Spring 事务传播机制源码浅析——PROPAGATION_REQUIRED 默认传播机制
Spring 事务传播机制
事务传播是 Spring 中提出来的概念,很多人使用事务都是在方法上标注注解 @Transactional,然而当存在方法之间的调用时,如果每个方法上面都标注着 @Transactional 注解,那么你应该执行哪个注解 @Transactional 的功能呢?
所以这里就需要一个机制或者规范来解决这个问题,能够保证所有方法上面的事务能够正常执行(或者说是让事务生效),这个就是事务的传播机制。
这里还需要明白传播这个概念,比如以下示例:
@Service
public class CalculateServiceImpl implements CalculateService {
@Override
@Transactional
public void add(int a, int b) {
try {
orderService.crateOrder();
stockService.addStock();
} catch (Exception e) {
e.printStackTrace();
System.out.println("出错啦e="+e);
}
}
}
@Service
public class OrderServiceImpl implements OrderService {
@Override
public void crateOrder() {
String sql = "update `storage` set total_num= total_num+2000 where id = 1;";
int update = jdbcTemplate.update(sql);
}
}
@Service
public class StockServiceImpl implements StockService {
@Override
public void addStock() {
String sql = "update `test_user` set age= age + 2000 where id = 1;";
int update = jdbcTemplate.update(sql);
}
}
你觉得有发生事务传播嘛?答案肯定是没有的,全程就只存在一个 add() 方法的事务,crateOrder()、addStock() 方法又没有标注事务注解,所以这两个方法之间根本就不存在事务传播的说法,所以考虑的时候先看看有事务传存在没。
要怎么让上面方法间存在事务传播特性呢?可给 crateOrder() 或者 addStock() 方法加上 @Transactional 。
TransactionSynchronizationManager 工具类
该工具类可以获取到当前 Connection 对象,都能获取到了 Connection 对象,就可以通过它来判断几个开启了事务的方法是否在同一个事务中运行。
获取方法如下所示:
ConnectionHolder connectionHolder = (ConnectionHolder)TransactionSynchronizationManager.getResource(dataSource);
System.out.println("add() 方法中的 Connection==>"+connectionHolder.getConnection());
参数需要传入配置的数据源即可,还是非常方便的。
Spring 事务传播分类
这七种传播特性在源码中也有非常清晰的代码支持,其中最重要的三种是红色字体标注的。
1、死活不要事务的
- PROPAGATION_NEVER:有事务直接抛异常(刚子),一定得非事务执行
- PROPAGATION_NOT_SUPPORTED:没事务就非事务执行,有挂起,然后非事务执行
2、可有可无事务的
- PROPAGATION_SUPPORTS:有事务就用,没有就算了
3、必须需要事务的
- PROPAGATION_REQUIRED(默认):有事务加入该事务,没有就新建事务
- PROPAGATION_REQUIRES_NEW:不管有没有事务都新建一个事务,如果有事务将第一个事务挂起
- PROPAGATION_NESTED:没有事务就新建一个事务,如果有事务则在同一个事务中新建保存点作为回滚点,当内部事务回滚时不会影响外部事务的提交,但是外部事务提交会把内部事务一起回滚回去(这也是和 request_new 传播机制的区别)。
- PROPAGATION_MANDATORY:没有事务直接抛出异常,一定要有事务才可以执行
事务使用示例和源码解析
PROPAGATION_REQUIRED 事务默认传播机制
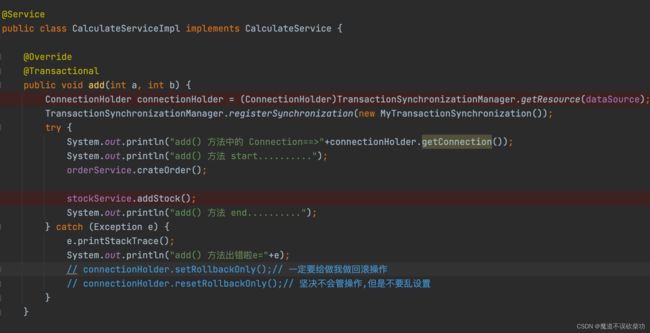
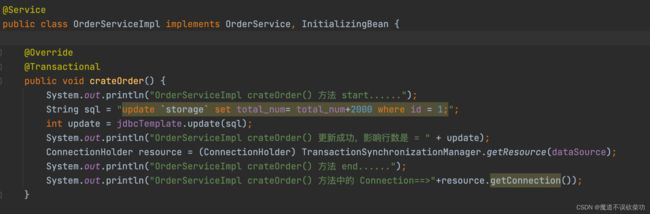

