服务器性能挖掘提升,【AWS征文】用什么方法来挖掘提升 EBS、S3 和 EFS 的潜在性能...
在使用 AWS 云计算服务的过程中,不可避免的需要接触到一些基础的存储服务,如 EBS、S3、EFS 等。那我们平时的设定是否正确?是否获得的最佳的性能?本文将带你了解如何获取存储资源更高级别的性能。
一、测试环境准备
首先我们需要准备自己的测试环境,为了简便创建和减少创建中的错误,我们这里使用 AWS CloudFormation 来一键创建我们需要的测试资源栈。
1.1、使用 CloudFormation 创建资源
打开 CloudFormation 控制台,输入下面的模版地址创建资源,然后点击 Next。
https://s3.amazonaws.com/code.wzlinux.com/wzlinux_storage_performance.yaml

输入 Stack name,点击 Next。
默认,点击 Next。
勾选需要创建的资源,点击 Create Stack。

然后查看创建过程,直到资源创建完毕。
1.2、使用 Instance Connect 连接创建的 EC2
打开 AWS Console,选择 EC2。
勾选 CloudFormation 创建的 EC2,名字为 Wzlinux_Storage_Performance。
点击实例右上角的 Connect 按钮。
选择 EC2 Instance Connect 选项。

登陆进去查看,如果无法登陆可能需要等一会,等待 CloudFormation 彻底创建完成。

隔一段时间之后,会话会自动断开,到时候关闭窗口重新连接即可。
二、EBS Performance
测试基础 IOPS
这里我们会用到一个 IO 测试工具 fio,工具已经使用 CloudFormation 安装好了,我们使用这个工具把 EC2 上面的 GP2 硬盘的 burst credits 消耗完,这样可以去测试真实的 EBS 性能。
使用下面的命令可以查看 FIO 是否在运行。
ps -ef| grep fio

我们去查看一下容量为 1GB 的 GP2 硬盘的监控情况,设备为 /dev/sdb 。

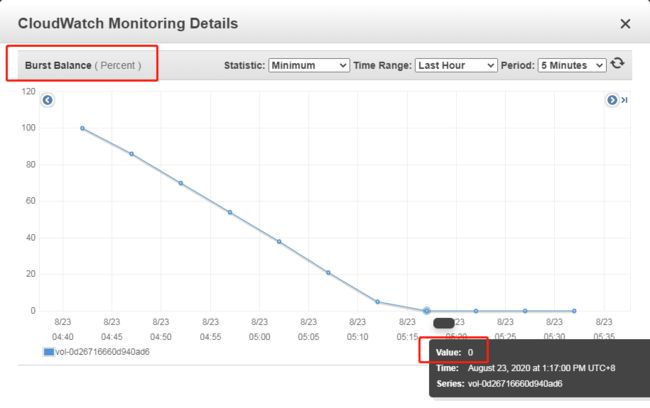
这里有两个监控指标是我们需要关注的,Read Throughput 和 Burst Balance。
在 Burst Balance 消耗完之前,Read Throughput 会一直处于 3000 IOPS
Burst Balance 积分大约在 30 分钟内消耗完毕
Burst Balance 积分消耗完毕之后,Read Throughput 会处于 100 IOPS 的性能
差不多过了半个小时之后,我们查看一下监控,看看目前指标的状况。

