KOSMOS-2.5:密集文本的多模态读写模型
Overview
-
- 总览
- 摘要
- 1 引言
- 2 KOSMOS-2.5
-
- 2.1 模型结构
- 2.1 图像和文本表征
- 2.3 预训练数据
- 2.4 数据处理
- 2.5 过滤与质量控制
- 3 实验
-
- 3.1 评估
- 3.2 实现细节
- 3.3 结果
- 3.4 讨论
- 4 相关工作
-
- 4.1 多模态大语言模型
- 4.2 图文理解
- 5 总结与展望
总览
题目: KOSMOS-2.5: A Multimodal Literate Model
机构:微软
论文: https://arxiv.org/pdf/2309.11419.pdf
代码: https://github.com/microsoft/unilm
任务: 密集文档类图像转录成结构化文本输出
特点: 同时支持产生具有空间感知的文本块和结构化的markdown文本
方法: 预训练的视觉编码器和一个与重采样模块连接的语言解码器组成
前置相关工作:Pix2Struct,KOSMOS-2,Flamingo
摘要
我们提出了KOSMOS-2.5,这是一个多模态读写模型,用于机器阅读文本密集型图像。KOSMOS-2.5在大规模文本密集型图像上进行预训练,擅长两个独立但协作的转录任务: (1)生成空间感知的文本块,每个文本块在图像内的位置都被赋予其空间坐标; (2)生成结构化文本输出,将样式和结构捕获到markdown格式。通过共享的Transformer架构、任务特定的提示和灵活的文本表示,我们实现了这种统一的多模态读写能力。我们对KOSMOS-2.5进行了文档级文本识别与图像到markdown文本生成的端对端评估。此外,通过监督精调,这个模型可以轻松地适应使用不同提示的任何文本密集型图像理解任务,使其成为涉及文本丰富图像的实际应用的通用工具。这项工作也为未来扩大多模态大语言模型铺平了道路。

图1:KOSMOS-2.5是一个多模态大型语言模型,它将文本图像作为输入,分别按照不同的任务提示生成具有边界框的空间感知文本或带有Markdown元素的Markdown格式文本。
1 引言
近年来,大型语言模型(LLMs)已在人工智能研究中成为关键领域。这些模型旨在从大量的自然语言数据中学习,使它们能够以令人印象深刻的精度执行各种语言相关的任务。这一发展是由模型规模的进步推动的,这使得研究人员可以创建具有空前复杂性的模型。因此,LLMs在各个行业和应用中变得越来越普遍,从客户服务聊天机器人到虚拟助手和自动化内容创建。近年来的显著趋势是专注于构建更大更复杂的模型,如GPT-3 [BMR+20] 和GPT-4 [Ope23],它们拥有数百/数千亿的参数,可以生成引人入胜的语言输出。尽管这些模型需要大量的计算资源进行训练和运行,但它们具有潜在的革命性的潜力,可能改变我们与自然语言的互动并理解自然语言的方式。
当前的LLMs主要关注文本信息,不能理解视觉信息。然而,多模态大型语言模型(MLLMs)领域的进步目标是解决这个局限性。MLLMs在一个基于Transformer的模型中结合了视觉和文本信息,使得模型可以根据两种模态来学习和生成内容。在包括自然图像理解和文本图像理解在内的各种实际应用中,MLLMs已经展示出很大的潜力。这些模型利用了作为多模态问题通用接口的语言建模的力量,使它们能够处理和根据文本和视觉输入生成响应。虽然现有的MLLMs主要关注分辨率较低的自然图像,但对文本图像的探索是一个需要进一步研究的领域。利用大规模多模态预训练来处理文本图像是MLLM研究的重要方向。通过将文本图像纳入训练过程并开发基于文本和视觉信息的模型,我们可以为涉及高分辨率文本密集型图像的多模态应用解锁新的可能性。
