《数据结构( C++)》:第一章、数据结构概论
第一章、数据结构概论
- 0.简单介绍
- 1.数据结构的概念
-
- 1.1 数据与数据结构
- 1.2 数据结构的分类及其描述
-
- (1)**线性结构(linear structure)**
- (2)**非线性结构(nonlinear structure)**
- (3)用集合和关系形式化描述数据结构
- 1.3 数据结构的存储(物理)结构
-
- (1)**顺序存储方法(sequential storage)**
- (2)**链接存储方法(linked storage)**
- (3)**索引存储方法(indexed storage)**
- (4)**散列存储方法(hashing storage)**
- 1.4 数据类型与抽象数据类型(ADT)
-
- (1)数据类型
- (2)抽象数据类型的定义及描述
- (3)数据类型的实现
- 1.6 练习题
-
- 一、选择题
- 二、简答题
- 三、应用题
- 四、填空题
- 五、判断题
- 2.算法的基本概念
-
- 2.1 计算与算法
- 2.2 算法的特性(5个)
- 2.3 算法的设计
- 2.4 算法的描述
- 2.5 练习题
-
- 一、选择题
- 二、简答题
- 三、判断题
- 3.算法的性能分析
-
- 3.1 算法的评价标准
-
- (1)**正确性(correctness)**
- (2)**可读性(readability)**
- (3)**健壮性(robustness)**
- (4)**效率( efficiency)**
- (5)**简单性( simplicity)**
- (6)**可使用性(usability)**
- 3.2 算法性能的分析方法
-
- (1)经验测试:即做实验。
- (2)先验估计:
- (3)经验测试与先验估计对比
- 3.3 算法的空间性能分析—空间复杂度
-
- (1)算法的空间性能的影响因素
- (2)度量方法:
- (3)常用的空间复杂度:
- 3.4 算法的时间性能分析—==时间复杂度==(重点)
-
- (1)算法的时间性能的影响因素:
- (2)算法的时间性能度量:
- (3)渐近复杂性分析:
- (4)渐近时间复杂性的数学符号:
- (5)大 O O O表示法中使用的典型函数:
- (6)算法分析的一般步骤:
- (7)**一般算法**的时间复杂性分析:
- (8)**递归算法**的时间复杂性分析:
- 3.5 练习题
-
- 一、选择题
- 二、应用题
-
-
- 四、填空题
-
- 五、算法分析与设计
0.简单介绍
教材:数据结构(用面向对象方法与 C++语言描述)(第 2 版).殷人昆主编. 北京:清华大学出版社.2007.6
本章课本对应:P1-P42页
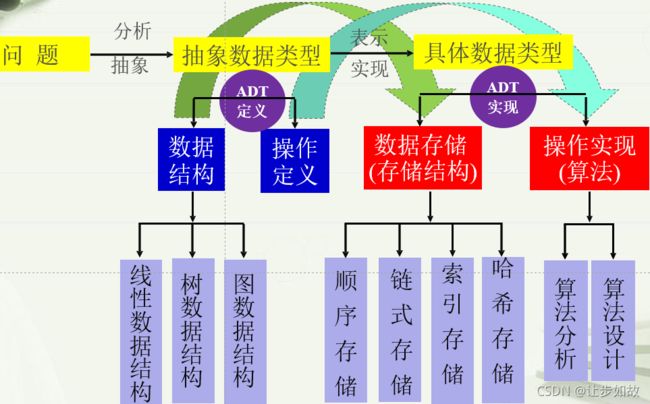
1.数据结构的概念
数据结构+算法=程序
1.1 数据与数据结构
数据(data) 是信息的载体,是描述客观事物的数、字符,以及所有能输入到计算机中并被计算机程序识别和处理的符号的集合。
数据的基本单位是数据元素( data element)。一个数据元素可由若干个**数据项(data item)**组成,它是一个数据整体中相对独立的单位。
在数据元素中的数据项可以分为两种,一种叫做初等项,如学生的性别、籍贯等,这些数据项是在数据处理时不能再分割的最小单位 ;另一种叫做组合项,如学生的成绩,它可以再划分为物理、化学等更小的项。通常,在解决实际应用问题时把每个学生记录当作一个基本单位进行访问和处理。
结构(structure) 是指数据元素之间的关系(relation)。
数据结构(data structure) 由某一数据元素的集合和该集合中数据元素之间的关系组成,即带结构的数据元素的集合。
记为:Data_Structure={D,R}
其中,Data_Structure是数据结构的名称、D是某一数据元素的有限集合(一般为一个数据对象)、R是D上关系的有限集。
注:这里说的数据元素之间的关系是指元素之间本身固有的逻辑关系,与计算机无关。
1.2 数据结构的分类及其描述
依据数据元素之间关系的不同,数据结构分为两大类:线性结构和非线性结构。
(1)线性结构(linear structure)
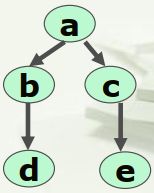
线性结构也称为线性表,在这种结构中所有数据元素都按某种次序排列在一个序列中,如图1.5所示。

线性关系:对于每一数据元素,除第一个元素外,其他每一个元素都有一个且仅有一个直接前驱,第一个数据元素没有前驱;除最后一个元素外,其他每一个元素都有一个且仅有一个直接后继,最后一个元素没有后继。
(2)非线性结构(nonlinear structure)
在非线性结构中各个数据元素不再保持在一个线性序列中,每个数据元素可能与零个或多个其他数据元素发生联系。根据关系的不同,可分为层次结构和群结构。
层次结构(hierarchical structure) 是按层次划分的数据元素的集合,指定层次上元素可以有零个或多个处于下一个层次上的直接所属下层元素。树形结构就是典型的层次结构。
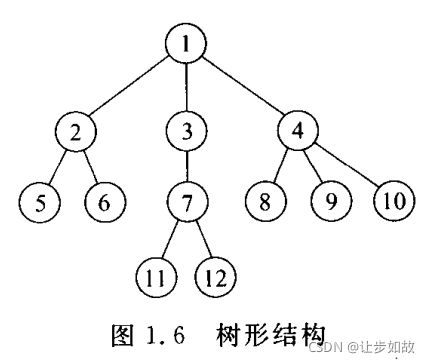
群结构(group structure) 中所有元素之间无顺序关系。图结构就是一种群结构。它是由图的顶点集合和连接顶点的边集合组成。

集合是一种数学模型,但由于不关心数据之间的关系(即关系为空),也就无法在处理数据时利用上关系。因此不属于数据结构。
(3)用集合和关系形式化描述数据结构
根据数据结构的定义,任何一个数据结构都可以利用集合和关系形式化描述出来。
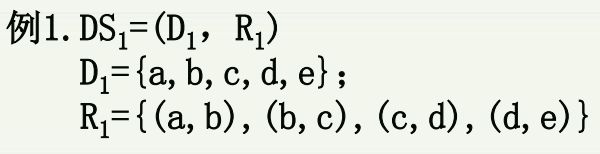
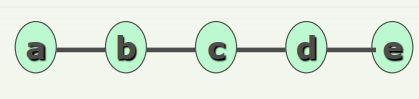
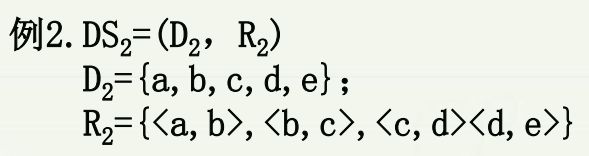


1.3 数据结构的存储(物理)结构
数据结构的存储(物理)结构:数据结构在计算机中的表示(映象),即数据结构在计算机中的组织形式,是指逻辑结构的存储镜像(image)。
我们研究数据结构的目的是要利用数据之间的关系(结构),因此,在存储时既要存储元素本身,还要存储(表示)关系!
