虚拟文件系统(VFS)
为支持各种本机文件系统,且在同时允许访问其他操作系统的文件,Linux内核在用户进程(或C标准库)和文件系统实现之间引入了一个抽象层。该抽象层称之为虚拟文件系统(Virtual File System),简称VFS。VFS的任务并不简单。一方面,它用来提供一种操作文件、目录及其他对象的统一方法。另一方面,它必须能够与各种方法给出的具体文件系统的实现达成妥协。

图1 用作文件系统抽象的VFS层
1 文件系统类型
文件系统一般可以分为下面3种。
(1) 基于磁盘的文件系统(Disk-based Filesystem)是在非易失介质上存储文件的经典方法,用以在多次会话之间保持文件的内容。实际上,大多数文件系统都由此演变而来。比如,一些众所周知的文件系统,包括Ext2/3、Reiserfs、FAT和iso9660。
(2)虚拟文件系统(Virtual Filesystem)在内核中生成,是一种使用户应用程序与用户通信的方法。proc文件系统是这一类的最佳示例。它不需要在任何种类的硬件设备上分配存储空间。相反,内核建立了一个层次化的文件结构,其中的项包含了与系统特定部分相关的信息。
(3)网络文件系统(Network Filesystem)是基于磁盘的文件系统和虚拟文件系统之间的折中。这种文件系统允许访问另一台计算机上的数据,该计算机通过网络连接到本地计算机。在这种情况下,数据实际上存储在一个不同系统的硬件设备上。
2 通用文件模型
VFS不仅为文件系统提供了方法和抽象,还支持文件系统中对象(或文件)的统一视图。VFS提供一种结构模型,包含了一个强大文件系统所应具备的所有组件。但该模型只存在于虚拟中,必须使用各种对象和函数指针与每种文件系统适配。所有文件系统的实现都必须提供与VFS定义的结构配合的例程,以弥合两种视图之间的差异。当然,虚拟文件系统的结构并非是幻想出来的东西,而是基于描述经典文件系统所使用的结构。VFS抽象层的组织显然也与Ext2文件系统类似。
在处理文件时,内核空间和用户空间使用的主要对象是不同的。对用户程序来说,一个文件由一个文件描述符标识。该描述符是一个整数,在所有有关文件的操作中用作标识文件的参数。文件描述符是在打开文件时由内核分配,只在一个进程内部有效。两个不同进程可以使用同样的文件描述符,但二者并不指向同一个文件。基于同一个描述符来共享文件是不可能的。
内核处理文件的关键是inode。每个文件(和目录)都有且只有一个对应的indoe,其中包含元数据(如访问权限、上次修改的日期,等等)和指向文件数据的指针。但inode并不包含一个重要的信息项,即文件名,这看起来似乎有些古怪。通常,假定文件名称是其主要特征之一,因此应该被归入用于管理文件的对象(inode)中。
2.1 inode
2.1.1 基本概念
如何用数据结构表示目录的层次结构?如前所述,inode对文件实现来说是一个主要的概念,但它也用于实现目录。换句话说,目录只是一种特殊的文件,它必须正确地解释。inode的成员可能分为下面两类。
① 描述文件状态的元数据。例如,访问权限或上次修改的日期。
② 保存实际文件内容的数据段(或指向数据的指针)。就文本文件来说,用于保存文本。
2.1.2 举个栗子
为阐明如何用inodes来构造文件系统的目录层次结构,我们来考察内核查找对应于/usr/bin/ emacs的inode过程。
查找起始于inode,它表示根目录/,对系统来说必须总是已知的。该目录由一个inode表示,其数据段并不包含普通数据,而是根目录下的各个目录项。这些项可能代表文件或其他目录。每个项由两个成员组成。
① 该目录项的数据所在inode的编号。
② 文件或目录的名称。
系统中所有inode都有一个特定的编号,用于唯一地标识各个inode。文件名和inode之间的关联即通过该编号建立。
(1)查找操作中的第一步是查找子目录usr的inode。这一步会扫描根inode的数据段,直至找到一
个名为usr的目录项(如果查找失败,则返回File not found错误)。相关的inode可以根据inode编号定位。
(2)重复上述步骤,但这一次在usr对应inode的数据段中查找名为bin的目录项,以便根据其inode编号定位inode。下一步在bin的inode数据段中,将查找名为emacs的目录项。这仍然会返回一个inode编号,这一次的inode表示文件而非目录。图8-2给出了查找过程结束时的情形(所经由的路径由对象之间的指针表示)。
(3)最后一个inode的文件内容,与前三个inode不同。前三个inode都表示目录,其文件内容是目录项的一个列表,包括子目录和文件。与emacs文件关联的inode,其数据段存储了文件的内容。
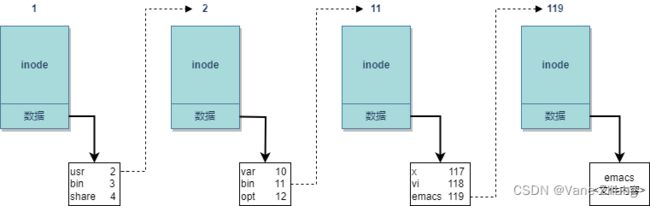
图2 查找/usr/bin/emacs的操作
2.2 链接
链接(link)用于建立文件系统对象之间的联系。linux中有两种类型的链接,分别是符号链接(软链接)与硬链接。
符号链接可以认为是“方向指针”(至少从用户程序来看是这样),表示某个文件存在于特定的位置。当然我们都知道,实际的文件在其他地方。符号链接可以认为是一个目录项,其中除了指向文件名的指针,并不存在其他数据。目标文件删除时,符号链接仍然继续保持。对每个符号链接都使用了一个独立的inode。相应inode的数据段包含一个字符串,给出了链接目标的路径。
对于符号链接,可以区分原始文件和链接。对于硬链接,情况不是这样。在硬链接已经建立后,无法区分哪个文件是原来的,哪个是后来建立的。在硬链接建立时,创建的目录项使用了一个现存的inode编号。删除符号链接并不困难,但硬链接的处理有一点技巧。
我们假定硬链接(B)与原始文件(A)共享同一个inode。一个用户现在想要删除A。这通常会销毁相关的inode连同其数据段,以便释放存储空间供后续使用。那么接下来B就不能继续访问了,因为相关的inode和文件信息不再存在了。当然,这不是我们想要的行为。在inode中加入一个计数器,即可防止这种情况。每次对文件创建一个硬链接时,都将计数器加1。如果其中一个硬链接或原始文件被删除(不可能区分这两种情况),那么将计数器减1。只有在计数器归0时,我们才能确认该inode不再使用,可以从系统删除。
2.3 编程接口
用户进程和内核的VFS实现之间的接口照例由系统调用组成,其中大多数涉及对文件、目录和一般意义上的文件系统的操作。对上述的操作,内核提供了50多个系统调用。我们只考察最重要的调用,以阐明关键原则。
文件使用之前,必须用open或openat系统调用打开。在成功打开文件之后,内核向用户层返回一个非负的整数。这种分配的文件描述符起始于3。我们知道,尽管没有明确规定,这个标识符号之所以不从0开始,是因为所有的进程都分配了前3个标识符(0~2)。0表示标准输入,1表示标准输出,2表示标准错误输出。
在文件已经打开后,其名称就没什么用处了。它现在由其文件描述符唯一标识,所有其他库函数都需要传递文件描述符作为一个参数(进一步传递到系统调用)。尽管传统上文件描述符在内核中足以标识一个文件,但现在情况不再如此。由于多个命名空间和容器的引入,具有相同数值的多个文件描述符可以共存于内核中。对文件的唯一表示由一个特殊的数据结构(struct file)提供,我将在下文讨论。我们在示例程序调用close的部分会看到文件描述符,该调用关闭与文件的“连接”(释放文件描述符,以便在后续打开其他文件时使用)。 read也需要将文件描述符作为第一个参数,以标识读取数据的来源。
在一个打开文件中的当前位置保存在文件位置指针(file pointer)中,这是一个整数,指定了当前位置与文件起始点的偏移量。对随机存取文件而言,该指针可以设置为任何值,只要不超出文件存储容量范围即可。这用于支持对文件数据的随机访问。其他文件类型,如命名管道或字符设备的设备文件,不支持这种做法。它们只能从头至尾顺序读取。在文件打开时,可以指定各种标志(如O_RDONLY),用来规定文件的存取模式。
2.4 将文件作为通用接口
UNIX是基于少量审慎选择的范型而建立的。一个非常重要的隐喻贯穿内核的始终(特别是VFS),尤其是在有关输入和输出机制的实现方面。
万物皆文件
好,我们承认:当然该规则有少数例外(例如,网络设备),但大多数内核导出、用户程序使用的函数都可以通过VFS定义的文件接口访问。以下是使用文件作为其主要通信手段的一部分内核子系统:
- 字符和块设备;
- 进程之间的管道;
- 用于所有网络协议的套接字;
- 用于交互式输入和输出的终端。
要注意,上述的某些对象不一定联系到文件系统中的某个项。例如,管道是通过特殊的系统调用生成,然后由内核在VFS的数据结构中管理,管道并不对应于一个可以用通常的rm、ls等命令访问的真正的文件系统项。我们特别感兴趣的是访问块设备和字符设备的设备文件。这些是真正的文件,通常位于/dev目录。其内容是在进行读写操作时由相关的设备驱动程序动态生成的。
3 VFS的结构
既然我们已经熟悉了VFS的基本结构和用户接口,下面我们将重点讨论其实现细节。在VFS接口的实现中,涉及大量数据结构,有些非常冗长。因此最好草拟出各个组成部分的一个大体概观,并说明其联结方式。
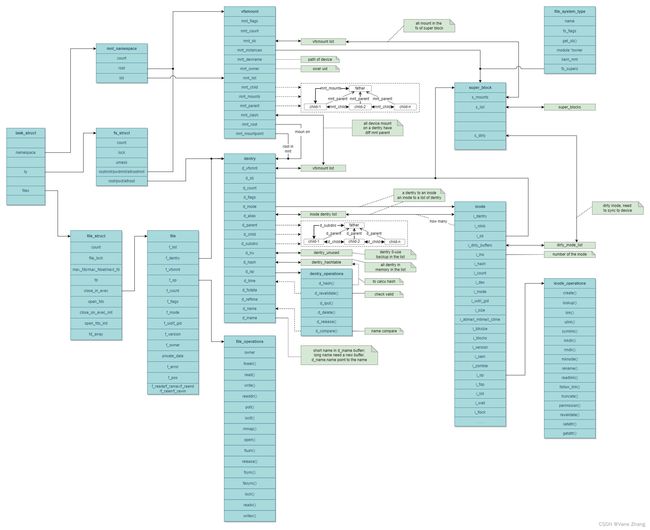
图3 各个VFS组件的相互关系
3.1 结构概观
VFS由两个部分组成:文件和文件系统,这些都需要管理和抽象。
3.1.1 文件的表示
如上所述,inode是内核选择用于表示文件内容和相关元数据的方法。理论上,实现这个概念只需要一个数据结构(尽管很长),其中包含了所有必要的数据。实际上,数据分散到一系列较小的、布局清晰的结构中。如图3所示。
(1) 在VFS对底层文件系统的访问时,并未使用固定的函数,而是使用了函数指针。这些函数指针保存在两个结构中,包括了所有相关的函数。
① inode操作:创建链接、文件重命名、在目录中生成新文件、删除文件。
② 文件操作:作用于文件的数据内容。它们包含一些显然的操作(如读和写),还包括如设置文件位置指针和创建内存映射之类的操作。
(2)除此之外,还需要其他结构来保存与inode相关的信息。特别重要的是与每个inode关联的数据段,其中存储了文件的内容或目录项表。每个inode还包含了一个指向底层文件系统的超级块对象的指针,用于执行对inode本身的操作(这些操作也是通过函数指针数组实现,稍后我们会看到)。还可以提供有关文件系统特性和限制的信息。
(3)因为打开的文件总是分配到系统中一个特定的进程,内核必须在数据结构中存储文件和进程之间的关联。task_struct包含一个成员,其中保存了所有打开的文件(通过一种迂回方式)。该成员是一个数组,访问时使用文件描述符作为索引。各个数组项包含的对象不仅关联到对应文件的inode,还包含一个指针,指向用于加速查找操作的目录项缓存的一个成员。各个文件系统的实现也能在VFS inode中存储自身的数据(不通过VFS层操作)。
3.1.2 文件系统和超级块信息
VFS支持的文件系统类型通过file_system_type连接进来起来。每种文件系统,不管有多少实例安装到系统中,还是根本就没有安装到系统中,都只有一个file_system_type。 该对象提供了一种读取超级块的方法,在文件系统安装时,会调用该方法从磁盘中读取超级块信息并载入到内存中。同时,将有一个vfsmount结构体在安装点被创建,该结构体用来代表代表一个安装点。
内核还建立了一个链表,包含所有活动文件系统的超级块实例。之所以使用活动(active)这个术语替代已装载(mounted),是因为在某些环境中,有可能使用一个超级块对应几个装载点。尽管每个文件系统在file_system_type中只出现一次,但所有超级块实例的链表中,可能有几个同一文件系统类型的超级块实例。
另外,超级块结构有一个成员是列表,该列表包括相关文件系统中所有修改过的inode(标记为脏)。内核会周期性扫描脏块的列表,并将修改传输到底层硬件。
3.2 inode
VFS的inode结构如下:
struct inode {
struct hlist_node i_hash;
struct list_head i_list;
struct list_head i_sb_list;
struct list_head i_dentry;
unsigned long i_ino;
atomic_t i_count;
unsigned int i_nlink;
uid_t i_uid;
gid_t i_gid;
dev_t i_rdev;
unsigned long i_version;
loff_t i_size;
struct timespec i_atime;
struct timespec i_mtime;
struct timespec i_ctime;
unsigned int i_blkbits;
blkcnt_t i_blocks;
umode_t i_mode;
struct inode_operations *i_op;
const struct file_operations *i_fop; /* 此前为->i_op->default_file_ops */
struct super_block *i_sb;
struct address_space *i_mapping;
struct address_space i_data;
struct dquot *i_dquot[MAXQUOTAS];
struct list_head i_devices;
union {
struct pipe_inode_info *i_pipe;
struct block_device *i_bdev;
struct cdev *i_cdev;
};
int i_cindex;
__u32 i_generation;
unsigned long i_state;
unsigned long dirtied_when; /* 第一个脏操作发生的时间,以jiffies计算 */
unsigned int i_flags;
atomic_t i_writecount;
void *i_security;
} 这里的inode结构是用于在内存中进行处理的,包含了一些实际介质上存储的inode所没有的成员,这些成员由内核自身在从底层文件系统读入信息时生成或动态建立。还有一些文件系统,如FAT和Reiserfs没有使用经典意义上的inode,因此必须从其包含的数据中提取信息并生成这里给出的形式。
inode中的大部分成员用于管理简单的状态信息。例如,i_atime、i_mtime、t_ctime分别存储了最后访问的时间、最后修改的时间、最后修改inode的时间。
文件长度保存在i_size,按字节计算。 i_blocks指定了文件按块计算的长度。块的大小是文件系统的特征,不属于文件自身。在许多文件系统创建时,会选择一个块长度,作为在硬件介质上分配存储空间的最小单位。
每个VFS inode(对给定的文件系统)都由一个唯一的编号标识,保存在i_ino中。i_count是一个使用计数器,指定访问该inode结构的进程数目。i_nlink也是一个计数器,记录使用该inode的硬链接总数。文件访问权限和所有权保存在i_mode(文件类型和访问权限)、i_uid和i_gid(与该文件相关的UID和GID)中。
在inode表示设备文件时,则需要i_rdev(设备号),它表示与哪个设备进行通信。通过i_rdev足以找到有关目标设备、我们感兴趣的所有信息。对于块设备,最终会找到struct block_device的一个实例。
如果inode表示设备特殊文件,那么i_rdev之后的匿名联合就包含了指向设备专用数据结构的指针。在i_bdev用于块设备,i_pipe包含了用于实现管道的inode的相关信息,而i_cdev用于字符设备。由于一个inode一次只能表示一种类型的设备,所以将i_pipe、i_bdev和i_cdev放置在联合中是安全的。