在这项研究中,我们提出了KOSMOS-2.5,这是一个多模态读写模型,利用了为解决文本密集型图像机器阅读问题而设计的KOSMOS- 2 [PWD+23],如图1所示。KOSMOS-2.5在一个统一的多模态模型中执行两个密切相关的转录任务。第一个任务生成具有空间感知的文本块,将文本行分配其在文本丰富的原始图像内的相应空间坐标。第二个任务产生结构化文本输出,捕获Markdown格式的样式和结构。这两个任务都在一个统一的框架下进行,利用共享的Transformer架构、任务特定提示和灵活的文本表示。具体来说,我们的模型架构结合了一个基于ViT的视觉编码器和一个由重采样模块连接的基于Transformer的语言解码器。我们的模型在一个包含具有边界框的文本行和简单markdown文本的文本表示的大型文本密集型图像语料库上进行了预训练。通过采用这种双任务训练策略,KOSMOS- 2.5增强了其通用的多模态读写能力。我们评估了KOSMOS-2.5在两个任务上的性能:端到端的文档级文本识别和markdown格式的图像到文本生成。实验结果在几个文本密集型图像理解任务上都展示了强大的读写性能。此外,KOSMOS-2.5也展示了在少量示例和零示例学习场景中的有前途的能力,为涉及文本丰富图像的实际应用提供了一个通用的接口。
这项工作的贡献总结如下:
- KOSMOS-2.5代表了文本图像理解领域的一个重要理念转变,从仅编码器(encoder only)/编码器-解码器(encoder-decoder)模型转变为仅解码器(decoder-only)模型。它通过整合双重转录任务(产生具有空间感知的文本块和结构化的markdown文本)到一个统一的模型架构中进行预训练。
- 这种创新方法通过整合生成性的多模态语言建模,简化了用于各种下游任务的传统复杂的级联工作流程,从而使应用接口变得更为流畅。
- 此外,KOSMOS-2.5展示出了令人印象深刻的多模态读写能力,为未来的多模态大型语言模型的扩展奠定了基础。
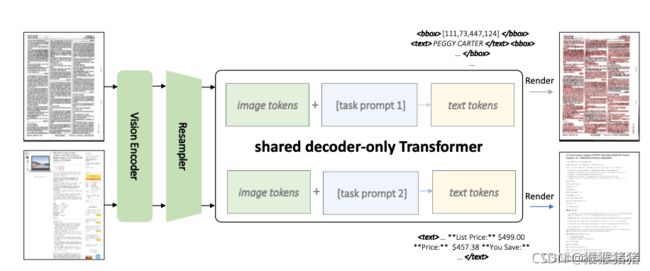
KOSMOS-2.5的模型架构。一个共享的仅解码器(decoder only)的Transformer模型基于来自视觉编码器的输入图像和不同的任务提示生成输出文本序列。
2 KOSMOS-2.5
2.1 模型结构
如图2所示,KOSMOS-2.5的模型架构由一个预训练的视觉编码器和一个与重采样模块连接的语言解码器组成。我们采用了基于视觉Transformer(ViT)[DBK+21]的预训练视觉编码器。我们进一步适应了一个配备有注意力池化机制的Perceiver重采样模块,以减小图像embedding的大小[ADL+22]。语言解码器基于Transformer的解码器建立,以便根据图像和文本上下文对下一个令牌进行预测。
2.1 图像和文本表征
KOSMOS-2.5接收由图像和文本表示组成的复合输入。图像表示在各种配置中保持统一,并利用跟随Pix2Struct [LJT+23]的可变分辨率输入策略。精确地说,我们提取可以在预定义的序列长度L内适应的最大数量的固定大小的补丁(16×16)。此外,使用重采样器[Flamingo ADL+22]作为注意力池化机制以减少图像嵌入的数量。然而,文本表示更为多样化,可以是两种类型之一:带有边界框的文本行或普通的markdown文本。
带有边界框的文本行:对于基于布局的文档表示,提取文本行及其关联的边界框。受KOSMOS-2 [PWD+23]的启发,我们将文本行定位在图像的空间位置,通过对齐其表示。然后,将这些边界框的坐标转换为离散的位置标记。考虑到L还表示每个图像维度的最大长度,我们引入了一组 2 L + 2 2L+2 2L+2的专门标记。这些标记, < x 0 > , < x 1 > , … , < x L − 1 > , < y 0 > , … , < y L − 1 > , < b b o x > 和 < / b b o x >
