推荐系统工程篇之搭建以图搜图服务
基于内容的召回在推荐系统中是比较常见的召回策略,常见有基于用户或物品的标签召回或者基于用户的年龄,地域等召回,一般该策略的实现是基于开源软件 Elasticseach 实现的。虽然召回的结果都比较合理,但是召回的新颖度,惊喜度等都比较低。比如通过标签“刘德华”进行召回,基本上召回的都是包含刘德华字眼的物品,不太可能召回出“黎明”,“张学友”等其他四大天王的物品。近年随着万物皆可 Embedding,特别是 word2vec,item2vec, graph2vec 等技术的成功应用,通过物品向量召回物品向量的方法也成为推荐系统中比较常用的召回策略。本文着重讲述通过开源软件 Vearch 来搭建一个向量搜索服务,并成功实现以图搜图的功能。
介绍
最近一直在做小视频的推荐优化,优化的目标是人均入屏。按照之前资讯流的推荐经验,希望根据用户的播放记录召回更多相关的小视频来给用户消费。小视频的推荐场景和现在比较火爆的抖音有点类似,就是自动播放一小段视频(5-30s左右),该小视频基本占据了一整屏,用户可以对这个小视频进行点赞,分享,评论;如果不喜欢可以通过上滑来观看下一个小视频。考虑到决定用户是否想看的因素不太可能是视频下方两行的视频标题,更多的因素还在于视频的封面图能否引起用户的兴趣。基于这样的项目背景,所以才想搭建一个以图搜图的服务来进行小视频的封面图召回。
因为之前使用过 gRPC 封装过 Faiss 来搭建向量召回服务,再加上之前做过图片的分类项目,都是将图片转换为向量作为分类器的输入,所以要做这个事基本要解决两件事:
- 对图片进行预处理,并将其转换为固定长度的向量
- 将各个图片的向量录入 Faiss,并使用其完成向量搜索的任务
比如在博文Faiss 在项目中的使用中,作者就是使用 SIFT 算法进行图片特征的提取,这些特征对应一个 128 维的向量。将每张图片的特征向量输入给 Faiss 进行相似向量的召回。比如在博文基于gRPC的Faiss server实践中,MXPlayer的技术团队对原先基于 Flask 框架开发的用户/物品向量召回服务进行了 gRPC 的升级,单机压测 QPS 比之前高了2倍以上。本来打算是魔改之前 基于 gRPC 的 Faiss 服务来满足当期的业务场景需求的,但是偶然间发现京东开源的软件 Vearch,就将之前的念头掐灭了,并决定好好的学习这个开源软件。
服务组成
以图搜图的服务由两部分组成,一个是向量搜索服务,由 Vearch 提供;一个是将图片的特征提取成特征向量,由 Vearch 的插件 python-algorithm-plugin 提供。
向量搜索服务-Vearch
Vearch 是对大规模深度学习向量进行高性能相似搜索的弹性分布式系统。它的核心是向量搜索,是基于 Faiss 实现的叫 Gamma 引擎。不过除了向量搜索外, Gamma 还可以存储包含标量的文档,并对这些标量字段进行快速索引和过滤。说白了,标量和矢量都支持,而一般的像 Elasticsearch只支持标量。Faiss 只能构建单机的向量搜索服务,而Vearch 以 Gamma 为向量搜索引擎,使用 Raft 协议实现多副本存储,提供 Master 和 Router组件来构建向量相似搜索的弹性分布式系统。其架构图如下:
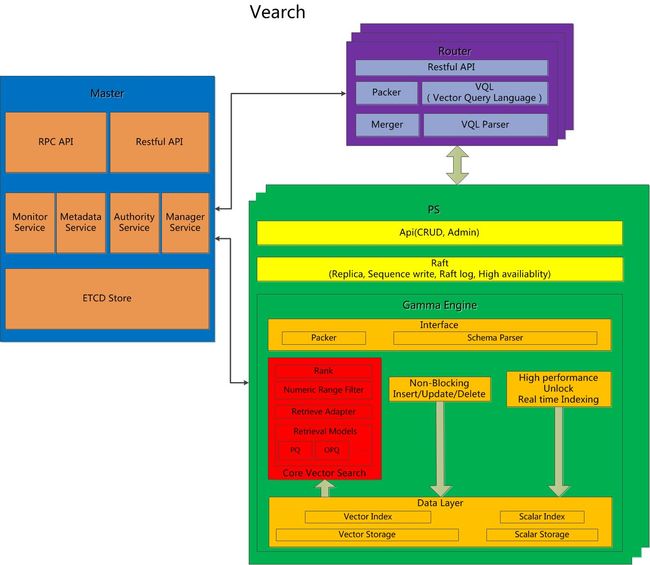
图中主要有三大组件: Master, Router,PartitionServer,其功能如下:
- Master 负责 schema 管理,进行集群级别的源数据和资源协调
- Router 提供增删改查的 RESTful API,对请求进行路由转发和结果合并
- PartitionServer 主要是基于raft协议实现多副本存储,而具体的存储,索引和检索能力是由 Gamma 引擎提供。
从上面可以知道 Gamma 之于 Vearch,就相当于 Lucene 之于 Elasticsearch。
图片处理服务-Vearch插件
图像处理的服务 Vearch 也提供了对应的插件python-algorithm-plugin。Vearch 的目标是构建一个高性能相似搜索的弹性分布式系统。文本,图片和视频都可以转换成向量,所以 Vearch 团队提供了对应的插件来更好的集成到 Vearch 中。对于图片,该插件提供了目标检测,特征提取和相似搜索等功能。其处理逻辑如下:
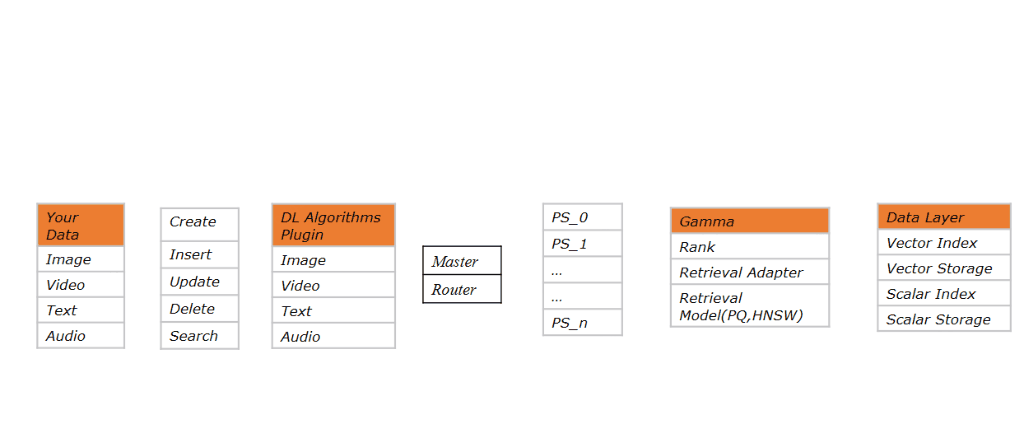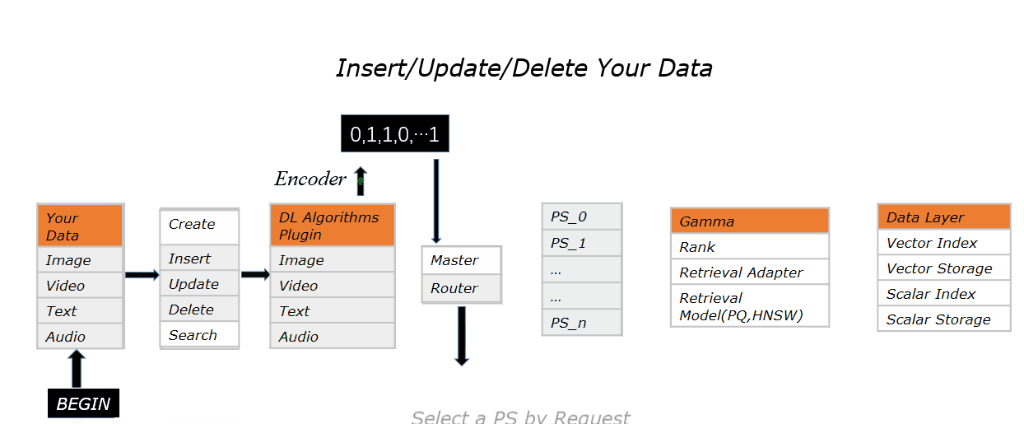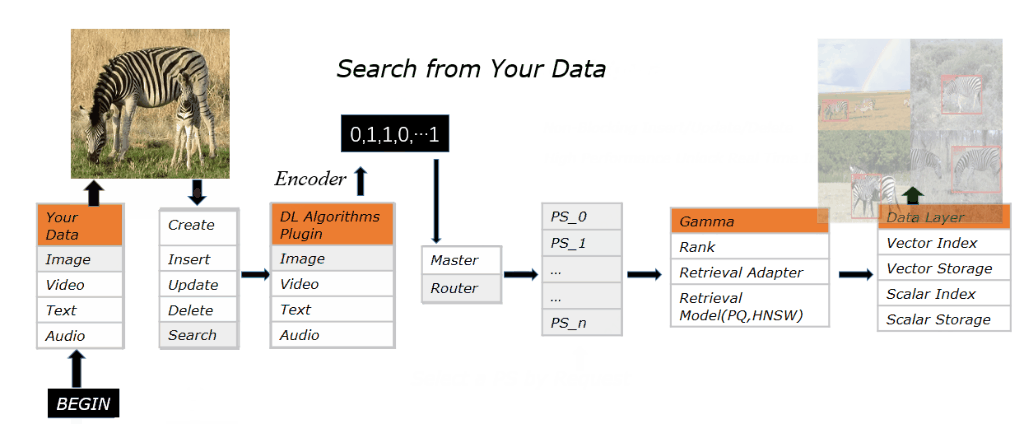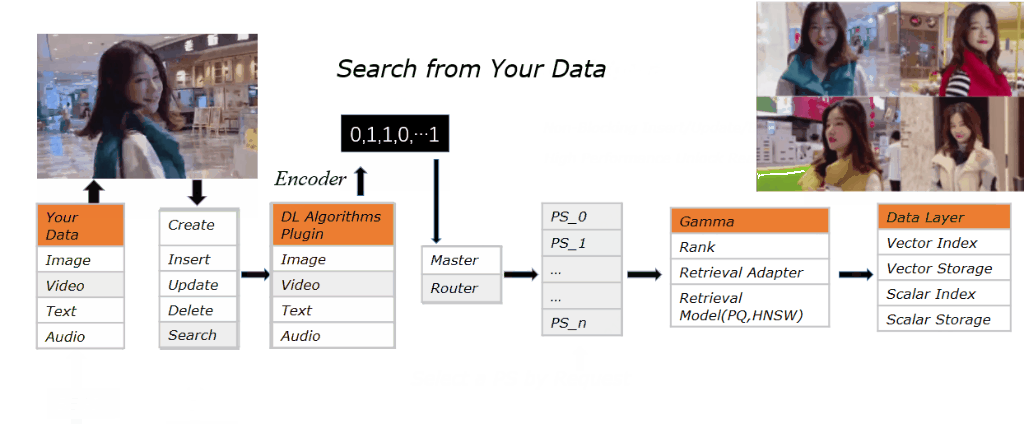
其逻辑就是从图片中抽取向量特征存储进 Vearch 的 Gamma 引擎中,并提供检索服务。
服务搭建
以图搜图的服务由两个服务构成,一个是向量搜索服务,由 Vearch 提供;另一个是图片特征提取为向量,由 Vearch 的插件python-algorithm-plugin提供。
vearch
Vearch 是用 Go 编写的,而其核心引擎 Gamma 是用 C++ 编写的(毕竟Faiss 也是 C++ 开发的),所以服务安装部署比较简单粗暴,只要设置好依赖的 lib 包(Faiss,Gamma,RocksDB),并有编译好的二进制文件 vearch,对于单机模式直接使用 ./vearch -conf config.toml 进行服务的启动,而对于集群服务,通过最后的命令参数 ./vearch -conf config.toml ps/router/master 进行配置。
不过因为我们线上服务器 Gcc 的版本太低,没有 Go 环境等因素,所以采用的是 Docker 方式。鉴于要详细了解 Faiss 服务是如何演变为 Vearch 这个弹性分布式系统的,所以采用的源码编译安装。
# 下载源码
git clone https://github.com/vearch/vearch
# 切换到镜像编译目录
cd vearch/cloud
# 打包环境镜像 vearch/vearch_env:3.2.2,将gcc,git,faiss,rocksdb,go等安装好
# 这步打包比较慢,可以直接使用官方镜像 docker pull vearch/vearch_env:3.2.2
sh compile_env.sh
# 使用 vearch_env 编译二进制文件 vearch,主要是拉取 gamma 源码进行编译
sh compile.sh
# 打包 vearch/vearch:3.2.2, 将打包好的二进制文件vearch和依赖的库放到镜像中。
# 可以直接使用官方镜像 docker pull vearch/vearch:3.2.2
sh build.sh
