Flex 词法分析实验实现(电子科技大学编译技术Icoding实验)
Flex 词法分析
此为电子科技大学编译技术 实验1:词法分析
将具体实现中的三个文件和自己的实验报告一起上传才能通过
根据词法分析实验中给定的文法,利用 flex 设计一词法分析器,该分析器从标准输入读入源代码后,输出单词的类别编号及附加信息。 附加信息规定如下: 当类别为 Y_ID、num_INT 或 num_FLOAT 时,附加信息为该类别对应的属性,如 main, 100, 29.3等; 当类别为 关键字 时,附件信息为 KEYWORD; 当类别为 运算符 时,附件信息为 OPERATOR; 当类别为 其它符号时,附件信息为 SYMBOL
单词类别的定义:
enum yytokentype {
num_INT = 258,
num_FLOAT = 259,
Y_ID = 260,
Y_INT = 261,
Y_VOID = 262,
Y_CONST = 263,
Y_IF = 264,
Y_ELSE = 265,
Y_WHILE = 266,
Y_BREAK = 267,
Y_CONTINUE = 268,
Y_RETURN = 269,
Y_ADD = 270,
Y_SUB = 271,
Y_MUL = 272,
Y_DIV = 273,
Y_MODULO = 274,
Y_LESS = 275,
Y_LESSEQ = 276,
Y_GREAT = 277,
Y_GREATEQ = 278,
Y_NOTEQ = 279,
Y_EQ = 280,
Y_NOT = 281,
Y_AND = 282,
Y_OR = 283,
Y_ASSIGN = 284,
Y_LPAR = 285,
Y_RPAR = 286,
Y_LBRACKET = 287,
Y_RBRACKET = 288,
Y_LSQUARE = 289,
Y_RSQUARE = 290,
Y_COMMA = 291,
Y_SEMICOLON = 292,
Y_FLOAT = 293
};
例如对于源代码
int main(){
return 3;
}
词法分析器的输出为:
<261, KEYWORD>
<260, main>
<285, SYMBOL>
<286, SYMBOL>
<287, SYMBOL>
<269, KEYWORD>
<258, 3>
<292, SYMBOL>
<288, SYMBOL>
1 具体实现
以下具体实现分为了三个文件 —— token.h,lexer.l,lexer_main.c
当然你也可以直接写成一个 .l 文件,具体看补充
1.1 头文件 token.h
创建一个头文件 token.h,定义了词法分析器中所需的标记类型和附加信息的数据结构;这个头文件中包含了枚举 yytokentype,定义了各种标记类型的类别编号,以及一个联合 _YYLVAL,用于存储附加信息,具体代码如下:
#ifndef TOKEN_H
#define TOKEN_H
enum yytokentype {
num_INT = 258,
num_FLOAT = 259,
Y_ID = 260,
Y_INT = 261,
Y_VOID = 262,
Y_CONST = 263,
Y_IF = 264,
Y_ELSE = 265,
Y_WHILE = 266,
Y_BREAK = 267,
Y_CONTINUE = 268,
Y_RETURN = 269,
Y_ADD = 270,
Y_SUB = 271,
Y_MUL = 272,
Y_DIV = 273,
Y_MODULO = 274,
Y_LESS = 275,
Y_LESSEQ = 276,
Y_GREAT = 277,
Y_GREATEQ = 278,
Y_NOTEQ = 279,
Y_EQ = 280,
Y_NOT = 281,
Y_AND = 282,
Y_OR = 283,
Y_ASSIGN = 284,
Y_LPAR = 285,
Y_RPAR = 286,
Y_LBRACKET = 287,
Y_RBRACKET = 288,
Y_LSQUARE = 289,
Y_RSQUARE = 290,
Y_COMMA = 291,
Y_SEMICOLON = 292,
Y_FLOAT = 293
};
typedef union _YYLVAL{
int token;
int int_value;
float float_value;
char* id_name;
}_YYLVAL;
#endif //TOKEN_H
1.2 Flex文件 lexer.l
创建Flex规则文件 lexer.l,其中包含词法分析器的规则定义:
-
注释处理:规则中包括了处理注释的规则
(\/\/.*\n)|(\/\*.*\*\/),可以将注释从源代码中过滤掉 -
十六进制整数:规则可以成功地识别十六进制整数,例如
0x10 -
标识符:规则中有处理标识符的规则,注意,使用了
strdup(yytext)来为标识符分配内存。这会为每个标识符创建一个新的动态分配的字符串,要确保在适当的时候释放这些字符串以避免内存泄漏 -
操作符:规则包括处理各种操作符的规则
-
浮点数:规则可以成功地识别浮点数,但需要注意浮点数的格式。当前规则要求小数点前面至少有一个数字,例如
0.1,而不支持.1这种形式 -
数值的存储:规则中将整数存储为
yylval.int_value,浮点数存储为yylval.float_value
具体代码:
%{
#include "token.h"
%}
_YYLVAL yylval;
%%
[ \t\n] ;
(\/\/.*\n)|(\/\*.*\*\/) ;
int { return Y_INT; }
float { return Y_FLOAT; }
void { return Y_VOID; }
const { return Y_CONST; }
