浅谈反应式架构:基本概念介绍
个人博客导航页(点击右侧链接即可打开个人博客):大牛带你入门技术栈
淘宝从2018年开始对整体架构进行反应式升级, 取得了非常好的成绩。其中『猜你喜欢』应用上限 QPS 提升了 96%,同时机器数量缩减了一半;另一核心应用『我的淘宝』实际线上响应时间下降了 40% 以上。PayPal凭借其基于Akka构建的反应式平台squbs,仅使用8台2vCPU虚拟机,每天可以处理超过10亿笔交易,与基于Spring实现的老系统相比,代码量降低了80%,而性能却提升了10倍。能够取得如此好的成绩,人们不禁要问反应式到底是什么? 其实反应式并不是一个新鲜的概念,它的灵感来源最早可以追溯到90年代,但是直到2013年,Roland Kuhn等人发布了《反应式宣言》后才慢慢被人熟知,继而在2014年迎来爆发式增长,比较有意思的是,同时迎来爆发式增长的还有领域驱动设计(DDD),原因是2014年3月25日,Martin Fowler和James Lewis向大众介绍了微服务架构,而反应式和领域驱动是微服务架构得以落地的有力保障。紧接着各种反应式编程框架相继进入大家视野,如RxJava、Akka、Spring Reactor/WebFlux、Play Framework和未来的Dubbo3等,阿里内部在做反应式改造时也孵化了一些反应式项目,包括AliRxObjC、RxAOP和AliRxUtil等。 从目前的趋势看来,反应式概念将会逐渐深入人心, 并且将引领下一代技术变革。
本文将向大家介绍什么是反应式,以及为什么要采用反应式架构,并且通过一个编程示例,深入分析传统的编程方式会带来哪些问题和挑战,以及如何做异步化改造,顺利迈出反应式架构演进的第一步。
1 什么是反应式?
1.1 反应式介绍
为了直观地了解什么是反应式,我们先从一个大家都比较熟悉的类比开始。首先打开Excel,在B、C、D三列输入如下公式:

B、C和D三列每个单元格的值均依赖其左侧的单元格,当我们在A列依次输入1、2和3时,变化会自动传递到了B、C和D三列,并触发相应状态变更,如下图:

我们可以把A列从上到下想象成一个数据流,每一个数据到达时都会触发一个事件,该事件会被传播到右侧单元格,后者则会处理事件并改变自身的状态。这一系列流程其实就是反应式的核心思想。
通过这个例子,你应该能感受到反应式的核心是数据流(data stream), 下面我们再来看一个例子。我们很多人每天都会坐地铁上下班,地铁每两分钟一班,并且同一条轨道会被很多地铁共享,你会不会因为担心追尾,而不敢坐首尾两节车厢呢? 其实如果采用反应式架构构建地铁系统,就无需担心追尾问题。在反应式系统中,每辆地铁都会实时将自己的速度和位置等状态信息通知给上下游的其他地铁,同时也会实时的接收其他地铁的状态信息,并实时做出反馈。例如当发现下游地铁突然意外减速,则立即调整自身速度,并将减速事件通知到上游地铁,如此,整条轨道上的所有地铁形成一种回压机制(back pressure),根据上下游状态自动调整自身速度。 下面我们来看下维基百科关于反应式编程的定义:
反应式编程 (reactive programming) 是一种基于数据流 (data stream) 和 变化传递 (propagation of change) 的声明式 (declarative) 的编程范式。
从上面的定义中,我们可以看出反应式编程的核心是数据流以及变化传递。维基百科给出的定义比较通用,具有普适性,没有区分数据流的同步和异步模式, 更准确地说,异步数据流(asynchronous data stream)或者说反应式流(reactive stream)才是反应式编程的最佳实践。细心的读者会发现,讲了这么多,这不就是观察者模式(Observer Pattern)嘛! 其实这个说法并不准确,其实反应式并不是指具体的技术,而是指一些架构设计原则, 观察者模式是实现反应式的一种手段,在接下来的反应式流(Reactive Stream)一节,我们会发现反应式流基于观察者模式扩展了更多的功能,更强大也更易用。
