《深度学习入门:梯度下降法全解析,小白必看!》
目录
一、引言
二、什么是梯度下降?
2.1 误差的计算
2.2 梯度的计算
2.3 参数更新
2.4 重复迭代
三、梯度下降法的几种主要类型
1. 批量梯度下降(Batch Gradient Descent)
2. 随机梯度下降(Stochastic Gradient Descent, SGD)
3. 小批量梯度下降(Mini-Batch Gradient Descent)
四、梯度下降的挑战与解决方案
1. 学习率的选择
2. 局部最小值与鞍点
3. 梯度消失与梯度爆炸
五、梯度下降的实践技巧
1. 数据预处理
2. 学习率调度
3. 批量归一化
4. 早停(Early Stopping)
六、总结
声明
一、引言
在深度学习领域,模型训练的核心目标是使模型尽可能准确地拟合数据分布,从而使模型在新数据上具有良好的泛化能力。梯度下降法作为一种经典的优化算法,广泛应用于深度学习中的参数优化过程。通过不断调整模型参数,梯度下降法能够最小化损失函数,从而使模型逐渐达到最优状态。这么说大家可能看不太明白,举个比较经典的例子,房价预测,假设我们想根据房子的面积来预测房价。我们有一些已知的数据:
| 房子面积(平方米) | 房价(万元) |
| 50 | 300 |
| 60 | 360 |
| 70 | 420 |
| 80 | 480 |
我们的目标是找到一个公式,可以根据房子的面积预测出房价。为了简单起见,我们假设房价和面积之间是线性关系,也就是说,房价可以用一个简单的公式表示:
房价=w×面积+b
其中,w 是“斜率”(权重),b 是“截距”(偏置)。我们的任务就是通过数据找到最合适的 w 和 b,使得这个公式能够尽可能准确地预测房价。
二、什么是梯度下降?
梯度下降是一种用于优化数学函数的迭代算法,其核心目标是找到函数的最小值点。在深度学习中,这个函数通常是损失函数(Loss Function),它衡量了模型预测值与真实值之间的差异。通过最小化损失函数,我们可以使模型的预测结果尽可能接近真实值。还是以房价预测为例,梯度下降是一种优化算法,用来找到公式中最优的 w 和 b,使得预测值和真实值之间的误差最小。我们可以把误差想象成一个“山谷”,而梯度下降就是我们一步步往下走,找到山谷的最低点。
2.1 误差的计算
首先,我们需要一个方法来衡量预测值和真实值之间的差距。我们用“均方误差”(MSE)来表示误差:

其中,n 是数据的数量。
2.2 梯度的计算
接下来,我们需要计算误差对 w 和 b 的变化率(梯度)。梯度告诉我们,如果我们调整 w 或 b,误差会如何变化。公式如下:

2.3 参数更新
根据梯度,我们调整 w 和 b 的值,朝着误差减小的方向移动。更新公式如下:
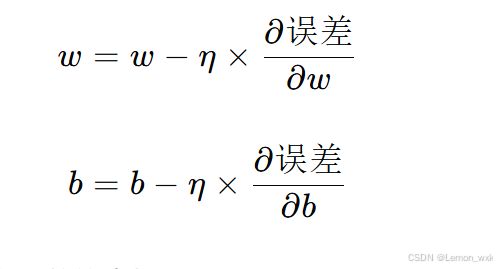
其中,η 是学习率,决定了我们每次调整的步长。
2.4 重复迭代
通过多次迭代,w 和 b 会逐渐接近最优值,误差也会越来越小。在这个房价预测的例子中,通过梯度下降,我们可以找到最合适的 w 和 b,使得预测值和真实值尽可能接近。梯度下降的参数更新公式为:
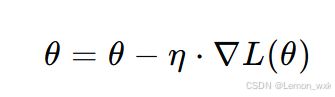
其中,η 是学习率(Learning Rate),控制参数更新的步长。
我的理解就是我们通过一些数据拟合出一些公式来帮助我们来预测某些东西,但是不可避免的就是误差的存在,我们就需要寻找一些最优的参数来优化我们的公式使其预测的更加准确,梯度下降就像我们在黑暗中摸索着下山,每次根据坡度(梯度)调整方向和步长(学习率),最终找到最低点(最优参数)。但是在人工智能领域的实际应用中我们拟合的公式是很复杂的,不像房价预测这个例子这么简单,但是梯度下降法就不会受到约束,即使很复杂也可以寻找到最优参数,所以其在人工智能领域应用十分广泛。