数据结构DS的物理结构Р对应于从DS的数据元素到存储区M(维护着逻辑结构S)的一个映射:
P : ( D , S ) — > M P:(D,S)—>M P:(D,S)—>M
P的四种基本映射模型:顺序(Sequential)、链接(Linked)、索引(Indexed)、散列(Hashing)。
数据结构的存储结构可以用以下4种基本的存储方法得到:
(1)顺序存储方法(sequential storage)
占用连续地址空间,数据元素依次存放。用物理上的相邻映射出逻辑上的关系(结构)。
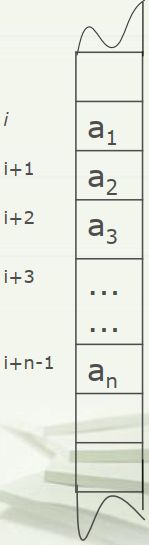
优点:占用空间少(没有“显式”存储关系);空间连续。
缺点:表示关系的能力弱;不便于修改, 插入和删除某个结点需要修改一系列的结点。
通常,顺序存储结构可借助程序语言中的一维数组来描述。
(2)链接存储方法(linked storage)
占用空间任意,元素任意存放。在存放元素的同时,还存放与其有关系的元素的地址(指针),即通过指针映射出逻辑上的关系。
一个存储结点:
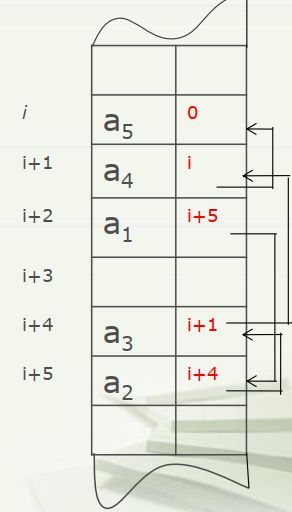

优点:便于修改, 修改时只需要修改结点的指针字段, 不需要移动其他结点。
缺点:占用存储空间, 因为需要存储结点之间的逻辑关系。 因为结点之间不一定相邻, 因此不能对结点进行随机访问。
通常,链式存储结构要借助程序语言中的指针类型来描述。
(3)索引存储方法(indexed storage)
该方法在存储元素信息的同时,还建立附加的索引表。索引表中每一项称为索引项,索引项的一般形式是:(关键码,地址)。关键码是能够唯一标识一个结点(即元素)的那些数据项。
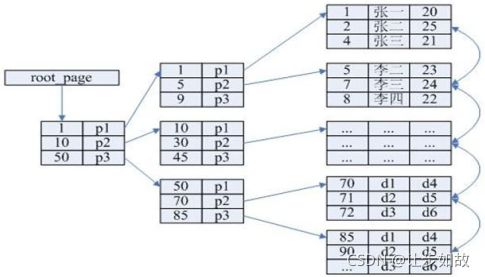
若每个结点在索引表中都有一个索引项,则该索引表称为稠密索引(dense index);若一组相邻的结点在索引表中只有一个索引项,则该索引表称为稀疏索引(sparse index)。稠密索引中索引项中的地址指示结点所在的物理位置,稀疏索引中索引项中的地址指示一组相邻结点的起始存储位置。

优点:可以快速查找, 可以随机访问, 方便修改。
缺点:建立索引表增加了时间和空间的开销。
(4)散列存储方法(hashing storage)
该方法的处理方式是根据结点的关键码通过一个函数(地址映射函数)计算直接得到该结点的存储地址。
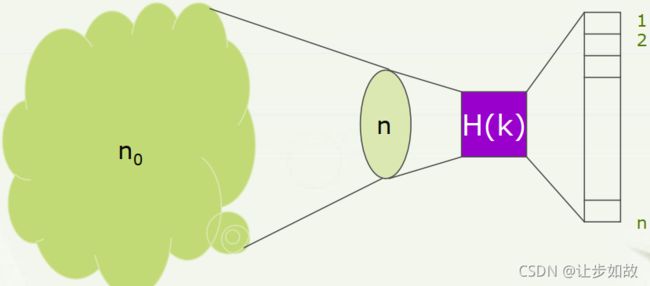
优点:查找速度快, 适用于快速查找和插入的场景。
缺点:只存结点数据, 不存结点之间的关系。
- 同一逻辑结构采用不同的关系映射方式,可以得到不同的存储结构。
- 选择何种存储结构来存储相应的逻辑结构,具体问题具体分析,主要考虑运算方便及算法的时间和空间要求。
- 研究数据结构的目的是为了更好地加工和处理。要处理必须先存储起来,所以必须讨论存储结构,但存储起来还不是最终目的,还要对存储的数据结构实施一些操作(或运算),因此数据结构和操作是分不开的。
- 数据结构主要有三个方面的内容:数据的逻辑结构、数据的(物理)存储结构、对数据的操作(操作具体设计为算法)。
1.4 数据类型与抽象数据类型(ADT)
(1)数据类型
**数据类型(data type)**一个数据值的集合和定义在这个值集上的一组操作的总称。
- 高级语言中的数据类型实际上包括:数据的逻辑结构、数据的存储结构及所定义的操作的实现。
- 高级语言中的数据类型按值的不同特性分为:原子类型(如整型、实型、字符型、布尔型);结构类型(如数组、结构体等)。
- 数据类型并不局限于高级语言,它实际上是一个广义的概念。例如:“教师”就是一个数据类型,它有值“教龄”,有操做“教书”等;如果具体说小学教师、大学教师,可以看作是一个具体的类型(好像有了存储结构);
- 撇开计算机,现实中的任何一个问题都可以定义为一个数据类型—称为抽象数据类型。
(2)抽象数据类型的定义及描述
**抽象数据类型(abstract data type,ADT)**一个数学模型及定义在这个模型上的==一组操作(或运算)==的总称。
一个ADT可以用三元组表示:(D,S,P)
其中:D是数据对象、S是D上的关系集、P是对D的基本操作集。

ADT特点:
①封装与隐藏:将数据和操作封装在一起,内部结构和实现细节对外屏蔽,实现信息隐藏。
②抽象:用户只能通过ADT里定义的接口和说明来访问和操作数据。
(3)数据类型的实现
一个数据类型的实现一般分为三个阶段:
- ADT阶段,又称为定义阶段;