1.2 反应式历史
早在1985年,David Harel 和 Amir Pnueli 就发表了《反应式系统的开发》论文,在论文中,他们采用二分法对复杂的计算过程进行归纳,提出了转换式(transformative)与反应式(reactive)系统。其中反应式系统就是指能够持续地与环境进行交互,并且及时地进行响应。例如视频监控系统会持续监测, 并当有陌生人闯入时立刻触发警报。
表1 反应式历史
| 时间 | 事件 |
|---|---|
| 1985 | 《反应式系统的开发》by David Harel & Amir Pnueli |
| 1997 | Functional reactive programming (FRP) by Conal Elliott |
| 2009 | Rx 1.0 for .NET by Erik Meijer’s team at Microsoft |
| 2013 | Rx for Java by Netflix |
| 2013 | 反应式宣言 V1.0 |
| 2014 | 反应式宣言 V2.0 |
| 2015 | Reactive Streams |
| Now | RxJava 3, Akka Streams, Reactor, Vert.x 3, Ratpack |
图1 谷歌搜索趋势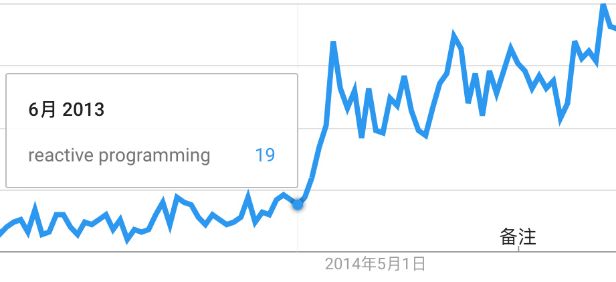
从Google搜索趋势上可以看出,从2013年6月份开始,反应式编程的搜素趋势出现了爆发式增长,原因是2013年6月反应式宣言发布了第一个版本。
1.3 ReactiveX 介绍
ReactiveX是Reactive Extensions的缩写,一般简写为Rx,最初是LINQ的一个扩展,由微软的架构师Erik Meijer领导的团队开发,在2012年11月开源。Rx是一个编程模型,目标是提供一致的编程接口,帮助开发者更方便的处理异步数据流。Rx支持几乎全部的流行编程语言,大部分语言库由ReactiveX这个组织负责维护,比较流行的有RxJava/RxJS/Rx.NET/Rx.Scala/ Rx.Swift,社区网站是http://reactivex.io/。
1.4 反应式宣言
2013年6月,Roland Kuhn等人发布了《反应式宣言》, 该宣言定义了反应式系统应该具备的一些架构设计原则。符合反应式设计原则的系统称为反应式系统。根据反应式宣言, 反应式系统需要具备即时响应性(Responsive)、回弹性(Resilient)、弹性(Elastic)和消息驱动(Message Driven)四个特质,以下内容摘自反应式宣言官网, 描述比较抽象,大家不必纠结细节,了解即可。
- 即时响应性(Responsive)。系统应该对用户的请求即时做出响应。即时响应是可用性和实用性的基石, 而更加重要的是,即时响应意味着可以快速地检测到问题并且有效地对其进行处理。
- 回弹性(Resilient)。 系统在出现失败时依然能保持即时响应性, 每个组件的恢复都被委托给了另一个外部的组件, 此外,在必要时可以通过复制来保证高可用性。 因此组件的客户端不再承担组件失败的处理。
- 弹性(Elastic)。 系统在不断变化的工作负载之下依然保持即时响应性。 反应式系统可以对输入负载的速率变化做出反应,比如通过横向地伸缩底层计算资源。 这意味着设计上不能有中央瓶颈, 使得各个组件可以进行分片或者复制, 并在它们之间进行负载均衡。
- 消息驱动(Message Driven)。反应式系统依赖异步的消息传递,从而确保了松耦合、隔离、位置透明的组件之间有着明确边界。 这一边界还提供了将失败作为消息委托出去的手段。 使用显式的消息传递,可以通过在系统中塑造并监视消息流队列, 并在必要时应用回压, 从而实现负载管理、 弹性以及流量控制。 使用位置透明的消息传递作为通信的手段, 使得跨集群或者在单个主机中使用相同的结构成分和语义来管理失败成为了可能。 非阻塞的通信使得接收者可以只在活动时才消耗资源, 从而减少系统开销。