i_devices也与设备文件的处理有关联:利用该成员作为链表元素,使得块设备或字符设备可以维护一个inode的链表,每个inode表示一个设备文件,通过设备文件可以访问对应的设备。
3.2.1 inode操作
内核提供了大量函数,对inode进行操作。为此定义了一个函数指针的集合,以抽象这些操作,因为实际数据是通过具体文件系统的实现操作的。调用接口总是保持不变,但实际工作是由特定于实现的函数完成的。
inode结构有两个指针(i_op和i_fop),指向实现了上述抽象的数组。一个数组与特定于inode的操作有关,另一个数组则提供了文件操作。file_operations用于操作文件中包含的数据,而inode_operations负责管理结构性的操作(例如删除一个文件)和文件相关的元数据(例如,属性)。所有inode操作都集中到以下结构中:
struct inode_operations {
int (*create) (struct inode *,struct dentry *,int, struct nameidata *);
struct dentry * (*lookup) (struct inode *,struct dentry *, struct nameidata *);
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*symlink) (struct inode *,struct dentry *,const char *);
int (*mkdir) (struct inode *,struct dentry *,int);
int (*rmdir) (struct inode *,struct dentry *);
int (*mknod) (struct inode *,struct dentry *,int,dev_t);
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *);
int (*readlink) (struct dentry *, char __user *,int);
void * (*follow_link) (struct dentry *, struct nameidata *);
void (*put_link) (struct dentry *, struct nameidata *, void *);
void (*truncate) (struct inode *);
int (*permission) (struct inode *, int, struct nameidata *);
int (*setattr) (struct dentry *, struct iattr *);
int (*getattr) (struct vfsmount *mnt, struct dentry *, struct kstat *);
int (*setxattr) (struct dentry *, const char *,const void *,size_t,int);
ssize_t (*getxattr) (struct dentry *, const char *, void *, size_t);
ssize_t (*listxattr) (struct dentry *, char *, size_t);
int (*removexattr) (struct dentry *, const char *);
void (*truncate_range)(struct inode *, loff_t, loff_t);
long (*fallocate)(struct inode *inode, int mode, loff_t offset,
loff_t len);
}inode_operations的部分函数说明如下:
- lookup根据文件系统对象的名称(表示为字符串)查找其inode实例。
- link用于删除文件。但根据上文的描述,如果硬链接的引用计数器表明该inode仍然被多个文件使用,则不会执行删除操作。
- xattr函数建立、读取、删除文件的扩展属性,经典的UNIX模型不支持这些属性。例如,可使用这些属性实现访问控制表(access control list,简称ACL)。
- truncate修改指定inode的长度。该函数只接受一个参数,即所处理的inode的数据结构。在调用该函数之前,必须将新的文件长度手工设置到inode结构的i_size成员。
- truncate_range用于截断一个范围内的块(即,在文件中穿孔),但该操作当前只有共享内存文件系统支持。
- follow_link根据符号链接查找目标文件的inode。因为符号链接可能是跨文件系统边界的,该例程的实现通常非常短,实际工作很快委托给一般的VFS例程完成。
- fallocate用于对文件预先分配空间,在一些情况下可以提高性能。但只有很新的文件系统(如Reiserfs或Ext4)才支持该操作。
struct dentry在所述很多函数原型中用作参数。struct dentry是一种标准化的数据结构,可以表示文件名或目录。它还建立了文件名及其inode之间的关联。
3.2.2 inode链表
(1)链表
每个inode都有一个i_list成员,可以将inode存储在一个链表中。根据inode的状态,它可能有四种主要的情况。
① inode存在于内存中,未关联到任何文件,也不处于活动使用状态。
② inode结构在内存中,正在由一个或多个进程使用,通常表示一个文件。两个计数器(i_count和i_nlink)的值都必须大于0。文件内容和inode元数据都与底层块设备上的信息相同。
③ inode处于活动使用状态。其数据内容已经改变,与存储介质上的内容不同。这种状态的inode被称作脏的。
④ 在检测到可移动设备的介质改变时,此前使用的inode就都没有意义了,另外文件系统重新装载时也会发生这种情况。
fs/inode.c中内核定义了两个全局变量表头,inode_unused用于有效但非活动的inode(上述第1类),inode_in_use用于所有使用但未改变的inode(第2类),脏的inode(第3类)保存在一个特定于超级块的链表中。
inode还通过一个特定于超级块的链表维护,表头是super_block->s_inodes。i_sb_list用作链表元素。但超级块管理了更多的inode链表,与i_sb_list所 在的链表是独立的。如果一个inode是脏的,即其内容已经被修改,则列入脏链表,表头为super_block->s_dirty,链表元素是i_list。另外两个链表(表头为super_block->s_iosuper_block->s_more_io)使用同样的链表元素i_list。这两个链表包含的是已经选中向磁盘回写的inode,但正在等待回写进行。
(2)散列表
每个inode不仅出现在特定于状态的链表中,还在一个散列表中出现,以支持根据inode编号和超级块快速访问inode,这两项的组合在系统范围内是唯一的。该散列表是一个数组,可以借助于全局变量inode_hashtable(也定义在fs/inode.c中)来访问。该表启动期间在fs/inode.c中的inode_init函数中初始化。消息输出表明,该数组的长度基于可用的物理内存计算。
wolfgang@meitner> dmesg
...
Inode-cache hash table entries: 262144 (order: 9, 2097152 bytes)
...fs/inode.c中的hash函数用于计算散列和(我不会讲述该散列方法的实现)。它将inode编号和超级块对象的地址合并为一个唯一的编号,保证位于散列表已经分配的下标范围内。碰撞照例通过溢出链表解决。inode的成员i_hash用于管理溢出链表。
3.3 特定于进程的信息
文件描述符(就是整数)用于在一个进程内唯一地标识打开的文件。这假定了内核能够在用户进程中的描述符和内核内部使用的结构之间,建立一种关联。每个进程的task_struct中包含了用于完成该工作的成员。
//
struct task_struct {
...
/* 文件系统信息 */
int link_count, total_link_count;
...
/* 文件系统信息 */
struct fs_struct *fs;
/* 打开文件信息 */
struct files_struct *files;
/* 命名空间 */
struct nsproxy *nsproxy;
...
} 整数成员link_count和total_link_count用于在查找环形链表时防止无限循环。进程的文件系统相关数据保存在fs中,例如当前工作目录和chroot限制有关的信息。由于内核允许同时运行多个模仿独立系统的容器,从容器角度看似“全局”的每个资源,都由内核包装起来,分别根据每个容器进行管理。虚拟文件系统也受到影响,因为各个容器可能因装载点的不同导致不同的目录层次结构。对应的信息包含在ns_proxy->mnt_namespace中。
task_struct的file成员类型为files_struct。其定义如下:
//
struct files_struct {
atomic_t count;
struct fdtable *fdt;
struct fdtable fdtab;
int next_fd;
struct embedded_fd_set close_on_exec_init;
struct embedded_fd_set open_fds_init;
struct file * fd_array[NR_OPEN_DEFAULT];
}; next_fd表示下一次打开新文件时使用的文件描述符。close_on_exec_init和open_fds_init是位图。 对执行exec时将关闭的所有文件描述符,在close_on_exec中对应的比特位都将置位。open_fds_init是最初的文件描述符集合。struct embedded_fd_set只是一个简单的unsigned long整数,封装在一个特殊的结构中。
//
struct embedded_fd_set {
unsigned long fds_bits[1];
}; fd_array的每个数组项都是一个指针,指向每个打开文件的struct file实例。默认情况下,内核允许每个进程打开 NR_OPEN_DEFAULT个文件,该值定义在 include/linux/sched.h中,默认值为BITS_PER_LONG。因此在32位系统上,允许打开文件的初始数目是32;64位系统可以同时处理64个文件。如果一个进程试图同时打开更多的文件,内核必须对files_struct中用于管理与进程相关的所有文件信息的各个成员,分配更多的内存空间。最重要的信息包含在fdtab中。内核为此定义了另一个数据结构。
//
struct fdtable {
unsigned int max_fds;
struct file ** fd; /* 当前fd_array */
fd_set *close_on_exec;
fd_set *open_fds;
struct rcu_head rcu;
struct files_struct *free_files;
struct fdtable *next;
}; struct files_struct中包含了该结构的一个实例和指向一个实例的指针,因为这里使用了RCU机制以便在无需锁定的情况下读取这些数据结构,这可以加速处理。在讨论具体的做法之前,我们需要介绍各个成员的语义。
max_fds指定了进程当前可以处理的文件对象和文件描述符的最大数目。这里没有固有的上限,因为这两个值都可以在必要时增加(只要没有超出由Rlimit指定的值,但这与文件结构关)。尽管内核使用的文件对象和文件描述符的数目总是相同的,但必须定义不同的最大数目。这归因于管理相关数据结构的方法。
- fd是一个指针数组,每个数组项指向一个file结构的实例,管理一个打开文件的所有信息。用户空间进程的文件描述符充当数组索引。该数组当前的长度由max_fds定义。
- open_fds是一个指向位域的指针,该位域管理着当前所有打开文件的描述符。每个可能的文件描述符都对应着一个比特位。如果该比特位置位,则对应的文件描述符处于使用中;否则该描述符未使用。当前比特位置的最大数目由max_fdset指定。
- close_on_exec也是一个指向位域的指针,该位域保存了所有在exec系统调用时将要关闭的文件描述符的信息。
初看起来,struct fdtable和struct files_struct之间某些信息似乎是重复的:exec时关闭文件描述符和打开文件描述符两个位图,以及file指针的数组。事实上并非如此,因为file_struct中的成员是数据结构真正的实例,而fdtable的成员则是指针。实际上,后者的成员fd、open_fds和close_on_exec都初始化为指向前者对应的3个成员。因此,fd数组包含了NR_OPEN_DEFAULT项。close_on_exec 和 open_fds 位图最初包括 BITS_PER_LONG 个 比 特 位 。 由 于NR_OPEN_DEFAULT设置为BITS_PER_LONG,所有这些长度都是相同的。如果需要打开更多文件,内核会分配一个fd_set的实例,替换最初的embedded_fd_set。fd_set定义如下:
//
#define __NFDBITS (8 * sizeof(unsigned long))
#define __FD_SETSIZE 1024
#define __FDSET_LONGS (__FD_SETSIZE/__NFDBITS)
typedef struct {
unsigned long fds_bits [__FDSET_LONGS];
} __kernel_fd_set;
typedef __kernel_fd_set fd_set; 要注意,struct embedded_fd_set可以转换为struct fd_set。在这种意义上讲,embedded_fd_set是fd_set的缩小版,可以同样使用,但占用的空间较小。如果两个位图或fd数组的初始长度限制太低,内核可以将对应的指针指向更大的结构,以扩展空间。数组扩展的“步长”是不同的,这也说明了为什么该结构中描述符和文件数量需要两个不同的最大值。还需要讨论files_struct定义时用到的一个结构:struct file。该结构保存了内核所看到的文件的特征信息。
其定义如下(稍有简化):
//
struct file {
struct list_head fu_list;
struct path f_path;
#define f_dentry f_path.dentry
#define f_vfsmnt f_path.mnt
const struct file_operations *f_op;
atomic_t f_count;
unsigned int f_flags;
mode_t f_mode;
loff_t f_pos;
struct fown_struct f_owner;
unsigned int f_uid, f_gid;
struct file_ra_state f_ra;
unsigned long f_version;
...
struct address_space *f_mapping;
...
