Apache Hive概述以及在linux安装hive
目录
一、Apache Hive概述
二、Apache Hive基础架构
1.Hive架构图
2.Hive组件
三、Hive集群部署
1.安装MySQL数据库(root用户)
2.配置Hadoop
3.下载Hive
4.提供Mysql Driver包
5.配置Hive
6.初始化数据库
7.修改hive安装目录用户组,切换到Hadoop用户
8.启动hive服务
四、Hive简单操作(建议记事本打好粘贴)
1.创建表
2.插入表
3. 查询数据
4.验证Hive存储
5.验证SQL语句启动的MapReduce程序
五、Hive客户端
1. Hive server2 & Beeline
2.启动Beeline
3. DATa grip连接hive server2
一、Apache Hive概述
Apache Hive是一款分布式SQL计算的工具,其主要功能是:将SQL语句翻译成MapReduce程序运行。基于Hive为用户提供了分布式SQL计算能力,写的是SQL,运行的是MapReduce。
Hive的优点:
①操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
②底层执行MapReduce,可以完成分布式海量数据的SQl处理。
二、Apache Hive基础架构
1.Hive架构图

2.Hive组件
(1)元数据存储
通常是存储在关系数据库MySQL/derby中。Hive中的元数据包括表的名字、表的列和分区及其属性、表的属性(是否为外部表等)、表的数据所在目录等。
Hive提供了Metastore服务进程提供元数据管理功能。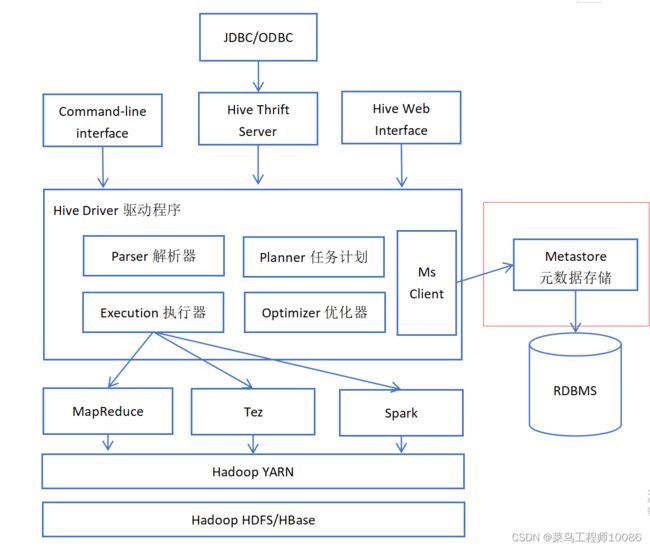
(2)Drive驱动程序
包括语法解释器、计划编译器、优化器、执行器。
完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询几乎存储在HDFS并在随后执行引擎调用执行。这部分内容不是具体的服务进程,而是封装在Hive所依赖的Jar文件即java代码中。
(3)用户接口
包括CLI、JDBC/ODBC、web GUI。其中CLI(command line interface)为shell命令行;Hive的Thrift服务器运行外部客户端提供网络与Hive进行交互,类似于JDBC或ODBC协议。web GUI是通过浏览器访问Hive。
-- Hive提供了Hive Shell、ThirftServer等服务进程向用户提供操作接口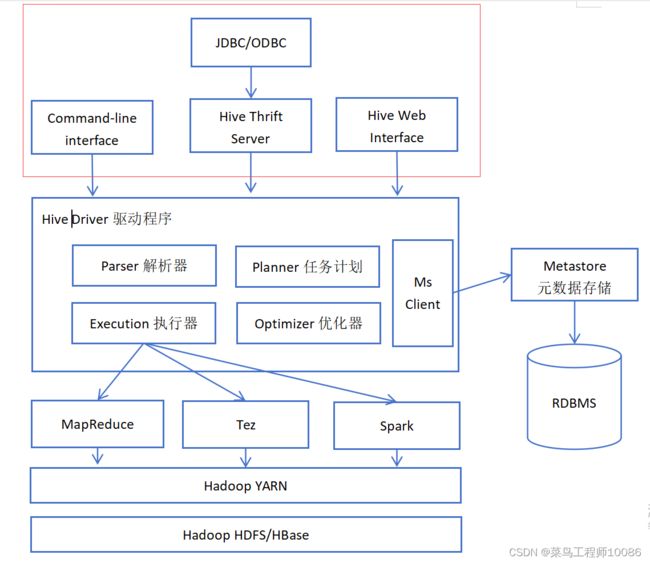
三、Hive集群部署
Hive是单机工具,只需要在一台机器部署即可。另外由于Hive需要元数据服务,需要提供一个关系数据库(我选择的MySQL)。为了方便都安装在node1节点。
1.安装MySQL数据库(root用户)
(1)更新密钥
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
![]()
(2)安装MySQL yum库
rpm -Uvh https://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm
(3)yum安装MySQL
yum -y install mysql-community-server
(4)启动MySQL设置开机启动
systemctl start mysqld
systemctl enable mysqld
(5)检查MySQL服务状态
systemctl status mysqld
(6)查看MySQL密码
grep 'temporary password' /var/log/mysqld.log