1.5 Reactive Streams
反应式宣言仅阐述了设计原则,并没有给出具体的实现规范,导致每个反应式框架都各自实现了一套自己的API规范,且相互之间无法互通。为了解决这个问题,Reactive Streams规范应运而生。
Reactive Streams的目标是定义一组最小化的异步流处理接口,使得在不同框架之间,甚至不同语言之间实现交互性。Reactive Streams规范包含了4个接口,7个方法,43条规则以及一套用于兼容性测试的标准套件TCK(The Technology Compatibility Kit)。该规范已经成为了业界标准, 并且在Java 9中已经实现,对应的实现接口为java.util.concurrent.Flow。 有一点需要提醒的是,虽然Java 9已经实现了Reactive Streams,但这并不意味着像RxJava、Reactor、Akka Streams这些流处理框架就没有意义了,事实上恰恰相反。Reactive Streams的目的在于增强不同框架之间的交互性,提供的是一组最小功能集合,无法满足我们日常的流处理需求,例如组合、过滤、缓存、限流等功能都需要额外实现。流处理框架的目的就在于提供这些额外的功能实现,并通过Reactive Streams规范实现跨框架的交互性。
举个例子来说,MongoDB的Java驱动实现了Reactive Streams规范, 开发者使用任何一个流处理框架,仅需要几行代码即可实时监听数据库的变化。例如下面是基于Akka Stream的实现代码:
mongo
.collection("users")
.watch()
.toSource
.groupedWithin(10, 1.second)
.throttle(1, 1.second)
.runForeach { docs =>
// 处理增量数据
}
上面的几行代码实现了如下功能:
- 将接收到的流数据进行缓冲以方便批处理,满足以下任一条件便结束缓冲并向后传递
- 缓冲满10个元素
- 缓冲时间超过了1000毫秒
- 对缓冲后的元素进行流控,每秒只允许通过1个元素
1.6 小结
本章首先通过形象的例子让大家对反应式系统有一个直观的认知,然后带领大家一起回顾了反应式的发展历史,最后向大家介绍了三个反应式项目,包括ReactiveX、反应式宣言和Reactive Streams。 ReactiveX是反应式扩展,旨在为各个编程语言提供反应式编程工具。反应式宣言站在一个更高的角度,使用抽象语言向大家描述什么是反应式系统,以及实现反应式系统应该遵循的一些设计原则。Reactive Streams规范的目的在于提高各个反应式框架之间的交互性,本身并不适合作为开发框架直接使用,开发者应该选择一个成熟的反应式框架,并通过Reactive Streams规范与其它框架实现交互。
2 为什么需要反应式?
2.1 命令式编程 VS 声明式编程
实际上我们绝大多数程序员都在使用传统的命令式编程,这也是计算机的工作方式。命令式编程就是对硬件操作的抽象, 程序员需要通过指令,精确的告诉计算机干什么事情。这也是编程工作中最枯燥的地方,程序员需要耗尽脑汁,将复杂、易变的业务需求翻译成精确的计算机指令。
声明式编程是解决程序员的利器,声明式编程更关注我想要什么(What)而不是怎么去做(How)。SQL是最典型的声明式语言,我们通过SQL描述想要什么,最终由数据库引擎执行SQL语句并将结果返回给我们。
SELECT COUNT(*) FROM USER u WHERE u.age > 30
1.5节使用Akka Stream实现监听MongoDB的代码也是典型的声明式编程,如果采用命令式方式重写, 不仅费时费力,而且还会导致代码量暴增,最重要的是要通过更多的单元测试保证实现的正确性。
反应式架构推荐使用声明式编程, 使用更接近自然语言的方式描述业务逻辑, 代码清晰易懂并且富有表达力, 最重要的是大大降低了后期维护成本。