Markdown文本:对于基于标记的文档表示,其中输出文本以markdown格式出现,文本组件同时捕获内容和格式标记。与基于布局的文档不同,markdown文本不需要边界框。相反,文本直接被标记化,保留所有特殊字符和格式指示符。
为了适应这些多样化的输入类型,我们采用了不同的复合表示。对于带有文本行和边界框的图像-文本对,输入为 < s > < i m a g e > I m a g e E m b e d d i n g < / i m a g e > ∪ n = 1 N ( B n ⊕ T n ) < / s > <s>和 < / s > </s>标示序列的边界, < i m a g e >
2.3 预训练数据
预训练过程使KOSMOS-2.5能够学习适用于各种文本密集型图像理解任务的多功能表示。该模型在来自不同来源的丰富数据集上进行预训练。传统的光学字符识别(OCR)任务主要是生成图像中的文本内容及其2D位置。然而,它们常常忽视了保持原始文档的顺序和结构完整性的需要,这对涉及结构化信息的文本密集型(text-intensive)图像理解任务至关重要。
为了解决这个问题,我们引导 KOSMOS-2.5 在两个不同但协作的转录任务中表现优秀:
- 生成具有空间意识的文本块,其中每个文本块在图像内被分配了其空间坐标。
- 产生的结构化文本输出可以捕获到markdown格式中的样式和结构。与普通文本相比,在如下方面具有优势,Markdown通过明确区分不同的结构元素(如表格和列表)并使用特定的标记。例如,表格的单元格可以用竖线(|)表示,列表项用子弹(*,-,或+)表示。它也规范了排版强调(如粗体(粗体)和斜体(斜体))的表示,将文档结构的学习和自然语言理解集成在一个统一的模型中。
对于具有空间感知的文本块,我们使用:
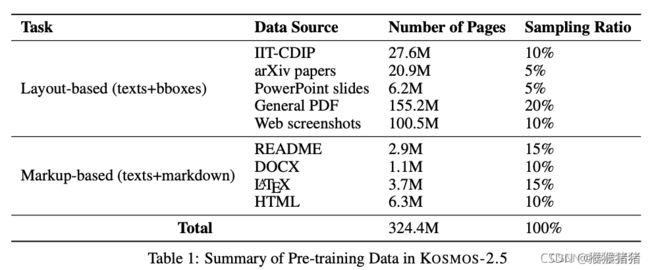
- IIT-CDIP:IIT-CDIP数据集是一个大规模的公共集合,包含了扫描的文档图像。我们使用大约 2760 万页来训练我们的模型。
- arXiv 论文:arXiv 是一个开放获取的研究共享平台,提供了另一个重要的数据源,约为 2090 万页。我们下载了大量数据,从https://info.arxiv.org/help/bulk_data/index.html官方下载了PDF以及其latex源文件。
- PowerPoint 幻灯片:从包含 PowerPoint 文档的各种网页中收集了约 620 万页的语料库,大大增强了我们的训练数据的多样性。
- 通用PDF:此外,我们在网上爬取了不同开放领域的数字PDF文件,收集了大约 1.552 亿页的大规模语料库。
- 网页屏幕截图:scraped并 渲染了几乎包含 1 亿页的 mC4 网页的子集的屏幕截图。
对于以markdown格式输出的结构化文本,我们使用:
- README: 我们收集了来自开源GitHub项目的290万个"README.md"文件,主要以markdown格式书写。
- DOCX: 我们还从网络上爬取了数以百万计的WORD 文件,从中提取出110万页的DOCX页面。 DOCX页面被转换为markdown格式,每个页面对应其markdown信息。
- LATEX: 我们使用了整个arXiv论文的一个子集,从中提取出PDF页面和其对应的从LaTex代码转换的markdown信息,总共包含370万页。 •
- HTML:我们从上述的mC4子集中获得了630万个HTML文件,并将它们转换为markdown格式。
2.4 数据处理
预训练数据覆盖面广,每种类型的数据都需要不同的处理流程,如下所示:
- IIT-CDIP IIT-CDIP 数据集主要包含扫描的文档图像。我们使用 Microsoft Read API来提取文本和布局信息。