- 虚拟数据类型阶段,又称为表示阶段;
- 物理数据类型阶段,又称物理实现阶段。
那么,高级语言中的数据类型是哪个阶段?你过去编程解决问题是哪个阶段?
ADT定义:数据结构、操作 (抽象)、数据:逻辑形式。
ADT实现:物理结构、算法 (具体)、数据:物理形式。
1.6 练习题
一、选择题
1.可以用( )定义一个完整的数据结构。
A,数据元素 B.数据对象 C.数据关系 D.抽象数据类型
2.(2015.1)在数据结构的讨论中把数据结构从逻辑上分为( )两大类。
A.动态结构、静态结构 B.内部结构、外部结构 C.线性结构、非线性结构 D.紧凑结构、非紧凑结构
3.下述( )与数据的存储结构无关。
A.栈 B.双向链表 C.散列(哈希)表 D.线索树 E.循环队列
4.以下数据结构中,( )是非线性数据结构。
A.树 B.队列 C.栈 D.字符串
5.以下属于逻辑结构的是( )。
A.顺序表 B.散列(哈希)表 C.有序表 D.单链表
6.以下关于数据结构的说法中,正确的是( )。
A.数据的逻辑结构独立于其存储结构 B.数据的存储结构独立于其逻辑结构
C.数裾的逻辑结构唯一决定其存储结构 D.数据结构仅由其逻辑结构和存储结构决定
7.(2015.16)数据结构的定义为(D,S),其中D是( )的集合。
A 算法 B数据元素 C 数据操作 D 逻辑结构
8.顺序存储结构要求必须是地址连续的存储空间。假设有 n 个学生数据元素,每个学生包括学号、姓名、成绩等数据项。
下面能正确获取顺序存储空间的是( )。
struct node{
int St_No;
char St_Name[10];
float St_Score;
};
A、
int n;
struct node *St;
cin>>n;
St=(struct node *)malloc(sizeof(struct node));
B、
int n;
struct node *St;
cin>>n;
St=(struct node *)malloc(n);
C、
int n;
struct node *St;
cin>>n;
St=(struct node *)malloc(sizeof(struct node)*n);
D、
int n;
struct node *St;
cin>>n;
St = malloc(sizeof(struct node)*n);
9.关于数据结构,下面不正确的描述是( )。
A 数据结构本身与计算机无关
B 求解简单问题,可以不用考虑数据结构
C 数据结构在计算机诞生之初就已经产生了
D 随着计算机应用的深入,解决的问题越来越复杂。一方面发展硬件技术,另一方面通过研究分析问题的数据及特点,并利用其特性提高问题求解的效率,这就产生了数据结构
10.关于数据结构,正确的描述是( )。
A 数据及其存储方式
B 数据结构就是存储结构
C 数据及数据之间的逻辑关系
D 数据之间的逻辑关系
11.存储密度是评价数据结构存储方案的一个指标。它定义为: 存储数据元素占用空间/分配给数据结构的总存储空间。下面不正确的是( )。
A 一般来说,存储密度越大,对数据的操作就越困难;反之存储密度越小,对数据的操作就越容易。
B 顺序存储方式比链式存储方式存储密度小
C 顺序存储方式比链式存储方式存储密度大
D 存储密度反映了存储空间的利用率
12.关于数据结构和存储结构的关系,错误的描述是( )。
A 各种存储结构存储数据元素本身占用的存储空间大小是一样的,但是存储(表示)关系占用的空间不同。
B 数据结构就是存储结构,存储结构就是数据结构
C 一种数据结构可以有多种不同的存储结构
D 一种存储结构可以存储不同的数据结构
13.数据结构按其结构关系区分有三种,不包括( )。
A.树 B.线性表 C.图 D.集合
14.数据结构采用顺序存储结构时,存储单元的地址( )。
A 部分连续,部分不连续 B.一定不连续 C.不一定连续 D.一定连续
15.关于ADT,下面不正确的描述是( )。
A 对同一个问题,不同人可以抽象定义不同的ADT
B.一个ADT,可以有不同的实现
C.对一个问题抽象定义出的ADT 只能有一种实现
D.两个ADT 相同,是指其数据结构和定义的操作分别都相同
16.以下说法错误的是( )。
A.抽象数据类型具有信息隐蔽性。
B.抽象数据类型具有封装性。
C.抽象数据类型的一个特点是使用与实现分离。
D.使用抽象数据类型的用户可以自己定义对抽象数据类型中数据的各种操作。
17.Which one is not a part of an abstract data structure?
