基于Arthas排查线上OOM的例子
最近工作当中遇到了一个现场OOM问题需要排查原因。由于之前没有接触过因此这次的排查过程给与了我一定的灵感和排查经验,特此总结和记录这个过程希望后面遇到相关的问题能有所帮助。
背景:
现场生产环境发生一例OOM内存溢出问题,通过日志查看只能看到业务代码存在报错的情况,但是没有看到有OOM的日志提示信息,也就是说无法通过log日志直观看到OOM的原因。
那么思路就需要转变了,我们想要知道哪个线程在执行业务代码时花费了多少时间占用了多少JVM内存空间,那么是可以通过生产的dump日志进行解析的,于是赶紧联系现场发布人员获取到了一个xxxxxx.hprof文件。接下来我们通过dump的解析工具MAT(MamoryAnalyzer.exe)打开,就可以看到调用的堆栈信息了。
如下图:
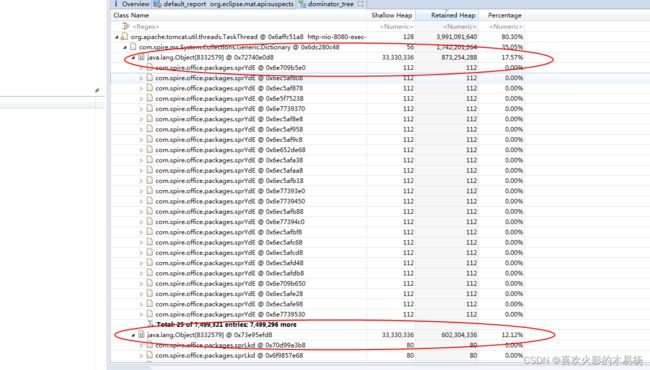
通过上图可以看到不同调用线程的执行情况和占用内存情况,我们可以找到占用内存最多的线程及性能针对性分析。
首先这些列进行介绍每个列代表的含义,以及出现这些数字的原因。
Class Name:线程调用栈经过的类名和方法
Shallow Heap:自身占用内存,不含指向对象的占用内存
Retained Heap:自身占用内存+内部对象指定占用内存
Percentage:线程占用整个堆老年代内存的百分比
怎么理解Shallow Heap和Retained Heap呢?Shallow Heap这个实际是线程或方法自身的占用大小,例如一个线程本身内部就有线程空间,虽然很小但是也是存在的,在上图中该线程Shallow Heap就是128个字节。而每一个sprYdE自身Shallow Heap就是112个字节。但是为什么Retained Heap会这么大呢?那是因为线程内部有很多其它的对象或属性等,对象本身又指向一个内存大小,因此把这些全部加起来就是总的占用内存大小了。从上图可以看到这个线程的Retained Heap是非常大的,原因是创建了大量的sprYdE对象和sprLkd对象积累导致的。
而再通过前面的调用链,我们可以很清楚明确报错的方法出现再document.saveFile(xxx,xxx.PDF)这个方法上。接下来只要针对这个方法进行改造即可。
上面就是现场发生了这个OOM的问题定位过程。那么我们也可以使用一些性能监控平台(如Arthas)进行性能监控,在发生OOM等问题等通过Arthas导出dump等方式,结合MAT或JDK自带的内存分析工具进行问题定位。具体步骤如下:
一.官网下载Arthas的完整发布包arthas-bin.zip(本质就是一个SpringBoot工程),使用java -jar arthas-boot.jar启动,选择需要监控的工程进程就可以进行监控了:
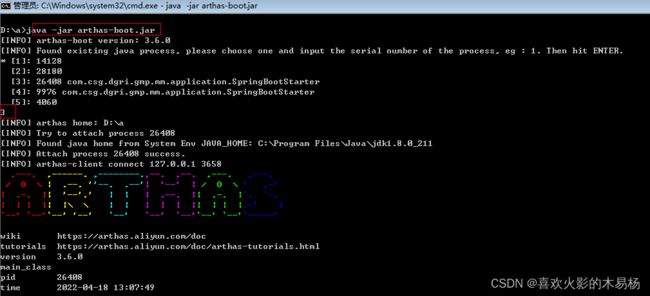
然后我们通过浏览器进行操作。在浏览器中输入:localhost:3658就可以打开监控命令页面:
先输入dashboard命令,可以查看此时这个监控工程的执行情况,这里包括占用JVM内存的情况。
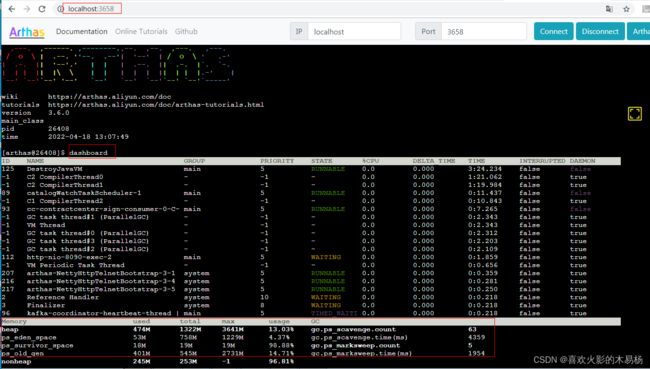
我们可以通过上面占用JVM的情况,大致分析出这个工程在运行期间是否发生了占用内存过高甚至OOM情况,一般情况下发生内存占用过多大概率是JVM的堆内存占用过大了,那么由此引出了JVM堆内存模型中ps_eden_space、ps_survivor_space和ps_old_gen三个分代内存空间的关系。