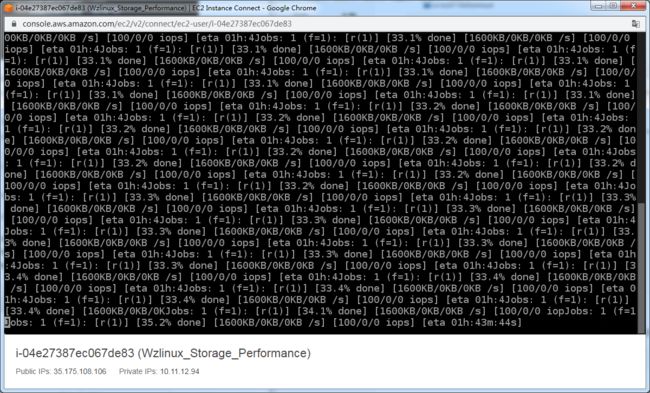
登陆到 EC2 上面,使用下面的命令查看 FIO 的作业,来查看当前的 IOPs。
sudo screen -r
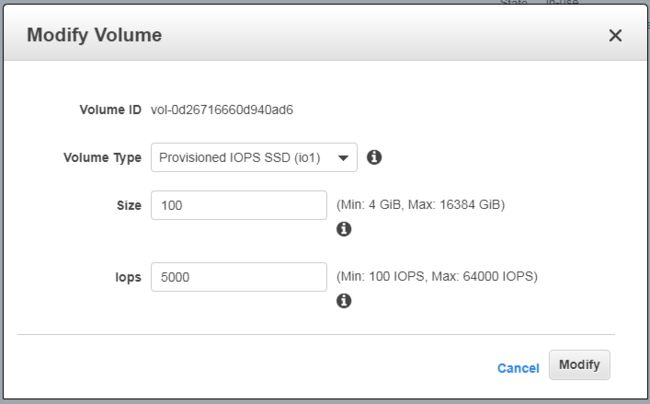
扩容磁盘
在 AWS 的控制台中,点击 Actions,选择 Modify Volume。修改为如下值:
Volume Type: Provisioned IOPS SSD(io1)
Size: 100GB
Iops: 5000
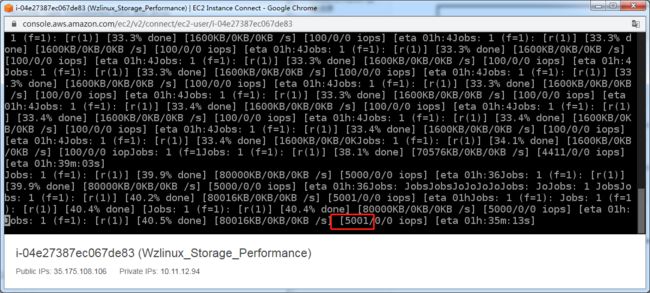
再去查看一下当前的 IOPS 如何。
登陆到 EC2 查看一下扩容之后的卷。
lsblk
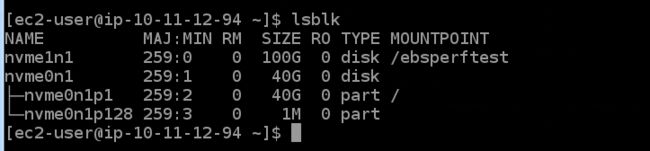
调整文件系统大小,才可以使用扩容之后的卷。
sudo umount /ebsperftest
sudo resize2fs /dev/nvme1n1
sudo mount /ebsperftest
查看一下当前的分区。
df -h

再去查看磁盘的监控情况,IOPS 已经达到 5000,因为换成了 io1,所以没有了 Burst balance 指标。

总结
通过增大磁盘的容量,可以提升磁盘的 IOPS。
gp2 磁盘的最大 IOPS 为 16000,让容量超过 5333GB 之后,IOPS 不会再增加。
如果容量比较小,但是又想获得更高的 IOPS,选择 io1。
gp2 磁盘容量低于 1000GB,可以突增到 3000 IOPS。
gp2 每 GB 获得 3 IOPS,io1 每 GB 获得 50 IOPS。
三、S3 Performance
3.1、优化大文件吞吐量
在本节中,我们将通过对大型对象拆分为更小的块并增加用于传输对象的线程数来演示大型对象的并行化传输。
登陆 EC2,然后配置 AWS CLI,因为我们赋予了 EC2 操作 S3 的角色,这里只需要配置好区域即可。
aws configure