A.Abstract operations
B.Structure(Relation)
C.Data
D.Implementation of Operations
18.人机对弈问题的数据是棋局的状态,数据量非常大,这些数据之间具有( )关系。
A.层次关系
B.无
C.图关系
D.线性关系
19.数据结构中,与计算机无关的是数据的( )结构。
A.物理
B.物理和存储
C.存储
D.逻辑
20.Which application can be developed based on the graph data structure?
A.Family information system
B.Transportation networks
C.File directory
D.Student management system
21.数据结构采用链式存储时,其存储空间地址( )。
A.不一定连续
B.一定不连续
C.一定连续
D.部分连续
22.关于抽象数据类型和数据类型,下面不正确的描述是( )。
A.高级语言提供的数据类型是一些物理实现了的抽象数据类型
B.抽象数据类型本身与计算机无关
C.一个数据类型的实现包括三个阶段:抽象定义、虚拟表示、物理实现
D.抽象数据类型包括数据结构、存储结构和定义的操作
答案:1-5 DCAAC 6-10 ABCCC 11-15 BBDDC 16-20 DDADB 21-22 AD
二、简答题
1.(P37 1.1)什么是数据?它与信息是什么关系?
2.(P37 1.2)什么是数据结构?有关数据结构的讨论涉及哪三个方面?
3.(P37 1.3)数据的逻辑结构分为线性结构和非线性结构两大类。线性结构包括数组、链表、栈、队列、优先级队列等;非线性结构包括树、图等。这两类结构各自的特点是什么?
4.(P37 1.4 有删改)什么是抽象数据类型?
三、应用题
1.对于两种不同的数据结构,逻辑结构或物理结构一定不相同吗?
2.试举一例,说明对相同的逻辑结构,同一种运算在不同的存储方式下实现时,其运算效率不同。
3.(P38 1.7)有下列几种用二元组表示的数据结构,试画出它们分别对应的图形表示(当出现多个关系时,对每个关系画出相应的结构图),并指出它们分别属于何种结构。
( 1 ) A = ( K , R ) , K = { a 1 , a 2 , a 3 , a 4 } , R = { } (1)A=(K,R),K=\{a_1,a_2,a_3,a_4\},R=\{\qquad\} (1)A=(K,R),K={a1,a2,a3,a4},R={}
( 2 ) B = ( K , R ) , K = { a , b , c , d , e , f , g , h } , R = { r } , r = { < a , b > , < b , c > , < c , d > , < d , e > , < e , f > , < f , g > , < g , h > } (2)B=(K,R),K=\{a,b,c,d,e,f,g,h\},R=\{r\},r=\{
( 3 ) C = ( K , R ) , K = { a , b , c , d , e , f , g , h } , R = { r } , r = { < d , b > , < d , g > , < b , a > , < b , c > , < g , e > , < g , h > , < e , f > } (3)C=(K,R),K=\{a,b,c,d,e,f,g,h\},R=\{r\},r=\{
( 4 ) D = ( K , R ) , K = { 1 , 2 , 3 , 4 , 5 , 6 } , R = { r } , r = { ( 1 , 2 ) , ( 2 , 3 ) , ( 2 , 4 ) , ( 3 , 4 ) , ( 3 , 5 ) , ( 3 , 6 ) , ( 4 , 5 ) , ( 4 , 6 ) } (4)D=(K,R),K=\{1,2,3,4,5,6\},R=\{r\},r=\{(1,2),(2,3),(2,4),(3,4),(3,5),(3,6),(4,5),(4,6)\} (4)D=(K,R),K={1,2,3,4,5,6},R={r},r={(1,2),(2,3),(2,4),(3,4),(3,5),(3,6),(4,5),(4,6)}
四、填空题
1.(2015.1)数据的逻辑结构被分为集合结构( )、( )、( )、( )四种。
2.(2015.2)数据的存储结构被分为( )、( )、( )、( )四种。
3.(2015.3)一种抽象数据类型包括( )和( )两个部分。
4.(2015.5)栈、队列逻辑上都是( )结构。
5.(2015.6)线性结构反映结点间的逻辑关系是( )的,图中的数据元素之间的关系是( )的,树形结构中数据元素间的关系是( )的。
答案:1.(2015.1)集合结构、线性结构、树形结构、图形结构
2.(2015.2)顺序结构、链接结构、索引结构、散列结构
3.(2015.3)数据、操作 4.(2015.5)线性存储
5.(2015.6)一对一、多对多、一对多
五、判断题
1.(P37 1.5(1)(2)(3)(4))判断下列叙述的对错。
(1〉数据元素是数据的最小单位。
(2)数据结构是数据元素的集合和这个集合中各数据元素之间关系的集合。
(3)数据结构是具有结构的数据对象。
(4)数据的逻辑结构是指各数据元素之间的逻辑关系,是用户按使用需要建立的。
2.(P37 1.6)判断下列叙述的对错。
(1) 所谓数据的逻辑结构是指数据元素之间的逻辑关系。
(2)同一数据逻辑结构中的所有数据元素都具有相同的特性是指数据元素所包含的数据项的个数都相等。
(3)数据的逻辑结构与数据元素本身的内容和形式无关。
(4)数据结构是指相互之间存在一种或多种关系的数据元素的全体。