}; 各个成员的语义如下。
- f_uid和f_gid指定了用户的UID和GID。
- f_owner包含了处理该文件的进程有关的信息(因而也确定了SIGIO信号发送的目标PID,以实现异步输入输出)。
- 预读特征保存在f_ra。这些值指定了在实际请求文件数据之前,是否预读文件数据、如何预读(预读可以提高系统性能)。
- 打开文件时传递的模式参数(通常指定读、写或读写访问模式)保存在f_mode字段中。
- f_flags指定了在open系统调用时传递的额外的标志。
- 文件位置指针的当前值(对于顺序读取操作或读取文件特定部分的操作,都很重要)保存在f_pos变量中,表示与文件起始处的字节偏移。
- f_path封装了下面两部分信息:① 文件名和inode之间的关联;② 文件所在文件系统的有关信息。
path数据结构定义如下:
//
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
}; struct dentry提供了文件名和inode之间的关联,有关所在文件系统的信息包含在struct vfs_mount中。由于以前的一些内核版本没有使用struct path,而是将dentry和vfsmount成员显式嵌入到struct file中,因此需要使用相应的辅助宏,以确保尚未更新到新接口的代码仍然能够工作。
- f_op指定了文件操作调用的各个函数。
- f_version由文件系统使用,以检查一个file实例是否仍然与相关的inode内容兼容。这对于确保已缓存对象的一致性很重要。
- mapping指向属于文件相关的inode实例的地址空间映射。通常它设置为inode->i_mapping,但文件系统或其他内核子系统可能会修改它。
每个超级块都提供了一个s_list成员用作表头,以建立file对象的链表,链表元素是file->f_list。该链表包含该超级块表示的文件系统的所有打开文件。例如,在以读/写模式装载的文件系统以只读模式重新装载时,会扫描该链表。当然,如果仍然有按写模式打开的文件,是无法重新装载的,因而内核需要检查该链表来确认。file实例可以用get_empty_filp分配,该函数利用了自身的缓存并将实例用基本数据预先初始化。
提高初始限制
每当内核打开一个文件或做其他的操作时,如果需要file_struct提供比初始值更多的项,则调用expand_files。该函数检查是否有必要增大数组,如果是这样则调用expand_fdtable。该函数实现如下(稍有简化)。
// fs/file.c
static int expand_fdtable(struct files_struct *files, int nr)
{
struct fdtable *new_fdt, *cur_fdt;
spin_unlock(&files->file_lock);
new_fdt = alloc_fdtable(nr);
spin_lock(&files->file_lock);
copy_fdtable(new_fdt, cur_fdt);
rcu_assign_pointer(files->fdt, new_fdt);
if (cur_fdt->max_fds > NR_OPEN_DEFAULT)
free_fdtable(cur_fdt);
return 1;
} alloc_fdtable分配一个文件描述符表,可以容纳最大可能数目的项,并为增大的位图分配内存(只有同时增大所有的组件才有意义)。此后,该函数将文件描述符表先前的内容复制到新的、增大的实例中。将files_fdt指针切换到新实例的过程由RCU函数rcu_assign_pointer处理,然后释放旧的文件描述符表。
3.4 文件操作
文件操作由标准库的函数执行,这些函数指示内核执行系统调用,然后系统调用执行所需的操作。因而VFS层提供了抽象的操作,以便将通用文件对象与具体文件系统实现的底层机制关联起来。
各个file实例都包含一个指向struct file_operations实例的指针,该结构保存了指向所有可能文件操作的函数指针。该结构定义如下:
//
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long,loff_t);
ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long,loff_t);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, struct dentry *, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*dir_notify)(struct file *filp, unsigned long arg);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
}; 仅当文件系统以模块形式装载并未编译到内核中时,才使用owner项。该项指向在内存中表示模块的数据结构。
- read和write分别负责读写数据。这两个函数的参数包括文件描述符、缓冲区(放置读/写数据)和偏移量(指定在文件中读写数据的位置),另一个参数指定了需要读取和写入的字节数目。
- aio_read用于异步读取操作。
- open打开一个文件,这相当于将一个file对象关联到一个inode。
- file对象的使用计数器到达0时,调用release。换句话说,即该文件不再使用时。这使得底层实现能够释放不再需要的内存和缓存内容。
- 如果文件的内容映射到进程的虚拟地址空间中,访问文件就变得很容易。这通过mmap完成,其运行方式已经在第3章讨论过。
- readdir读取目录内容,因此只对目录对象适用。
- ioctl用于与硬件设备通信,因而只能用于设备文件(不能用于其他对象,因为其他对象对应的file_operations中,ioctl为NULL指针)。在有必要向设备发送控制命令时,将使用该方法(write函数用于发送数据)。尽管该函数对所有外设的名称和调用语法都相同,但实际支持的命令与具体硬件相关。
- poll用于poll和select系统调用,以便实现同步的I/O多路复用。这意味着什么?在进程等待来自文件对象的输入数据时,需要使用read函数。如果没有数据可用(在进程从外部接口读取数据时,可能有这样的情况),该调用将阻塞,直至数据可用。如果一直没有数据,read函数将永远阻塞,这将导致不可接受的情况出现。
select系统调用也基于poll方法,用于解决这种情况。它设置一个超时限制,如果超过一定时间没有数据到达,则放弃读取操作。这确保了在没有其他数据可用时,程序流程可以恢复正常。
- 在文件描述符关闭时将调用flush,同时将使用计数器减1,这一次计数器不必是0(计数器为0时,将执行release)。网络文件系统需要这个函数,以标记传输结束。
- fsync由fsync和fdatasync系统调用使用,用于将内存中的文件数据与存储介质同步。
- fasync用于启用/停用由信号控制的输入和输出(通过信号通知进程文件对象发生了改变)。
- readv和writev用于同名系统调用的实现,用以实现向量的读取和写入。向量本质上是一个结构,用以提供一个非连续的内存区域,放置读取的结果或写入的数据。该技术称之为快速分散—聚集(fast scatter-gather)。它用于避免多次read/write调用,以免降低性能。
- lock函数用于锁定文件。它用于对多个进程的并发文件访问进行同步。
- revalidate由网络文件系统使用,以确保在介质改变后远程数据的一致性。
- check_media_change只适用于设备文件,由于检查在上一次访问以来是否发生了介质改变。主要的例子是用户可以换介质的设备,如光驱和软驱的块设备文件(硬盘通常不能换)。
- sendfile通过sendfile系统调用在两个文件描述符之间交换数据。因为套接字(参见第12章)也表示为文件描述符,该函数也用于实现网络上简单、高效的数据交换。
- splice_read和splice_write用于从管道向文件传输数据,反之亦然。
如果一个对象使用这里给出的结构作为接口,那么并不必实现所有的操作。有两种方法可以指定某个方法不可用,一种是将函数指针设置为NULL,另一种是将函数指针指向一个占位函数,该函数直接返回错误值。
// fs/block_dev.c
const struct file_operations def_blk_fops = {
.open = blkdev_open,
.release = blkdev_close,
.llseek = block_llseek,
.read = do_sync_read,
.write = do_sync_write,
.aio_read = generic_file_aio_read,
.aio_write = generic_file_aio_write_nolock,
.mmap = generic_file_mmap,
.fsync = block_fsync,
.unlocked_ioctl = block_ioctl,
.splice_read = generic_file_splice_read,
.splice_write = generic_file_splice_write,
};Ext3文件系统使用一个不同的函数集。
// fs/ext3/file.c
const struct file_operations ext3_file_operations = {
.llseek = generic_file_llseek,
.read = do_sync_read,
.write = do_sync_write,
.aio_read = generic_file_aio_read,
.aio_write = ext3_file_write,
.ioctl = ext3_ioctl,
.mmap = generic_file_mmap,
.open = generic_file_open,
.release = ext3_release_file,
.fsync = ext3_sync_file,
.splice_read = generic_file_splice_read,
.splice_write = generic_file_splice_write,
};尽管这两个对象分配了不同的指针,但也有些指针是相同的,例如以generic_前缀开头的函数,这些是VFS层的通用辅助函数。
3.4.1 目录信息
除了打开文件描述符的列表之外,还必须管理其他特定于进程的数据。因而每个task_struct实例都包含一个指针,指向另一个结构,类型为fs_struct。
//
struct fs_struct {
atomic_t count;
int umask;
struct dentry * root, * pwd, * altroot;
struct vfsmount * rootmnt, * pwdmnt, * altrootmnt;
}; umask表示标准的掩码,用于设置新文件的权限。其值可以使用umask命令读取或设置。在内部由同名的系统调用完成。该结构中类型为dentry的成员指向目录的名称,vfsmount类型的成员表示一个已经装载的文件系统。
dentry和vfsmount类型的成员各有3个,名称类似。实际上,这些项是成对的,并且彼此关联。
- root和rootmnt指定了相关进程的根目录和文件系统。通常二者分别是/目录和系统的root文件系统。当然,对于通过chroot(暗中通过同名的系统调用)锁定到某个子目录的进程来说,情况并非如此。那么相应的进程就会使用某个子目录,而不是全局的根目录,该进程会将该子目录视为其根目录。
- pwd和pwdmnt指定了当前工作目录和文件系统的vfsmount结构。在进程改变其当前目录时,二者都会动态改变。在使用shell时,这是很频繁的(cd命令)。尽管每次chdir系统调用都会改变pwd的值,但仅当进入了一个新的装载点时,pwdmnt才会改变。
- cd /mnt改变pwd项但未改变pwdmnt项,我们仍然处于根目录所在的文件系统中。
- cd floppy同时改变了pwd和pwdmnt的值,因为已经切换到一个新目录,并且进入到一个新的文件系统。
- altroot和altrootmnt成员用于实现个性(personality)。这种特性允许为二进制程序建立一个仿真环境,使得程序认为是在不同于Linux的某个操作系统下运行。
3.4.2 VFS命名空间
我们知道内核提供了实现容器的可能性。单一的系统可以提供许多容器,但容器中的进程无法感知容器外部的世界,也无法得知所在容器的有关信息。容器彼此完全独立,从VFS角度来看,这意味着需要针对每个容器分别跟踪装载的文件系统。单一的全局视图是不够的。
VFS命名空间是所有已经装载、构成某个容器目录树的文件系统的集合。通常调用fork或clone建立的进程会继承其父进程的命名空间。但可以设置CLONE_NEWNS标志,以建立一个新的VFS命名空间。如果修改新的命名空间,改变不会传播到属于不同命名空间的进程。对其他命名空间的改变也不会影响新的命名空间。
回想一下struct task_struct包含的成员nsproxy,该成员负责命名空间的处理。内核使用以下结构(稍有简化)管理命名空间。在各种命名空间中,其中之一是VFS命名空间。
//
struct nsproxy {
...
struct mnt_namespace *mnt_ns;
...
}; 实现VFS命名空间所需信息的数量相对很少:
//
struct mnt_namespace {
atomic_t count;
struct vfsmount * root;
struct list_head list;
...