if { return Y_IF; }
else { return Y_ELSE; }
while { return Y_WHILE; }
break { return Y_BREAK; }
continue { return Y_CONTINUE; }
return { return Y_RETURN; }
"+" { return Y_ADD; }
"-" { return Y_SUB; }
"*" { return Y_MUL; }
"/" { return Y_DIV; }
"%" { return Y_MODULO; }
"<" { return Y_LESS; }
"<=" { return Y_LESSEQ; }
">" { return Y_GREAT; }
">=" { return Y_GREATEQ; }
"!=" { return Y_NOTEQ; }
"==" { return Y_EQ; }
"!" { return Y_NOT; }
"&&" { return Y_AND; }
"||" { return Y_OR; }
"=" { return Y_ASSIGN; }
"(" { return Y_LPAR; }
")" { return Y_RPAR; }
"{" { return Y_LBRACKET; }
"}" { return Y_RBRACKET; }
"[" { return Y_LSQUARE; }
"]" { return Y_RSQUARE; }
"," { return Y_COMMA; }
";" { return Y_SEMICOLON; }
[0-9]+ { yylval.int_value = atoi(yytext); return num_INT; }
[0-9]*\.[0-9]+ { yylval.float_value = atof(yytext); return num_FLOAT; }
[a-zA-Z_][a-zA-Z0-9_]* { yylval.id_name = strdup(yytext); return Y_ID; }
0x[0-9a-fA-F]+ { yylval.int_value = strtol(yytext, NULL, 16); return num_INT; }
%%
1.3 main函数文件 lexer_main.c
创建main函数文件 lexer_main.c ,它将从词法分析器接收的标记类型和附加信息输出为类别编号和附加信息
-
#include部分包含了标准输入输出头文件和自定义的 token.h 头文件 -
extern int yylex();和extern _YYLVAL yylval;声明了从词法分析器生成的函数和变量 -
while((token = yylex()) != 0)循环调用yylex()函数来获取标记,直到返回值为 0 表示词法分析结束 -
在循环内部,根据标记的类型进行相应的打印输出。对于标识符、整数和浮点数,使用
yylval结构中相应的成员来获取值 -
根据标记类型的范围,将其分类为关键字、运算符或其他符号,并打印相应的输出
-
使用了
free()函数来释放在标识符规则中动态分配的yylval.id_name内存,以避免内存泄漏
具体代码:
#include \n" );
break;
}
}
else{
if(token <= 269 || token == 293) {
char words[10] = "KEYWORD";
printf("<%d, %s>\n", token, words);
}else if(token <= 284) {
char words[10] = "OPERATOR";
printf("<%d, %s>\n", token, words);
}else if(token <= 292) {
char words[10] = "SYMBOL";
printf("<%d, %s>\n", token, words);
}else{
printf("\n" );
}
}
}
return 0;
}
Icoding:将以上三个文件+实验报告上传即可
2 运行测试
在虚拟机上(我的是 VMware + Ubuntu22.04.3)进行的测试
在这三个文件的目录下,执行:
-
使用 Flex 编译 test.l 文件,这将生成 lex.yy.c 文件,其中包含词法分析器的C代码
flex test.l -
使用 GCC 编译 lex.yy.c 和 lexer_main.c,并生成可执行文件 test,在这一步,使用
-lfl标志来链接 Flex 库gcc lex.yy.c lexer_main.c -o test -lfl -
运行生成的可执行文件 test,并通过标准输入
<重定向输入测试文件 test1.sy,从而进行词法分析./test < test1.sy
测试文件 test1.sy:
// test if-else-if
int ifElseIf() {
int a;
a = 5;
int b;
b = 10;
if(a == 6 || b == 0xb) {
return a;
}
else {
if (b == 10 && a == 1)
a = 25;
else if (b == 10 && a == -5)
a = a + 15;
else
a = -+a;
}
return a;
}
int main(){
putint(ifElseIf());
return 0;
}
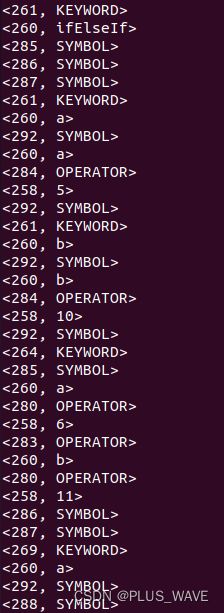
运行结果部分展示:
3 补充
可以直接写成一个 .l 文件,如下 lexer.l:
%{
enum yytokentype {
num_INT = 258,
num_FLOAT = 259,
Y_ID = 260,