- arXiv 论文,PowerPoint 幻灯片,通用 PDF 我们首先将 arXiv 论文和 PowerPoint 幻灯片编译和转换为 PDF 文件。我们使用 PyMuPDF 解析器 高效地提取文本和布局信息。
- 网页截图 我们也在模型预训练中包含网页截图,以进一步多样化布局分布。我们从mC4数据集的英文部分收集网页URL。使用Playwright访问指定的URL并打开网页。使用 lxml 库提取并解析页面的HTML内容,以获取文档对象模型(DOM)树表示。对这个 DOM 树进行遍历,检查其中每个元素的 XPath。这个遍历过程的目的是确定每个元素是否可见,并获取其边界框的信息。
- README(markdown) 除了基于布局的数据外,我们还收集了基于标记的数据进行预训练。我们收集了许多 GitHub 项目的 “README.md” 文件并用Pandoc将这些文件转换为HTML。然后,用wkhtmltopdf来将生成的HTML内容转化为图像。
- DOCX(markdown) Microsoft Office WORD 文件已在现有研究中得到广泛使用,如 TableBank [LCH+20] 和 ReadingBank [WXC+21]。我们收集 WORD DOCX 文件,并将它们转换为带 markdown 的文本。首先,我们使用 Pandoc 将 DOCX 文件中的 XML 内容转换为 markdown 文件。由于 Pandoc 在生成的 markdown 中保留了 “” 标签来表示表格单元格,我们进一步识别出所有的表格,并使用 markdownify将它们转换为 markdown 格式。最后,将原来的 DOCX 文件转换为 PDF 文件,并根据启发式方法将每一页对齐到 markdown 内容的相应范围。
- LATEX(markdown) 来自 arXiv 的 LATEX 文档已被用来生成 PDF 文件,以获取带有边界框的文本。同时,我们也将 LATEX 内容转换为 markdown 文本。类似于 Nougat [BCSS23],我们使用 LaTeXML将 LATEX 代码转化为 HTML 序列,然后再转化为 markdown 格式。与 Nougat 不同,我们在页面开始的地方保留所有的表格,因为大多数 LATEX 用户更喜欢使用 “[t]” 或 “[h]” 来定位表格,而不是 “[b]”。同时,我们也将来自 LATEX 格式的表格内容转换成了 markdown 格式。
- HTML(markdown) 从 HTML 网页获取 markdown 资源最直接的方式是通过网络爬取。然而,由于 HTML 标签的误用,网页往往充满了各种各样的布局和样式。此外,HTML 页面可能包含其他无关的元素,如广告、导航菜单或格式化元素,使得提取干净和有意义的内容变得困难。为了克服这些障碍,我们使用 Playwright,这是一个快速可靠的网络端到端测试框架。这个库允许我们浏览 HTML 结构,过滤掉非必要元素,并提取相关的文本内容。我们还应用自定义规则和正则表达式来进一步精细化提取的文本并将其格式化为 markdown,确保生成的 markdown 文件是连贯和可读的。
2.5 过滤与质量控制
我们使用 fastText 进行语言识别(阈值为0.5),以从整个预训练数据集中过滤出非英语文档。为了确保每个来源内的内容多样性,我们利用 MinHash [Bro97] 来识别和删除重复的页面。我们使用与 [LIN+21] 相同的参数,相似度为0.8的文档对将被标记为重复。预训练数据的详细划分,以及它们各自的采样比例,已在表1中提供。在处理来自 README、DOCX、LATEX 和 HTML 来源的图像到 markdown 数据时,我们发现由于转换问题,文本图像中的内容和其对应的 markdown 序列之间存在差异。因此,我们通过评估图像和 markdown 文件之间的标记重叠来优化数据,要求标记交集与并集的比例大于0.95才能被包含进来。附录A.2展示了一些训练样本。
