【Docker 内核详解】namespace 资源隔离(四):Mount namespace & Network namespace
【Docker 内核详解 - namespace 资源隔离】系列包含:
- namespace 资源隔离(一):进行 namespace API 操作的 4 种方式
- namespace 资源隔离(二):UTS namespace & IPC namespace
- namespace 资源隔离(三):PID namespace
- namespace 资源隔离(四):Mount namespace & Network namespace
- namespace 资源隔离(五):User namespaces
namespace 资源隔离(四):Mount namespace & Network namespace
1.Mount namespace
mount namespace 通过隔离文件系统挂载点对隔离文件系统提供支持,它是历史上第一个 Linux namespace,所以标识位比较特殊,就是 CLONE_NEWNS。隔离后,不同 mount namespace 中的文件结构发生变化也互不影响。可以通过 /proc/[pid]/mounts 查看到所有挂载在当前 namespace 中的文件系统,还可以通过 /proc/[pid]/mountstats 看到 mount namespace 中文件设备的统计信息,包括挂载文件的名字、文件系统类型、挂载位置等。
进程在创建 mount namespace 时,会把当前的文件结构复制给新的 namespace。新 namespace 中的所有 mount 操作都只影响自身的文件系统,对外界不会产生任何影响。这种做法非常严格地实现了隔离,但对某些情况可能并不适用。比如父节点 namespace 中的进程挂载了一张 CD-ROM,这时子节点 namespace 复制的目录结构是无法自动挂载上这张 CD-ROM 的,因为这种操作会影响到父节点的文件系统。
2006 年引入的 挂载传播(mount propagation)解决了这个问题,挂载传播定义了 挂载对象(mount object)之间的关系,这样的关系包括共享关系和从属关系,系统用这些关系决定任何挂载对象中的挂载事件如何传播到其他挂载对象。
- 共享关系(
share relationship)。如果两个挂载对象具有共享关系,那么一个挂载对象中的挂载事件会传播到另一个挂载对象,反之亦然。 - 从属关系(
slave relationship)。如果两个挂载对象形成从属关系,那么一个挂载对象中的挂载事件会传播到另一个挂载对象,但是反之不行;在这种关系中,从属对象是事件的接收者。
一个挂载状态可能为以下一种:
- 共享挂载(
share):传播事件的挂载对象称为共享挂载。 - 从属挂载(
slave):接收传播事件的挂载对象称为从属挂载。 - 共享 / 从属挂载(
shared and slave):同时兼有前述两者特征的挂载对象称为共享 / 从属挂载。 - 私有挂载(
private):既不传播也不接收传播事件的挂载对象称为私有挂载。 - 不可绑定挂载(
unbindable):另一种特殊的挂载对象称为不可绑定的挂载,它们与私有挂载相似,但是不允许执行绑定挂载,即创建mount namespace时这块文件对象不可被复制。
通过下图可以更好地了解它们的状态变化。
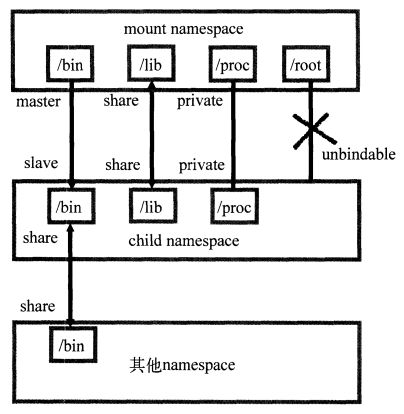
以上图为例说明常用的挂载传播方式。最上层的 mount namespace 下的 /bin 目录与 child namespace 通过 master slave 方式进行挂载传播,当 mount namespace 中的 /bin 目录发生变化时,发生的挂载事件能够自动传播到 child namespace 中;/lib 目录使用完全的共享挂载传播,各 namespace 之间发生的变化都会互相影响;/proc 目录使用私有挂载传播的方式,各 mount namespace 之间互相隔离;最后的 /root 目录一般都是管理员所有,不能让其他 mount namespace 挂载绑定。
默认情况下,所有挂载状态都是私有的。设置为共享挂载的命令如下。
mount --make-shared
从共享挂载状态的挂载对象克隆的挂载对象,其状态也是共享,它们相互传播挂载事件。设置为从属挂载的命令如下。
mount --make-slave
来源于从属挂载对象克隆的挂载对象也是从属的挂载,它也从属于原来的从属挂载的主挂载对象。
将一个从属挂载对象设置为共享 / 从属挂载,可以执行如下命令,或者将其移动到一个共享挂载对象下。
mount --make-shared
如果想把修改过的挂载对象重新标记为私有的,可以执行如下命令。
mount --make-private
通过执行以下命令,可以将挂载对象标记为不可绑定的。
mount --make-unbindable
这些设置都可以递归式地应用到所有子目录中,如果大家感兴趣可以自行搜索相关命令在代码中实现 mount namespace 隔离与其他 namespace 类似,加上 CLONE_NEWNS 标识位即可。让我们再次修改代码,并且另存为 mount.c 进行编译运行。
// [...]
int child pid = clone(child main, child stack + STACK_SIZE,
CLONE_NEWNS | CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD,NULL);
// [...]