}; count是一个使用计数器,指定了使用该命名空间的进程数目。root指向根目录的vfsmount实例,list是一个双链表的表头,该链表保存了VFS命名空间中所有文件系统的vfsmount实例,链表元素是vfsmount的成员mnt_list。
命名空间操作(如mount和umount)并不作用于内核的全局数据结构。相反,它们操作的是当前进程的命名空间实例,可以通过task_struct的同名成员访问。改变会影响命名空间的所有成员,因为一个命名空间中的所有进程共享同一个命名空间实例。
3.5 目录项缓存
由于块设备速度较慢,可能需要很长时间才能找到与一个文件名关联的inode。即使设备数据已经在页缓存中,仍然每次都会重复整个查找操作。
Linux使用目录项缓存(简称dentry缓存)来快速访问此前的查找操作的结果,该缓存围绕着struct dentry建立。在VFS连同文件系统实现读取的一个目录项(目录或文件)的数据之后,则创建一个dentry实例,以缓存找到的数据。
3.5.1 dentry结构
该结构定义如下:
//
struct dentry {
atomic_t d_count;
unsigned int d_flags; /* 由d_lock保护 */
spinlock_t d_lock; /* 每个dentry的锁 */
struct inode *d_inode; /* 文件名所属的inode,如果为NULL,则表示不存在的文件名 */
/*
* 接下来的3个字段由__d_lookup处理
* 将它们放置在这里,使之能够装填到一个缓存行中
*/
struct hlist_node d_hash; /* 用于查找的散列表 */
struct dentry *d_parent; /* 父目录的dentry实例 */
struct qstr d_name;
struct list_head d_lru; /* LRU链表 */
union {
struct list_head d_child;
/* 链表元素,用于将当前dentry连接到父目录dentry的d_subdirs链表中 */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* 子目录/文件的目录项链表 */
struct list_head d_alias; /* 链表元素,用于将dentry连接到inode的i_dentry链表中 */
unsigned long d_time; /* 由d_revalidate使用 */
struct dentry_operations *d_op;
struct super_block *d_sb; /* dentry树的根,超级块 */
void *d_fsdata; /* 特定于文件系统的数据 */
int d_mounted;
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* 短文件名存储在这里 */
}; 各个dentry实例组成了一个网络,与文件系统的结构形成一定的映射关系。与给定目录下的所有文件和子目录相关联的dentry实例,都归入到d_subdirs链表(在目录对应的dentry实例中)。子结点的d_child成员充当链表元素。
但其中并非完全映射文件系统的拓扑结构,因为dentry缓存只包含文件系统结构的一小部分。最常用文件和目录对应的目录项才保存在内存中。原则上,可以为所有文件系统对象都生成dentry项,但物理内存空间和性能原因都限制了这样做。
我们经常提到,dentry结构的主要用途是建立文件名和相关的inode之间的关联。结构中有3个成员用于该目的。
(1)d_inode是指向相关的inode实例的指针
如果dentry对象是为一个不存在的文件名建立的,则d_inode为NULL指针。这有助于加速查找不存在的文件名,通常情况下,这与查找实际存在的文件名同样耗时。
(2) d_name指定了文件的名称。qstr是一个内核字符串的包装器。它存储了实际的char *字符串以及字符串长度和散列值,这使得更容易处理查找工作。
这里并不存储绝对路径,只有路径的最后一个分量,例如对/usr/bin/emacs只存储emacs,因为上述链表结构已经映射了目录结构。
(3) 如果文件名只由少量字符组成,则保存在d_iname中,而不是dname中,以加速访问。
短文件名的长度上限由DNAME_INLINE_NAME_LEN指定,最多不超过16个字符。但内核有时能够容纳更长的文件名,因为该成员位于结构的末尾,而容纳该数据的缓存行可能仍然有可用空间(这取决于体系结构和处理器类型)。
剩余成员的语义如下所示。
- d_flags可以包含几个标志,标志在include/linux/dcache.h中定义。但其中只有两个与我们的目的相关:DCACHE_DISCONNECTED指定一个dentry当前没有连接到超级块的dentry树。DCACHE_UNHASHED表明该dentry实例没有包含在任何inode的散列表中。要注意,这两个标志是彼此完全独立的。
- d_parent是一个指针,指向当前结点父目录的dentry实例,当前的dentry实例即位于父目录的d_subdirs链表中。对于根目录(没有父目录),d_parent指向其自身的dentry实例。
- 当前dentry对象表示一个装载点,那么d_mounted设置为1;否则其值为0。
- d_alias用作链表元素,以连接表示相同文件的各个dentry对象。在利用硬链接用两个不同名称表示同一文件时,会发生这种情况。对应于文件的inode的i_dentry成员用作该链表的表头。各个dentry对象通过d_alias连接到该链表中。
- d_op指向一个结构,其中包含了各种函数指针,提供对dentry对象的各种操作。这些操作必须由底层文件系统实现。我将在下文讨论该结构。
- s_sb是一个指针,指向dentry对象所属文件系统超级块的实例。该指针使得各个dentry实例散布到可用的(已装载的)文件系统。由于每个超级块结构都包含了一个指针,指向该文件系统装载点对应目录的dentry实例,因此dentry组成的树可以划分为几个子树。
内存中所有活动的dentry实例都保存在一个散列表中,该散列表使用fs/dcache.c中的全局变量dentry_hashtable实现。用d_hash实现的溢出链,用于解决散列碰撞。在下文中,我将该散列表称为全局dentry散列表。
内核中还有另一个dentry的链表,表头是全局变量dentry_unused(也在fs/dcache.c中初始化)。该链表包含哪些项?所有使用计数器(d_count)到达0(因而任何进程都不再使用)的dentry实例都自动地放置到该链表上。下一节将讨论dentry缓存的结构,读者会看到该链表是如何管理的。
在内核需要获取有关文件的信息时,使用dentry对象很方便,但它不是表示文件及其内容的主要对象,这一职责分配给了inode。例如,根据dentry对象无法确认文件是否已经修改。必须考察对应的inode实例,才能确认这一点,而使用dentry对象很容易找到inode实例。
3.5.2 缓存的组织
dentry结构不仅使得易于处理文件系统,对提高系统性能也很关键。他们通过最小化与底层文件系统实现的通信,加速了VFS的处理。
每个由VFS发送到底层实现的请求,都会导致创建一个新的dentry对象,以保存请求的结果。这些对象保存在一个缓存中,在下一次需要时可以更快速地访问,这样操作就能够更快速地执行。缓存是如何组织的?dentry对象在内存中的组织,涉及下面两个部分。
(1)一个散列表(dentry_hashtable)包含了所有的dentry对象。
(2)一个LRU(最近最少使用,least recently used)链表,其中不再使用的对象将授予一个最后宽限期,宽限期过后才从内存移除。
我们知道,散列表是用经典的方式实现的。fs/dcache.c中的d_hash函数用于确定dentry对象的散列位置。
LRU链表的处理有一点技巧。该链表的表头是全局变量dentry_unused,包含的对象是structdentry实例,使用的链表元素是struct dentry的d_lru成员。
在dentry对象的使用计数器(d_count)到达0时,会被置于LRU链表上,这表明没有什么应用程序正在使用该对象。一项在链表中越靠后,它就越老,这是经典的LRU原理。要注意,有时候dentry对象可能临时处于该链表上,尽管这些对象仍然处于活动使用状态,而且其使用计数大于0。这是因为内核进行了一些优化:在LRU链表上的dentry对象恢复使用时,不会立即将其从LRU链表移除,这可以省去一些锁操作,从而提高了性能。
由于LRU链表中的对象同时仍然处于散列表中,通过查找操作也可以找到dentry对象。一旦找到某个dentry对象之后,即可将其从LRU链表移除,因为它现在处于活动使用状态。同时将其使用计数器加1。
3.5.3 dentry操作
dentry_operations结构保存了一些指向各种特定于文件系统可以对dentry对象执行的操作的
函数指针。该结构定义如下:
//
struct dentry_operations {
int (*d_revalidate)(struct dentry *, struct nameidata *);
int (*d_hash) (struct dentry *, struct qstr *);
int (*d_compare) (struct dentry *, struct qstr *, struct qstr *);
int (*d_delete)(struct dentry *);
void (*d_release)(struct dentry *);
void (*d_iput)(struct dentry *, struct inode *);
char *(*d_dname)(struct dentry *, char *, int);
}; - d_iput从一个不再使用的dentry对象中释放inode(在默认的情况下,将inode的使用计数器减1,计数器到达0后,将inode从各种链表中移除)。
- 在最后一个引用已经移除(d_count到达0时)后,将调用d_delete。
- 在最后删除一个dentry对象之前,将调用d_release。d_release和d_delete的两个默认实现什么都不做。
- d_hash计算散列值,该值用于将对象放置到dentry散列表中。
- d_compare比较两个dentry对象的文件名。尽管VFS只执行简单的字符串比较,但文件系统可以替换默认实现,以适合自身的需求。
- d_revalidate对网络文件系统特别重要。它检查内存中的各个dentry对象构成的结构是否仍然能够反映当前文件系统中的情况。因为网络文件系统并不直接关联到内核/VFS,所有信息都必须通过网络连接收集,可能由于文件系统在存储端的改变,致使某些dentry不再有效。该函数用于确保一致性。
本地文件系统通常不会发生此类不一致情况,VFS对d_revalidate的默认实现什么都不做。
由于大多数文件系统都没有实现前述的这些函数,内核的惯例是这样:如果文件系统对每个函数提供的实现为NULL指针,则将其替换为VFS的默认实现。
3.5.4 标准函数
内核提供了几个辅助函数,可以简化对dentry对象的处理。以下辅助函数需要一个指向struct dentry的指针作为参数。每个都执行了一个简单的操作。
- 每当内核的某个部分需要使用一个dentry实例时,都需要调用dget。调用dget将对象的引用计数加1,即获取对象的一个引用。
- dput是dget的对应物。如果内核中的某个使用者不再需要一个dentry实例时,就必须调用dput。该函数将dentry对象的使用计数减1。如果计数下降到0,则调用dentry_operations->d_delete方法(如果可用)。此外,还需要使用d_drop从全局dentry散列表移除该实例,并将其置于LRU链表上。如果在调用dput时该对象并未包含在散列表中,则通过kfree将其从内存中删除。
- d_drop将一个dentry实例从全局dentry散列表移除。调用dput时,如果使用计数下降到0则自动调用该函数,另外如果需要使一个缓存的dentry对象失效,也可以手工调用。__d_drop是d_drop的一个变体,并不自动处理锁定。
- d_delete在确认dentry对象仍然包含在全局dentry散列表中之后,使用__d_drop将其移除。如果该对象此时只剩余一个使用者,还会调用dentry_iput将相关inode的使用计数减1。d_delete通常紧挨着dput之前调用。这样做确保了dput删除了dentry对象,因为它不再处于全局dentry散列表中。
有些辅助函数更为复杂,因此最好查看其原型。
//
extern void d_instantiate(struct dentry *, struct inode *);
struct dentry * d_alloc(struct dentry *, const struct qstr *);
struct dentry * d_alloc_anon(struct inode *);
struct dentry * d_splice_alias(struct inode *, struct dentry *);
static inline void d_add(struct dentry *entry, struct inode *inode);
struct dentry * d_lookup(struct dentry *, struct qstr *); - d_instantiate将一个dentry实例与一个inode关联起来。这意味着设置d_inode字段并将该dentry增加到inode->i_dentry链表。
- d_add调用了d_instantiate。此外,该对象还添加到全局dentry散列表dentry_hashtable中。
- d_alloc为一个新的struct dentry实例分配内存。初始化各个字段,如果给出了一个表示父结点的dentry,则新dentry对象的超级块指针从父结点获取。此外,新的dentry添加到父结点的子目录或文件链表,表头是parent->d_subdirs。
- d_alloc_anon为一个struct dentry实例分配内存,但并不设置与父结点dentry的任何关联,因此该函数与d_alloc相比去掉了相关参数。新的dentry添加到两个链表中:特定于超级块、用于匿名dentry对象的链表,表头为super_block->s_anon;与inode关联的所有dentry实例的链表,表头为inode->i_dentry。要注意,如果inode已经包含了一个断开连接的dentry,由前一次对d_alloc_anon的调用分配,那么这一次将使用原来的dentry,而不再分配新的实例。
- d_splice_alias将一个断开连接的dentry对象连接到dentry树中。该功能的inode参数表示与dentry关联的inode。如果inode表示目录之外的文件系统对象,则调用d_add就足够了。对于目录来说,d_splice_alias函数确保只有一个dentry别名存在,这需要更多管理工作,我不会详细论述。
- d_lookup根据目录对应的dentry实例,搜索名称为name的文件对应的dentry对象。
4 处理VFS对象
如上所述的各数据结构,是VFS层工作的基础。我们在后面几节里将具体讨论该抽象层。我们首先关注文件系统的装载和卸载(和文件系统注册,这是装载和卸载的先决条件)。我接下来介绍最重要,也是大家最感兴趣的功能,即如何通过同样的接口表示文件和所有其他的对象。
