http协议
认识URL
我们俗称的”网址“其实就是URL

-
协议方案:如我们常见的
http和https,https是一种加密协议,安全性更高,右面会单独进行讲解 -
登陆信息:在http的URL中显式写用户名和密码的方式很少见,但是有一个地方经常用到:ssh协议

-
服务器地址:可以填写服务器的域名或IP地址;如果填写的是域名,在访问URL时,浏览器也会通过域名在DNS服务器获取到IP地址
-
端口号:可以显式指定,也可以缺省
-
若缺省,浏览器根据协议方案会为我们自动添加
- http->80
- https->443
- sshd->22
-
若显式指定,必须在
[1024, n]范围内
-
-
文件路径:URL标定了网络上的某个资源,这个资源本质就是服务器端的主机上的某个路径下的文件,如上图中的
/dir/index.html,注意这里的web根目录不一定是Linux主机的根目录,此根目录是由服务器程序进行设定的 -
查询字段:几个查询字段之间用
&进行分割 -
片段标识符
encode & decode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现.
比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
如:
+-encode->%2B:字符+对应的ASCII需要一个字节,值为43(十进制),即2B(16进制),编码后即%2B加-encode->%E5%8A%A0:汉字加用utf-8编码需要三个字节,对应的16进制值为E5 8A A0,用三个%分别引导三个字节,编码后就是%E5%8A%A0
HTTP报文解析
http报文分为两种:
- 请求报文(一般由客户端发出)
- 响应报文(一般由服务器端发出)

如下是百度网站图标资源请求过程中的一组报文,我们暂且不分析其中的具体含义,仅分析其两个报文格式
请求报文:
GET https://www.baidu.com/favicon.ico HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
sec-ch-ua: “Microsoft Edge”;v=“117”, “Not;A=Brand”;v=“8”, “Chromium”;v=“117”
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.0.0
sec-ch-ua-platform: “Windows”
Accept: image/webp,image/apng,image/svg+xml,image/,/*;q=0.8
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: no-cors
Sec-Fetch-Dest: image
Referer: https://www.baidu.com/
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
其中,第一行分别是
- 请求方法:GET(含义及其它方法看后面)
- URL:https://www.baidu.com/favicon.ico(表示访问了www.baidu.com、443号端口、
/favicon.ico路径的资源) - HTTP版本号:HTTP/1.1
剩余一行行的都属于请求报头
最后是一个空行,表示报头部分结束
没有正文部分
相应正文:
HTTP/1.1 200 OK
Accept-Ranges: bytes
Content-Length: 16958
Content-Type: image/x-icon
Date: Mon, 14 Aug 2023 10:21:18 GMT
Etag: “423e-5bd257db4e500”
Last-Modified: Wed, 10 Mar 2021 02:33:24 GMT
Server: Apache
Vary: Accept-Encoding,User-Agent…(由于是图片信息,正文呈现乱码)
第一行:
- 版本:HTTP/1.1
- 状态码:200(至于含义及其它状态码,后面会分析)
- 状态码的描述:OK(显然,它表示此次请求是成功了的)
接下来一直到空行,都属于报头部分,描述了正文大小、数据类型、日期……等信息
空行往后都属于正文部分,也就是图片的二进制数据,此处用字符呈现是一些乱码,不具有参考价值
HTTP的请求方法

看似这里有很多方法,但大部分的Web服务器也只会用到GET和POST两种方法
下面,我们着重对这两种方法进行分析
为了方便查看它们的区别,我们写一个简单的HTML表单(form)
index.html
DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>html测试title>
head>
<body>
<h3>hello my serverh3>
<form action="login_success.jpg" method="get">
Username: <input type="text" name="user"><br>
Password: <input type="password" name="passwd"><br>
<input type="submit" value="Submit"><br>
form>
body>
html>
我们将此html挂载在http服务器进程上
渲染呈现:

测试:
两次定义表单时,我们分别设置
-
method="get":提交表单的方法是GET -
methord=“post”:提交表单的方法是POST
两种情况下,当我们点击Submit:
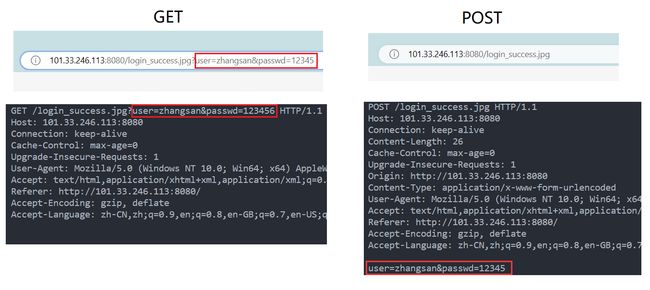
理解:
当浏览器向服务器申请首页资源后(http://101.33.246.113:8080/index.html),会获得上述表单,当填写完成,点击Submit后,浏览器会自动生成URL和http请求报文,向服务器进行提交表单
由上图可以发现两种请求方式并不太相同
- GET:直接以明文方式将参数拼接到了URL的查询字符串部分,报文的正文部分是空白的
- POST:将两个参数被写到了报文的正文部分,URL没有
所以,由于GET通过URL进行传参,私密性相对较差
POST通过正文传参,适合传一些较大的内容
HTTP的状态码