三个方法都是使用默认的传播机制,然后 add() 方法取调用 createOrder()、addStock() 接口,此时输出结果如下所示:
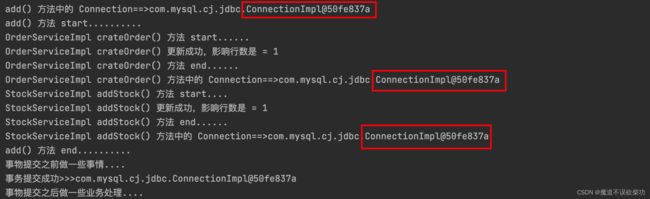
可以清楚的看到使用的是同一个事务,也是同一个事务提交,如果有一个方法出错,也会全部回滚。不会产生脏数据。
使用示例看完,接下来追溯源码,事务的增强上一篇讲事务流程已经讲过了,都在 TransactionInterceptor 类上(实质是个 Advice),源码如下:
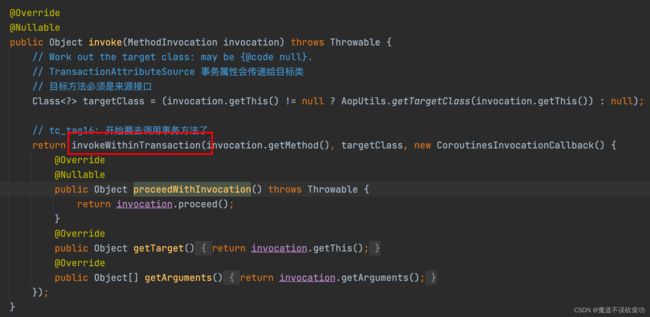
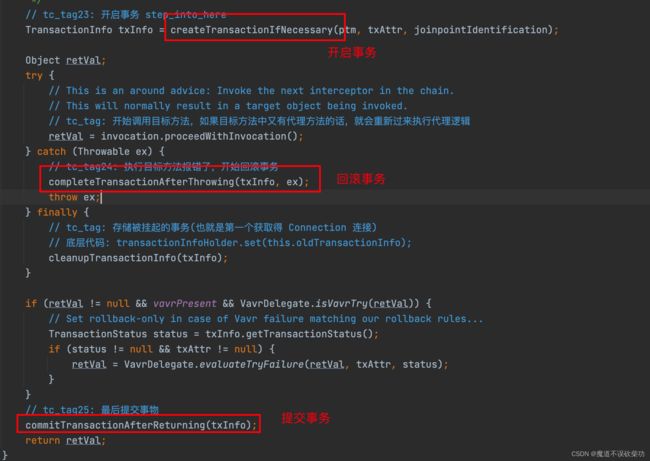
这里重点分析这三个方法:
进入 createTransactionIfNecessary() 方法,如下所示:

getTransaction() 方法非常核心,将 getTransaction() 方法分成六个核心步骤逐个分析,如下所示:

第一步骤
源码如下:
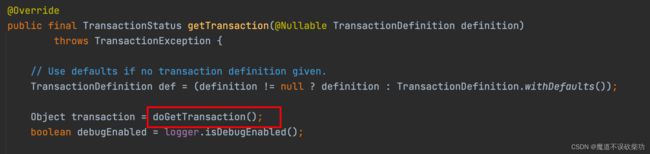

可以发现第一步骤有两行非常重要的代码,第一行代码主要是从 ThreadLocal 类型的变量中去获取值,源码如下:
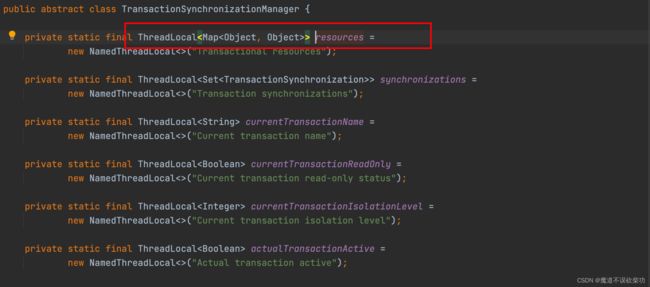
第一次也就是现在过来的 add() 方法,现在从这个 ThreadLocal 变量中取值,肯定是取不到值的,因为在 add() 方法之前就没有事务过来过,所以这里 add() 方法过来这里 get() 不到值,接着执行第二行代码,源码如下:


就是在 txObject 事务对象中保存了两个值 ConnectionHolder 与 boolean newConnectionHolder,此时这两个值ConnectionHolder = null、newConnectionHolder = false,可以理解为第一个步骤就是返回了一个 DataSourceTransactionObject 事务对象,里面保存着两个元素。
第二步骤
继续执行第二个步骤,源码如下:
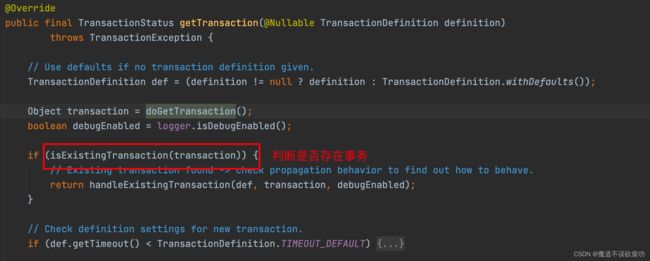


注意第一个步骤中保存的 ConnectionHolder 对象就是 null,所以条件不成立,表示前面根本不存在事务,因为现在还在准备去开启事务的路上呢。
所以第二步骤第一次过来的 add() 方法判断不成立,不执行 if 里面的逻辑,直接走 else 逻辑。源码如下:

现在 add() 方法就是使用的 PROPAGATION_REQUIRED 事务传播,所以条件成立,直接执行 startTransaction() 开启事务的方法,源码如下:
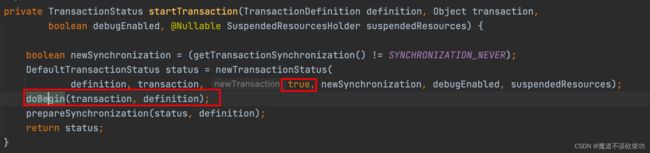
注意此时会创建一个用于事务内部状态流转的对象,DefaultTransactionStatus 对象保存当前事务是新事务还是老事务,很明显,add() 是第一个 过来开启事务的,所以这个肯定是 new 表示要新建事务,注意现在 add() 方法的堆栈上面保存的 newTransaction 状态为 true,然后继续进入到 doBegin() 方法,源码如下:
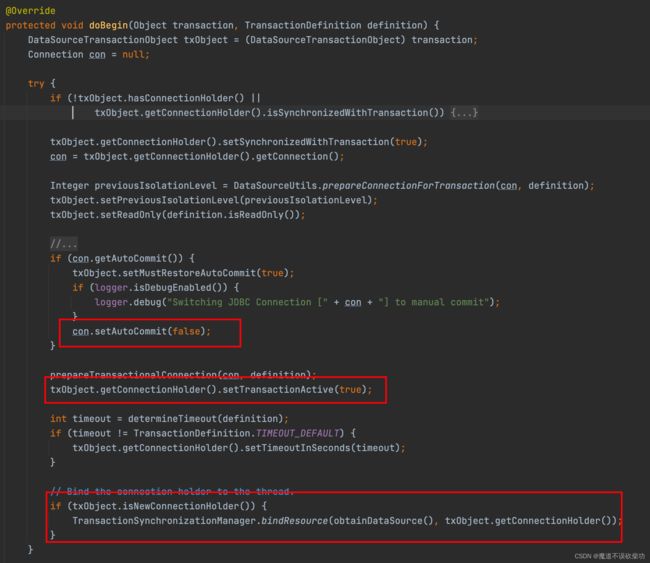
可以发现 doBegin() 方法主要干了这几件事情:
- 把事务设置成 false 手动提交
- 把 transactionActive 状态设置成 true 表示事务开启了,现在事务是运行状态的
- 还有这一步非常关键:将 ConnectionHolder(里面封装着 Connection 对象) 存放到了 ThreadLocal 变量中(建立绑定关系)
至此 add() 方法上面的 @Transactional 注解开启了第一个新事物,然后开始调用目标方法,执行 add() 方法里面具体的逻辑,源码如下:


当执行 add() 方法内部逻辑,执行 orderService.createOrder() 方法,createOrder() 方法也标注了 @Transactional 注解,所以也会去执行上面的六大步骤,所以此时 createOrder() 方法执行代理逻辑,源码如下:


此时从 ThreadLocal 变量中是可以获取到 ConnectionHolder(里面封装着 Connection 连接) 对象(因为第一次进来的 add() 把创建的事物保存到了 ThreadLocal 变量中),然后把 ConnectionHolder 保存到了 DataSourceTransactionObject 事务对象中,继续返回上一层,源码如下:


此时这个判断条件完全成立,ConnectionHolder 不为 null,并且 transactionActive 状态是 true,条件都满足,所以就会走进 if 逻辑里面的代码,源码如下:


handleExistingTransaction() 方法经过一堆的事务传播匹配,都不满足,因为我们使用的是默认的传播机制,所以直接执行到最后一行代码,注意此时传入的 newTransaction = false,因为现在事务不是新建的事物,目前使用的还是同一个 Connection 连接对象,只有当调用了 startTransaction() 方法才会创建 newTransaction = true 的新事务。
进入到 prepareTransactionStatus() 方法内部,源码如下:
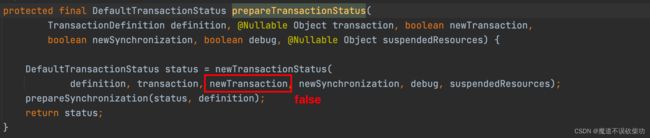
就是在 createOrder() 方法的堆栈中创建了一个 DefaultTransactionStatus 状态管理的对象。记住一点 newTransaction 状态现在是 false。
然后返回,准备去调用目标方法,执行 createOrder() 方法的业务逻辑,源码如下:

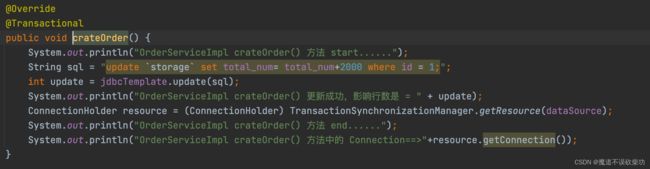
执行完 createOrder() 目标方法的业务逻辑,然后就要开始准备去执行提交操作了,但是真的能提交么?答案是不能的,往下分析源码:



从源码中可以清晰的看到,想要提交,就必须保证 newTransaction = true,否则别想提交,很可惜,此时 createOrder() 的事务设置的传播行为默认传播,因为是默认的传播,所以在前面的逻辑中会把 newTransaction 状态设置成 false,表示当前传播不需要开启新事务,因为 add() 方法已经开启了一事务,所以 createOrder() 方法直接使用 add() 方法开启的事务就可以了,这也就是 PROPAGATION_REQUIRED 传播机制的特点(存在事务就加入其中,没有事务就去开启新事务)。
所以此时 createOrder() 是提交不了的,后面的 addStock() 方法也是一样的提交不了,addStock() 方法执行完,那么表示 add() 方法的业务逻辑执行完了,此时返回调用处,源码如下:

此时 add() 业务逻辑执行完,就要准备去执行提交操作了,因为在 add() 方法的堆栈上面 newTransaction 状态是为 true 的,所以可以提交成功,提交过程的源码如下:

发现提交成功之后,还需要做一些处理,源码如下:

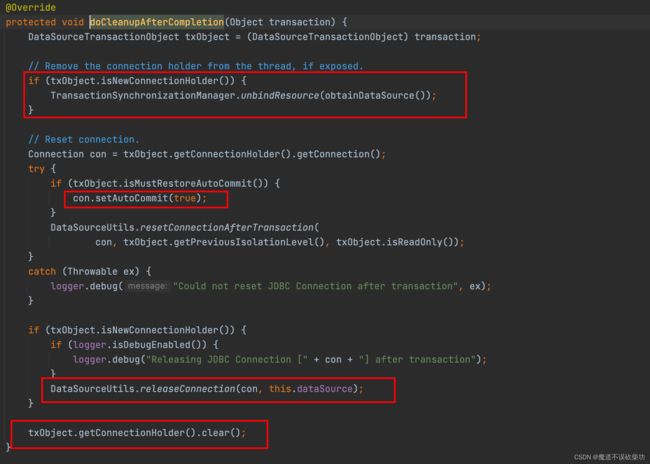
提交之后会做四件事情:
- 清空 ThreadLocal 中的 Connection 对象(或者说解绑第一次过来的 Connection 对象)
- 将 Connection 恢复成自动提交 true
- 释放 Connection 连接(或者说将 Connection 归还数据库连接池中,可以让其他人能够再用这个 Connection)
- 将事务对象中的 ConnectionHolder 设置成 null,清空 ConnectionHolder 的值
至此整个事务执行完成。
假设中间某个方法出现了异常,那就需要执行回滚操作,源码如下:

第一行主要判断是否有异常抛出,源码如下:

用抛出的异常和你在事务上配置的 rollbackFor 异常进行匹配,如果找不到,就通过父类的匹配方法匹配,父类匹配源码如下:

只要抛出的异常类型是属于 RuntimeException 或者 Error 类型就需要执行回滚操作。
如果抛出的异常不是属于 RuntimeException 异常或者 Error ,就会去执行 commit() 提交操作了,所以在回滚处理中也可能存在 commit() 操作。
现在给 createOrder() 加上一行异常抛出,代码如下:
@Service
public class OrderServiceImpl implements OrderService, InitializingBean {
@Override
@Transactional
public void crateOrder() {
System.out.println("OrderServiceImpl crateOrder() 方法 start......");
String sql = "update `storage` set total_num= total_num+2000 where id = 1;";
int update = jdbcTemplate.update(sql);
System.out.println("OrderServiceImpl crateOrder() 更新成功,影响行数是 = " + update);
ConnectionHolder resource = (ConnectionHolder) TransactionSynchronizationManager.getResource(dataSource);
System.out.println("OrderServiceImpl crateOrder() 方法 end......");
System.out.println("OrderServiceImpl crateOrder() 方法中的 Connection==>"+resource.getConnection());
int b = 0;
int a = 10/b;
}
}
因为 crateOrder() 方法抛出了异常,所以会走到回滚操作,源码如下:


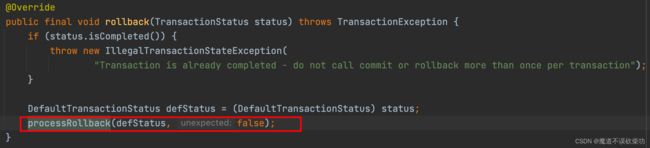
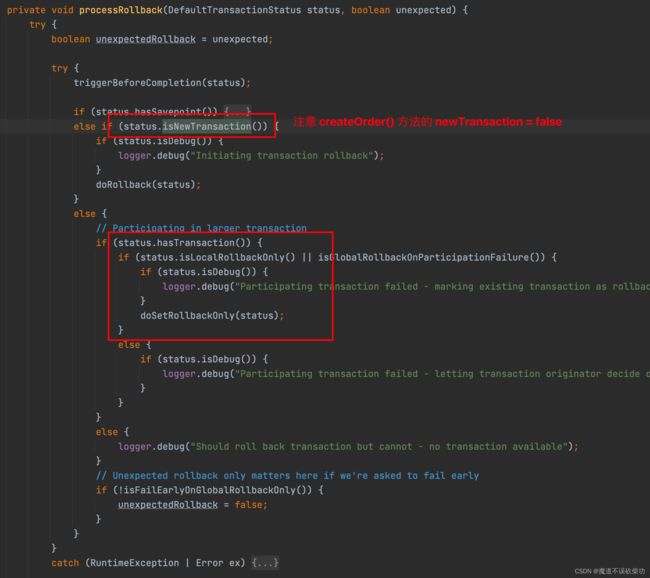
注意 createOrder() 方法的 newTransaction = false,所以不会去执行回滚操作,而是走了 else 逻辑,调用了 txObject.setRollbackOnly() 方法,源码如下:
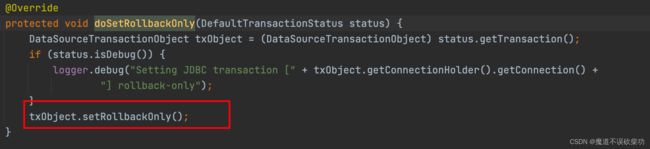

