ES 7.X 做类百度搜索,进行搜索自动补全和热搜词及拼音功能实现
文章目录
- 前言
- 一、如何使用ES做类似百度的检索?
- 二、全文检索自动补齐
-
- 1.创建索引
- 2.添加数据
- 3.高级检索
- 三 热搜词
-
- 1.思路
- 2.DSL语句
- 3.java代码实现
- 四 拼音补全
- 1.DSL语法
- 2.java代码实现
- 总结
前言
前面讲了springboot集成ES的两种方法和es简单的增删改查,那么针对高级检索,es在7.x推荐的restclinet采用的查询方式需要了解del语言格式,那么今天来简单对dsl语言转化成java代码进行一个学习
一、如何使用ES做类似百度的检索?
1.先来回想一下,百度搜索的风格,在进行百度搜索时,百度首页会出现一个热搜词

2.在使用搜索框搜索时,会进行搜索补全
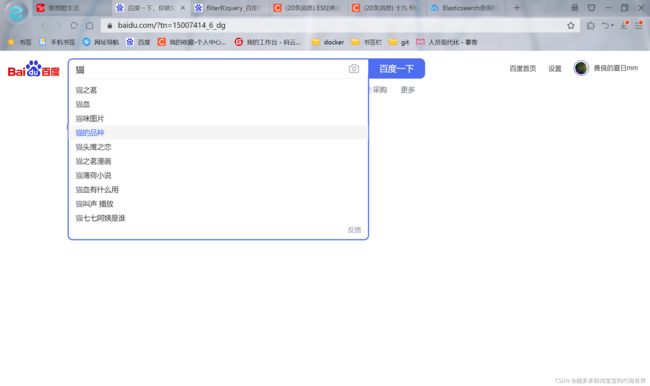
3.使用拼音可以进行检索

二、全文检索自动补齐
1.创建索引
一般来说,输入框提示出来的词都是经常被搜索的词,所以全文检索检索的是对应的热搜词的索引。
1.创建索引,并且为了后续做拼音检索,应该对检索的fileName字段采用拼音分词器分词和ik分词器两种分词方式。但是这儿的hot词使用的是keyword,不能进行拼音分词。
猜想:fileds可以设置多个字段,这个后面找时间来验证
{
"properties": {
"createTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss || yyyy-MM-dd || yyyy/MM/dd HH:mm:ss|| yyyy/MM/dd ||epoch_millis"
},
"searchInput": {
"type": "completion",
"analyzer": "ik_max_word",
"fields": {
"hot": {
"type": "keyword" //用于热搜词
}
}
}
}
}
猜想结构:
{
"properties": {
"createTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss || yyyy-MM-dd || yyyy/MM/dd HH:mm:ss|| yyyy/MM/dd ||epoch_millis"
},
"searchInput": {
"type": "completion",
"analyzer": "ik_max_word",
"fields": {
"hot": {
"type": "keyword" //用于热搜词
},
"hot-py":{
"type": "text",
"term_vector": "with_positions_offsets",
"analyzer": "pinyin_analyzer", //用于热搜拼音
"boost": 10.0
}
}
}
}
}
2.添加数据
我是使用封装的工具类进行的添加数据,当然可以使用repository使用
/**
* 新增数据,自定义id
*
* @param object 要增加的数据
* @param index 索引,类似数据库
* @param id 数据ID,为null时es随机生成
* @return
*/
public String addData(Object object, String index, String id) throws IOException {
if (null == id) {
return addData(object, index);
}
if (this.existsById(index, id)) {
return this.updateDataByIdNoRealTime(object, index, id);
}
//创建请求
IndexRequest request = new IndexRequest(index);
request.id(id);
request.timeout(TimeValue.timeValueSeconds(1));
//将数据放入请求 json
request.source(JSON.toJSONString(object), XContentType.JSON);
//客户端发送请求
IndexResponse response = restHighLevelClient.index(request, RequestOptions.DEFAULT);
log.info("添加数据成功 索引为: {}, response 状态: {}, id为: {}", index, response.status().getStatus(), response.getId());
return response.getId();
}
3.高级检索
1.自动补全功能在es中是提供了这个功能的,需要定义查询对象 SuggestBuilder ,suggest类型下有几种类型:
suggest term: 根据 编辑距离(edit distance) 给出提示、建议,给出的结果是单个词
suggest phrase: 在Term suggester的基础上,会考量多个term之间的关系,比如是否同时出现在索引的原文里,相邻程度,以及词频等等。给出的结果是一个句子
suggest completion: 定义特殊字段,用于提示不全。字段type需要定义为:completion, 数据会编码成FST,索引一起存放,FST都会加载到内存中。只能用于前缀补全。
DSL查询语句demo
{
"suggest": {
"suggest": {
"prefix": "猫",
"completion": {
"field": "search_input.hot",
"size": 10
}
}
}
}
suggest:代表接下来的查询是一个suggest类型的查询
suggest:这次查询的名称,自定义
prefix:用来补全的词语前缀,本例中搜索以 猫开头的内容
completion:代表是completion类型的suggest,其它类型还有:Term、Phrase
field:要查询的字段
2.java代码实现
@Override
public Set getSearchSuggest(Integer pageSize,String key){
//定义suggest对象
SuggestBuilder suggestBuilder = new SuggestBuilder();
//定义本次查询名字SEARCH_INPUT = suggest,设置prefix 补齐前缀,查询个数pagesize个,skipDuplicates去除重复数据
CompletionSuggestionBuilder suggestion = SuggestBuilders
.completionSuggestion(SEARCH_INPUT).prefix(key).size(pageSize).skipDuplicates(true);
suggestBuilder.addSuggestion(SEARCH_SUGGEST,suggestion);
SearchRequest request = new SearchRequest().indices(ESConst.HOT_KEY_INDEX).source(new SearchSourceBuilder().suggest(suggestBuilder));
//可以通过设置searchsourcebuilder来设置_source过滤字段
SearchResponse searchResponse = null;
try {
searchResponse = restHighLevelClient.search(request, RequestOptions.DEFAULT);
System.out.println(searchResponse);
} catch (IOException e) {
e.printStackTrace();
}
Suggest suggest = searchResponse.getSuggest();
Set<String> keywords = null;