(5)从逻辑关系上讲,数据结构主要分为两大类:线性结构和非线性结构。
答案:1.FTFF 2.FFTFT
2.算法的基本概念
2.1 计算与算法
**计算(calculate)**指运用事先规定的规则,将一组数值变换为另一(所需的)数值的过程。一般要有一个计算模型。
算法(Algorithm)简单说,就是解决问题的一种方法或过程,由一系列计算步骤构成(目的是将问题的输入变换为输出)。即,它是一个定义良好的计算过程,它以一个或一组值作为输入,并产生一个或一组值作为输出。算法可以理解为由基本运算及规定的运算顺序所构成的完整的解题步骤,或者看成按照要求设计好的有限的确切的计算序列。
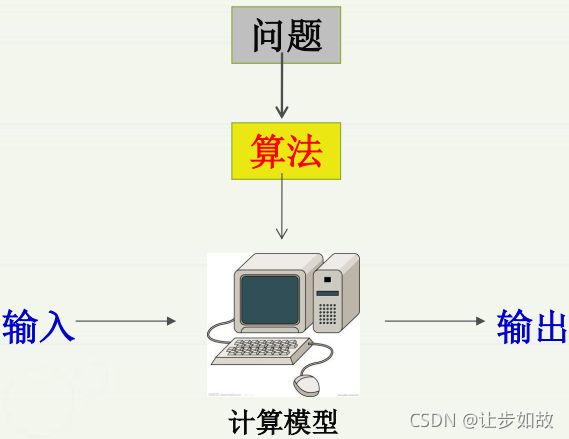
如果问题的一个算法能应用于该问题的任何一个实例,得到该问题的正确解,称这个算法解决了这个问题。
2.2 算法的特性(5个)
(1)有穷性/终止性:有限步内必须停止;
(2)确定性:每一步都是严格定义和确定的动作;
每一步骤操作语义唯一
(3)能行性:每一个动作都能够被精确地机械执行;
人用纸和笔理论上可以执行。
(4)有输入:满足给定约束条件的输入(可以没有);
(5)有输出:满足给定约束条件的结果(必须有)。
算法和程序不同,程序可以不满足上述的特性(4)。
一个算法用某种程序设计语言写出来就是程序,但程序描述的不一定都是算法。
2.3 算法的设计
算法设计是求解问题的关键,也是软件的核心。这是人的脑力创新的一种表现形式。算法设计是一种艺术。
但人们长期设计算法已总结出了一些算法设计策略:
最朴素的策略:蛮力
高级策略:分治策略、贪心策略、动态规划策略、回溯策略、智能策略、概率策略…
2.4 算法的描述
(1)自然语言描述
特点:容易,但有时罗嗦、有二义性;
(2)图示(流程图、N-S图、PAD图等)
特点:直观清晰,但不宜实现;
(3)算法语言(伪代码)
特点:严谨、简洁,易程序实现;
(4)程序设计语言
特点:可以直接运行,但太严格;
2.5 练习题
一、选择题
1-2.计算机算法是指(1) ,它必须具备(2) 这3个特性。
(1)A.计算方法 B.排序方法 C.解决某一个问题的步骤序列 D.调度方法
(2)A.可执行性、可移植性、可扩充性 B.可执行性、确定性、有穷性 C.确定性、有穷性、稳定性 D.易读性、稳定性、安全性
3.一个算法应该是( )。
A.程序 B.问题求解步骤的描述 C.要满足5个基本特性 D.A和C
4.下面关于算法说法正确的是( )。
A.算法最终必须由计算机程序实现 B.为解决某问题的算法同为该问题编写的程序含义是相同的
c.算法的可行性是指指令不能有二义性 D.以上几个都是错误的
5.(2015.17)算法分析的目的是( )。
A .找出数据结构的合理性 B.研究算法中输入和输出的关系
C.分析算法的效率以求改进 D.分析算法的易懂性和文档性
6.关于程序、数据结构和算法,下面正确的描述是( )。
A 程序是对数据结构和算法的一种实现表示
B 程序就是算法 C 算法就是程序
D 程序是由数据结构和算法组成的
7.一个算法必须总是(对任何合法的输入值)在执行有穷步之后结束,是指算法的( )特性。
A 可行性 B 正确性 C 有穷性 D 确定性
8.关于算法的正确性,下面错误的描述是( )。
A 运行算法,进行测试,可以保证算法的正确性
B 运行算法,进行测试,不能保证算法的正确性
C 算法的正确性应该通过数学证明手段来保证
D 所谓正确性是指,对问题的任何输入,都能正确得到相应的输出
9.算法设计是一种创新行为,没有固定模式,但有一些经验总结。递归算法就是一种( )策略。
A 贪心 B 动态规划 C 蛮力 D 分治
10.计算机算法指的( ),它必须具可读性、健壮性、高性能等特性。
A 排序方法 B 解决问题的步骤序列 C 调度方法 D 计算方法
11.关于设计算法的分治策略,下面错误的描述是( )。选择一项:
A 分解和合并是关键 B 简单的分解与合并就会产生好算法
C 递归算法就是采用了分治策略
D 折半查找算法就是采用的分治策略,而且子问题的解就是原问题的解
12.在用贪心策略设计算法时,关键是( )的确定和证明。选择一项:
A 分解子问题的方法 B 贪心准则 C 动态规划方程 D 合并解的方法
13.算法的计算量的大小称为计算的( )。
A 现实性 B 难度 C 复杂度 D 效率
14.关于算法,错误的描述是( )。
A 算法必须有输出,但可以没有输入 B 程序就是算法,算法就是程序
C 算法的每一步必须有严格定义和确定的动作 D 算法必须在执行有限步后能自动结束
答案:1-5 CBBDC 6-10 ACADB 11-14 BBCB
二、简答题
1.(P38 1.8)什么是算法?算法的5个特性是什么?试根据这些特性解释算法与程序的区别。
三、判断题
1.判断下列叙述的对错。
(1)(P37 1.5(5))算法和程序原则上没有区别,在讨论数据结构时二者是通用的。
答案:1.F
3.算法的性能分析
3.1 算法的评价标准
判断一个算法的优劣,主要有以下几个标准:
(1)正确性(correctness)
要求算法能够正确地执行预定的功能和性能要求。这是最重要的标准,这要求算法的编写者对问题的要求有正确的理解,并能正确地,无歧义地描述和利用某种编程语言正确地实现算法。
(2)可读性(readability)
算法应当是可读的。这是理解、测试和修改算法的需要。为了达到这一要求,所有的变量函数命名必须有实际含义。在算法中必须加入注释。
(3)健壮性(robustness)
要求在算法中加入对输人参数、打开文件、读文件记录、子程序调用状态进行自动检错、报错并通过与用户对话来纠错的功能。这也叫做容错性或例外处理。一个完整的算法必须具有健壮性,能够对不合理的数据进行检查。但在算法初写时可以暂不管它,集中精力考虑如何实现必要的功能,待到算法成熟时再追加它。