首先,我们从标准库用来与内核通信的系统调用谈起。
4.1 文件系统操作
尽管文件操作对所有应用程序来说都属于标准功能,但对文件系统的操作只限于少量几个系统程序,即用于装载和卸载文件系统的mount和umount程序 。
还必须考虑到另一个重要的方面,即文件系统在内核中是以模块化形式实现的。这意味着可以将文件系统编译到内核中,而内核自身在编译时也完全可以限制不支持某个特定的文件系统。事实上大约有50个文件系统,把这些代码都编译到内核中几乎没有意义。
因此,每个文件系统在使用以前必须注册到内核,这样内核能够了解可用的文件系统,并按需调用装载功能。
4.1.1 注册文件系统
在文件系统注册到内核时,文件系统是编译为模块,或者持久编译到内核中,都没有差别。如果不考虑注册的时间(持久编译到内核的文件系统在启动时注册,模块化文件系统在相关模块载入内核时注册),在两种情况下所用的技术方法是同样的。
fs/super.c中的register_filesystem用来向内核注册文件系统。该函数的结构非常简单。所有文件系统都保存在一个(单)链表中,各个文件系统的名称存储为字符串。在新的文件系统注册到内核时,将逐元素扫描该链表,直至到达链表尾部或找到所需的文件系统。在后一种情况下,会返回一个适当的错误信息(一个文件系统不能注册两次);否则,将描述新文件系统的对象置于链表末尾,这样就完成了向内核的注册。
用于描述文件系统的结构定义如下:
//
struct file_system_type {
const char *name;
int fs_flags;
struct super_block *(*get_sb) (struct file_system_type *, int,
const char *, void *, struct vfsmount *);
void (*kill_sb) (struct super_block *);
struct module *owner;
struct file_system_type * next;
struct list_head fs_supers;
}; name保存了文件系统的名称,是一个字符串(因此包含了例如reiserfs、ext3等类似的值)。fs_flags是使用的标志,例如标明只读装载、禁止setuid/setgid操作或进行其他的微调。owner是一个指向module结构的指针,仅当文件系统以模块形式加载时,owner才包含有意义的值(NULL指针表示文件系统已经持久编译到内核中)。
各个可用的文件系统通过next成员连接起来,这里无法利用标准的链表功能,因为这是一个单链表。
我们最感兴趣的成员是fs_supers和函数指针get_sb。对于每个已经装载的文件系统,在内存中都创建了一个超级块结构。该结构保存了文件系统它本身和装载点的有关信息。由于可以装载几个同一类型的文件系统(最好的例子是home和root分区,二者的文件系统类型通常相同),同一文件系统类型可能对应了多个超级块结构,这些超级块聚集在一个链表中。fs_supers是对应的表头。在下文讨论文件系统装载时,会涉及更多细节。
另外,用于从底层存储介质读取超级块的函数(其地址保存在get_sb)对装载过程也很重要。逻 辑 上 , 该 函 数 依 赖 具 体 的 文 件 系 统 , 不 能 实 现 为 抽 象 。 而 且 该 函 数 也 不 能 保 存 在 上 述 的super_operations结构中,因为超级块对象和指向该结构的指针都是在调用get_sb之后创建的。kill_super在不再需要某个文件系统类型时执行清理工作。
4.1.2 装载和卸载
目录树的装载和卸载比仅仅注册文件系统复杂得多,因为后者只需要向一个链表添加对象,而前者需要对内核的内部数据结构执行很多操作,所以要复杂得多。文件系统的装载由mount系统调用发起。在详细讨论各个步骤之前,我们需要阐明在现存目录树中装载新的文件系统必须执行的任务。我们还需要讨论用于描述装载点的数据结构。
(1)vfsmount结构
UNIX采用了一种单一的文件系统层次结构,新的文件系统可以集成到其中,如图4所示。

图4 文件系统层次结构,包括各种文件系统类型
图中给出了3种不同的文件系统。全局的根目录/使用了Ext2文件系统,/mnt为Reiserfs文件系统,而/mnt/cdrom使用了ISO9660格式,这通常用于光盘。使用mount可查询目录树中各种文件系统的装载情况。
wolfgang@meitner> mount
/dev/hda7 on / type ext2 (rw)
/dev/hda3 on /mnt type reiserfs (rw)
/dev/hdc on /mnt/cdrom type iso9660 (ro,noexec,nosuid,nodev,user=wolfgang)/mnt和/mnt/cdrom目录被称为装载点,因为这是附接(装载)文件系统的位置。每个装载的文件系统都有一个本地根目录,其中包含了系统目录(就光盘来说是source和libs目录)。在将文件系统装载到一个目录时,装载点的内容被替换为即将装载的文件系统的相对根目录的内容。前一个目录数据消失,直至新文件系统卸载才重新出现(当然,在此期间旧文件系统的数据不会被改变,但是无法访问)
在我们的例子中,装载是可以嵌套的。光盘装载在/mnt/cdrom目录中。这意味着ISO9660文件系统的相对根目录装载在一个Reiser文件系统内部,因而与用作全局根目录的Ext2文件系统是完全分离的。
在内核其他部分常见的父子关系,也可以用于更好地描述两个文件系统之间的关系。Ext2是/mnt中的Reiserfs的父文件系统。/mnt/cdrom中包含的是/mnt的子文件系统,与根文件系统Ext2无关(至少从这个角度看是这样)。
每个装载的文件系统都对应于一个vfsmount结构的实例,其定义如下
//
struct vfsmount {
struct list_head mnt_hash;
struct vfsmount *mnt_parent; /* 装载点所在的父文件系统 */
struct dentry *mnt_mountpoint; /* 装载点在父文件系统中的dentry */
struct dentry *mnt_root; /* 当前文件系统根目录的dentry */
struct super_block *mnt_sb; /* 指向超级块的指针 */
struct list_head mnt_mounts; /* 子文件系统链表 */
struct list_head mnt_child; /* 链表元素,用于父文件系统中的mnt_mounts链表 */
int mnt_flags;
/* 64位体系结构上,是一个4字节的空洞 */
char *mnt_devname; /* 设备名称,例如/dev/dsk/hda1 */
struct list_head mnt_list;
struct list_head mnt_expire; /* 链表元素,用于特定于文件系统的到期链表中 */
struct list_head mnt_share; /* 链表元素,用于共享装载的循环链表 */
struct list_head mnt_slave_list;/* 从属装载的链表 */
struct list_head mnt_slave; /* 链表元素,用于从属装载的链表 */
struct vfsmount *mnt_master; /* 指向主装载,从属装载位于master->mnt_slave_list链表上 */
struct mnt_namespace *mnt_ns; /* 所属的命名空间 */
/*
* 我们把mnt_count和mnt_expiry_mark放置在struct vfsmount的末尾,
* 以便让这些频繁修改的字段与结构的主体处于两个不同的缓存行中
* (这样在SMP机器上读取mnt_flags不会造成高速缓存的颠簸)
*/
atomic_t mnt_count;
int mnt_expiry_mark; /* 如果标记为到期,则其值为true */
}; mnt_mntpoint是当前文件系统的装载点在其父目录中的dentry结构。文件系统本身的相对根目录所对应的dentry保存在mnt_root中。两个dentry实例表示同一目录(即装载点)。这意味着,在文件系统卸载后,不必删除此前的装载点信息。在我讨论mount系统调用时,使用两个dentry项的必要性就一清二楚了。
mnt_sb指针建立了与相关的超级块之间的关联(对每个装载的文件系统而言,都有且只有一个超级块实例)。mnt_parent指向父文件系统的vfsmount结构。
文件系统之间的父子关系由上述结构的两个成员所实现的链表表示。mnt_mounts表头是子文件系统链表的起点,而mnt_child字段则用作该链表的链表元素。
系统的每个vfsmount实例,都还可以通过另外两种途径标识。一个命名空间的所有装载的文件系统都保存在namespace->list链表中。使用vfsmount的mnt_list成员作为链表元素。我在这里忽视拓扑结构的问题,因为所有(文件系统)的装载操作是相继执行的。
在nmt_flags可以设置各种独立于文件系统的标志。以下常数列出了所有可能的标志:
//
#define MNT_NOSUID 0x01
#define MNT_NODEV 0x02
#define MNT_NOEXEC 0x04
#define MNT_NOATIME 0x08
#define MNT_NODIRATIME 0x10
#define MNT_RELATIME 0x20
#define MNT_SHRINKABLE 0x100
#define MNT_SHARED 0x1000 /* 如果vfsmount是共享装载,则该标志置位 */
#define MNT_UNBINDABLE 0x2000 /* 如果vfsmount是不可绑定装载,则该标志置位 */
#define MNT_PNODE_MASK 0x3000 /* 传播标志掩码 */ 第一部分涉及经典的性质,如禁止setuid执行,或装载时设备文件的存在性或如何管理存取时间的处理。如果装载的文件系统是虚拟的,即没有物理后端设备,则设置MNT_NODEV。MNT_SHRINKABLE专用于NFS和AFS的,用来标记子装载。设置了该标记的装载允许自动移除。
最后一部分包含的标志,涉及共享装载和不可绑定的装载。
还使用了一个散列表,称作mount_hashtable,且定义在fs/namespace.c中。溢出链表以链表形式实现,链表元素是mnt_hash。vfsmount实例的地址和相关的dentry对象的地址用来计算散列和。mnt_namespace是装载的文件系统所属的命名空间。
mnt_count实现了一个使用计数器。每当一个vfsmount实例不再需要时,都必须用mntput将计数器减1。mntget与mntput相对,在获取vfsmount实例使用时,必须调用mntget。
剩余字段用来实现几个新的装载类型,这些主要是在内核版本2.6开发期间引入的。mnt_slave、mnt_slave_list和mnt_master用来实现从属装载(slave mount)。主装载(master mount)将所有从属装载保存在一个链表上 ,mnt_slave_list用作表头,而mnt_slave作为链表元素。所有从属装载都通过mnt_master指向其主装载。
共享装载更容易表示。内核所需做的就是将所有共享装载保存在一个循环链表上。mnt_share作为链表元素。
装载过期用mnt_expiry_mark处理。该成员用来表示装载的文件系统是否已经不再使用。mnt_expire用作链表元素,用于将所有可能自动过期的装载放置在一个链表上。
最后,mnt_ns指向该装载所属的命名空间。
(2)超级快管理
在装载新的文件系统时,vfsmount并不是唯一需要在内存中创建的结构。装载操作开始于超级块的读取。我在上文提到过几次这个结构,但没有严格地定义它。现在是定义该结构的时候了。file_system_type对象中保存的read_super函数指针返回一个类型为super_block的对象,用于在内存中表示一个超级块。它是借助于底层实现产生的。
该结构的定义非常冗长。 因此我在下面给出的是一个简化的版本。
//
struct super_block {
struct list_head s_list; /* 将该成员置于起始处 */
dev_t s_dev; /* 搜索索引,不是kdev_t */
unsigned long s_blocksize;
unsigned char s_blocksize_bits;
unsigned char s_dirt;
unsigned long long s_maxbytes; /* 最大的文件长度 */
struct file_system_type *s_type;
struct super_operations *s_op;
unsigned long s_flags;
unsigned long s_magic;
struct dentry *s_root;
struct xattr_handler **s_xattr;
struct list_head s_inodes; /* 所有inode的链表 */
struct list_head s_dirty; /* 脏inode的链表 */
struct list_head s_io; /* 等待回写 */
struct list_head s_more_io; /* 等待回写,另一个链表 */
struct list_head s_files;
struct block_device *s_bdev;
struct list_head s_instances;
char s_id[32]; /* 有意义的名字 */
void *s_fs_info; /* 文件系统私有信息 */
/* 创建/修改/访问时间的粒度,单位为ns(纳秒)。
粒度不能大于1秒 */
u32 s_time_gran;
}; - s_blocksize和s_blocksize_bits指定了文件系统的块长度(这对于硬盘上的数据组织特别有用)。本质上,这两个变量以不同的方式表示了相同信息。s_blocksize的单位是字节,而s_blocksize_bits则是对前一个值取以2为底的对数。
- s_maxbytes保存了文件系统可以处理的最大文件长度,因实现而异。
- s_type指向file_system_type实例,其中保存了与文件系统有关的一般类型的信息。
- s_root将超级块与全局根目录的dentry项关联起来。
只有通常可见的文件系统的超级块,才指向/(根)目录的dentry实例。具有特殊功能、不出现在通常的目录层次结构中的文件系统(例如,管道或套接字文件系统),指向专门的项,不能通过普通的文件命令访问。
处理文件系统对象的代码经常需要检查文件系统是否已经装载,而s_root可用于该目的。如果它为NULL,则该文件系统是一个伪文件系统,只在内核内部可见。否则,该文件系统在用户空间中是可见的。
- xattr_handler是一个指向结构的指针,该结构包含了一些用于处理扩展属性的函数指针。
- s_dev和s_bdev指定了底层文件系统的数据所在的块设备。前者使用了内核内部的编号,而后者是一个指向内存中的block_device结构的指针,该结构用于更详细地定义设备操作和功能。s_dev项总是一个数字。与此相反,s_bdev可以为NULL指针。
- s_fs_info是一个指向文件系统实现的私有数据的指针,VFS不操作该数据。
