用 puppeteer 实现网站自动分页截取的趣事
最近因为工作中的一个需求,需要针对用户数据页面进行分页并截屏并返回 PDF 文件,期间用到了 puppeteer 与 HTML 分页算法,还找到了一个不错的插件,于是来聊些其中遇到的趣事,先附上目录。
-
一、利用 puppeteer 截取页面
-
1.1 puppeteer 还是 puppeteer-core
-
1.2 简单的 cookie 透传
-
1.3 页面加载状态判断
-
1.4 截图格式选择 pdf 还是 png
-
二、DFS 加二分,一个简单的 HTML 分页算法
-
三、CSS 打印样式
-
四、插件与其他
-
4.1 puppeteer-recorder
-
4.2 参考
开始吧。
一、利用 puppeteer 截取页面
puppeteer,即 Headless Chrome Node.js API 实现,被广泛用于自动化测试和爬虫方向的工作,一个最基本用法如下:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
// 下文中会多次用到 page 对象,可以先留意下
const page = await browser.newPage();
await page.goto('https://www.google.com');
// other actions...
await browser.close();
})();
如上示例打开了 Chromium 浏览器,并打开了一个新页面跳转至 Google 首页,然后将浏览器关闭,关于更多详细的用法可以直接翻阅 API 文档查看。我们来看其他几个点。
1.1 puppeteer 还是 puppeteer-core
从 1.7.0 版本往后,puppeteer 会同时发布两个版本:
- puppeteer
- puppeteer-core
说到两者的区别,主要在于:
puppeteer-core在安装时不会下载 Chromiumpuppeteer-core会忽略所有PUPPETEER_*环境变量
所以,在使用 puppeteer-core 时,需要确保环境中已拥有可执行的 Chromium 文件,比如在调用 puppeteer.launch 方法时,如果你将对应的 Chrome 压缩包解压到了你的 dist 文件夹中,那么便可以通过下面的方式显式指明你的浏览器可执行路径 executablePath
const path = require('path');
import { launch } from 'puppeteer-core';
const getExecutableFilePath = () => {
const extraPath = {
Linux_x64: 'chrome',
Mac: 'Chromium.app/Contents/MacOS/Chromium',
Win: 'chrome.exe',
}[getOSType()]; // 假设通过这个函数可以获得系统类型
return path.join(path.resolve('dist/chrome'), extraPath);
}
const browser = await launch({
executablePath: getExecutableFilePath(),
args: [ '--no-sandbox', ],
headless: true,
});
但更多时候,在国内使用 puppeteer-core 还有一个特殊考虑,那就是 puppeteer 需要下载 Chrome,正常情况下速度很慢。关于两者详细的区别可以看 https://github.com/puppeteer/puppeteer/blob/main/docs/api.md#puppeteer-vs-puppeteer-core
1.2 简单的 cookie 透传
假设你的 puppeteer 服务提供给他人调用,而请求方想截取的是一张需要登陆状态的页面,该怎么办呢?简单来看,透传 cookie 貌似就能解决这个问题。
puppeteer 在 Page 类上提供有 setCookie 方法,这允许你从请求方发来的 request headers 上获取 cookies,并将内容按键值对解析后批量注入打开的浏览器环境。简单的示例可以长成这样:
import { SetCookie } from 'puppeteer-core';
const cookieList: SetCookie[] = [{ ... }];
await page.setCookie(...cookieList);
调用 setCookie 时你可以传入一个对象,也可以传入展开的对象数组,每个传入对象中 name 和 value 属性是必须的,当然也可以指定 domain 字段细化 cookie 的应用范围。由于涉及到对 url 的处理,推荐一个三方库 url-parse,可以节省不少时间,用法如下:
/**
* URL Schema
*
* - `protocol`: The protocol scheme of the URL (e.g. `http:`).
* - `slashes`: A boolean which indicates whether the `protocol` is followed by two forward slashes (`//`).
* - `auth`: Authentication information portion (e.g. `username:password`).
* - `username`: Username of basic authentication.
* - `password`: Password of basic authentication.
* - `host`: Host name with port number.
* - `hostname`: Host name without port number.