官方的镜像打包还是有优化的空间的,打包建议使用centos源,准备好 Faiss, RocksDB, Go等源文件。
图像处理
图像处理的服务没有现成的 Docker 镜像,而且 Github 仓库上提供的镜像打包有问题,可以使用以下的仓库进行打包。
# 下载源码(使用修正后的 Dockfile 文件)
git clone -b study https://github.com/haojunyu/python-algorithm-plugin
# 切换到镜像目录并打包镜像 vearch/images:3.2.2
# 可以直接使用打包好的镜像 docker pull haojunyu/vimgs:3.2.2
cd python-algorithm-plugin && docker build -t haojunyu/vimgs:3.2.2 .
swarm启动
因为两个服务都已经打包成 Docker 镜像了,这里直接使用命令 docker stack deploy -c docker-compose.yml vearch 来启动服务, docker-compose.yml 内容如下:
version: '3.3'
services:
vearch:
image: vearch/vearch:3.2.2
ports:
- "8817:8817"
- "9001:9001"
volumes:
- ./config.toml:/vearch/config.toml
- ./data:/datas
- ./logs:/logs
deploy:
mode: replicated
replicas: 1
restart_policy:
condition: on-failure
delay: 10s
max_attempts: 3
logging:
driver: "json-file"
options:
max-size: "1g"
imgs:
image: haojunyu/vimgs:3.2.2
ports:
- "4101:4101"
volumes:
- ./python-algorithm-plugin/src/config.py:/app/src/config.py
- ./images/imgs:/app/src/imgs
command: ["bash", "../bin/run.sh", "image"]
deploy:
mode: replicated
replicas: 3
restart_policy:
condition: on-failure
delay: 10s
max_attempts: 3
注意: 挂载文件 python-algorithm-plugin/src/config.py 是图片处理服务的配置文件,一般只需要针对自己的情况改动以下四个配置:
port指图片处理服务的端口,默认 4101gpus指定服务是否使用 gpu,默认不用为 -1master_address和router_address指 Vearch 服务的 master 和 router服务
服务用法
因为图片服务和 Vearch 服务是高度集成的。一般是直接调用图片服务,而图片向量录入 Vearch交给图片服务自己处理。Vearch 详细的操作可以参考文档。
服务监控
# 这里master_server指vearch主节点及其对应端口:localhost:8817
# 查看集群状态
curl -XGET http://master_server/_cluster/stats
