大语言模型(LLM)发展历程及模型相关信息汇总(2023-07-12更新)
大语言模型(large language model,LLM)发展历程及模型相关信息汇总(2023-07-12更新)
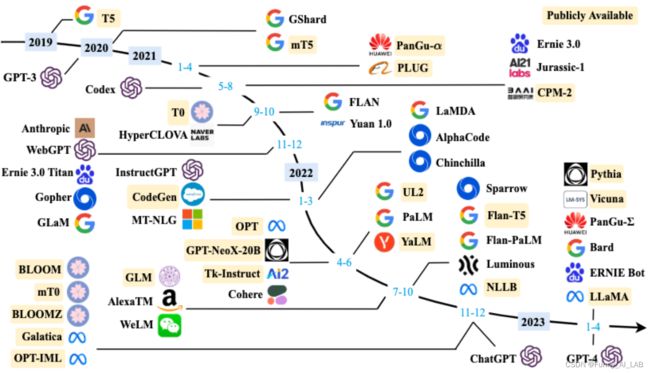
LLM发展时间轴:以下用表格形式汇总了从 BERT(2018-10-11)到 Baichuan(203-06-15)共计 58种语言大模型的相关信息:主要从 模型名称,发布时间,模型参数,发布机构,github/官网,发表论文7个维度进行统计。
| 排序 | 模型名称 | 发布时间 | 模型参数 | 发布机构 | GitHub/官网 | 论文 |
| 57 | Baichuan-7B | 2023-06-15 | 70亿 | 百川智能 | https://github.com/baichuan-inc/baichuan-7B | |
| 56 | Aquila-7B | 2023-06-10 | 70亿 | BAAI | https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila | |
| 55 | Falcon | 2023-05-24 | 400亿 | Technology Innovation Institute | https://falconllm.tii.ae/ | |
| 54 | Guanaco | 2023-05-23 | 70亿~650亿 | University of Washington | https://github.com/artidoro/qlora | QLORA: Efficient Finetuning of Quantized LLMs |
| 53 | RWKV | 2023-05-22 | 70亿 | RWKV Foundation | https://github.com/BlinkDL/RWKV-LM | RWKV: Reinventing RNNs for the Transformer Era |
| 52 | CodeT5+ | 2023-05-13 | 160亿 | Salesforce | https://github.com/salesforce/CodeT5 | CodeT5+: Open Code Large Language Models for Code Understanding and Generation |
| 51 | PaLM2 | 2023-05-10 | 10亿~100亿 | https://ai.google/static/documents/palm2techreport.pdf | PaLM 2 Technical Report | |
| 50 | RedPajamaINCITE | 2023-05-05 | 28亿 | TOGETHER | https://huggingface.co/togethercomputer/RedPajama-INCITE-Instruct-3B-v1 | Releasing 3B and 7B RedPajama-INCITE family of models including base, instruction-tuned & chat models |
| 49 | MPT | 2023-05-05 | 70亿 | MosaicML | https://github.com/mosaicml/llm-foundry | Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs |
| 48 | StarCoder | 2023-05-05 | 70亿 | Hugging Face | https://github.com/bigcode-project/starcoder/ | Star Coder: May the Source be With You! |
| 47 | OpenLLaMa | 2023-05-03 | 70亿 | Berkeley Artificial Intelligence Research | https://github.com/openlm-research/open_llama | OpenLLaMA: An Open Reproduction of LLaMA |
| 46 | StableLM | 2023-04-20 | 30亿&70亿 | Stability AI | https://stability.ai/blog/stability-ai-launches-the-first-of-its-stablelm-suite-of-language-models | Stability AI Launches the First of its StableLM Suite of Language Models |
| 44 | Koala | 2023-04-03 | 130亿 | Berkeley Artificial Intelligence Research | https://github.com/young-geng/EasyLM | Koala: A Dialogue Model for Academic Research |
| 43 | Vicuna-13B | 2023-03-31 | 130亿 | LM-SYS | https://github.com/lm-sys/FastChat | Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality |
| 42 | BloombergGPT | 2023-03-30 | 500亿 | Bloomberg | https://www.bloomberg.com/company/press/bloomberggpt-50-billion-parameter-llm-tuned-finance/ | BloombergGPT: A Large Language Model for Finance |
| 41 | GPT4All | 2023-03-29 | 70亿 | Nomic AI | https://github.com/nomic-ai/gpt4all | GPT4All: Training an Assistant-style Chatbot with Large Scale Data Distillation from GPT-3.5-Turbo |
| 40 | Dolly | 2023-03-24 | 60亿 | Databricks | https://huggingface.co/databricks/dolly-v1-6b | Hello Dolly: Democratizing the magic of ChatGPT with open models |
| 39 | ChatGLM-6B | 2023-03-14 | 62亿 | 清华大学 | https://github.com/THUDM/ChatGLM-6B | ChatGLM-6B: An Open Bilingual Dialogue Language Model |
| 38 | GPT-4 | 2023-03-14 | 未知 | OpenAI | https://cdn.openai.com/papers/gpt-4.pdf | GPT-4 Technical Report |
| 37 | StanfordAlpaca | 2023-03-13 | 70亿 | Stanford | https://github.com/tatsu-lab/stanford_alpaca | Alpaca: A Strong, Replicable Instruction-Following Model |
| 36 | LLaMA | 2023-02-24 | 70亿~650亿 | Meta | https://github.com/facebookresearch/llama | LLaMA: Open and Efficient Foundation Language Models |
| 35 | GPT-3.5 | 2022-11-30 | 1750亿 | OpenAI | https://platform.openai.com/docs/models/overview | GPT-3.5 Model |