- s_time_gran指定了文件系统支持的各种时间戳的最大可能的粒度。该值对所有时间戳都是相同的,单位为ns。结构包含了两个表头,用于建立与超级块相关的inode和文件的集合。
- s_dirty是一个表头,用于脏inode的链表,在同步内存内容与底层存储介质上的数据时,使用该链表会更加高效。该链表只包含已经修改的inode,因此回写数据时并不需要扫描全部inode。该字段不能与s_dirt混淆,后者不是表头,而是一个简单的整型变量。如果以任何方式改变了超级块,需要向磁盘回写,都会将s_dirt设置为1。否则,其值为0。
- s_files链表包含了一系列file结构,列出了该超级块表示的文件系统上所有打开的文件。内核在卸载文件系统时将参考该链表。如果其中仍然包含为写入而打开的文件,则文件系统仍然处于使用中,卸载操作失败,并将返回适当的错误信息。
结构的第一个成员s_list是一个链表元素,用于将系统中所有的超级块聚集到一个链表中。该链表的表头是全程变量super_blocks,定义在fs/super.c中。
最后,各个超级块都连接到另一个链表中,表示同一类型文件系统的所有超级块实例,这里不考虑底层的块设备,但链表中的超级块的文件系统类型都是相同的。表头是file_system_type结构的fs_supers成员。s_instances用作链表元素。
s_op指向一个包含了函数指针的结构,该结构按熟悉的VFS方式,提供了一个一般性的接口,用于处理超级块相关操作。操作的实现必须由底层文件系统的代码提供。
该结构定义如下:
//
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb);
void (*destroy_inode)(struct inode *);
void (*read_inode) (struct inode *);
void (*dirty_inode) (struct inode *);
int (*write_inode) (struct inode *, int);
void (*put_inode) (struct inode *);
void (*drop_inode) (struct inode *);
void (*delete_inode) (struct inode *);
void (*put_super) (struct super_block *);
void (*write_super) (struct super_block *);
int (*sync_fs)(struct super_block *sb, int wait);
void (*write_super_lockfs) (struct super_block *);
void (*unlockfs) (struct super_block *);
int (*statfs) (struct super_block *, struct kstatfs *);
int (*remount_fs) (struct super_block *, int *, char *);
void (*clear_inode) (struct inode *);
void (*umount_begin) (struct super_block *);
int (*show_options)(struct seq_file *, struct vfsmount *);
int (*show_stats)(struct seq_file *, struct vfsmount *);
}; 该结构中的操作并不改变inode的内容,但会控制从底层文件系统实现获取和返回inode数据的方式。该结构还包括一些方法,用于执行其他操作,如重新装载文件系统。由于这些函数指针的名称清楚地表示了函数的作用,我在下面只是简单讲述一下。
- read_inode读取inode数据。奇怪的是,除了一个指向inode结构的指针之外,它不需要其他参数。函数接下来如何知道读取哪个inode?答案相对简单。传递进来的inode的i_ino字段,保存了一个inode编号,唯一标识了文件系统中需要读取的inode。底层实现的例程将读取该值,从存储介质取出有关数据,并填充inode对象剩余的字段。
- dirty_inode将传递的inode结构标记为“脏的”,因为其数据已经修改。
- delete_inode将inode从内存和底层存储介质删除。
在讨论文件系统实现时,读者会看到,从存储介质删除inode时,会移除指向相关数据块的指针,但文件数据不受影响(在未来的某个无法确定的时间,数据可能被覆盖)。只有能接触到计算机并了解文件系统结构,才足以恢复删除的文件(这对于敏感数据来说可能是一个问题)。
- 在进程结束数据的使用时,put_inode将inode使用计数器减1。
直至所有使用者都调用了该函数,并且计数器到达0的时候,我们才能将对象从内存删除。
- 当某个inode不再使用时,由VFS在内部调用clear_inode。它释放仍然包含数据的所有相关的内存页面。并非所有文件系统都实现了clear_inode,未实现该接口的文件系统能够以其他方式释放内存。
- write_super和write_super_lockfs将超级块写入存储介质。两个函数之间的差别在于其使用内核锁机制的方式。内核必须根据当前情况选择适当的函数。我不会详细讨论代码中的细节差别,因为二者本质上完成的工作是相同的。
- unlockfs用于Ext3和Reiserfs日志文件系统,以确保与设备映射器代码(Device Mapper Code)的正确交互。
- remount_fs重新装载一个已经装载的文件系统,选项可能有所改变(这发生在启动时,例如允许对root文件系统的写访问,而此前root文件系统是以只读访问方式装载的)。
- put_super将超级块的私有信息从内存移除,这发生在文件系统卸载、该数据不再需要时。
- statfs给出有关文件系统的统计信息,例如使用和未使用的数据块的数目,或文件名的最大长度。它与同名的系统调用有密切的协作。
- umount_begin仅用于网络文件系统(NFS、CIFS和9fs)和用户空间文件系统(FUSE)。它允许在卸载操作开始之前,与远程的文件系统提供者通信。仅在文件系统强制卸载时调用该方法。换句话说,它仅用于MNT_FORCE强制内核执行umount操作时,此时可能仍然有对该文件系统的引用。
- sync_fs将文件系统数据与底层块设备上的数据同步。
- show_options用于proc文件系统,用以显示文件系统装载的选项。show_stats提供了文件系统的统计信息,同样用于proc文件系统。
(3)mount系统调用
mount系统调用的入口点是sys_mount函数,其定义在fs/namespace.c中。图5给出了相关的代码流程图。
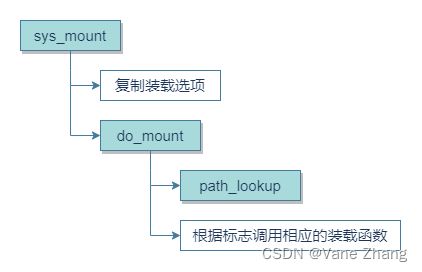
图5 sys_mount的代码流程图
这里讲述的方法仅用于在现存的root文件系统中装载一个新文件系统。上述算法的改进版本可以装载root文件系统本身,但不太值得单独讲述(其代码可以参看init/do_mounts.c中的mount_root)。
在装载选项(类型、设备和选项)已经由sys_mount从用户空间复制到内核空间,内核将控制转移给do_mount,该函数将分析传递的信息,并设置相应的标志。其中还将使用下文讨论的path_lookup函数,找到装载点的dentry项。
do_mount充当一个多路分解器,将仍然需要完成的工作委派给与装载类型相关的各个函数。
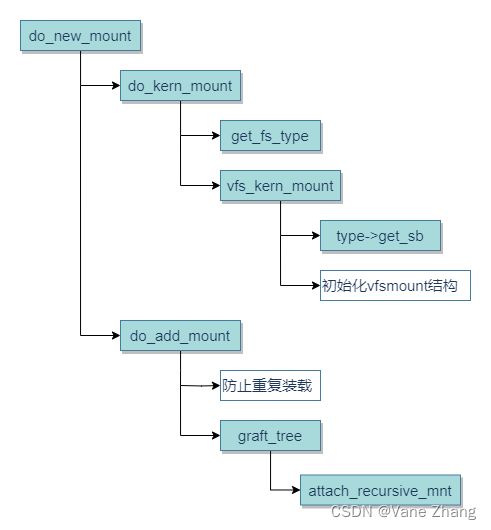
图6 do_new_mount的代码流程图
- do_remount修改已经装载的文件系统的选项(MS_REMOUNT)。
- do_loopback用于通过环回接口(loopback interface)装载一个文件系统(完成该操作需要MS_BIND标志)。
- do_move_mount(MS_MOVE)用来移动一个已经装载的文件系统。
- do_change_type负责处理共享、从属和不可绑定装载,它可以改变装载标志或在涉及的各个vfsmount实例之间建立所需的数据结构的关联。
- do_new_mount处理普通装载操作。这是默认情况,因此不需要特殊标志。do_new_mount值得仔细讨论一番,因为它使用很是频繁。其代码流程图如图8-6所示。do_new_mount分为两个部分:do_kern_mount和do_add_mount。
- do_kern_mount的初始任务是使用get_fs_type找到匹配的file_system_type实例。该辅助函数扫描已注册文件系统的链表(如上所述),返回正确的项。如果没有找到匹配的文件系统,该例程就自动加载对应的模块。此后,vfs_kern_mount调用特定于文件系统的get_sb函数读取相关的超级块,并返回structsuper_block的实例。
- do_add_mount处理一些必需的锁定操作,并确保一个文件系统不会重复装载到同一位置(当然,将同一文件系统多次装载到不同位置是可能的)。主要工作委托给graft_tree。新装载的 文件系统通过调用attach_recursive_mnt添加到父文件系统的命名空间。该函数定义如下。
// fs/namespace.c
static int attach_recursive_mnt(struct vfsmount *source_mnt,
struct nameidata *nd, struct nameidata *parent_nd)
{
struct vfsmount *dest_mnt = nd->mnt;
struct dentry *dest_dentry = nd->dentry;
...
mnt_set_mountpoint(dest_mnt, dest_dentry, source_mnt);
commit_tree(source_mnt);
...
}nameidata结构用于将一个 vfsmount实例和一个dentry实例聚集起来。在这里,该结构保存了装载点的dentry实例和该目录此前(即新的装载操作执行之前)所在文件系统的vfsmount实例。
mnt_set_mountpoint确保新的vfsmount实例的mnt_parent成员指向父文件系统的vfsmount实例,而mnt_mountpoint成员指向装载点在父文件系统中的denty实例。
//fs/namespace.c
void mnt_set_mountpoint(struct vfsmount *mnt, struct dentry *dentry,
struct vfsmount *child_mnt)
{
child_mnt->mnt_parent = mntget(mnt);
child_mnt->mnt_mountpoint = dget(dentry);
dentry->d_mounted++;
}这使得在内核卸载文件系统时,能够重建该文件系统装载之前的情形。旧的dentry实例的d_mounted值加1,这样内核能够识别出有一个文件系统装载在这里。
此外,新的vfsmount实例还添加到全局散列表以及父文件系统vfsmount实例中的子文件系统链表,使用的链表元素如上所述。这些工作由commit_tree执行:
//fs/namespace.c
static void commit_tree(struct vfsmount *mnt)
{
struct vfsmount *parent = mnt->mnt_parent;
...
list_add_tail(&mnt->mnt_hash, mount_hashtable +
hash(parent, mnt->mnt_mountpoint));
list_add_tail(&mnt->mnt_child, &parent->mnt_mounts);
...
}(4)共享子树
到现在为止我讨论过的机制涵盖了任何UNIX系统上都可用的标准装载情况。但Linux支持一些更高级的特性,可以更好地利用命名空间机制。由于这些特性是在内核版本2.6(确切地说,是内核版本2.6.16)开发期间引入的,其使用仍然多少有些限制。因此在讨论其实现之前,我先简要解释一下基本原理。对于实际应用的具体细节和mount工具的共享子树语义的详细描述,读者可以参见手册页mount(8)。另外,有关共享子树的详细特性,可以在http://lwn.net/Articles/159077/网页找到。
这些扩展装载选项(我将其集合称之为共享子树)对装载操作实现了几个新的属性。
- 共享装载:一组已经装载的文件系统,装载事件将在这些文件系统之间传播。如果一个新的文件系统装载到该集合的某个成员中,则装载的文件系统就将复制到集合的所有其他成员中。
- 从属装载:相比共享装载,它只是去掉了集合的所有成员之间的对称性。集合中有一个文件系统称之为主装载。主装载中的所有装载操作都会传播到从属装载中,但从属装载中的装载操作不会反向传播到主装载中。
- 不可绑定的装载:不能通过绑定操作复制。
- 私有装载:本质上就是为经典的UNIX装载类型取了个新名字,它们可以装载到文件系统中多个位置,但装载事件不会传播到这种文件系统,也不会从这种文件系统向外传播。
考虑一个装载到文件系统中多个位置的文件系统。这是UNIX和Linux的标准特性,用到目前为止讨论过的旧框架即可做到。设想图7左上部分描述的情形:目录/virtual包含了root文件系统3个相同的绑定装载,分别是/virtual/a、/virtual/b和/virtual/c。但我们还希望任何装载在/media中的媒介都还能在/virtual/user/media中可见,即使该媒介是在装载结构建立后添加的。解决方案是用共享装载替换绑定装载。在这种情况下,任何装载在/media中的文件系统,都可以在其共享装载集合的其他成员(/、/file/virtual/a/、/file/virtual/b/和/file/virtual/c/)中看到。图7右上部分给出了这种情况下的目录树。
如果上文介绍的文件系统结构用作容器的基础,一个容器的每个用户都可以看到所有其他容器,只需要查看/virtual/name/virtual的内容即可!通常,这不是我们想要的。 对该问题的一个补救措施是将/virtual转换为不可绑定子树。其内容接下来不能被绑定装载看到,而容器中的用户也无法看到外部的情况。图7左下部分说明了这种情况。
在所有容器的用户都应该看到装载在/media的设备时(例如,装载到/media/usbstick的USB存储棒),会引发另一个问题。如果/media在各个容器之间共享,显然是可以工作的,但有一个缺点,即任何容器的用户都会看到由任何其他容器装载的媒介。将/media转换为从属装载,则能够保持我们想要的特性(装载事件会从/传播过来),而且将各个容器彼此隔离开来。如图7右下部分所示,由用户A装载的摄像机不能被其他任何容器看到,而USB存储棒的装载点则会向下传播到/virtual的所有子目录中。

图7 共享子树的特性
我们现在把注意力转向对装载实现需要进行的扩展。如果MS_SHARED、MS_PRIVATE、MS_SLAVE或MS_UNBINDABLE其中某个标志传递到mount系统调用,那么do_mount将调用do_change_type改变给定装载的类型。该函数定义如下:
// fs/namespace.c
static int do_change_type(struct nameidata *nd, int flag)
{
struct vfsmount *m, *mnt = nd->mnt;
int recurse = flag & MS_REC;
int type = flag & ~MS_REC;
...