# 查看健康状态
curl -XGET http://master_server/_cluster/health
# 查看端口状态
curl -XGET http://master_server/list/server
# 清除锁(在创建表时会对集群加锁,若在此过程中,服务异常,会导致锁不能释放,需要手动清除才能新建表。)
curl -XGET http://master_server/clean_lock
# 副本扩容缩容
curl -XPOST -H "content-type: application/json" -d'
{
"partition_id":1,
"node_id": 1,
"method": 0
}
' http://master_server/partition/change_member
库和空间操作
库和空间的概念类似mysql里面的数据库和表的概念。
- 库操作
# 查看及群众所有的库
curl -XGET http://master_server/list/db
# 创建库
curl -XPUT -H "content-type:application/json" -d '{
"name": "sv_month"
}
' http://master_server/db/_create
# 查看库
curl -XGET http://master_server/db/$db_name
# 删除库(库下存在表空间则无法删除)
curl -XDELETE http://master_server/db/$db_name
# 查看指定库下所有表空间
curl -XGET http://master_server/list/space?db=$db_name
- 表空间操作
# 在库sv_month下创建表空间test(针对image)
curl -XPUT -H "content-type: application/json" -d '{
"name":"test",
"partition_num":1,
"replica_num":1,
"engine":{
"name":"gamma",
"index_size":70000,
"max_size":10000000,
"id_type":"String",
"retrieval_type":"IVFPQ",
"retrieval_param":{
"metric_type":"InnerProduct",
"ncentroids":256,
"nsubvector":32
}
},
"properties":{
"itemid":{
"type":"keyword",
"index":true
},
"feature1":{
"type":"vector",
"dimension":512,
"model_id":"vgg16",
"format":"normalization"
}
}
}' http://image_server:4101/space/sv_month/_create
数据操作
- 数据插入
# 插入本地图片数据到表空间中
curl -XPOST -H "content-type: application/json" -d' {
"itemid":"COCO_val2014_000000123599",
"feature1":{