* - `port`: Optional port number.
* - `pathname`: URL path.
* - `query`: Parsed object containing query string, unless parsing is set to false.
* - `hash`: The "fragment" portion of the URL including the pound-sign (`#`).
* - `href`: The full URL.
* - `origin`: The origin of the URL.
*/
const Url = require('url-parse');
let host: string = Url(url).hostname;
如此一来你就可以在打开对应页面时,带上和请求方一致的 cookie 信息了。
1.3 页面加载状态判断
我们首先要先把页面加载出来,然后才能做截图处理。但是加载页面,如何判断页面加载完毕呢?puppeteer 在打开页面时有提供 waitUntil 选项以及 timeout 时长,这里取值可以是下列四个选项之一:
const maxTimeout: number;
const url: string;
const gotoAction = () => {
return page.goto(url, {
waitUntil: waitUntil as 'networkidle0' | 'networkidle2' | 'domcontentloaded' | 'load',
timeout: maxTimeout,
});
};
通过一个 Promise 简单包装下打开页面时可能出现的报错,我们的代码可以写成下面这样:
let pageErrorPromise = new Promise((_res, rej) => {
promiseReject = rej;
});
page.on('pageerror', (pageerr) => {
promiseReject(pageerr);
});
await Promise.race([
gotoAction(),
pageErrorPromise,
]);
当然,即便到这一步,你依旧可能没法确认页面已经加载完毕,假设页面就是存在一段特殊逻辑需要在5s后进行一个公式渲染。
好在 puppeteer 提供有监听页面变量/方法变动的 API,于是我们可以这么做:
await page.waitForFunction('window.allDone', {
timeout: maxTimeout,
});
如此一来,只需要目标页面在完成所有内容渲染后触发 window.allDone “通知“我们即可。
1.4 截图格式选择 pdf 还是 png
puppeteer 的 page 类提供有 page.screenshot([options]) 和 page.pdf([options]) 两个 API,分别可以将当前页面截取为图片和 PDF 格式的数据,这个可以具体查看文档使用即可。
但在实际使用时,我有遇到一些问题,比如截取 PDF 时指定的宽高不完全准确、页面在内容布局超长时指定的宽度会失效等等,这里面一部分可以通过设置 viewport 解决,另一部分搜了下像是这个 issue 提到的问题,即puppeteer 在截图时会针对相似的内置规格进行“四舍五入”。
注:还有一个需要注意的是,pdf API 到现在还只支持在 headless 模式下操作。
二、DFS 加二分,一个简单的 HTML 分页算法
对于分页操作,我们往往不能直接截图生成 PDF 就完事,一方面是尺寸可能和我们需要的效果存在差异,另一方面则是默认打印的效果无法保证页面中 DOM 不被分页分割成两半。
因此,我们需要设计一个简单的分页算法,对 DOM 进行重排,以适合我们的打印布局。这里简单介绍下我们在研发中采用的方法。
分页算法我们分成以下几个部分。
**第一步,等待所有 DOM 节点加载完成。**由于页面中大多数资源除了文本便是图片资源,而图片资源还可能会通过动态逻辑生成,为了准确计算各个节点的尺寸大小与重排,我们需要等待节点加载并完成渲染后再做进一步操作,这里采用监听 load 事件(load 事件已经包含样式文件以及图片资源的加载判断,但针对 JavaScript 逻辑中动态生成的图片标签可能捕获不准)加额外一次 img 标签 complete 状态轮询的方式确定内容渲染完成。
// load 事件监听
window.onload = (event) => {
console.log('page is fully loaded');
};
// img 标签加载状态轮询(在 load 事件触发后执行)
const imgs = document.querySelectorAll('img');
imgs.map((img) => {
if (img.complete) {
// ...
} else {
// ...