if (suggest != null) {
keywords = new HashSet<>();
List<? extends Suggest.Suggestion.Entry<? extends Suggest.Suggestion.Entry.Option>> entries = suggest.getSuggestion(SEARCH_SUGGEST).getEntries();
for (Suggest.Suggestion.Entry<? extends Suggest.Suggestion.Entry.Option> entry: entries) {
for (Suggest.Suggestion.Entry.Option option: entry.getOptions()) {
/** 最多返回9个推荐,每个长度最大为20 */
String keyword = option.getText().string();
if (!StringUtils.isEmpty(keyword) && keyword.length() <= 20) {
/** 去除输入字段 */
if (keyword.equals(key)) continue;
keywords.add(keyword);
if (keywords.size() >= pageSize) {
break;
}
}
}
}
}
return keywords;
}
自此,可以简单的得到检索时的补全词汇集合;当然也可以设置纠错词汇,只需要修改suggest对象类型。
三 热搜词
1.思路
热搜词的关键在于,需要查询什么。一般来说热搜词为数量最多的词。所以,我在全文检索时对流媒体进行查询时,会写一个切面类,在查询之前,将输入框中的词保存到es的热搜词索引中。那么就简单,我们只需要对hot-key的索引进行分组查询,算出个数最多的词进行排序。
2.DSL语句
es中的aggregations聚合,相当于SQL中的group by
es聚合分为四种方式:指标聚合,桶聚合,矩阵聚合,管道聚合。
单个分组用指标聚合,terms相当于分组后统计各组的count结果
"aggs": {
"hot_count" : {
"terms" : {
"field" : "search_input.hot"
}
}
}
3.java代码实现
@Override
public List<Map<String, Object>> getHotKey(Integer pageSize,String type) {
SearchRequest searchRequest = new SearchRequest(ESConst.HOT_KEY_INDEX);
//构建搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//select keyword, count(*) as hot_count from hot-key group by keyword; -- > 分组
TermsAggregationBuilder aggregationBuilder = AggregationBuilders.terms(HOT_COUNT).field(SEARCH_INPUT+".hot");
//不需要解释
sourceBuilder.explain(false);
//不需要原始数据
sourceBuilder.fetchSource(false);
//不需要版本号
sourceBuilder.version(false);
sourceBuilder.aggregation(aggregationBuilder);
RangeQueryBuilder rangeQueryBuilder = null;
switch (type){
case ESConst.MONTH: rangeQueryBuilder = QueryBuilders.rangeQuery("createTime").gte(LocalDateTime.now().minusMonths(1).format(formatter)).lte(LocalDateTime.now().format(formatter));
break;
case ESConst.WEEK: rangeQueryBuilder = QueryBuilders.rangeQuery("createTime").gte(LocalDateTime.now().minusWeeks(1).format(formatter)).lte(LocalDateTime.now().format(formatter));
break;
case ESConst.DAY: rangeQueryBuilder = QueryBuilders.rangeQuery("createTime").gte(LocalDateTime.now().minusDays(1).format(formatter)).lte(LocalDateTime.now().format(formatter));
break;
default: rangeQueryBuilder = QueryBuilders.rangeQuery("createTime").gte(LocalDateTime.now().minusDays(1).format(formatter)).lte(LocalDateTime.now().format(formatter));
break;
}
//时间范围
sourceBuilder.query(rangeQueryBuilder);
searchRequest.source(sourceBuilder);
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(searchResponse);
Terms terms = searchResponse.getAggregations().get(HOT_COUNT);
List<Map<String,Object>> result = new ArrayList<>();
for (Terms.Bucket bucket : terms.getBuckets()) {
Map<String, Object> map = new HashMap<>();
map.put("hotKey", bucket.getKeyAsString());
map.put("hotValue",bucket.getDocCount());
result.add(map);
}
return result;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
四 拼音补全
下面的代码还未经过测试,只是我想象的使用方法,后面我会进行尝试
1.DSL语法
{
"suggest": {
"suggest": {
"prefix": "猫",
"completion": {
"field": "suggestion",
"size": 10
}
},
"py_suggest":{
"prefix": "maohe",
"completion": {
"field": "search_input.py-hot",
"size": 10
}
}
}
}
因为searchinput字段在创建时mapping映射了两种分词,所以我想,在后面加一个查询条件应该没有问题
2.java代码实现
在原有的java代码基础上,在其中添加对应的py_suggest自定义字段的查询
/*尝试拼音补全*/
CompletionSuggestionBuilder pysuggestion = SuggestBuilders
.completionSuggestion(SEARCH_INPUT+".hot-py")
.prefix(key)
.size(pageSize)
.skipDuplicates(true);
suggestBuilder.addSuggestion("py_suggest",pysuggestion);
/*------------------*/
总结
dsl语言不用记住,当需要使用的时候进行百度,只需要知道es中对象创建和处理遵循的dsl语言的结构便可以写出java代码