使用 AWS CLI 进行一些 S3 的配置。
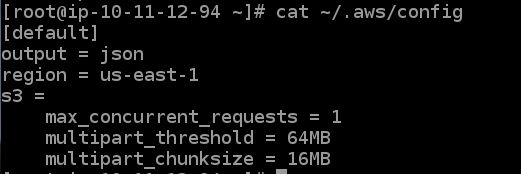
aws configure set default.s3.max_concurrent_requests 1
aws configure set default.s3.multipart_threshold 64MB
aws configure set default.s3.multipart_chunksize 16MB
查看配置好的参数信息。
cat ~/.aws/config
增加线程
使用下面命令创建一个 5 GB 的文件。
dd if=/dev/urandom of=5GB.file bs=1 count=0 seek=5G
使用 1 个线程把文件上传到 S3,并记录时间,在 CloudFormation 的 Outputs 里面可以看到我们的 S3 Bucket 的名称。
# 配置环境变量
bucket=storageperformanceworkshop-bucket01-z66if6h9nuco
time aws s3 cp 5GB.file s3://${bucket}/upload1.test

使用 2 个线程把文件上传到 S3,并记录时间。
aws configure set default.s3.max_concurrent_requests 2
time aws s3 cp 5GB.file s3://${bucket}/upload2.test

使用 10 个线程把文件上传到 S3,并记录时间。
aws configure set default.s3.max_concurrent_requests 10
time aws s3 cp 5GB.file s3://${bucket}/upload3.test

使用 20 个线程把文件上传到 S3,并记录时间。
aws configure set default.s3.max_concurrent_requests 20
time aws s3 cp 5GB.file s3://${bucket}/upload4.test

我们看到,在 10 个线程提升到 20 个线程后,传输速度并没有成倍提升。在某种程度上, AWS CLI 会限制所能达到的性能。这是一个 CLI 的限制,如果我们使用其他的传输软件将线程数增加到 100 个,可以继续提高传输的性能。
拆分文件
使用下面的命令创建一个 1 GB 文件。
dd if=/dev/urandom of=1GB.file bs=1 count=0 seek=1G
数据也可以被拆分成多个部分,下一步讲演示如何使用多个源文件传输 5 GB 的数据。
并行上传五个 1 GB 的文件到 S3,-j 指定并行线程数量。
time seq 1 5 | parallel --will-cite -j 5 aws s3 cp 1GB.file s3://${bucket}/parallel/object{}.test

总结
工作负载可以通过将大型对象拆分为块或拥有较小的文件来实现并行化。
每个 PUT 的收费是每 1000 个请求 0.05 美元。当你把一个 5gb 的文件分成 16mb 的块时,结果是 313 个 PUT 而不是 1 个 PUT。从本质上讲,你可以把它看作是为了更快而付出的通行费。
3.2、优化 Sync 命令
这个小节,我们将使用 aws s3 sync 命令传输 2 GB 的数据,共计 2000 个文件。
登陆 EC2,使用 1 个线程 sync 数据。
aws configure set default.s3.max_concurrent_requests 1
time aws s3 sync /ebs/tutorial/data-1m/ s3://${bucket}/sync1/

使用 10 个线程 sync 数据。
aws configure set default.s3.max_concurrent_requests 10
time aws s3 sync /ebs/tutorial/data-1m/ s3://${bucket}/sync2/

3.3、优化小文件操作
这个练习将演示如何在移动小对象时增加每秒事务量(TPS)。
登陆到 EC2,创建一个表示对象 id 列表的文本文件。
seq 1 500 > object_ids
cat object_ids
创建一个 1 KB 的文件。
dd if=/dev/urandom of=1KB.file bs=1 count=0 seek=1K
使用 1 个线程上传 500 个 1KB 文件到 S3。
time parallel --will-cite -a object_ids -j 1 aws s3 cp 1KB.file s3://${bucket}/run1/{}
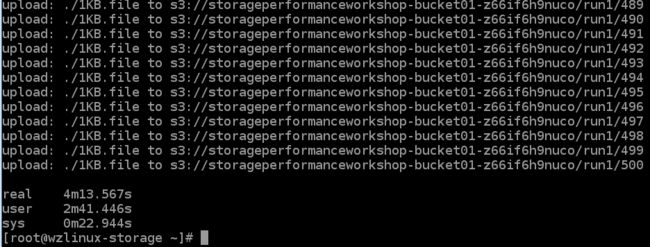
使用 10 个线程上传 500 个 1KB 文件到 S3。
time parallel --will-cite -a object_ids -j 10 aws s3 cp 1KB.file s3://${bucket}/run2/{}