CLONE_NEWNS 生效之后,子进程进行的挂载与卸载操作都将只作用于这个 mount namespace,因此在上文中提到的处于单独 PID namespace 隔离中的进程在加上 mount namespace 的隔离之后,即使该进程重新挂载了 /proc 文件系统,当进程退出后,root mountnamespace(主机)的 /proc 文件系统是不会被破坏的。
2.Network namespace
当我们了解完各类 namespace,兴致勃勃地构建出一个容器,并在容器中启动一个 Apache 进程时,却出现了 “80 端口已被占用” 的错误,原来主机上已经运行了一个 Apache 进程,这时就需要借助 network namespace 技术进行网络隔离。
network namespace 主要提供了关于网络资源的隔离,包括网络设备、IPv4 和 IPv6 协议栈、IP 路由表、防火墙、/proc/net 目录、/sys/class/net 目录、套接字(socket)等。一个物理的网络设备最多存在于一个 network namespace 中,可以通过创建 veth pair(虚拟网络设备对:有两端,类似管道,如果数据从一端传入,另一端也能接收到,反之亦然)在不同的 network namespace 间创建通道,以达到通信目的。
veth是Virtual Ethernet Device的缩写,是一种成对出现的 Linux 虚拟网络接口设备。它最常用的功能是用于将不同的 Linux network namespaces 命名空间网络连接起来,让两个 namespaces 之间可以进行通信。我们可以简单的把veth pair理解为用一根网线,把两台电脑(两个 namespaces)连接起来。这样我们就很好理解,veth pair的任何一端 down 掉了,另外一端也就 down 掉了。
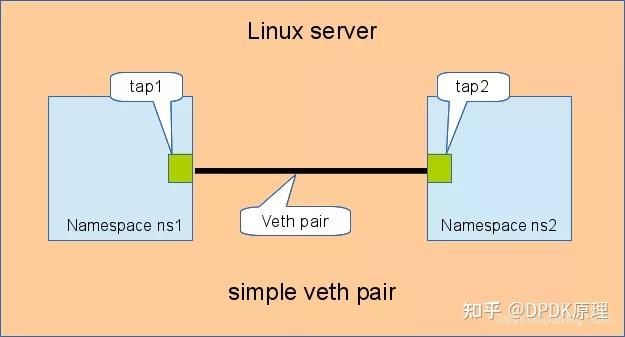
一般情况下,物理网络设备都分配在最初的 root namespace(表示系统默认的 namespace)中。但是如果有多块物理网卡,也可以把其中一块或多块分配给新创建的 network namespace。需要注意的是,当新创建的 network namespace 被释放时(所有内部的进程都终止,并且 namespace 文件没有被挂载或打开),在这个 namespace 中的物理网卡会返回到 root namespace,而非创建该进程的父进程所在的 network namespace。
当说到 network namespace 时,指的未必是真正的网络隔离,而是把网络独立出来,给外部用户一种透明的感觉,仿佛在与一个独立网络实体进行通信。为了达到该目的,容器的经典做法就是创建一个 veth pair,一端放置在新的 namespace 中,通常命名为 eth0 ,一端放在原先的 namespace 中连接物理网络设备,再通过把多个设备接入网桥或者进行路由转发,来实现通信的目的。
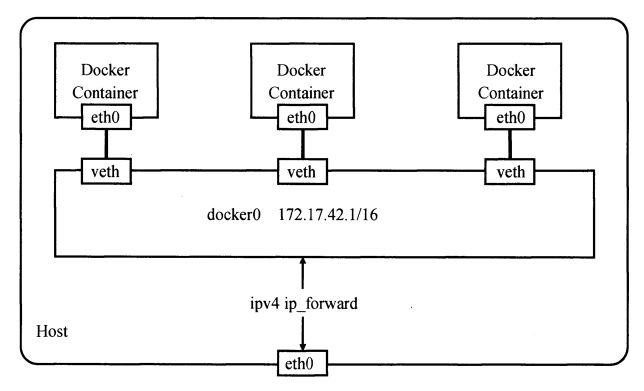
也许大家会好奇,在建立起 veth pair 之前,新旧 namespace 该如何通信呢?答案是 pipe(管道)。以 Docker daemon 启动容器的过程为例,假设容器内初始化的进程称为 init。Docker daemon 在宿主机上负责创建这个 veth pair,把一端绑定到 docker0 网桥上,另一端接入新建的 network namespace 进程中。这个过程执行期间,Docker daemon 和 init 就通过 pipe 进行通信。具体来说,就是在 Docker daemon 完成 veth pair 的创建之前,init 在管道的另一端循环等待,直到管道另一端传来 Docker daemon 关于 veth 设备的信息,并关闭管道。init 才结束等待的过程,并把它的 eth0 启动起来。整个结构如下图所示。
与其他 namespace 类似,对 network namespace 的使用其实就是在创建的时候添加 CLONE_NEWNET 标识位。后续博客将会对 Docker 网络进行详细介绍,此处不再赘述。