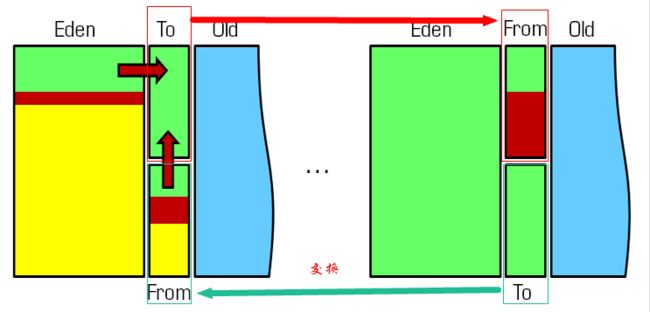
一、Eden新生代:一般内存空间比较小,用于频繁GC回收无用对象
主要是用来存放新生的对象。一般占据堆的1/3空间。由于频繁创建对象,所以新生代会频繁触发MinorGC进行垃圾回收。
新生代又分为 Eden区、ServivorFrom、ServivorTo三个区。
Eden区:Java新对象的出生地(如果新创建的对象占用内存很大,则直接分配到老年代)。当Eden区内存不够的时候就会触发MinorGC,对新生代区进行一次垃圾回收。
ServivorTo:保留了一次MinorGC过程中的幸存者。
ServivorFrom:上一次GC的幸存者,作为这一次GC的被扫描者。
MinorGC的过程:MinorGC采用复制算法。首先,把Eden和ServivorFrom区域中存活的对象复制到ServicorTo区域(如果有对象的年龄以及达到了老年的标准,则赋值到老年代区),同时把这些对象的年龄+1(如果ServicorTo不够位置了就放到老年区);然后,清空Eden和ServicorFrom中的对象;最后,ServicorTo和ServicorFrom互换,原ServicorTo成为下一次GC时的ServicorFrom区。
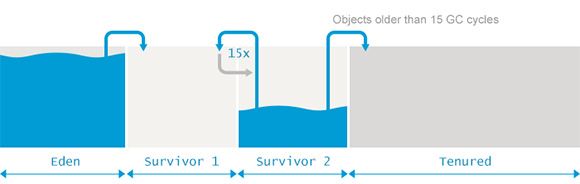
二、Old老年代:一般分配的空间比较大
主要存放应用程序中生命周期长的内存对象或大对象。
老年代的对象比较稳定,所以MajorGC不会频繁执行。在进行MajorGC前一般都先进行了一次MinorGC,使得有新生代的对象晋身入老年代,导致空间不够用时才触发。当无法找到足够大的连续空间分配给新创建的较大对象时也会提前触发一次MajorGC进行垃圾回收腾出空间。
MajorGC采用标记—清除算法:首先扫描一次所有老年代,标记出存活的对象,然后回收没有标记的对象。MajorGC的耗时比较长,因为要扫描再回收。MajorGC会产生内存碎片,为了减少内存损耗,我们一般需要进行合并或者标记出来方便下次直接分配。
当老年代也满了装不下的时候,就会抛出OOM(Out of Memory)异常。
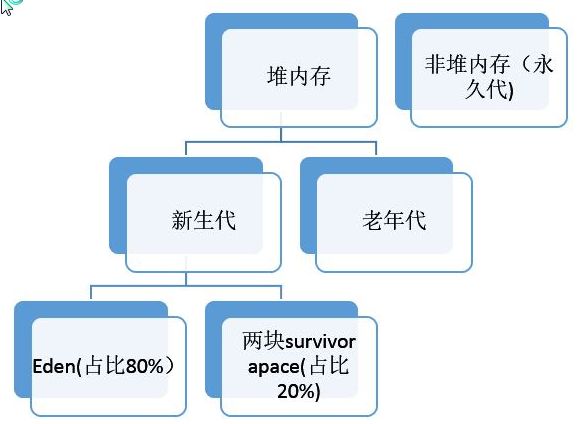
简而言之。我们知道一个对象在创建时,一般是在Eden区分配内存空间,但是当这个对象在执行过程中始终都没有被销毁那么在多次GC之后,这个对象就会逐渐进行后面的分代空间中。而对于一些大对象来说,有可能在Eden区经过一个GC之后发现需要占用的内存很大,于是马上就将这个大对象直接放到了Old区,于是这种大对象一多自然Old空间不足就可能会出现内存溢出问题。
了解了上面的分代情况,以及可能会出现OOM的情况,于是我们通过Arthas观察老年代如果发生内存占用过高,就基本可以判定这个工程大概率会发生内存溢出问题。那么接下来怎么定位具体这个工程哪个地方的代码会导致这种情况发生呢?
我们可以通过Arthas的heapdump xxxxxx.hprof命令导出dump文件到本地:
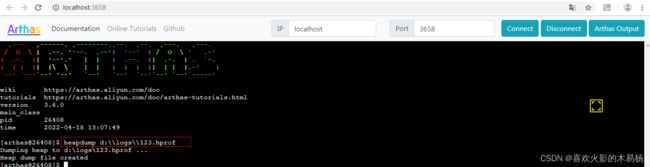
然后使用MAT等内存分析工具打开这个dump文件,就可以进行内存分析了。分析方式跟前面生产环境定位OOM问题的思路步骤一样,这里就不重复展开了。
关于Arthas还有很多使用的命令,比如监控某个方法的调用过程耗时时间等,可以使用[trace 类名 方法名 -n 监控次数]等命令进行监控,详细请查阅官网。