3 实验
3.1 评估
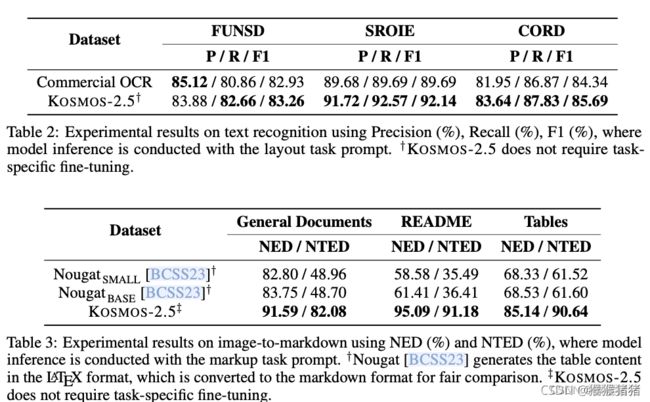
文本识别 我们使用词级精度(# 正确匹配的数量除以检测到的词的数量)、召回率(# 正确匹配的数量除以基准真实词的数量)和 f1 值作为评估文本识别性能的指标。如果基准真实词中有重复的词,那么预测中也应该有重复的词。我们在三个基准数据集上评估文本识别,包括 FUNSD [JET19],SROIE HCH+19和 CORD [PSL+19]。我们将 KOSMOS-2.5 与 Google Document AI 中的文档OCR的文本识别结果进行对比。
图像到 markdown 生成 考虑到图像到 markdown 转换任务的独特性,评估生成的 markdown 的质量需要专门的度量。我们采取了两部分的评估方案:标准化编辑距离(NED)和标准化树编辑距离(NTED),同时考虑语法准确性和原始结构元素的保留。
NED的计算方式如下:
N E D = 1 − 1 N ∑ i = 1 N D ( s i , s ^ i ) / m a x ( l e n ( s i ) , l e n ( s ^ i ) ) NED = 1 - \frac{1}{N}\sum_{i=1}^ND(s_i,\hat{s}_i)/max(len(s_i),len(\hat{s}_i)) NED=1−N1i=1∑ND(si,s^i)/max(len(si),len(s^i))
其中 N N N, s s s和 s ^ \hat{s} s^分别表示样本的数量,预测,以及gt。 D ( . , . ) D(.,.) D(.,.)和 l e n ( . ) len(.) len(.)表示编辑距离方法以及字符串的长度。NED的值域是0-1,越高的NED值表示预测结果越接近gt。
然而,由于 markdown 内在的层次结构,仅依赖于类似 NED 这样的基于字符串的比较度量可能是不够的。因此,我们采用 NTED 作为评估结构差异的额外评估指标。NTED 是树的编辑距离,标准化了树中的节点数量,考虑到解析树之间的结构差异。具体而言,首先将预测的 markdown 序列转换为 HTML 树。然后,使用 ZSS 算法 [ZS89] 计算预测值和真实值之间的树编辑距离。NTED 的公式为:
N T E D = 1 − 1 N ∑ i = 1 N T D ( t i , t ^ i ) / m a x ( n o d e ( t i ) , n o d e ( t ^ i ) ) NTED = 1 - \frac{1}{N}\sum_{i=1}^NTD(t_i,\hat{t}_i)/max(node(t_i),node(\hat{t}_i)) NTED=1−N1i=1∑NTD(ti,t^i)/max(node(ti),node(t^i))
其中 N N N, t t t,以及 t ^ \hat{t} t^分别表示样本的数目,HTML树的预测,以及HTML树的gt。除此之外, T D ( . , . ) TD(.,.) TD(.,.)和 n o d e ( . ) node(.) node(.)表示树的编辑距离方法以及一棵树里面的节点数目。
我们创建了三个数据集,以从不同的数据源评估图像到 markdown 的任务,包括文档级 markdown 生成、README markdown 生成和表格 markdown 生成。每个数据集包括1000对 ⟨图像,markdown⟩ 对,这些对都是从预训练数据中挑选出来的。我们将 KOSMOS-2.5 与 Nougat BCSS23基础和小型模型生成的 markdown 进行比较。
3.2 实现细节