2.2 同步编程 VS 异步编程
当谈到同步与异步时,就不得不提一下阻塞与非阻塞的概念,因为这两组概念很容易混淆。导致混淆的原因是它们在描述同一个东西,但是关注点不同。 阻塞与非阻塞关注方法执行时当前线程的状态,而同步与异步则关注方法调用结果的通知机制。因为是从不同角度描述方法的调用过程,所以这两组概念也可以相互组合,即将线程状态和通知机制进行组合。例如JDK1.3及以前的BIO是同步阻塞模式,JDK1.4发布的NIO是同步非阻塞模式,JDK1.7发布的NIO.2是异步非阻塞模式。
跟命令式编程一样,同步编程也是目前被广泛采用的传统编程方式。同步编程的优点是代码简单并且容易理解,代码按照先后顺序依次执行;缺点是CPU利用率非常低,大部分时间都白白浪费在了IO等待上。
异步编程通过充分利用CPU资源并行执行任务, 在执行时间和资源利用率上远远高于同步方式。举个例子来说,对于一个10核服务器,使用同步方式抓取10个网页,每个网页耗时1秒,则总耗时为10秒;如果采用异步方式,10个抓取任务分别在各自的线程上执行,总耗时只有1秒。 构建反应式系统并非易事,尤其是针对遗留系统进行改造,这将会是一个较为漫长的过程。反应式架构的核心思想是异步非阻塞的反应式流,作为过渡阶段,我们可以选择先对系统进行完全异步化重构,为进一步向反应式架构演进奠定基础。接下来,我们将先分析一个传统的同步示例,然后针对该示例进行异步化重构。
2.3 同步编程示例
假设我们要实现一个查询手机套餐余额的方法, 该方法接受一个手机号参数,返回该手机号的套餐余额信息, 包括剩余通话时间、剩余短信数量和剩余网络流量。 由于查询套餐余额需要连续发起三次同步阻塞的数据库查询请求,所以在实现中需要利用缓存提高读取性能, 代码如下:
private PhonePlanCache cache;
public PhonePlan retrievePhonePlan(String phoneNo) {
PhonePlan plan = cache.get(phoneNo);
if (plan != null) {
return plan;
}
Long leftTalk = readLeftTalk(phoneNo);
Long leftText = readLeftText(phoneNo);
Long leftData = readLeftData(phoneNo);
return new PhonePlan(leftTalk, leftText, leftData);
}
首先我们检查是否可以直接从缓存中读取套餐余额信息,如果可以则直接返回, 否则连续发起三次同步阻塞的远程调用, 从数据库中依次读取通话余额、短信余额和流量余额。代码逻辑非常简单,但是由于同步阻塞代码对线程池依赖非常严重,接下来我们还需要根据SLA估算线程池和连接池大小。估算的过程并不容易,好在我们有利特尔法则。
1954年, John Little基于等候理论提出了利特尔法则(Little's law): 在一个稳定的系统中,系统可以同时处理的请求数量L, 等于请求到达的平均速度 λ 乘以请求的平均处理时间W, 即:
L = λ * W
这个法则同样可以用来计算线程池和连接池大小。 例如系统每秒接收1000个请求,每个请求的平均处理时间是10ms, 则合适的数据库连接池大小应该为10。 也就是说系统可以同时处理10个请求。 从长时间来看,系统平均会有10个线程在等待数据库连接上的响应。 但是需要注意的是,利特尔法则只适用于一个稳定系统, 无法处理峰值情况, 而通常系统请求数量的峰值会比平均值高很多。假设为了应付峰值情况,我们将线程池大小调整为50, 由于连接池大小仍为10,所以会导致大量线程在等待可用连接, 我们需要再次增大连接池大小以改善系统性能。通常经过如此反复调整后的参数已经严重偏离了利特尔法则, 导致系统性能严重下降,在高并发场景下,如果网络稍有抖动或数据库稍有延迟,则会导致瞬间积压大量请求, 如果没有有效的应对措施,系统将面临瘫痪风险。