(7)设置简单密码
mysql -uroot -p #登录MySQL,密码是刚刚查看的临时密码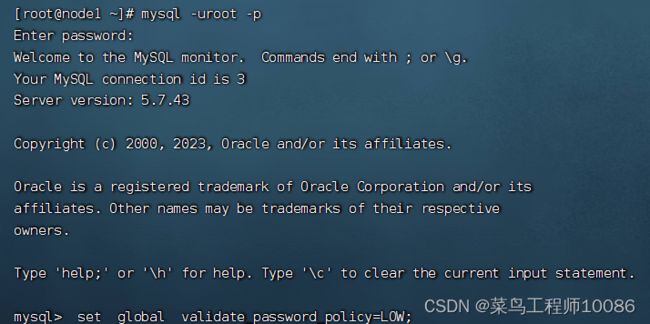
set global validate_password_policy=LOW; #密码安全级别低
set global validate_password_length=4; #密码长度最低四位
ALTER USER 'root'@'localhost' IDENTIFIED BY '密码';
grant all privileges on *.* to root@"%" identified by 'root' with grant option;![]()
flush privileges;

2.配置Hadoop
(1)配置core-site.xml文件

(2)分发文件(在core-site.xml文件所属目录分发)
scp core-site.xml node2:`pwd`/
scp core-site.xml node3:`pwd`/
3.下载Hive
(1)下载Hive安装包
链接:https://pan.baidu.com/s/1bUzPcw-vh6OE1eZ-6UWRkQ
提取码:1111
(2)root用户上传  (3)解压
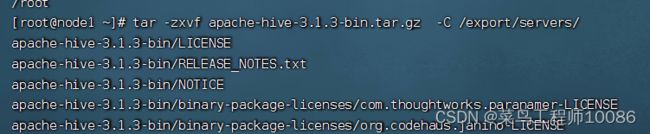
(3)解压
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /export/servers/
(4)构建软连接
ln -s /export/servers/apache-hive-3.1.3-bin/ /export/servers/hive
4.提供Mysql Driver包
链接:https://pan.baidu.com/s/1NkVdJTvtLe0sAIsqMaEnbg
提取码:1111
(1)上传

(2)将下载好的驱动 jar 包,放入: Hive 安装文件夹的 lib 目录内 
5.配置Hive
在 Hive 的 conf 目录内,新建 hive-env.sh 文件,填入以下环境变量内容: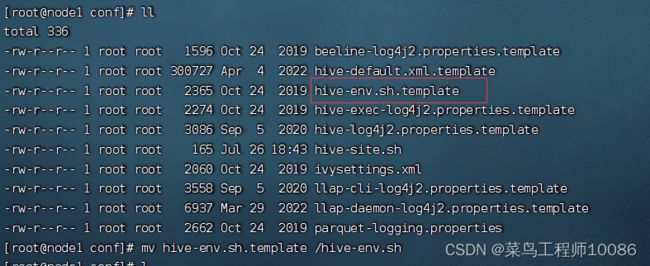
将此文件改名为hive-env.sh即可
export HADOOP_HOME=/export/servers/hadoop
export HIVE_CONF_DIR=/export/servers/hive/conf
export HIVE_AUX_JARS_PATH=/export/servers/hive/lib
新建hive-site.xml,填入以下内容:


6.初始化数据库
(1)登录MySQL,新建数据库hive
CREATE DATABASE hive CHARSET UTF8;

(2)进入Hive安装目录下的bin目录

执行:./schematool -initSchema -dbType mysql -verbos

进入MySQL查看hive数据库,如果有74张表即表示成功

7.修改hive安装目录用户组,切换到Hadoop用户
chown -R hadoo[:hadoop apache-hive-3.1.3-bin/ hive
切换用户Hadoop,在hive目录创建文件夹logs

8.启动hive服务
(1)启动元数据服务
前台启动: bin/hive --service metastore
后台启动: nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
(2)启动客户端
Hive Shell 方式(可以直接写 SQL ): bin/hive
Hive ThriftServer 方式(不可直接写 SQL ,需要外部客户端链接使用): bin/hive --service hiveserver2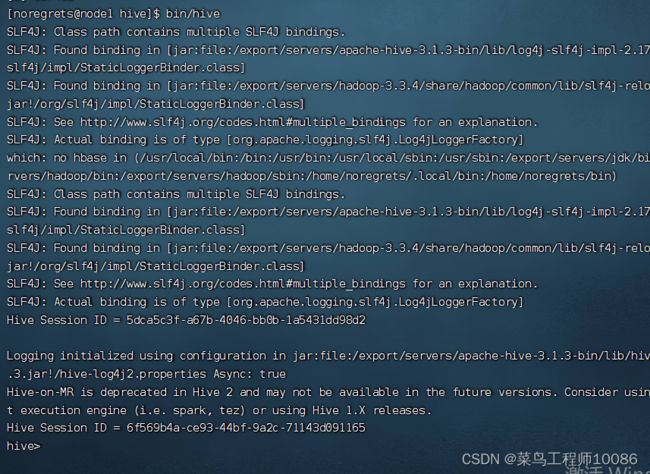
出现hive,然后show databases,如果能够显示则表示hive安装成功。
四、Hive简单操作(建议记事本打好粘贴)
1.创建表
create table test(id INT,name string,gender string);
2.插入表
insert into test values (1,"王力宏","男"),(2,"周杰伦","男"),(3,"林志玲","女");
3. 查询数据
select gender,count(*) as cnt from test group by gender;

4.验证Hive存储
hdfs dfs -ls /user/hive/warehouse

5.验证SQL语句启动的MapReduce程序
进入网址node1:8088
五、Hive客户端
1. Hive server2 & Beeline
启动matestore服务和hive server2服务
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
2.启动Beeline
(1)在hive目录启动/bin/beeline

(2)连接Hive server2
!connect jdbc:hive2://node1:10000
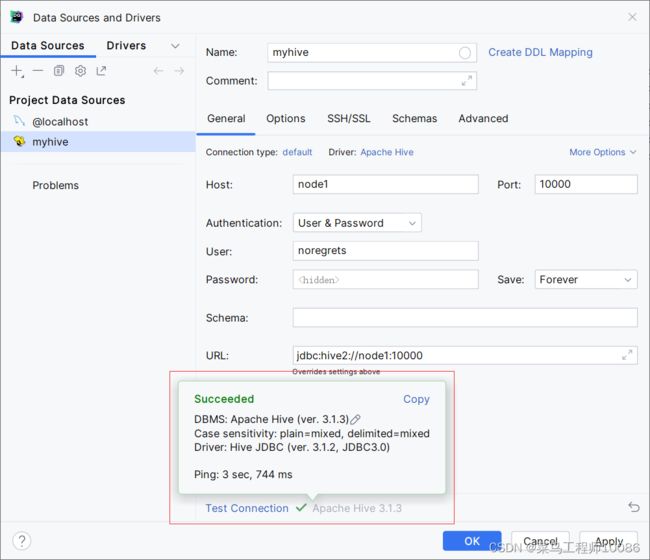
3. DATa grip连接hive server2
(1)连接Hive
下载驱动

填写连接信息
点击Test Connection