我们采用 AdamW 优化器 [LH17] 进行优化,设置 β = (0.9,0.98),权重衰减为0.01,dropout为0.1。学习率在初始的375步中增加到2 × 10^-4,然后在剩下的训练步骤中线性衰减到零。批量大小可以根据可用的计算资源和特定的训练要求进行调整。KOSMOS-2.5 共包含1.3b 个参数。视觉编码器来自于Pix2Struct-Large模型的编码器进行初始化。语言解码器包含24个变压器层,隐藏尺寸为1536,FFN 中间尺寸为6144,注意头为16。附录A.1中有更多的训练超参数的详细信息。
由于可用的基于布局的数据比基于标记的数据要多得多,我们最初只使用基于布局的数据集对模型进行了10万步的训练。然后,将这两个数据集合并进行进一步的14万步训练。此外,我们将评估数据集的训练分割合并到整个预训练数据中,将过程再增加1万步。对于文本标记化,我们使用 SentencePiece [KR18],并采用“全句”格式 [LOG+19]。这种方法将每一个输入序列与完整的句子打包,这些句子是从一个或多个文档中连续样本出的。新添加的位置标记的词嵌入被随机初始化,所有参数在训练期间得到更新。我们还借鉴了TrOCR [LLC+22]在训练中的数据增强方法,使模型更加鲁棒。
在整个评估过程中,模型推理使用单一模型checkpoint在各种评估数据集中进行,分别使用相应的任务提示,表明我们的方法并不需要对每个数据集进行个性化的模型微调。
3.3 结果
KOSMOS-2.5是一个灵活的框架,可以方便地进行多任务处理,具体的任务由提供的任务提示决定。实验结果显示在表2和表3中。具体而言,对于文本识别任务,我们的 KOSMOS-2.5 在 F1 分数方面超过了 Google Document OCR,分别高出0.33%、2.45%和1.35%,展现了其显著的效果。对于图像到 markdown 的任务,值得注意的是,我们的方法明显优于 Nougat [BCSS23]。例如,KOSMOS-2.5 在 README 数据集的 NED 方面,相比 NougatBASE 提高了33.68% (95.09% 对比 61.41%)。此外,关于 NTED,KOSMOS-2.5 在文档数据集上相较于 NougatBASE 提高了33.38% (82.08% 对比 48.70%)。 我们将性能提升归因于我们的训练数据相对于 Nougat 的多样性增加,Nougat 主要集中在学术论文领域。值得注意的是,我们训练数据的大多样性显著提高了我们的模型对不同文档类型的理解,并增强了其泛化能力。总结来说,实验结果验证了 KOSMOS-2.5 在各种任务中的显著能力。
3.4 讨论
我们在图3中展示了一个示例,显示了当 KOSMOS-2.5 面对相同的输入文本图像时,根据各种任务提示生成的模型输出。如图所示,模型根据接收到的任务提示生成不同的输出。
当给出布局任务提示时,模型生成以下包含文本内容和相应边界框的文本序列:

当给出标记任务提示时,模型按 markdown 格式生成另一个文本序列:

显然,KOSMOS-2.5 在精确识别文本位置和识别文本内容方面表现出色。此外,它熟练地捕获了文本图片中的风格和结构,包括标题、要点、表格和粗体文本等元素。附录 A.3 提供了这个示例使用不同任务提示的完整输出序列。
KOSMOS-2.5 提供了一个统一的架构和接口用于文本图像理解,使其适用于各种应用场景。首先,它可以直接微调为单一模型,用于广泛的文本图像理解任务,包括信息提取、布局检测和分析、视觉问题解答、截图理解、用户界面自动化等许多其他任务。这种统一的模型接口显著简化了下游任务训练,并使模型能够有效地在实际应用中遵循指令。其次,我们的解决方案与更强大的 LLM,如 GPT-3.5 或 GPT-4 兼容。我们模型的输出可以作为上下文供LLM使用,通过进一步的提示工程来增强它们的功能。这种方法让 LLM 具有强大的文本图像理解能力。第三,我们有可能通过增加文本数据来扩充预训练,将其转化为通用的 MLLM。这种扩展模型不仅可以处理视觉信号,而且具有强大的语言理解能力。