Y_INT = 261,
Y_VOID = 262,
Y_CONST = 263,
Y_IF = 264,
Y_ELSE = 265,
Y_WHILE = 266,
Y_BREAK = 267,
Y_CONTINUE = 268,
Y_RETURN = 269,
Y_ADD = 270,
Y_SUB = 271,
Y_MUL = 272,
Y_DIV = 273,
Y_MODULO = 274,
Y_LESS = 275,
Y_LESSEQ = 276,
Y_GREAT = 277,
Y_GREATEQ = 278,
Y_NOTEQ = 279,
Y_EQ = 280,
Y_NOT = 281,
Y_AND = 282,
Y_OR = 283,
Y_ASSIGN = 284,
Y_LPAR = 285,
Y_RPAR = 286,
Y_LBRACKET = 287,
Y_RBRACKET = 288,
Y_LSQUARE = 289,
Y_RSQUARE = 290,
Y_COMMA = 291,
Y_SEMICOLON = 292,
Y_FLOAT = 293
};
typedef union _YYLVAL{
int token;
int int_value;
float float_value;
char* id_name;
}_YYLVAL;
%}
_YYLVAL yylval;
%%
[ \t\n] ;
(\/\/.*\n)|(\/\*.*\*\/) ;
int { return Y_INT; }
float { return Y_FLOAT; }
void { return Y_VOID; }
const { return Y_CONST; }
if { return Y_IF; }
else { return Y_ELSE; }
while { return Y_WHILE; }
break { return Y_BREAK; }
continue { return Y_CONTINUE; }
return { return Y_RETURN; }
"+" { return Y_ADD; }
"-" { return Y_SUB; }
"*" { return Y_MUL; }
"/" { return Y_DIV; }
"%" { return Y_MODULO; }
"<" { return Y_LESS; }
"<=" { return Y_LESSEQ; }
">" { return Y_GREAT; }
">=" { return Y_GREATEQ; }
"!=" { return Y_NOTEQ; }
"==" { return Y_EQ; }
"!" { return Y_NOT; }
"&&" { return Y_AND; }
"||" { return Y_OR; }
"=" { return Y_ASSIGN; }
"(" { return Y_LPAR; }
")" { return Y_RPAR; }
"{" { return Y_LBRACKET; }
"}" { return Y_RBRACKET; }
"[" { return Y_LSQUARE; }
"]" { return Y_RSQUARE; }
"," { return Y_COMMA; }
";" { return Y_SEMICOLON; }
[0-9]+ { yylval.int_value = atoi(yytext); return num_INT; }
[0-9]*\.[0-9]+ { yylval.float_value = atof(yytext); return num_FLOAT; }
[a-zA-Z_][a-zA-Z0-9_]* { yylval.id_name = strdup(yytext); return Y_ID; }
0x[0-9a-fA-F]+ { yylval.int_value = strtol(yytext, NULL, 16); return num_INT; }
%%
int main(int argc, char **argv) {
int token;
while((token = yylex()) != 0) {
if(token <= 260){
switch (token) {
case Y_ID:
printf("<%d, %s>\n", token, yylval.id_name);
free(yylval.id_name);
break;
case num_INT:
printf("<%d, %d>\n", token, yylval.int_value);
break;
case num_FLOAT:
printf("<%d, %f>\n", token, yylval.float_value);
break;
default:
printf("\n" );
break;
}
}
else{
if(token <= 269 || token == 293) {
char words[10] = "KEYWORD";
printf("<%d, %s>\n", token, words);
}else if(token <= 284) {
char words[10] = "OPERATOR";
printf("<%d, %s>\n", token, words);
}else if(token <= 292) {
char words[10] = "SYMBOL";
printf("<%d, %s>\n", token, words);
}else{
printf("\n" );
}
}
}
return 0;
}
此时只需要执行以下即可测试:
-
flex lexer.l -
gcc lex.yy.c -o test -lfl -
./test < test1.sy