendonly=true,compresstype=zlib,compresslevel=9),
PARTITION May21 START (DATE '2021-05-01') INCLUSIVE with (appendonly=true,compresstype=zlib,compresslevel=5),
PARTITION Jun21 START (DATE '2021-06-01') INCLUSIVE with (appendonly=true,compresstype=zlib,compresslevel=5),
PARTITION Jul21 START (DATE '2021-07-01') INCLUSIVE with (appendonly=true,compresstype=zlib,compresslevel=5),
PARTITION Aug21 START (DATE '2021-08-01') INCLUSIVE with (appendonly=true,compresstype=zlib,compresslevel=5),
PARTITION Sep21 START (DATE '2021-09-01') INCLUSIVE with (appendonly=true,compresstype=zlib,compresslevel=1),
PARTITION Oct21 START (DATE '2021-10-01') INCLUSIVE with (appendonly=true,compresstype=zlib,compresslevel=1),
PARTITION Nov21 START (DATE '2021-11-01') INCLUSIVE with (appendonly=true,compresstype=zlib,compresslevel=1),
PARTITION Dec21 START (DATE '2021-12-01') INCLUSIVE END (DATE '2022-01-01') EXCLUSIVE with (appendonly=true,compresstype=zlib,compresslevel=1)
);
restore=# \d+ t16
Table "public.t16"
Column | Type | Modifiers | Storage | Stats target | Description
--------+---------------+-----------+---------+--------------+-------------
id | integer | | plain | |
date | date | | plain | |
amt | numeric(10,2) | | main | |
Child tables: t16_1_prt_apr21, RANGE PARTITION ( date >= '2021-04-01'::date AND date < '2021-05-01'::date )
t16_1_prt_aug21, RANGE PARTITION ( date >= '2021-08-01'::date AND date < '2021-09-01'::date )
t16_1_prt_dec21, RANGE PARTITION ( date >= '2021-12-01'::date AND date < '2022-01-01'::date )
t16_1_prt_feb21, RANGE PARTITION ( date >= '2021-02-01'::date AND date < '2021-03-01'::date )
t16_1_prt_jan21, RANGE PARTITION ( date >= '2021-01-01'::date AND date < '2021-02-01'::date )
t16_1_prt_jul21, RANGE PARTITION ( date >= '2021-07-01'::date AND date < '2021-08-01'::date )
t16_1_prt_jun21, RANGE PARTITION ( date >= '2021-06-01'::date AND date < '2021-07-01'::date )
t16_1_prt_mar21, RANGE PARTITION ( date >= '2021-03-01'::date AND date < '2021-04-01'::date )
t16_1_prt_may21, RANGE PARTITION ( date >= '2021-05-01'::date AND date < '2021-06-01'::date )
t16_1_prt_nov21, RANGE PARTITION ( date >= '2021-11-01'::date AND date < '2021-12-01'::date )
t16_1_prt_oct21, RANGE PARTITION ( date >= '2021-10-01'::date AND date < '2021-11-01'::date )
t16_1_prt_sep21, RANGE PARTITION ( date >= '2021-09-01'::date AND date < '2021-10-01'::date )
Distributed by: (id)
Partition by: (date)
restore=# \d+ t16_1_prt_jan21
Append-Only Table "public.t16_1_prt_jan21"
Column | Type | Modifiers | Storage | Stats target | Description
--------+---------------+-----------+---------+--------------+-------------
id | integer | | plain | |
date | date | | plain | |
amt | numeric(10,2) | | main | |
Compression Type: zlib
Compression Level: 9
Block Size: 32768
Checksum: t
Check constraints:
"t16_1_prt_jan21_check" CHECK (date >= '2021-01-01'::date AND date < '2021-02-01'::date)
Inherits: t16
Distributed by: (id)
Options: appendonly=true, compresstype=zlib, compresslevel=9
restore=# \d+ t16_1_prt_jun21
Append-Only Table "public.t16_1_prt_jun21"
Column | Type | Modifiers | Storage | Stats target | Description
--------+---------------+-----------+---------+--------------+-------------
id | integer | | plain | |
date | date | | plain | |
amt | numeric(10,2) | | main | |
Compression Type: zlib
Compression Level: 5
Block Size: 32768
Checksum: t
Check constraints:
"t16_1_prt_jun21_check" CHECK (date >= '2021-06-01'::date AND date < '2021-07-01'::date)
Inherits: t16
Distributed by: (id)
Options: appendonly=true, compresstype=zlib, compresslevel=5
restore=# \d+ t16_1_prt_oct21
Append-Only Table "public.t16_1_prt_oct21"
Column | Type | Modifiers | Storage | Stats target | Description
--------+---------------+-----------+---------+--------------+-------------
id | integer | | plain | |
date | date | | plain | |
amt | numeric(10,2) | | main | |
Compression Type: zlib
Compression Level: 1
Block Size: 32768
Checksum: t
Check constraints:
"t16_1_prt_oct21_check" CHECK (date >= '2021-10-01'::date AND date < '2021-11-01'::date)
Inherits: t16
Distributed by: (id)
Options: appendonly=true, compresstype=zlib, compresslevel=1
t16是一个时间分区的分区表,不同的月份压缩级别不同,1-4月份压缩级别最高,5-8月份压缩级别适中,9-12月份压缩级别最低。
当然使用压缩就会影响查询速度,要综合考虑是空间换时间,还是时间换空间。对于时间较近的月份数据热度较高使用频繁,压缩级别的降低,降低了查询时CPU的负载,而时间较远的月份数据热度较低使用不频繁,压缩级别的升高能虽然大大节省了存储空间,但是同时也增加了查询时间。所以在使用压缩的时候要综合考虑利弊。
使用分区表时要注意
- 只分区大型表,不要分区小型表。
- 仅当可以基于查询条件实现分区消除(分区裁剪)并且可以基于查询谓词对表分区来完成分区消除时 才在大型表上使用分区。无论何时,优先使用范围分区而不是列表分区。
- 只有当查询中where选择条件包含表的分区列使用不可变操作符(例如=、<、 <= 、>、>=以及<>) 时,查询规划器才能有选择地扫描分区表。
- 不要使用默认分区。默认分区总是会被扫描,但是更重要的是,在很多情况下它们会被填得太满导致糟糕的性能。
- 绝不在相同的列上对表分区和分布。
- 不要使用多级分区。虽然支持子分区,但并不推荐使用这种特性,因为通常子分区包含很少的数据或者不包含数据。 分区或者子分区数量增加时性能也增加简直就是天方夜谭。维护很多分区和子分区的管理工作将会压过得到的性能收益。 为了性能、可扩展性以及可管理性,请在分区扫描性能和总体分区数量之间做出平衡。
- 谨防对列式存储使用太多分区。
- 考虑负载并发性以及为所有并发查询打开并且扫描的平均分区数。
【本文正在参与炫“库”行动-人大金仓有奖征文】人大金仓有奖征文