for (m = mnt; m; m = (recurse ? next_mnt(m, mnt) : NULL))
change_mnt_propagation(m, type);
return 0;
}nd中给出的路径的装载类型,可使用change_mnt_propagation改变。如果设置了MS_REC标志,则所有子装载的装载类型都将递归地改变。next_mnt提供了一个迭代器,能够遍历给定装载的所有子装载。
change_mnt_propagation负责对struct vfsmount的实例设置适当的传播标志。
// fs/pnode.c
void change_mnt_propagation(struct vfsmount *mnt, int type)
{
if (type == MS_SHARED) {
set_mnt_shared(mnt);
return;
}
do_make_slave(mnt);
if (type != MS_SLAVE) {
list_del_init(&mnt->mnt_slave);
mnt->mnt_master = NULL;
if (type == MS_UNBINDABLE)
mnt->mnt_flags |= MNT_UNBINDABLE;
}
}这对于共享装载是很简单的:用辅助函数set_mnt_shared设置MNT_SHARED标志就足够了。
如果必须建立从属装载、私有装载或不可绑定装载,内核必须重排装载相关的数据结构,使得目标vfsmount实例转化为从属装载。这是通过do_make_slave完成的。该函数执行以下几个步骤。
① 需要对指定的vfsmount实例,找到一个主装载和任何可能的从属装载。首先,内核搜索共享装载集合的各个成员。遍历到的各个vfsmount实例中,mnt_root成员与指定的vfsmount实例的mnt_root成员相同的第一个vfsmount实例,将指定为新的主装载。如果共享装载集合中不存在这样的成员,则将成员链表中第一个vfsmount实例用作主装载。
② 如果已经发现一个新的主装载,那么将所述vfsmount实例以及所有从属装载的实例,都设置为新的主装载的从属装载。
③ 如果内核找不到一个新的主装载,所述装载的所有从属装载现在都是自由的,它们不再有主装载了。
无论如何,都会移除MNT_SHARED标志。
在do_make_slave执行了这些调整之后,change_mnt_propagation还需要一些步骤来处理不可绑定装载和私有装载。对于这两种情况,如果所述装载是从属装载,则将其从从属装载链表中删除,并将其mnt_master设置为NULL,这两种装载类型都没有主装载。对于不可绑定的装载,将设置MNT_UNBINDABLE标志,以便识别。
在 向 系 统 装 载 新 的 文 件 系 统 时 , 共 享 子 树 显 然 也 影 响 到 内 核 的 行 为 。 决 定 性 的 步 骤 在attach_recursive_mnt中进行。我们在此前接触过该函数,但介绍得比较简单。这一次,我将与共享子树的作用一同讨论。 首先,该函数需要调查,读取装载事件应该传播到哪些装载。
// fs/namespace.c
static int attach_recursive_mnt(struct vfsmount *source_mnt,
struct nameidata *nd, struct nameidata *parent_nd)
{
LIST_HEAD(tree_list);
struct vfsmount *dest_mnt = nd->mnt;
struct dentry *dest_dentry = nd->detnry;
struct vfsmount *child, *p;
if (propagate_mnt(dest_mnt, dest_dentry, source_mnt, &tree_list))
return -EINVAL;
...
propagate_mnt遍历装载目标的所有从属装载和共享装载,并分别使用mnt_set_montpoint将新文件系统装载到这些文件系统中。所有受该操作影响的装载点都在tree_list中返回。
如果目标装载点是一个共享装载,那么新的装载及其所有子装载都会变为共享的:
// fs/namespace.c
if (IS_MNT_SHARED(dest_mnt)) {
for (p = source_mnt; p; p = next_mnt(p, source_mnt))
set_mnt_shared(p);
}
...最后,内核需要调用mnt_set_mountpoint和commit_tree结束装载过程,并将修改引入到前文讨论的普通装载的数据结构中。但要注意,需要对共享装载集合的每个成员或每个从属装载分别调用commit_tree(mnt_set_mountpoint已经在propagate_mnt中对这些装载调用过)。
// fs/namespace.c
mnt_set_mountpoint(dest_mnt, dest_dentry, source_mnt);
commit_tree(source_mnt);
list_for_each_entry_safe(child, p, &tree_list, mnt_hash) {
list_del_init(&child->mnt_hash);
commit_tree(child);
}
return 0;
}(5)umount系统调用
文件系统通过umount系统调用卸载,其入口点是fs/namespace.c中的sys_umount。图8给出了相关的代码流程图。

图8 sys_umount的代码流程图
首先,__user_walk找到装载点的vfsmount实例和dentry实例,二者包装在一个nameidata结构中。 实际工作委托给do_umount。
- 如果定义了特定于超级块的umount_begin函数,则调用该函数。举例来说,这容许网络文件系统在强制卸载之前,终止与远程文件系统提供者的通信。
- 如果装载的文件系统不再需要(通过使用计数器判断),或者指定了MNT_DETACH来强制卸载文件系统,则调用umount_tree。实际工作委托给umount_tree和release_mounts。本质上,前一个函数负责将计数器d_mounted减1,而后者使用保存在mnt_mountpoint和mnt_parent中的数据,将环境恢复到所述文件系统装载之前的原始状态。被卸载文件系统的数据结构,也从内核链表中移除。
(6)自动过期
内核也提供了一些基础设施,允许装载自动过期。在任何进程或内核本身都未使用某个装载时,如果使用了自动过期机制,那么该装载将自动从vfsmount树中移除。当前NFS和AFS网络文件系统使用了该机制。所有子装载的vfsmount实例,如果被认为将自动到期,都需要使用vfsmount->mnt_ expire链表元素,将其添加到链表中。
那么接下来对链表周期性地应用mark_mounts_for_expiry即可。该函数扫描所有链表项。如果装载的使用计数为1,即它只被父装载引用,那么它处于未使用状态。在找到这样的未使用装载时,将设置mnt_expiry_mark。在mark_mounts_for_expiry下一次遍历链表时,如果发现未使用项设置了mnt_expiry_mark,那么将该装载从命名空间移除。
要注意,mntput负责清除mnt_expiry_mark。这确保以下情形:如果一个装载已经处于过期链表中,然后又再次使用,那么在接下来调用mntput将计数器减1时,不会立即过期而被移除。代码流程如下所示。
① mark_mounts_for_expiry将未使用的装载标记为到期。
② 此后,该装载再次被使用,因此其mnt_count加1。这防止了mark_mounts_for_expiry将该装载从命名空间移除,尽管此时仍然设置着过期标记。
③ 在 用 mntput 将使用计数减 1 时,该函数也会确认移除过期标记。下一周期的mark_mounts_for_expiry将照常开始工作。
(7)伪文件系统
文件系统未必需要底层块设备支持。它们可以使用内存作为后备存储器(如ramfs和tmpfs),或根本不需要后备存储器(如procfs和sysfs),其内容是从内核数据结构包含的信息生成的。虽然此类文件系统已经与传统观念有很大不同,但仍然可以更进一步。如何进行呢?所有文件系统,无论是否是虚拟的,都有一个共性,即它们在用户空间中是可见的,以文件和目录的形式出现。但该性质并非是神圣不可侵犯的。伪文件系统是不能装载的文件系统,因而不可能从用户层直接看到。
初看起来,该特性似乎不怎么有用。如果文件系统无法向用户层导出任何东西,那么它能做什么呢?虽然文件和目录的确是文件系统内容的一种可能且无疑很有用的表示,但它们不是唯一的表示。纯粹从inode的角度来考虑一个文件系统,也是完全可行的。在这种图景中,文件和目录仅仅是前端而已,忽略文件或目录不会带来任何信息损失。
当然,这牺牲了用户层的可见性,但内核实际上并不关注这一点。在一些场合,可能需要在内核内部将inode群集起来,而用户层无须了解这一点。但以文件系统的形式建立这样的集合,内核可以从中收益,因为所有的标准辅助函数都能够处理通常的文件系统,现在当然也可以处理这样的集合。
伪文件系统的例子包括:负责管理表示块设备的inode的bdev,处理管道的pipefs,处理套接字的sockfs。所有这些都出现在/proc/filesystems中,但不能装载:
root@meitner # cat /proc/filesystems
...
nodev bdev
...
nodev sockfs
nodev pipefs
...
root@meitner # mount -t bdev bdev /mnt/bdev
mount: wrong fs type, bad option, bad superblock on bdev,
missing codepage or helper program, or other error
In some cases useful info is found in syslog - try
dmesg | tail or so
内核提供了装载标志MS_NOUSER,防止此类文件系统被装载。除此之外,本章讨论的所有文件系统机制,都适用于伪文件系统。内核可以用kern_mount或kern_mount_data装载一个伪文件系统。这两个函数最后会调用vfs_kern_mount,将文件系统数据集成到VFS数据结构中。
在从用户层装载一个文件系统时,只有do_kern_mount并不够。还需要将文件和目录集成到用户可见的表示中,该工作由graft_tree处理。但如果设置了MS_NOUSER标志,则graft_tree拒绝工作:
// fs/namespace.c
static int graft_tree(struct vfsmount *mnt, struct nameidata *nd)
{
...
if (mnt->mnt_sb->s_flags & MS_NOUSER)
return -EINVAL;
...
} 尽管如此,伪文件系统的结构内容对内核都是可用的。文件系统库提供了一些方法,可以毫不费力地向伪文件系统写入数据。
4.2 文件操作
操作整个文件系统是VFS一个重要的方面,但相对而言很少发生,因为除了可移动设备之外,文件系统都是在启动过程中装载,在关机时卸载。更常见的是对文件的频繁操作,所有系统进程都需要执行此类操作。
为容许对文件的通用存取,而无需考虑所用的文件系统,VFS以各种系统调用的形式提供了用于文件处理的接口函数,如前文所述。本节重点讲解进程处理文件时执行的常见操作。
4.2.1 查找inode
一个主要操作是根据给定的文件名查找inode,这使得我们首先需要了解有关查找该信息的机制。
nameidata结构用来向查找函数传递参数,并保存查找结果。我们在上文遇到过该结构但没有定义它,我们现在看一下它的定义。
//
struct nameidata {
struct dentry *dentry;
struct vfsmount *mnt;
struct qstr last;
unsigned int flags;
...