(4)效率( efficiency)
算法的效率主要指算法执行时计算机资源的消耗,包括存储和运行时间的开销,前者叫做算法的空间代价,后者叫做算法的时间代价。算法的效率与多种因素有关。
(5)简单性( simplicity)
算法的简单性是指一个算法所采用数据结构和方法的简单程度。算法的简单性便于用户编写、分析和调试,它与算法的出错率直接相关。算法越简单,其出错率越低,可靠性越高。但最简单的算法往往不是最有效的,即可能需要占用较长的运行时间和较多的内存空间。
(6)可使用性(usability)
要求算法能够很方便地使用。此特性也称用户友好性。为便于用户使用,要求该算法具有良好的界面和完备的用户文档。
3.2 算法性能的分析方法
算法分析(Algorithm Analysis) 估量一个算法效率的方法,包括运行时间效率和空间效率。
(1)经验测试:即做实验。
将算法写成程序,选择样本数据,实际运行算法,具体分析实验数据(占用空间、运行时间)。
现在在一些论文中也经常见到。
(2)先验估计:
根据算法(逻辑)流程本身,建立评估模型,得到评估结论。
算法复杂性的度量属于事前估计。它可分为空间复杂度度量和时间复杂度度量。
D.E.Knuth模型:对给定的算法流程进行数学建模。
- 思想 —统计算法基本操作的频度(次数)的累加和。
- 手段 —数学分析(会用到数学分析中的函数和近似函数)。
- 结果 —复杂冗长的数学表达式。
(3)经验测试与先验估计对比
| 算法效率的度量 | 经验测试(后期测试) | 先验估计(事前估计) |
|---|---|---|
| 方法 | 选择样本数据、运行环境运行算法计算出空间、时间。 | 根据算法的逻辑特征(基本数据量、基本操作)来估算。 |
| 优点 | 精确 | 可比性强 |
| 缺点 | 可比性差,效率低 | 不精确,仅仅是估计 |
3.3 算法的空间性能分析—空间复杂度
(1)算法的空间性能的影响因素
-
指令空间(由机器决定)﹔
-
数据空间(常量、变量占用空间);
数据空间一用来存储算法所有常量和变量的值。分成两部分:存储简单量、存储复合变量。
-
环境栈空间;
(2)度量方法:
单个常量、变量:由机器和编译器规定的类型存储决定数组变量:所占空间等于数组大小乘以单个数组元素所占的空间。
结构变量:所占空间等于各个成员所占空间的累加;
例如:
double a[100];所需空间为100×8=800
int matrix[r][c];所需空间为2×r×c
(3)常用的空间复杂度:
空间复杂度(space complexity) 是指当问题的规模以某种单位从1增加到n时,解决这个问题的算法在执行时所占用的存储空间也以某种单位由1增加到S(n),则称此算法的空间复杂度为S(n);
- 空间复杂度 S(1)
- 空间复杂度 S(n)
- 空间复杂度 S(n2)
3.4 算法的时间性能分析—时间复杂度(重点)
(1)算法的时间性能的影响因素:
- 机器的运行速度(执行代码的速度);
- 书写程序的语言;
- 编译产生代码的质量;
- 算法的策略;
- 问题的规模;
(2)算法的时间性能度量:
令 T ( P ) T(P) T(P)表示算法Р需要的时间,则有:
T ( P ) = c + t p T(P) =c+ t_p T(P)=c+tp(实例特征)
度量模型: T ( n ) = c + t p ( n ) , t p ( n ) = c a A D D ( n ) + c s S U B ( n ) + c m M U L ( n ) + c d D I V ( n ) + ⋯ T(n) = c+ t_p(n),t_p(n)=c_aADD(n)+c_sSUB(n)+c_mMUL(n)+c_dDIV(n)+\cdots T(n)=c+tp(n),tp(n)=caADD(n)+csSUB(n)+cmMUL(n)+cdDIV(n)+⋯
其中, c a , c s , c m , c d c_a,c_s,c_m,c_d ca,cs,cm,cd表示一个加、减、乘、除操作所需的时间;
函数ADD,SUB,MUL,DIV分别表示P中所使用的加、减、乘、除等基本操作的次数;
即T§是算法中一些基本操作的执行次数的累加和。它一般是关于规模(n)的函数(P29-32)。
(3)渐近复杂性分析:
算法的增长率(growth rate) 是指当问题规模增长时,算法代价的增长速率。具体就体现在两个函数的变化趋势上。
T(n)=f(n)——时间代价
S(n)=g(n)——空间代价
简单说,就是看看这个算法的资源消耗的增长有多快,增长快的(阶高),其资源消耗就大,复杂性就高!这就是复杂性渐近态的思想。
渐近复杂性分析只关心度量函数的阶就够了,因为按照渐近的思想,度量函数中的常数因子对算法复杂性的影响不敏感。渐近复杂性分析主要专注于问题的**“规模”、“基本的操作”和增长率**。
渐近复杂性分析(Asymptotic Algorithm Analysis) 确切说:渐近分析是指当输入规模很大,或者说大到一定程度时对算法的研究和分析。即,忽略其处理小规模问题时的能力差异,只关注其在处理更大规模问题时的表现。
仍然采用 D.E.Knuth模型
- 思想 —着眼长远、更为关注时间复杂度的总体变化 趋势和增长率,即按增长率确定算法的类别;
- 手段 —用近似的方式忽略公式中那些非常复杂但幂 次较低的项;
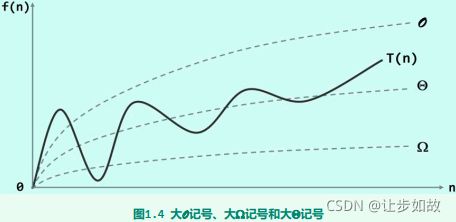
- 结果 —增长率的阶, O 、 Ω 、 Θ O、\Omega、\Theta O、Ω、Θ
(4)渐近时间复杂性的数学符号:
- 渐近上界: O O O——增长率的最小上界(限)——最坏情况下的时间代价
- 渐近下界: Ω \Omega Ω——增长率的最大下界(限)——最好情况下的时间代价