使用 50 个线程上传 500 个 1KB 文件到 S3。
time parallel --will-cite -a object_ids -j 50 aws s3 cp 1KB.file s3://${bucket}/run3/{}

使用 100 个线程上传 500 个 1KB 文件到 S3。
time parallel --will-cite -a object_ids -j 100 aws s3 cp 1KB.file s3://${bucket}/run4/{}

总结
从 50 个线程增加到 100 个线程可能不会带来更高的性能。为了便于演示,我们使用 AWS CLI 的多个实例来显示一个概念。在现实世界中,开发人员将创建比我们的演示方法更有效的线程池。可以合理地假设,添加的线程应该继续增加性能,直到出现类似 CPU 耗尽的另一个瓶颈。
3.4、优化将对象复制到不同位置
在本练习中,我们将演示如何更有效地将文件从 S3中的一个位置复制到另一个位置。
从之前上传到 S3 的文件,下载一个 5 GB 文件下来,然后添加一个前缀在上传到 S3。
time (aws s3 cp s3://$bucket/upload1.test 5GB.file; aws s3 cp 5GB.file s3://$bucket/copy/5GB.file)

使用 PUT COPY(copy-object) 来移动文件。
time aws s3api copy-object --copy-source $bucket/upload1.test --bucket $bucket --key copy/5GB-2.file

使用 s3 copy 在不同位置直接拷贝文件。
time aws s3 cp s3://$bucket/upload1.test s3://$bucket/copy/5GB-3.file

总结
第一个命令需要将来自 S3 的数据返回到 EC2 实例,然后将数据从 EC2 实例返回到 S3。
第二个命令使用 PUT COPY,但是只有单线程。
第三个命令也使用了 PUT COPY,但是也使用了传输管理器,它是多线程的,这取决于 AWS CLI 配置。
第二个和第三个命令在 S3 内部的 S3 位置之间执行复制。这导致只有来自 EC2 主机的 API 调用,数据传输带宽仅在 S3内部完成。
四、EFS Performance
4.1、优化 IOPS
在这个练习中,我们将演示创建1024 个文件的不同方法,并比较每个方法的性能。
登陆到 EC2,使用下面命令创建 1024 个空文件。
directory=$(echo $(uuidgen)| grep -o ".\\{6\\}$")
mkdir -p /efs/tutorial/touch/${directory}
time for i in {1..1024}; do
touch /efs/tutorial/touch/${directory}/test-1.3-$i;
done;

使用多线程命令创建 1024 个空文件。
directory=$(echo $(uuidgen)| grep -o ".\\{6\\}$")
mkdir -p /efs/tutorial/touch/${directory}
time seq 1 1024 | parallel --will-cite -j 128 touch /efs/tutorial/touch/${directory}/test-1.4-{}

多线程在多个目录下创建 1024 个空文件。
directory=$(echo $(uuidgen)| grep -o ".\\{6\\}$")
mkdir -p /efs/tutorial/touch/${directory}/{1..32}
time seq 1 32 | parallel --will-cite -j 32 touch /efs/tutorial/touch/${directory}/{}/test1.5{1..32}

总结
利用 Amazon EFS 的分布式数据存储设计的最佳方法是并行使用多个线程和 inodes。
4.2、I/O Sizes 和 Sync Frequency
在这个练习中,我们将演示不同的 I/O 大小和同步频率如何影响 EFS 的吞吐量。
使用1 MB 的块大小写一个2 GB 的文件到 EFS,每个文件后同步一次。
time dd if=/dev/zero of=/efs/tutorial/dd/2G-dd-$(date +%Y%m%d%H%M%S.%3N) bs=1M count=2048 status=progress conv=fsync

使用16 MB 的块大小写一个2 GB 的文件到 EFS,每个文件后同步一次。
time dd if=/dev/zero of=/efs/tutorial/dd/2G-dd-$(date +%Y%m%d%H%M%S.%3N) bs=16M count=128 status=progress conv=fsync