"feature":"../images/COCO_val2014_000000123599.jpg"
}
} ' http://image_server:4101/sv_month/test/AW63W9I4JG6WicwQX_RC
- 数据搜索
# 查询相似结果
curl -H "content-type: application/json" -XPOST -d '{
"query": {
"sum": [ {
"feature":"../images/COCO_val2014_000000123599.jpg", "field":"feature1"
}]
}
}' http://image_server:4101/sv_month/test/_search
服务效果及上线
效果
在服务构建成功后,就需要查看一下以图搜图的效果,而对于效果的鉴别初步以人工为准,最终以线上的指标数据为准。对于一个服务效果的好坏在搭建服务之初就应该有个预期,比如:
- 相同的图片相似度得接近 100%
- 相同类型的应该得到相同类型的结果,比如用小狗搜索出小狗,用汽车搜索出汽车等
以下就是以图搜图的效果截图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-epZBh6C1-1610984951433)(https://blog.haojunyu.com/imgs/search_animal.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4w6qvIsO-1610984951435)(https://blog.haojunyu.com/imgs/search_beauty.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G6aUzm1a-1610984951436)(https://blog.haojunyu.com/imgs/search_beauty2.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N4Dslgsr-1610984951437)(https://blog.haojunyu.com/imgs/search_car.png)]
总体来说效果还是挺不错的。
上线
推荐策略的上线方式有以下几种:
- 直接服务线上,像排序模型。这种方式要求服务支持高并发,高性能和高可用
- 线上调用+缓存,像内容搜索。这种方式要求服务支持高性能和高可用,并且缓存有较大概率被命中
- 结果离线写入缓存,像 cf,热门等可以提前算好的结果。
导入了小视频最近 7 天新增和最近 30 天曝光的视频共 9 万数据导入到单机模式的 Vearch 服务中,无法支撑两个桶平均 48 QPS的冲击,后使用第二种方式解决上线问题。而对应用户向量(播放的图片向量均值)搜索图片向量策略通过第三种方式上线的。
参考文献
- Faiss 在项目中的使用
- faiss-web-service
- 基于gRPC的Faiss server实践
- 京东分布式向量检索系统vearch
- vearch中文文档
- vearch核心引擎gamma
- vearch图像处理插件
- 图片搜索页面
如果该文章对您产生了帮助,或者您对技术文章感兴趣,可以关注微信公众号: 技术茶话会, 能够第一时间收到相关的技术文章,谢谢!

本篇文章由一文多发平台ArtiPub自动发布