- 渐近确界: Θ \Theta Θ——增长率的上、下界相同

(5)大 O O O表示法中使用的典型函数:

c < log 2 n < n < n l o g 2 n < n 2 < n 3 < 2 n < 3 n < n ! c<\log_2n
(6)算法分析的一般步骤:
- 确定问题规模参数;
- 确定关键(基本)操作、存储;
- 依据算法流程,建立各个量之间的“和”关系模型;
- 利用数学方法求出累计和函数T(n),S(n);
- 给出渐近表示。
(7)一般算法的时间复杂性分析:
1.决定哪个(哪些)参数表示输入规模;
2.确定基本操作。赋值、读、写等一般看作基本操作;(统一标准)
3.划分算法的三种控制结构;
4.对各种控制结构,有:
- (1)顺序操作序列,可以累加或取最大值;
- (2)分支的条件判断一般看作基本操作,分支结构的时间定义为条件成立和不成立时的和;
- (3)循环结构的时间为循环体的时间乘循环次数;
5.函数调用时要考虑函数的执行时间。
6.建立其基本操作执行次数的“求和”表达式(统计模型)
7.利用数学知识求和得到其T(n)
8.确定阶,得到渐近表示 O 、 Ω 、 Θ O、\Omega、\Theta O、Ω、Θ;一般给出 O O O表示。
例1,分析下面算法(程序段)表示的算法的时间复杂性。

例2,有算法如下,分析其的时间复杂性。
MaxElement(A[0..n-1]){
//功能:?
//输入:数组A[0..n-1]
// 输 出 :?
maxval=a[0];
for(i=1;i<=n-1;i++)
if(a[i]>maxval)
maxval=a[i];
return maxval;
}
答案:T(n)=O(n)
例3,有算法如下,分析其的时间复杂性。
UniqueElements(A[0..n-1]){
//功能:?
//输入:数组A[0..n-1]
// 输 出 :?
for(i=0;i<=n-2;i++)
for(j=i+1;j<=n-1;j++)
if(a[i]==a[j]) return False;
return True;
}
答案:T(n)=O(n2)
例4,有算法如下,分析其的时间复杂性。(p34 程序1.26)
void example(float x[][n],int m){
float sum[m];int i,j;
for(i=0;i答案:T(m,n)=O( m × n m\times n m×n)
例5,分析顺序查找算法的复杂性(p36 程序1.27)
int SequenceSearch(int a[],int n,int key){
//若找到,则返回元素的下标,否则返回-1;
for(int i=0;i答案:Tmin(n)=O(1)、Tmax(n)=O(n)、Tave(n)=O(n)
(8)递归算法的时间复杂性分析:
递归算法是比较特殊的一类算法,其时间复杂性分析过程一般有下面几步:
1.根据递归算法确定问题的相关参数;
2.分析递归算法,建立递推关系,给出边界条件,写出时间的递归方程;
3.求解递归方程;
4.给出递归方程解的渐近表示;
其中,求解递归方程式是关键,也是比较难的一步!
例6,Hanoi塔求解问题
void Hanoi(int n,char c1,char c2,char c3){
if(n==1) printf("%c->%c\n",c1,c2);
else{
Hanoi(n-1,c1,c3,c2);
printf("%c->%c\n",c1,c2);
Hanoi(n-1,c3,c2,c1);
}
}
答案: T ( n ) = 2 × 2 × 2 × ⋯ × c = 2 n − 1 × c = O ( 2 n ) T(n)=2\times2\times2\times\cdots\times c = 2^{n-1}\times c=O(2^n) T(n)=2×2×2×⋯×c=2n−1×c=O(2n)
例7,二分查找
int B_S(int l,int r,int a[],int x){
int m;
if(ra[m]) l=m+1;
else r=m-1;
B_S(l,r,a,x);}
}
}
答案: T ( n ) = c + c + c + ⋯ = log 2 n × c = O ( log 2 n ) T(n)=c+c+c+\cdots=\log_2n\times c=O(\log_2n) T(n)=c+c+c+⋯=log2n×c=O(log2n)
3.5 练习题
一、选择题
1.算法的计算量的大小称为算法的( )。
A.效率 B、复杂度 C.现实性 D.难度
2.算法的时间复杂度取决于( )。
A.问题的规模 B.待处理数据的初态 C.A和B
3.在下面的程序段中,对x的赋值语句的频度为( )。
for(i=0;iA.O(2n) B. O(n) C.O( n 2 n^2 n2) D.O( log 2 n \log_2n log2n)
4.程序段如下所示,其中n为正整数,则最后一行的语句频度在最坏情况下是( )。
for(i=n-1;i>=1;--i)
for(g=1;j<=i;++j)
if(A[j]>A[j+1]) A[j]与A[j+1]对换;
A. O(n) B.O( n log 2 n n\log_2n nlog2n) C.O(n3) D.O(n2)
5.(2015.13)下面程序段的时间复杂度为( )。
for (int i=0;iA O(m2) B O(n2) C O(m*n) D O(m+n)
6.(2015.14)下面程序段的时间复杂度为( )。
int f(unsigned int n) {
if(n= =0 || n= =1) return 1;
else return n*f(n-1);
}
A O(1) B O(n) C O(n2) D O(n !)