| 34 | BLOOM | 2022-11-09 | 1760亿 | BigScience | https://huggingface.co/bigscience/bloom | BLOOM: A 176B-Parameter Open-Access Multilingual Language Model |
| 33 | BLOOMZ | 2022-11-03 | 1760亿 | BigScience | https://github.com/bigscience-workshop/xmtf | Crosslingual Generalization through Multitask Finetuning |
| 32 | mT0 | 2022-11-03 | 130亿 | BigScience | https://github.com/bigscience-workshop/xmtf | Crosslingual Generalization through Multitask Finetuning |
| 31 | Flan-U-PaLM | 2022-10-20 | 5400亿 | https://github.com/google-research/t5x/blob/main/docs/models.md | Scaling Instruction-Finetuned Language Models | |
| 30 | Flan-T5 | 2022-10-20 | 110亿 | https://github.com/google-research/t5x/blob/main/docs/models.md | Scaling Instruction-Finetuned Language Models | |
| 29 | WeLM | 2022-09-21 | 100亿 | 微信 | https://welm.weixin.qq.com/docs/api/ | WeLM: A Well-Read Pre-trained Language Model for Chinese |
| 28 | PLUG | 2022-09-01 | 270亿 | 阿里达摩院 | https://github.com/alibaba/AliceMind/tree/main/PLUG | PLUG: Pre-training for Language Understanding and Generation |
| 27 | OPT | 2022-05-02 | 1750亿 | Meta | https://github.com/facebookresearch/metaseq/tree/main/projects/OPT | OPT: Open Pre-trained Transformer Language Models |
| 26 | PaLM | 2022-04-05 | 5400亿 | https://github.com/lucidrains/PaLM-pytorch | PaLM: Scaling Language Modeling with Pathways | |
| 25 | Chinchilla | 2022-03-29 | 700亿 | Google DeepMind | https://www.deepmind.com/blog/an-empirical-analysis-of-compute-optimal-large-language-model-training | Training Compute-Optimal Large Language Models |
| 24 | CodeGen | 2022-03-25 | 160亿 | Salesforce | https://github.com/salesforce/codegen | CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis |
| 23 | GLM-130B | 2022-03-17 | 1300亿 | 清华大学 | https://github.com/THUDM/GLM-130B | GLM: General Language Model Pretraining with Autoregressive Blank Infilling |
| 22 | InstructGPT | 2022-03-04 | 1750亿 | OpenAI | https://github.com/openai/following-instructions-human-feedback | Training Language Models to Follow Instructions with Human Feedback |
| 21 | AlphaCode | 2022-02-08 | 410亿 | Google DeepMind | https://www.deepmind.com/blog/competitive-programming-with-alphacode | Competition-Level Code Generation with AlphaCode |
| 20 | MT-NLG | 2022-01-28 | 5300亿 | Microsoft | https://github.com/microsoft/DeepSpeed | Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model |
| 19 | LaMDA | 2022-01-20 | 1370亿 | https://github.com/conceptofmind/LaMDA-rlhf-pytorch | LaMDA: Language Models for Dialog Applications | |
| 18 | WebGPT | 2021-12-17 | 1750亿 | OpenAI | https://openai.com/research/webgpt | WebGPT: Browser-assisted question-answering with human feedback |
| 17 | GLaM | 2021-12-13 | 12000亿 | https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html | GLaM: Efficient Scaling of Language Models with Mixture-of-Experts | |
| 16 | Gopher | 2021-12-08 | 2800亿 | Google DeepMind | https://www.deepmind.com/blog/language-modelling-at-scale-gopher-ethical-considerations-and-retrieval | Scaling Language Models: Methods, Analysis & Insights from Training Gopher |
| 15 | T0 | 2021-10-15 | 110亿 | Hugging Face | https://github.com/bigscience-workshop/t-zero | Multitask Prompted Training Enables Zero-Shot Task Generalization |
| 14 | FLAN | 2021-09-03 | 1370亿 | https://github.com/google-research/FLAN | Finetuned Language Models Are Zero-Shot Learners | |
| 13 | Codex | 2021-07-07 | 120亿 | OpenAI | https://github.com/openai/human-eval | Evaluating large language models trained on code |
| 12 | ERNIE3.0 | 2021-07-05 | 100亿 | 百度 | https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-3.0 | ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation |
| 11 | PanGu-Alpha | 2021-04-26 | 2000亿 | 华为 | https://openi.pcl.ac.cn/PCL-Platform.Intelligence/PanGu-Alpha | PanGu-α: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation |
| 10 | SwitchTransformer | 2021-01-11 | 16000亿 | https://huggingface.co/google/switch-large-128 | Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity | |
| 9 | mT5 | 2020-10-22 | 130亿 | https://huggingface.co/google/mt5-base | mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer | |
| 8 | GShard | 2020-06-30 | 6000亿 | https://arxiv.org/pdf/2006.16668.pdf | GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding | |
| 7 | GPT-3 | 2020-05-28 | 1750亿 | OpenAI | https://github.com/openai/gpt-3 | Language Models are Few-Shot Learners |
| 6 | Turing-NLG | 2020-02-13 | 170亿 | Microsoft | https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/ | Turing-NLG: A 17-billion-parameter language model by Microsoft |
| 5 | T5 | 2019-10-23 | 110亿 | https://github.com/google-research/t5x | Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer | |
| 4 | XLNet | 2019-06-19 | 3.4亿 | Google Brain | https://github.com/zihangdai/xlnet | XLNet: Generalized Autoregressive Pretraining for Language Understanding |
| 3 | Baidu-ERNIE | 2019-04-19 | 3.4亿 | 百度 | https://github.com/PaddlePaddle/ERNIE | ERNIE: Enhanced Representation through Knowledge Integration |
| 2 | GPT-2 | 2019-02-14 | 15亿 | OpenAI | https://github.com/openai/gpt-2 | Language Models are Unsupervised Multitask Learners |
| 1 | BERT | 2018-10-11 | 3.4亿 | https://github.com/google-research/bert | Bidirectional Encoder Representations from Transformers | |
| 0 | GPT-1 | 2018-06-11 | 1.17 亿 | OpenAI | https://github.com/openai/finetune-transformer-lm | Improving Language Understanding by Generative Pre-Training |
其中具有代表性的节点作品:
-结合对齐和翻译的神经网络机器翻译模型
论文题目:Neural Machine Translation by Jointly Learning to Align and Translate (2014)
论文解读:论文笔记《Neural Machine Translation by Jointly Learning to Align and Translate》
这篇文章引入了一种注意力机制(attention mechanism),用于提升递归神经网络(RNN)的长序列建模能力。这使得 RNN 能够更准确地翻译更长的句子——这也是后来开发出原始 Transformer 模型的动机。
Transformer:注意力机制
论文题目:Attention Is All You Need (2017)
论文解读:详解Transformer (Attention Is All You Need)
这篇论文介绍了原始 Transformer 模型的结构。该模型由编码器和解码器两部分组成,这两个部分在后续模型中分离成两个独立的模块。此外,该论文还引入了缩放点积注意力机制(Scaled Dot Product Attention Mechanism)、多头注意力机制(Multi-head Attention Blocks)和位置编码(Positional Input Encoding)等概念,这些概念仍然是现代 Transformer 系列模型的基础。
BERT: 语言理解的深度双向 Transformer 预训练
论文题目:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018)
论文解读:[详解] 一文读懂 BERT 模型
在原始的 Transformer 模型之后,大语言模型研究开始向两个方向分化:基于编码器结构的 Transformer 模型用于预测建模任务,例如文本分类;而基于解码器结构的 Transformer 模型用于生成建模任务,例如翻译、摘要和其他形式的文本内容生成。
GPT1:通过生成预训练改进语言理解
论文题目:Improving Language Understanding by Generative Pre-Training (2018)
论文解读:ChatGPT1论文解读《Improving Language Understanding by Generative Pre-Training》(2018)
在预训练阶段增加Transformer中间层可以显著提升效果;整个模型在12个数据集中的9个取得了更好的效果,说明该模型架构设计很不错,值得继续深入研究;辅助目标学习对于数据量越大的场景,可以越提升模型 的泛化能力。
GPT2:
论文题目:Language Models are Unsupervised Multitask Learners(2019)
GPT-2模型依旧使用Transformer模型的decoder,但相比于GPT-1,数据和模型参数变得更大,大约是之前的10倍,主打zero-shot任务。
GPT3:
论文题目:Language Models are Few-Shot Learners(2020)
论文解读:GPT-3阅读笔记:Language Models are Few-Shot Learners
GPT-3不再追求极致的zero-shot学习,即不给你任何样例去学习,而是利用少量样本去学习。因为人类也不是不看任何样例学习的,而是通过少量样例就能有效地举一反三。
由于GPT-3庞大的体量,在下游任务进行fine-tune的成本会很大。因此GPT-3作用到下游子任务时,不进行任何的梯度更新或fine-tune。
GPT4:生成式预训练变换模型
论文题目:GPT-4 Technical Report(2023)
论文解读:GPT-4大模型硬核解读,看完成半个专家
—论文解读:GPT系列论文阅读笔记
整理数据来源于网上公开资源,如有不对之处请指正,谢谢。
参考:
1.关于 ChatGPT 必看的 10 篇论文
2.理解大语言模型–10篇论文的简明清单
3.GPT-4论文精读【论文精读·53】
4 .通向AGI之路:大型语言模型(LLM)技术精要
5.万字长文:LLM - 大语言模型发展简史