使用1 MB 的块大小写一个2 GB 的文件到 EFS,每个块后同步一次。
time dd if=/dev/zero of=/efs/tutorial/dd/2G-dd-$(date +%Y%m%d%H%M%S.%3N) bs=1M count=2048 status=progress oflag=sync

使用16 MB 的块大小写一个2 GB 的文件到 EFS,每个块后同步一次。
time dd if=/dev/zero of=/efs/tutorial/dd/2G-dd-$(date +%Y%m%d%H%M%S.%3N) bs=16M count=128 status=progress oflag=sync

总结
在每个块之后进行同步将大大降低文件系统的性能。
每个文件后进行同步将获得最好的性能。
块大小对性能影响不大。
4.3、多线程性能
本练习将演示多线程访问如何提高吞吐量和 IOPS。
每个命令将使用 1MB 大小的块写一个 2GB 的文件到 EFS。
使用 4 个线程,每个块之后同步写入到 EFS。
time seq 0 3 | parallel --will-cite -j 4 dd if=/dev/zero of=/efs/tutorial/dd/2G-dd-$(date +%Y%m%d%H%M%S.%3N)-{} bs=1M count=512 oflag=sync

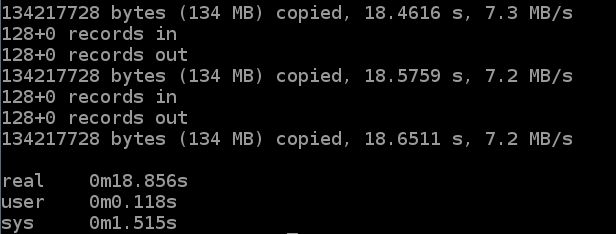
使用 16 个线程,每个块之后同步写入到 EFS。
time seq 0 15 | parallel --will-cite -j 16 dd if=/dev/zero of=/efs/tutorial/dd/2G-dd-$(date +%Y%m%d%H%M%S.%3N)-{} bs=1M count=128 oflag=sync
总结
EFS 的分布式数据存储设计意味着多线程应用程序可以驱动大量的聚合吞吐量和 IOPS。
通过增加线程数量并行化对 EFS 的写操作,可以提高总吞吐量和 IOPS 到 EFS。
4.4、比较文件传输工具
在本节中,我们将比较不同的文件传输实用程序和 EFS 的性能。
查看上传的 2000 个文件和 2 GB 数据。
du -csh /ebs/tutorial/data-1m/
find /ebs/tutorial/data-1m/. -type f | wc -l

使用 rsync 把文件从 EFS 传到 EFS。
sudo su
sync && echo 3 > /proc/sys/vm/drop_caches
exit
time rsync -r /ebs/tutorial/data-1m/ /efs/tutorial/rsync/

使用 cp 把文件从 EFS 传到 EFS。
sudo su
sync && echo 3 > /proc/sys/vm/drop_caches
exit
time cp -r /ebs/tutorial/data-1m/* /efs/tutorial/cp/

设置每个 CPU 四个线程。
threads=$(($(nproc --all) * 4))
echo $threads
使用 fpsync 把文件从 EFS 传到 EFS。
sudo su
sync && echo 3 > /proc/sys/vm/drop_caches
exit
time fpsync -n ${threads} -v /ebs/tutorial/data-1m/ /efs/tutorial/fpsync/
使用 cp + GUN Parallel 把文件从 EFS 传到 EFS。
sudo su
sync && echo 3 > /proc/sys/vm/drop_caches
exit
time find /ebs/tutorial/data-1m/. -type f | parallel --will-cite -j ${threads} cp {} /efs/tutorial/parallelcp

总结
并非所有文件传输工具都是相同的。
文件系统分布在数量不受限制的存储服务器上,这种分布式数据存储设计意味着,与单线程应用程序相比,多线程应用程序如 fpsync、 mcp 和 GNU 并行程序可以提高大量的吞吐量和 IOPS 到 EFS。
五、清理资源
删除 S3 的数据。
aws configure set default.s3.max_concurrent_requests 20
aws s3 rm s3://${bucket} --recursive
删除我们创建的 CloudFormation stack。