7.O indicates the ( ) bound。
A Exact B Mean C Upper D Lower
8.从 n>=3 个互异整数中,除最大、最小者以外,任取一个“常规元素”。 算法如下:该算法的时间复杂性为( )。
ordinaryElement(S[ ],n){
从S中任取三个元素 x,y,z;
通过比较,对它们排序;
输出中间元素;
}
A O(log2(n)) B O(n) C O(1) D O(nlog2(n))
9.Which one is slowest:
A O(n!) B O(2n) C O(n2) D O(log(n))
10.下面是求 a 的 n 次幂的递归算法,其时间复杂性为( )。
int power(int a,int n){
int t;
if(n==0) return 1;
else if(n%2==0){ t=power(a,n/2);
return t*t;
} else { t=power(a,(n-1)/2);
return a*t*t;
}
}
A O(n) B O( n2) C O(1) D O(log2(n) )
11.有求 n 个数累加和的算法如下,其时间复杂性为( )。
int Sum(int a[ ],int n){
if(n==0) s=a[n];
else s=a[n-1]+Sum(a,n-1);
return s;
}
A O(n) B O( n2) C O(1) D O(log2(n) )
12.如果一个算法的时间复杂性为 O(n),则下面不正确的是( )。
A 某些情况下,该算法可能比时间复杂性为 O( n2 )的算法性能差
B 任何时候它比时间复杂性为 O( n2 )的算法性能都好
C 该算法的最坏时间复杂性为线性增长率
D 如果计算机的运行速度提高 K 倍,那么在相同时间内,该算法可解决问题的规模也可以提高 K 倍
13.What is the time cost of the following code:( )。

A T(n)=c1*n*n+c2 B T(n)=c1n+c2 C T(n)=c1+c2 D T(n)=c1i*j + c2
14.有算法如下,其时间复杂性为( )。
x=0;
i=1;
while(i<=n){
x=x+i;
i=i*2;
};
A O(n) B O( n2) C O(1) D O(log2(n) )
15.Ω indicates the ( ) bound.
A Exact B Upper C Mean D Lower
16.对于任意非负整数,下面的算法统计其对应二进制中数位 1 的个数。该算法的时间复杂性为( )。
int countOnes(unsigned int n) {
int ones=0;
while(n>0){
ones=ones + n%2; //%为取余运算
n=n/2;
}
return ones;
}
A O(n) B O( n2) C O(1) D O(log2(n) )
17.关于渐近时间复杂性分析,不正确的是( )。
它是一种事前估计算法时间复杂性的方法
比较的是算法基本操作次数随问题规模变化的增长率
比较的是算法基本操作的次数
关注点是问题规模大到一定程度后算法的时间性能表现
18.下列程序段(算法)的时间复杂度为( )。
x=n; y=0;
while(x>=(y+1)*(y+1))
y=y+1;
A O(n) B O( n2) C O(1) D O(sqrt(n) )
答案:1-5 BCCDC 6-10 BCCAD 11-15 ABADD 16-18 DCD
二、应用题
1.有下列运行时间函数,分别写出相应的以O表示的运算时间。
(1)f1(n)=1000;
(2)f2(n)=n2+1000n;
(3) f3(n)=3n3+100n2+n+1;
2.如下函数mergesort( )执行的时间复杂度为多少?假设函数调用被写为mergesort(1,n),函数 merge( )的时间复杂度为O(n)。
void mergesort(int i,int j){
int m;
if(i!=j){
m=(i+j)/2;
mergesort(i,m);
mergesort (m+1,j);
merge(i,j,m);//本函数的时间复杂度为O(n)
}
}
3.(P39 1.13)指出下列各算法的功能并求出其时间复杂度。
(1)功能:
时间复杂度:
int Prime(int n){
int i = 2,x = (int)sqrt(n);
while ( i<= x){
if (n %i == 0) break;
i++;
}
if (i > x) return 1;
else return 0 ;
}
(2)功能:
时间复杂度:
int suml(int n){
int p = 1,s = 0;
for (int i = 1; i<=n; i++)
p* = i; s += p;
return s;
}
(3)功能:
时间复杂度:
int sum2(int n){
int s = 0 ;
for (int i = l; i(4)功能:
时间复杂度:
int fun(int n){
int i = 1,s = 1;
while (s (5)功能:
时间复杂度:
void UseFile(ifstream& inp,int c]){
//假定inp所对应的文件中保存有n个整数。
for (int i -== 0; i< 10; i++) c[i]=0;
int x;
while (inp >>x){
i= x%10;c[i]++;
}
}
(6)功能:
时间复杂度:
void mtable( int n){
for (int i = l; i<=n; i++){
for (int j m i; j<=n; j++){
cout<(7)功能:
时间复杂度:
void cmatrix(int a[][],int M,int N,int d){
//M和N为全局整型常量
for (int i = 0; i< M; i++)
for (int j = 0; j(8)功能:
时间复杂度:
void matrimult(int a[][],int b[][],int c[][],int M,int N,int L) {
//数组a[M][N]、b[N][L]、c[M][L]均为整型数组int i,j,k;
for (i = 0; i答案:1.(1)O(1) (2)O(n2) (3)O(n3) 2.O( n log 2 n n\log_2n nlog2n)
3.(1)O( n \sqrt{n} n) (2)O(n) (3)O(n2) (4)O( n \sqrt{n} n)
(5)O(n) (6)O(n2) (7)O(M × \times ×N) (8)O(M × \times ×N × \times ×L)
四、填空题
1.(P41 1.14(12))一个算法的时间复杂度为 ( 3 n 2 + 2 n log 2 n + 4 n − 7 ) / ( 5 n ) (3n^2+2n\log_2n+4n-7)/(5n) (3n2+2nlog2n+4n−7)/(5n),其数量级表示为( )。
答案:1.O(n)
五、算法分析与设计
1.(P41 1.15)设有3个值大小不同的整数a,b 和c,试编写一个C++函数,求
(1)其中值最大的整数;
(2)其中值最小的整数;
(3)其中位于中间值的整数。
2.(P42 1.16)用C++函数编写一个算法,比较两个整数a和b的大小,对于a > b,a = = b,a