三、梯度下降法的几种主要类型
在实际应用中,根据每次更新参数时使用的数据量,梯度下降可以分为以下三种类型:
1. 批量梯度下降(Batch Gradient Descent)
批量梯度下降每次更新参数时使用整个训练数据集计算梯度。这种方法的优点是计算的梯度是精确的,因此参数更新的方向是确定的,能够稳定地收敛到最优解。然而,其缺点是计算成本较高,尤其是当训练数据集较大时,计算整个数据集的梯度会非常耗时。
2. 随机梯度下降(Stochastic Gradient Descent, SGD)
随机梯度下降每次更新参数时只使用一个样本计算梯度。这种方法的优点是计算速度快,能够快速迭代,适合处理大规模数据集。然而,由于每次更新仅基于一个样本,梯度的估计会有较大的噪声,导致参数更新过程中的振荡现象,可能需要更多的迭代次数才能收敛。
3. 小批量梯度下降(Mini-Batch Gradient Descent)
小批量梯度下降每次更新参数时使用一小批样本(通常为 32、64、128 等)计算梯度。这种方法综合了批量梯度下降和随机梯度下降的优点,既能够利用小批量样本计算梯度来减少噪声,又能保持较快的计算速度,是目前深度学习中最常用的梯度下降变体。
四、梯度下降的挑战与解决方案
1. 学习率的选择
学习率是梯度下降法中的一个重要超参数,决定了参数更新的步长。学习率的选择对模型的训练效果有显著影响:
-
学习率过大:可能导致模型无法收敛,甚至发散。
-
学习率过小:可能导致训练过程过慢,甚至陷入局部最小值。
解决方案:通常需要通过实验来调整学习率,或者使用自适应学习率的方法,如 AdaGrad、RMSProp、Adam 等。
2. 局部最小值与鞍点
在高维参数空间中,损失函数可能存在多个局部最小值点和鞍点。梯度下降法可能会陷入局部最小值,导致无法找到全局最优解。
解决方案:使用动量(Momentum)方法或自适应学习率的方法,可以帮助模型跳出局部最小值。
3. 梯度消失与梯度爆炸
在深度神经网络中,梯度在反向传播过程中可能会迅速减小(梯度消失)或迅速增大(梯度爆炸),导致模型难以训练。
解决方案:
-
使用合适的激活函数,如 ReLU 及其变体。
-
对权重进行梯度裁剪(Gradient Clipping)。
-
使用合适的参数初始化方法,如 He 初始化或 Xavier 初始化。
五、梯度下降的实践技巧
1. 数据预处理
在训练模型之前,对数据进行标准化或归一化处理,可以使损失函数的等高线更加规则,从而加速梯度下降的收敛速度。
2. 学习率调度
在训练过程中,动态调整学习率(如学习率衰减)可以帮助模型更快地收敛。常见的学习率调度方法包括 Step Decay、Exponential Decay 和 Cosine Annealing 等。
3. 批量归一化
在深度神经网络中,使用批量归一化(Batch Normalization)可以减少内部协变量偏移,加速训练过程,同时还能起到一定的正则化作用。
4. 早停(Early Stopping)
在训练过程中,如果验证集的性能不再提升,则可以提前停止训练,避免过拟合。
六、总结
梯度下降法作为深度学习中最基础且重要的优化算法,为模型参数的优化提供了有效的途径。通过理解梯度下降的基本原理、主要流程以及变体和挑战,我们可以更好地应用和改进梯度下降法,从而提高深度学习模型的训练效果和性能。在实际应用中,结合具体的任务和数据特点,选择合适的梯度下降方法和参数设置,对于模型的成功训练至关重要。
声明
本人也是一枚小白,以上都是我学习之后的个人理解,若有不恰当指出,欢迎指出,我也是从网上自己学习意在分享出来让大家共同学习共同进步,有些内容也是来自网络如有侵权联系删除。