发现这里将一个 rollbackOnly 变量的状态设置成了 true,留意下这个点,然后继续返回到上层调用处:

执行完回滚方法但是并没有提交,只是将一个 rollbackOnly 变量的状态设置成了 true,然后就 throw ex 抛出异常,因为我们在 add() 方法中自己把异常吞掉了,所以 add() 方法就不会抛出异常了,代码如下:
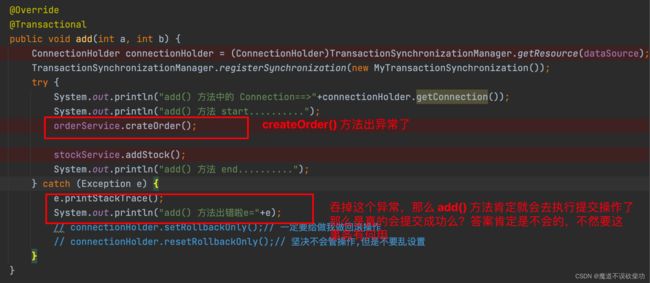
因为吞了异常,所以 add() 不会执行回滚逻辑,直接回去执行提交逻辑,源码如下:


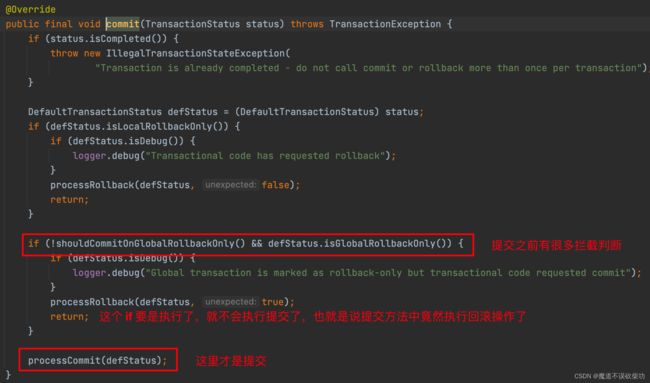
之前 createOrder() 方法抛出异常的时候,没有做回滚操作,而是将一个 rollbackOnly 变量的状态设置成了 true,在这里就用到了这个变量来做 if 判断,刚好是 true,所以走 if 逻辑,不会执行提交操作而是去执行回滚操作了,源码如下:

![]()
进入到 processRollback() 回滚方法,源码如下:

此时过来的是 add() 方法,add() 方法的堆栈上的 newTransaction 就是 true 的,因为第一次 add() 方法调用了 startTransaction() 方法,这个方法就是默认让 newTransaction 状态等于 true。所以 add() 方法在这里就能够进入真正的回滚操作了
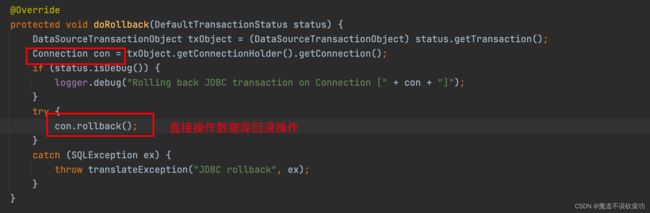
回滚完之后,和提交完之后都是要做以下四个操作的:
- 清空 ThreadLocal 中的 Connection 对象(或者说解绑第一次过来的 Connection 对象)
- 将 Connection 恢复成自动提交 true
- 释放 Connection 连接(或者说将 Connection 归还数据库连接池中,可以让其他人能够再用这个 Connection)
- 将事务对象中的 ConnectionHolder 设置成 null,清空 ConnectionHolder 的值
至此整个事务回滚也完成了。
总结一下 PROPAGATION_REQUIRED 传播机制:内部方法抛出异常没关系,就算被外部方法捕获这个异常也没关系,最终都是会被外部事务回滚的;但是如果内部方法抛出还自己给捕获了,或者说是外部方法抛出异常自己给捕获了,其实这样就相当于你自己把异常吞掉了,相当于业务逻辑没有异常了,所以最终事务提交,产生了脏数据。
篇幅过长,其他几个事务传播另开新章