}
});
**第二步,打平 DOM 树。**因为要确保分页的准确,所以我们肯定需要对整个 DOM 进行递归性遍历,挨个枚举判断其在文档流中的位置与尺寸,所以我们先将目标节点全部打平。这里相对比较简单,用个 DFS 将 DOM 元素递归打平即可,可能有时我们需要跳过一些指定元素的递归,那么额外维护一个列表即可。
// 节点列表
const elementList = [];
// 自定义跳过的节点与 className 列表
const CUSTOM_CLASS_AND_TAGS = ['header', 'footer', 'custom-pagination'];
// 获取节点
const getNode = (id: string): HTMLElement => {
return document.getElementById(id);
}
//
const dfs = (node: HTMLElement): void => {
// 注释节点则跳过
if (node.nodeType === Node.COMMENT_NODE) {
return ;
}
if (node.nodeType === Node.TEXT_NODE) {
elementList.push(node);
return ;
}
// 通过该方法可以获得节点的 className 以及 tag
const nodeClassAndTag = getNodeClassAndTag(node);
const isLeafNode = CUSTOM_CLASS_AND_TAGS.some(leafNodeSelector =>
nodeClassAndTag.includes(leafNodeSelector)
);
if (isLeafNode) {
elementList.push(node);
return ;
}
node?.childNodes?.forEach(item => dfs(item));
}
**第三步,找到跨越边界的节点。**这一步的解法也很直观,借助上一步产出的节点列表,我们可以利用二分来快速定位边界节点,但如何确定节点是否越界呢?这里需要借助 Web API 中的 Range 对象,Range 对象是表示一个包含节点与文本节点的一部分的文档片段。
利用 Document.createRange() 可以产生一个 Range,在这个对象上调用 getBoundingClientRect() 可以得到一个 DOMRect 对象,该对象将范围中的内容包围起来,你可以理解成这是一个边界矩形,通过他你便可以算出当前内容是否超过一页。
// 产生 Range
const range = document.createRange();
range.selectNodeContents(getNode('id'));
// 二分查找
const startIndex = 0;
const endIndex = elementList.length - 1;
while (startNodeIndex < endNodeIndex) {
const midNodeIndex = Math.floor((startNodeIndex + endNodeIndex) / 2);
const node = elementList[midNodeIndex];
const includeInNewPage = includeInNewPage(node);
if (includeInNewPage) {
startNodeIndex = midNodeIndex + 1;
} else {
endNodeIndex = midNodeIndex;
}
}
// 判断包含节点的 Range 是否越界
const includeInNewPage = (el: HTMLElement) => {
const innerRange = range.cloneRange();
innerRange.setEndAfter(el);
const rect = innerRange.getBoundingClientRect();
// 判断逻辑
// rect.height ...
}
**第四步,将内容切分为当前页与剩余内容。**虽然我们找到了越界的节点,但是我们并不清楚它是从哪开始越界的。
打个比方,当前节点是一段三行的文本,可能到第二行末尾都是放的下的,只有到第三行才越界,那么我们在切分时就该准确的找到这个位置,并把原来的 DOM 切成两半。再比如,如果我们所遇到的节点是非文本节点,那么这个节点便可以认为是不可再分的单元,只能被唯一分到其中一半中去,所以这块的伪代码应该长成这样:
const newPagedContentRange: Range;
const remainedContentRange: Range;
const paging = (boundaryNodeIndex: number) => {
const boundaryNode = elementList[boundaryNodeIndex];
if (boundaryNode.nodeType === Node.TEXT_NODE) {
const boundaryCharIndex = binarySearchBoundaryCharIndex(boundaryNode);
newPagedContentRange.setEnd(boundaryNode, boundaryCharIndex);
remainedContentRange.setStart(boundaryNode, boundaryCharIndex);
return;
}
newPagedContentRange.setEndBefore(boundaryNode);
remainedContentRange.setStartBefore(boundaryNode);
// 判断 newPagedContentRange 是不是真的有内容,避免无限循环
const rect = newPagedContentRange.getBoundingClientRect();
if (!rect.height) {
newPagedContentRange.setEndAfter(boundaryNode);
remainedContentRange.setStartAfter(boundaryNode);
}
}
上面有一个方法没有展开,即 binarySearchBoundaryCharIndex,它的作用是采用二分对当前文本节点进行切分,并返回越界的文本位置下标,这里在判断时依然是采用复制 Range 然后判断边界矩形的思路,只不过 Range.setEndAfter() API 要换成 Range.setEnd(),因为这里你要对一个节点中的文本依次遍历。完成判断之后,便可以拿到 newPagedContentRange 对当前页内容进行操作/复原。
另外,对 remainedContentRange 循环如上第三步和第四步,直至剩余内容不再超过一页。
三、CSS 打印样式
你也可以通过 CSS 指定打印样式,这允许我们针对页面在打印操作时进行样式的定制化操作。
/** 比如,你可以把你要定制的打印样式写入如下花括号中 */
@media print {
...