4 相关工作
4.1 多模态大语言模型
由ChatGPT [Cha22]代表的大型语言模型(LLM)的繁盛兴起,彻底改变了人工智能,对文本翻译、代码生成、问题回答等众多下游任务产生了重大影响。尽管发展迅速,但重要的是要认识到,人类对世界的感知并不仅限于语言,而是包括广泛的模态,特别强调视觉模态。许多研究试图为 LL M "带来眼睛 ",并开发多模态大型语言模型 (MLLM),可以分为以 LLM为中心的调度系统和端到端可训练的多模态系统。 以 LLM 为中心的调度系统 [Visual ChatGPT WYQ+23, MM-react YLW+23, LWS+23, Hugging GPT SST+23, Intern GPT LHW+23, ViperGPT SMV23, CLS+23] 利用许多视觉基础模型 (如 Stable Diffusion [RBL+22], ControlNet [ZA23], BLIP [LLXH22]),以语言为中心方式调度这些模型。例如,Visual ChatGPT [WYQ+23]开发一组提示,将视觉信息融入ChatGPT,使用户能够通过聊天来绘制或编辑图像。 MM-REACT [YLW+23] 提用视觉专家强化其多模态能力,通过设计能有效代表各种视觉信号的文本提示,包括图像和视频的文本描述、坐标和对应文件名。 HuggingGPT [SST+23] 将 LLM 与机器学习社区的广泛 AI 模型连接,通过 ChatGPT 的任务计划、模型选择和响应汇总能力来解决用户请求。此外,TaskMatrix.AI [LWS+23]大大扩展了规模,将基础模型与数百万 API 连接,用于解决数字和物理领域的任务。不同地,InternGPT [LHW+23] 纳入了指向指令(例如点击和拖动),以便更好地在聊天机器人与用户之间进行通信,同时也提高了聊天机器人执行视觉为中心的任务的准确性。然而,这种方法有几个缺点,如 API 调用的费用或预训练权重需要的存储空间。
端到端可训练的多模态系统 [HSD+22, ADL+22, HDW+23, PWD+23, HZH+21, XHL+21, ZCS+23, HML+23, LLSH23, DLL+23, LLWL23, LZR+23, WCC+23, SLL+23, ZHZ+23, GHZ+23, KSF23, LZC+23] 将视觉和语言模型整合到一个统一的模型中,然后在多模态数据集上进行进一步训练。例如,Flamingo [ADL+22] 利用门控交叉注意力来融合预训练的视觉和语言模型,显示出在下游多模态任务中的令人印象深刻的能力。 此外,BLIP-2 [LLSH23] 利用 Q-Former 将视觉特征与大型语言模型对齐。 此外,Instruct-BLIP 通过引入一种新的指令感知视觉特征提取方法来改进 Q-Former 的训练。 基于这种设计,MiniGPT-4 [ZCS+23] 使用 Vicuna [CLL+23] 作为文本编码器,并细调详细的图像描述以更好地匹配用户意图。 Sparkles 在涉及多张图片的开放式对话中解锁多模态指令跟踪模型的能力 [HML+23]。 LLaVA [LLWL23] 通过将图像标记视为外语,将视觉特征注入语言模型,并使用 GPT-4 [GPT23] 生成的对话进行微调。 KOSMOS-1 [HDW+23] 使用网络级别的语料库从头开始训练,同时在zero-shot、few-shot和多模态思维链提示设置中表现出令人印象深刻的性能。 类似地,KOSMOS-2 [PWD+23] 融合了grounding和referring能力,可以接受用户使用边界框选择的图像区域作为输入。 mPLUG-Owl [YXX+23] 有效地使用低秩适应和多模态指令数据集微调语言模型。 Otter [LZC+23] 建立在 Flamingo 的基础上,旨在探索多模态上下文学习能力。