} - 查找完成后,dentry和mnt包含了找到的文件系统项的数据。
- flags保存了标志,用于微调查找操作。在我讲述查找算法时,会返回来讲解这些标志。
- last包含了需要查找的名称。它是一个快速字符串(quick string),如前文所述,不仅包含字符串本身,还包括字符串的长度和一个散列值。
内核使用path_lookup函数查找路径或文件名。
// fs/namei.c
int fastcall path_lookup(const char *name, unsigned int flags, struct nameidata *nd) 除了所需的名称name和查找标志flags之外,该函数需要一个指向nameidata实例的指针,用作临时结果的“暂存器”。
首先,内核使用nameidata实例规定查找的起点。如果名称以/开始,则使用当前根目录的dentry和vfsmount实例(要注意,必须考虑到chroot的效应);否则,从当前进程的task_struct获得当前工作目录的数据。
link_path_walk是__link_path_walk函数的前端,后者的流程是一个不断穿过目录层次的过程。该函数大约有200行,是内核中最长的部分之一。图9给出了其代码流程图,图比实际代码简化了很多,我省去了许多次要的方面。
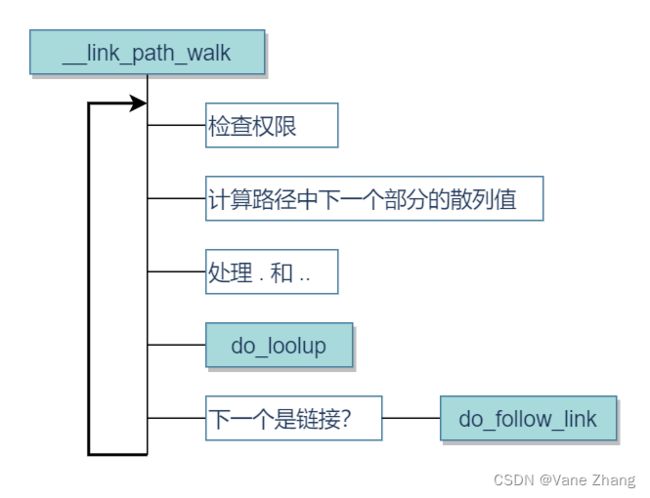
图9 __link_path_walk的代码流程图
该函数由一个大的循环组成,逐分量处理文件名或路径名。名称在循环内部分解为各个分量(各分量通过一个或多个斜线分隔)。每个分量表示一个目录名,最后一个分量例外,总是文件名。
为什么__link_path_walk的代码如此冗长?令人遗憾的是,查找与给定文件名相关的inode比初看起来复杂得多,而由于必须考虑下列因素,造成了更多的困难。
- 一个文件可能通过符号链接引用另一个文件,查找代码必须考虑到这种可能性,能够识别出链接,并在相应的处理后跳出循环。
- 必须检测装载点,而后据此重定向查找操作。
- 在通向目标文件名的路径上,必须检查所有目录的访问权限。进程必须有适当的权限,否则操作将终止,并给出错误信息。
- 格式奇怪但正确的名称,如/./usr/bin/../local/././bin//emacs,必须能够正确地解析。
我们看一下每个循环周期中执行的操作,直至指定的文件或目录名已经处理完毕,并找到匹配的inode。为此,首先将nameidata实例的mnt和dentry成员设置为根目录或工作目录对应的数据项。
- 根据所查看的inode是否定义了permission方法,来采用不同的方法判断当前进程是否允许进入该目录。如果 inode_operations实例中没有定义 permission方法,则调用 exec_permission_lite进行判断。根据进程的凭据,该函数选择文件的权限掩码中适当的部分,并检查是否设置了MAY_EXEC标志位(也会考虑进程的能力,在这里为简单起见我忽略了这一点)。如果inode定义了具体的permission方法,那么exec_permission_lit返回-EAGAIN,将此信息告知调用者。在这种情况下,使用vfs_permission判断进程是否有权限切换到指定的目录。vfs_permission仅调用permission函数,该函数依次调用inode_operations结构中保存的permission方法。
- 在内核遇到一个(或多个)斜线(/)之前,name是逐字符扫描的。斜线会跳过,因为我们只对文件名称本身感兴趣。例如,如果文件名为/home/wolfgang/test.txt,那么只有路径的3个分量home、wolfgang和test.txt是相关的,斜线应该与路径分量分离开来。每个循环中处理一个路径分量。路径分量的每个字符都传递给partial_name_hash函数,用于计算一个递增的散列和。当路径分量的所有字符都已经计算,则将该散列和转换为最后的散列值,并保存到一个qstr实例中。
- 一个点(.)作为路径分量表示当前目录,非常易于处理。内核将直接跳过查找循环的下一个周期,因为在目录层次结构中的位置没有改变。
- 两个点(..)稍微困难一点,因此该任务委托给follow_dotdot函数。当查找操作处理进程的根目录时,..是没有效果的,因为无法切换到根目录的父目录。否则,有两个可用的选项。如果当前目录不是一个装载点的根目录,则将当前dentry对象的d_parent成员用作新的目录,因为它总是表示父目录。但如果当前目录是一个已装载文件系统的根目录,保存在mnt_mountpoint和mnt_parent中的信息用于定义新的dentry和vfsmount对象。follow_mount和lookup_mnt用于取得所需的信息。
- 如果路径分量是一个普通的文件,则内核可以通过两种方法查找对应的dentry实例(以及对应的inode)。想要的信息可能位于dentry缓存中,访问它仅需要很小的延迟。该信息也有可能需要通过文件系统的底层实现进行查找,因而必须构建适当的数据结构。do_lookup负责区别这两种情况(稍后讨论),并返回所需的dentry实例。请注意,该步骤还需要检测装载点。
- 处理路径分量的最后一步是,内核判断该分量是否为符号链接。内核如何确认某个dentry实例是否代表符号链接?只有用于表示符号链接的inode,其inode_operations中才包含lookup函数。否则该字段为NULL指针。do_follow_link用作一个VFS层的前端,用于跟踪逻辑连接,将在下文讨论。
循环一直重复下去,直至到达文件名的末尾。如果内核发现文件名不再出现/,则确认已经到达文件名末尾。使用如上所述的方法,最后一个分量也可以对应到一个dentry实例,并将其返回,作为link_path_walk操作的结果。
(1)do_lookup的实现
do_lookup起始于一个路径分量,并且包含最初目录数据的nameidata实例,最终返回与之相关的inode。
内核首先试图在dentry缓存中查找inode,使用的是__d_lookup函数。即使找到匹配的数据,也并不意味着它是最新的,必须调用底层文件系统的dentry_operations中的d_revalidate函数,来检查缓存项是否仍然有效。如果有效,则将其作为缓存搜索的结果返回;否则,必须在底层文件系统中发起一个查找操作。如果在缓存中没有找到,也必须进行同样的操作。
real_lookup执行特定于文件系统的查找操作。其工作包括在内存中分配数据结构(用于保存查找结果),并调用inode_operations结构中特定于文件系统的lookup函数。
如果存在所需的目录,内核将接收到一个填充了数据的dentry实例;否则返回一个NULL指针。
do_lookup也需要处理跟踪装载点的工作。如果在缓存中找到一个有效的dentry实例,则 __follow_mount负责处理此事。内核在记录文件系统装载事件时,会将相关的 dentry实例的d_mount加1。为确保装载操作达到预期效果,内核在遍历目录结构时必须考虑到这个 事实。该工作通过调用__follow_mount完成,其实现非常简单(用作参数的path结构收集了所需的 指向装载点的vfsmount和dentry实例的指针)。
// fs/namei.c
static int __follow_mount(struct path *path)
{
int res = 0;
while (d_mountpoint(path->dentry)) {
struct vfsmount *mounted = lookup_mnt(path->mnt, path->dentry);
if (!mounted)
break;
path->mnt = mounted;
path->dentry = mounted->mnt_root;
res = 1;
}
return res;
} 该循环是如何工作的?首先检查判断当前的dentry实例是否是装载点。在这里,d_mountpoint宏只需判断d_mounted的值是否大于0。lookup_mount函数从mount_hashtable散列表获取装载的文件系统对应的vfsmount实例。该文件系统的vfsmount实例的mnt_root字段用作dentry结构的新值。所有这些都意味着,已装载文件系统的根目录用作装载点,这也是我们想要达到的目标。
while循环表明,可能有几个文件系统相继装载到前一个文件系统中,除了最后一个文件系统,所有其他文件系统都被相邻的后一个文件系统隐藏了一部分。
(2)do_follow_link的实现
在内核跟踪符号链接时,它必须要注意用户可能构造出的环状结构(有意或无意),如下例所示:
wolfgang@meitner> ls -l a b c
lrwxrwxrwx 1 wolfgang users 1 Mar 8 22:18 a -> b
lrwxrwxrwx 1 wolfgang users 1 Mar 8 22:18 b -> c
lrwxrwxrwx 1 wolfgang users 1 Mar 8 22:18 c -> a a、b和c形成了一个无限循环。如果内核不采取适当的预防措施,这可能被利用,致使系统变得不可用。
实际上,内核能够识别这种情况,并放弃处理。
wolfgang@meitner> cat a
cat: a: Too many levels of symbolic links与符号链接相关的另一个问题是,链接的目标与链接的源,可能位于不同的文件系统上。这导致了特定于文件系统的代码和VFS层函数之间的关联,通常这是不会发生的。用于跟踪链接的底层代码需要引用VFS的函数,通常都是反过来(VFS调用底层各个文件系统实现的函数)。
图10给出了do_follow_link的代码流程图。
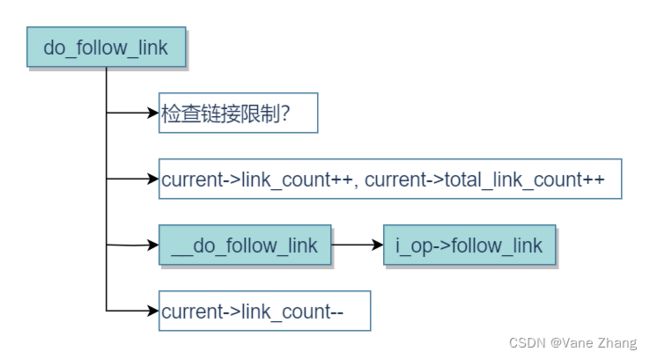
图10 do_follow_link的代码流程图
task_struct结构包含两个计数变量,用于跟踪连接。
//
struct task_struct {
...
/* 文件系统信息 */
int link_count, total_link_count;
...
}; link_count用于防止递归循环,而total_link_count限制路径名中连接的最大数目。默认情况下,内核允许MAX_NESTED_LINKS(通常设置为8)个递归和40个连续的链接,后一个常数是硬编码的,并非通过预处理器符号定义。
在do_follow_link例程的开头,内核首先检查是否超出了所述两个计数器的最大值。倘若如此,则终止do_follow_link,并返回错误码-ELOOP。
否则,将两个计数器都加1,并且调用特定于文件系统的follow_link例程跟踪当前链接。如果该链接并不指向另一个链接(因而该函数只需返回新的dentry项即可),则将link_count减1,如下述代码片段所示:
// fs/namei.c
static inline int do_follow_link(struct dentry *dentry, struct nameidata *nd)
{
...
current->link_count++;
current->total_link_count++;
err = __do_follow_link(path, nd);
current->link_count--;
...
}何时重置total_link_count的值?该计数器根本不重置,至少在查找单个路径分量期间是这样。 由于该计数器用于限制所使用链接的总数目(不见得是递归链接),在path_walk(该函数由 do_path_lookup调用)中开始查找一个全路径名或文件名时,会将该计数器重置为0。查找操作中遇 到的每个符号链接(不仅仅是递归链接)都会增加其值。
4.2.2 打开文件
在读和写文件之前,我们必须先打开文件。从应用程序的角度来看,这是通过标准库的open函数完成的,该函数返回一个文件描述符。该函数使用了同名的open系统调用,调用了fs/open.c中的sys_open函数。相关的代码流程图如图11所示。

图11 sys_open的代码流程图
第一步,force_o_largefile检查是否应该不考虑用户层传递的标志、总是强行设置O_LARGEFILE。如果底层处理器的字长不是32位(即64位系统),就会是这样。此类系统使用64位地址,大文件是唯一切合实际的默认选项。接下来打开文件的实际工作委托给do_sys_open。
在内核中,每个打开的文件由一个文件描述符表示,该描述符在特定于进程的数组中充当位置索引(数组是task_struct->files->fd_array)。该数组的元素包含了前述的file结构,其中包括每个打开文件的所有必要信息。因此,首先调用get_unused_fd_flags查找一个未使用的文件描述符。
因为系统调用的参数包括了表示文件名称的字符串,所以主要的问题是查找匹配的inode。上述刚好完成了此工作。
do_filp_open借助两个辅助函数来查找文件的inode。
① open_namei调用path_lookup函数查找inode并执行几个额外的检查(例如,确定应用程序是否试图打开目录,然后像普通文件一样处理)。如果需要创建新的文件系统项,该函数还需要应用存储在进程umask(current->fs->umask)中的权限位的默认设置。
② nameidata_to_filp初始化预读结构,将新创建的file实例放置到超级块的s_files链表上,并调用底层文件系统的file_operations结构中的open函数。
接下来,在控制权转回用户进程、返回文件描述符之前,fd_install必须将file实例放置到进程task_struct的files->fd数组中。
4.2.3 读取和写入
在文件成功打开之后,进程将使用内核提供的read或write系统调用,来读取或修改文件的数据。照例,入口例程是sys_read和sys_write,二者都在fs/read_write.c中实现。
(1)read
read函数需要3个参数:文件描述符、保存数据的缓冲区和指定读取字符数目的长度参数。这些参数直接传递到内核中。
对于VFS层,从文件读取数据并不困难,如图12所示。
根据文件描述符编号,内核(使用fs/file_table.c中的fget_light函数)能够从进程的task_struct中找到与之相关的file实例。

图12 sys_read的代码流程图
在用file_pos_read找到文件中当前读写位置之后(该例程仅需要返回file->f_pos的值),读取操作本身委托给vfs_read进行。该例程或者调用特定于文件的读取例程file->f_op->read,如果该例程不存在,则调用一般的辅助函数do_sync_read。此后,用file_pos_write记录文件内部新的读写位置。当然,该例程仍然只需要将file->f_ops设置为当前读写位置。读取数据涉及一个精致复杂的缓冲区和缓存系统,这些用于提高系统性能。
(2)write
write系统调用的结构与read同样简单。除了用f_op->write和do_sync_write替换了read中对应的例程之外,二者的代码流程图几乎完全相同。
从形式上看来,sys_write与sys_read的参数相同:一个文件描述符、一个指针变量、一个长度指示(表示为整数)。显然,其语义稍有不同。指针并非指向存储读取数据的缓冲区,而是指向需要写入文件的数据。长度参数指定了数据的字节长度。写操作同样需要通过内核的缓存系统。
参考:
《深入Linux内核架构》
《Linux内核设计与实现》
详解linux内核VFS - 嵌入式技术 - 电子发烧友网