}
/** 再比如,你可以这样设置页面边距 */
@page { margin: 2cm }
@page :left {
margin: 1cm;
}
@page :right {
margin: 1cm;
}
再比如,CSS 中还有三个属性,分别是 page-break-before、 page-break-after 和 page-break-inside,可以让我们精确地控制打印页面在何处分页。除此之外,也可以避免图片被切成两段。
- page-break-before 是否在此元素前面设置一个分页符;
- page-break-after 设置元素后面的分页符;
- page-break-inside 可以在元素内部产生一个截断,比如图片;
/* 以下是可选的设置项 */
page-break-after : auto | always | avoid | left | right
page-break-before : auto | always | avoid | left | right
page-break-inside : auto | avoid
当然,除了上面这些,我们如果需要在现有样式上支持打印样式,还需要做很多其他处理,比如对超链接高亮、隐藏音视频标签等等,这里就不详细展开了。
四、插件与其他
4.1 puppeteer-recorder
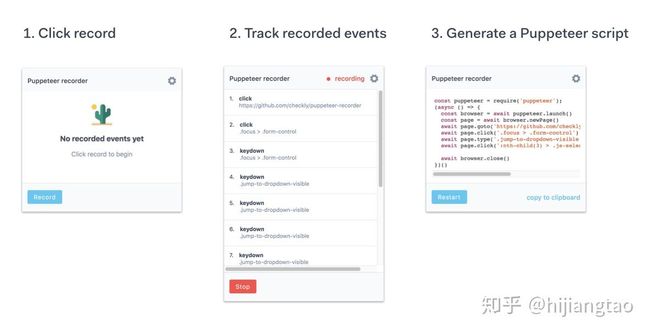
有一个不错的插件叫 puppeteer-recorder 推荐一下,它能够记录你在 Chrome 上的操作并据此生成一段 Puppeteer script 代码,比如我现在需要在打开页面后通过一系列点击操作跳转到另一个页面状态,如果按照传统方法我们应该是理清思路然后把这段流程用代码写出来,通过这个插件,三步即可达到相同效果:
- 点击 record 开始录制
- 按照预期在页面上交互
- 点击停止,复制插件上生成的如下代码
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch()
const page = await browser.newPage()
const navigationPromise = page.waitForNavigation()
await page.goto('https://hijiangtao.github.io/')
await page.setViewport({ width: 2560, height: 1280 })
await page.waitForSelector('.masthead > .masthead__inner-wrap > .masthead__menu > #site-nav > .site-title')
await page.click('.masthead > .masthead__inner-wrap > .masthead__menu > #site-nav > .site-title')
await navigationPromise
await page.waitForSelector('.archive > .pagination > ul > li:nth-child(3) > a')
await page.click('.archive > .pagination > ul > li:nth-child(3) > a')
await navigationPromise
await page.waitForSelector('.archive > .list__item:nth-child(6) > .archive__item > .archive__item-title > a')
await page.click('.archive > .list__item:nth-child(6) > .archive__item > .archive__item-title > a')
await navigationPromise
await page.waitForSelector('footer > .page__footer-follow > .social-icons > li:nth-child(3) > a')
await page.click('footer > .page__footer-follow > .social-icons > li:nth-child(3) > a')
await navigationPromise
await browser.close()
})()
祝大家在 Web 里玩的愉快。
服务推荐
- 蜻蜓代理
- ip代理
- 代理ip
- ip代理服务器
- 国内ip代理
- 代理服务ip
- 最新代理服务器
- 代理ip网
- 中国代理服务器
- 付费代理
- 企业级ip
- 企业级代理ip
- 中国代理ip
- 最新代理ip