4.2 图文理解
文本图像理解是一种尖端技术,其利用人工智能(包括自然语言处理和计算机视觉)的力量,自动理解、分类并从文档中提取信息[CXLW21]。任何包含手写或打印字符的文件都可以被视为文档,包括网页、幻灯片、海报甚至场景文本图像。文档在我们的日常生活中无处不在,因此文档的研究十分重要。
在深度学习时代之前,研究者使用基于规则的启发式方法进行文档分析[WCW82, O’G93]。他们手动观察布局信息并总结启发式规则,但这些方法的扩展性不强,且需要大量的人力成本。随后,深度学习的兴起带来了文档 AI 领域的重大进步[XLC+20, XXL+21, XLC+21, HLC+22, CLC+22, LXCW21, LXL+22, LGK+21, AJK+21, WJD22, GMW+ 22, LBY+ 21, YLZ+ 23]。例如,LayoutLM 系列[XLC+ 20, XXL+ 21, HLC+22]利用大规模文档数据进行预训练,并将文本、布局和图像信息融入到模型中,表现出了在下游任务(如关键信息提取和文档问题回答)上令人印象深刻的性能。相类似,DocFormer [AJK+21]在预训练期间引入了一个额外的任务来重构文档图像。Donut [KHY+21]引入了一个无需 OCR(光学字符识别)的文档理解变换器,直接将输入的文档图像映射到所需的 OCR 输出。MarkupLM [LXCW21]利用 Common Crawl 中的大规模网页,并使用节点级的分层结构信息作为预训练目标。XDoc [CLC+22]引入了一个统一的框架,用于在一个模型中处理多种文档格式以提高参数效率。UDOP [TYW+23]设计了一个集成了文本、图像和布局模态的统一模型,在多样化的文档理解任务上展现了令人印象深刻的性能。Pix2Struct [LJT+23]是一个预训练的图像到文本模型,用于将遮蔽的网页截图解析成简化的 HTML。
尽管在文本图像理解方面已取得了显著的进步,但大多数模型都是为特定任务设计的,缺乏泛化性。相反,所提出的 KOSMOS-2.5 在这个领域代表了一个重要的进步,展示了 MLLM 在实现对广泛的文本图像类型的健壮和泛化性能方面的潜力。
5 总结与展望
我们介绍了KOSMOS-2.5,这是一个基于 KOSMOS-2 构建的多模态读写模型,旨在增强机器对文本密集图像的理解。该模型从传统的仅编码器/编码器解码器模型转向更统一的仅解码器架构。转向生成性多模态语言建模简化了任务接口,消除了需要复杂的任务特定管线的需求。此外,KOSMOS-2.5 在few-shot和zero-shot学习能力上展示了潜力,为未来多模态读写模型的进步和可扩展性奠定了基础。 尽管这些结果令人鼓舞,但我们目前的模型还面临一些限制,为未来的研究提供了宝贵的方向。例如,KOSMOS-2.5 目前不支持使用自然语言指示进行文档元素位置的精细控制,尽管它在涉及文本的空间坐标的输入和输出上进行了预训练。引入指令调整可能是一个有前景的路径来增强模型的这个方面,从而扩大应用能力。此外,跨越多页的文档提出了挑战,因为它们通常需要全面的处理和理解。同时,KOSMOS-2.5也有可能允许将多个图像页面与文本交错作为输入; 然而,管理长上下文窗口仍是我们在未来的工作中期望解决的重要问题。
在更广泛的研究领域中,一个重要的方向是进一步推动模型规模能力的开发。随着任务范围的扩大和复杂性的增加,为了推动多模态读写模型的发展,扩大模型以处理更大量的数据是至关重要的。最终,我们的目标是开发一个能够有效解释视觉和文本数据,并在扩大的文本密集的多模态任务中平滑地泛化的模型。