2.4 同步编程面临的挑战
传统应用通常基于Servlet容器进行部署,而Servlet是基于线程的请求处理模型。从上文的讨论中我们发现,通常需要设置一个较大的线程池以获得较好的性能,较大的线程池会导致以下三个问题:
- 额外的内存开销。 在Java中,每个线程都有自己的栈空间,默认是1MB。如果设置线程池大小为200,则应用在启动时至少需要200M内存,一方面造成了内存浪费,另一方面也导致应用启动变慢。试想一下,如果同时部署1000个节点,这些问题将会被放大1000倍。
- CPU利用率低。 有两个方面原因会导致极低的CPU利用率。一方面是在Oracle JDK 1.2版本之后,所有平台的JVM实现都使用1:1线程模型(Solaris是个特例),这意味着一个Java线程会被映射到一个轻量级进程上,而有效的轻量级进程数量取决于CPU的个数以及核数。如果Java的线程数量远大于有效的轻量级进程数量,则频繁的线程上限文切换会浪费大量CPU时间; 另一方面,由于传统的远程操作或IO操作均为阻塞操作,会导致执行线程被挂起从而无法执行其他任务,大大降低了CPU的利用率。
- 资源竞争激烈。 当增大线程池后,其他的共享资源便会成为性能瓶颈,如数据库连接池资源。如果存在共享资源瓶颈,即使设置再大的线程池,也无法有效地提升性能。此时会导致多个线程竞争数据库连接, 使得数据库连接成为系统瓶颈。
除了上面这些问题,同步编程还会深刻地影响到我们的架构。
假设我们准备开发一个单点登录微服务,微服务框架使用 Dubbo 2.x,该版本尚未支持反应式编程,微服务接口之间调用仍然是同步阻塞方式。 假设我们需要实现如下两个接口:
- 用户登录接口
- 令牌验证接口
对于用户登录接口,由于需要多次访问数据库或缓存,并且需要使用Argon2等慢哈希算法进行密码校验,导致平均响应时间较长,约为500毫秒。而对于令牌验证接口,由于只需要做简单的签名校验,所以平均响应时间较短,约为5毫秒。 假设由于业务需要,用户登录接口的性能指标只需要达到1000tps即可,而令牌验证接口的性能指标则需要达到100,000tps。
通常来说,这两个接口会在同一个微服务类中实现,也通常会被发布到同一个容器中对外提供服务。为了满足业务需要,我们先来算一下需要多少硬件成本? 为了简化讨论,我们认为令牌验证接口无需硬件成本,只关注用户登录接口即可。根据利特尔法则, 总线程数量(L) = TPS(λ)*平均响应时间(W), 即:
总线程数量(L) = (1000*0.5) = 500
假设每个计算节点配置为4C8G, 那么一共需要 (500/4)=125台计算节点。 区区的1000tps竟然需要125台计算节点!你以为这就完了吗? 1000tps只是日常的请求压力,如果考虑峰值情况呢?假设峰值请求是10, 000tps,并且会持续10秒, 那么在这10秒内系统也可以看做是稳定状态, 那么根据利特尔法则,就需要部署1250台计算节点。 还有更坏的情况,如果某个节点由于数据库延迟或网络抖动等情况,导致用户登录请求积压,则用户登录请求会耗尽所有请求处理线程,导致原本可以快速响应的令牌验证请求无法被及时处理,而令牌验证接口的tps是100,000,这意味着1秒钟就会积压100,000个令牌验证请求, 系统已经处在危险边缘,随时都会崩溃。
为了解决令牌验证接口的快速响应问题,我们只能调整架构,将登陆和验证拆分成两个单独的微服务,并且各自部署到独立的容器中。这样是不是就万事大吉了呢?很不幸,单点登录迎来了一个新需求,针对员工账户需要远程调用LDAP进行认证, 而远程调用LDAP也是一个同步阻塞操作,这意味着每一个LDAP远程调用都会挂起一个线程,大量的远程调用也会耗尽所有线程,这些被挂起的线程啥都不做,就在那傻傻的等待远程响应。这其实就是微服务调用链雪崩的罪魁祸首。两个微服务之间调用已经如此棘手了,那如果调用链上有10个甚至更多的微服务调用呢? 那将是一场噩梦!
其实所有问题的根源都可以归结为传统的同步阻塞编程方式。尤其是在微服务场景下,随着调用链长度的不断增长,风险也将越来越高, 其中任何一个节点同步阻塞操作都会导致其下游所有节点线程被阻塞,如果问题节点的请求产生积压,则会导致所有下游节点线程被耗尽,这就是可怕的雪崩。
2.5 异步编程示例
我们说异步编程通常是指异步非阻塞的编程方式,即要求系统中不能有任何阻塞线程的代码。在现实情况下,想实现完全的异步非阻塞非常困难, 因为还有很多第三方的库或驱动仍然采用同步阻塞的编程方式。我们需要为这些库或驱动指定独立的线程池,以免影响到其他服务接口。
利用Java 8提供的CompletableFuture和Lambda两个特性,我们对2.2节的示例进行异步化改造,改造后代码如下:
private PhonePlanCache cache;
public CompletableFuture retrievePhonePlan(String phoneNo) {
PhonePlan cachedPlan = cache.get(phoneNo);
if (cachedPlan != null) {
return CompletableFuture.completedFuture(cachedPlan);
}
CompletableFuture leftTalkFuture = readLeftTalk(phoneNo);
CompletableFuture leftTextFuture = readLeftText(phoneNo);
CompletableFuture leftDataFuture = readLeftData(phoneNo);
CompletableFuture planFuture =
leftTalkFuture.thenCombine(leftTextFuture, (leftTalk, leftText) -> {
PhonePlan plan = new PhonePlan();
plan.setLeftTalk(leftTalk);
plan.setLeftText(leftText);
return plan;
}).thenCombine(leftDataFuture, (plan, leftData) -> {
plan.setLeftData(leftData);
return plan;
});
return planFuture;
}
我们发现虽然异步编程可以获得性能上的提升,但是编码复杂度却提升了很多,并且如果异步调用链太长,还容易导致回调地狱。
ES2017 在编程语言级别提供了async/await关键字用于简化异步编程,让开发者以同步的方式编写异步代码,例如:
const leftTalk = await readLeftTalkPromise(phoneNo);
const leftText = await readLeftTextPromise(phoneNo);
const leftData = await readLeftDataPromise(phoneNo);
const phonePlan = new PhonePlan(leftTalk, leftText, leftData);
在Scala中使用 for 语句也可以简化异步编程,例如:
for {
leftTalk <- leftTalkFuture
leftText <- leftTextFuture
leftData <- leftDataFuture
} yield new PhonePlan(leftTalk, leftText, leftData)
看到在其它语言中异步编程如此简单,是不是很羡慕? 别急, 在下一篇文章中,我们将会看到如何利用反应式编程简化异步调用问题。
3 总结
本文通过两部分内容为大家介绍了反应式的基本概念。第一部分介绍什么是反应式,包括反应式的发展历史和一些相关项目。第二部分介绍为什么要反应式,通过一个传统的编程示例向大家阐述同步编程所面临的问题和挑战,尤其在微服务场景下,面对成千上万的微服务接口以错综复杂的调用链,为了规避可能导致的雪崩风险,我们不得不对已有的架构进行无意义改造,不仅增加开发成本,而且导致部署和运维难度增加,同步编程方式已经深刻地影响到了我们的架构。但是不管怎么说,反应式改造是一个长期的过程, 在这个过程中,我们需要不断地完善基础设施,同时也要注重对开发人员的培养, 因为反应式编程是对传统方式的一次变革,编程模式和思维都需要进行转换,这对于开发人员来说同样是一次挑战。转型虽然痛苦,但是成功蜕变之后便会迎来新生。
附Java/C/C++/机器学习/算法与数据结构/前端/安卓/Python/程序员必读/书籍书单大全:
(点击右侧 即可打开个人博客内有干货):技术干货小栈
=====>>①【Java大牛带你入门到进阶之路】<<====
=====>>②【算法数据结构+acm大牛带你入门到进阶之路】<<===
=====>>③【数据库大牛带你入门到进阶之路】<<=====
=====>>④【Web前端大牛带你入门到进阶之路】<<====
=====>>⑤【机器学习和python大牛带你入门到进阶之路】<<====
=====>>⑥【架构师大牛带你入门到进阶之路】<<=====
=====>>⑦【C++大牛带你入门到进阶之路】<<====
=====>>⑧【ios大牛带你入门到进阶之路】<<====
=====>>⑨【Web安全大牛带你入门到进阶之路】<<=====
=====>>⑩【Linux和操作系统大牛带你入门到进阶之路】<<=====天下没有不劳而获的果实,望各位年轻的朋友,想学技术的朋友,在决心扎入技术道路的路上披荆斩棘,把书弄懂了,再去敲代码,把原理弄懂了,再去实践,将会带给你的人生,你的工作,你的未来一个美梦。