-
1XX:相对少见,可以用来表示任务进度
-
200:请求处理完毕
-
301&302:都是重定向操作,客户端向服务器发起请求,服务器端可以响应301或者302状态码,并结合Header中的location字段,指定一个新的url,让客户端去访问(浏览器收到后会自动完成),区别:
- 301:永久重定向,一般用于服务器域名、IP变更等情况
- 302:临时重定向,如资源升级,需要临时使用其它服务器
上述是服务器端使用意义的区别,在客户端,某些浏览器当收到是永久重定向,可能会直接修改书签等记录,而临时重定向则不会
常见的Header
- Content-Type: 数据类型(text/html等)
- Content-Length: Body的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息,方便服务器进行设备网页适配;
- referer: 告知服务器当前页面是从哪个页面跳转过来的;
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问,如果需要重定向其它url,需要写完整,如:
https://www.baidu.com/,否则会被认为是本地资源重定向 - Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能; (下面有详细说明)
- Connection: 决定当前的事务完成后,是否会关闭网络连接(下面有详细说明)
cookie & session
http协议的特点之一:无状态
但是很多情景都需要进行会话保持,比如我们在视频网站进行登陆后,即使关闭网页或浏览器,下次打开网站后依然需要是登陆状态的,不然非常影响用户体验
此时,就需要cookie和session的技术来支持
如下模拟浏览器登陆某视频网站的过程:

我们可以通过如下方法,在我们的浏览器上获取到某个网站的Cookie信息


Connection
我们知道,http的底层是TCP协议
在http1.0的时代,http协议只支持短链接,当完成一次请求,TCP与远端建立的连接即刻被close
但是,随着网络的发展,http所承载的任务变得更复杂,一个网页可能包含各种图片、视频等信息
用户所看到的完整的网页,背后可能是无数次http请求
如果依然使用原先的短链接,对于每次请求底层TCP都需要不断建立连接、断开连接,非常耗时
所以http1.1协议提出了长链接,即完成一次http请求后,底层的TCP连接还保持一段时间
当客户端向服务器发送请求报文时,添加Connection: keep-alive头,便是与服务器进行了协商,表示双方都同意采用长连接的方案
若使用Connection:closed,则表示使用短连接方式,服务器端处理完此请求即断开TCP连接
如果使用了保活策略,也就意味了一个TCP链接中可能会有多个HTTP请求,通过Content-Length便可解决粘包问题
为了解决多个请求的乱序问题,可以使用pipeline技术
如何理解http无状态
无状态协议
- 协议的状态是指下一次传输可以“记住”这次传输信息的能力。
- http是不会为了下一次连接而维护这次连接所传输的信息,为了保证服务器内存。
比如客户获得一张网页之后关闭浏览器,然后再一次启动浏览器,再登陆该网站,但是服务器并不知道客户关闭了一次浏览器。 - 由于Web服务器要面对很多浏览器的并发访问,为了提高Web服务器对并发访问的处理能力,在设计HTTP协议时规定Web服务器发送HTTP应答报文和文档时,不保存发出请求的Web浏览器进程的任何状态信息。这有可能出现一个浏览器在短短几秒之内两次访问同一对象时,服务器进程不会因为已经给它发过应答报文而不接受第二期服务请求。由于Web服务器不保存发送请求的Web浏览器进程的任何信息,因此HTTP协议属于无状态协议(Stateless Protocol)。
HTTP协议是无状态的和Connection: keep-alive的区别
- 无状态是指协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。从另一方面讲,打开一个服务器上的网页和你之前打开这个服务器上的网页之间没有任何联系。
- HTTP是一个无状态的面向连接的协议,无状态不代表HTTP不能保持TCP连接,更不能代表HTTP使用的是UDP协议(无连接)。
- 从HTTP/1.1起,默认都开启了Keep-Alive,保持连接特性,简单地说,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。
Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。
HTTP是一个无状态协议,这意味着每个请求都是独立的,Keep-Alive(服务器处理完客户的请求后,并收到客户端的应答后,不会立即断开)没能改变这个结果。
然而,随着时间的推移,人们发现静态的HTML着实无聊而乏味,增加动态生成的内容才会令Web应用程序变得更加有用。于是乎,HTML的语法在不断膨胀,其中最重要的是增加了表单(Form);客户端也增加了诸如脚本处理、DOM处理等功能;对于服务器,则相应的出现了CGI(Common Gateway Interface)以处理包含表单提交在内的动态请求。
在这种客户端与服务器进行动态交互的Web应用程序出现之后,HTTP无状态的特性严重阻碍了这些交互式应用程序的实现,毕竟交互是需要承前启后的,简单的购物车程序也要知道用户到底在之前选择了什么商品。于是,两种用于保持HTTP状态的技术就应运而生了,一个是Cookie,而另一个则是Session。
Cookie是客户端的存储空间,由浏览器来维持。具体来说cookie机制采用的是在客户端保持状态的方案,而session机制采用的是在服务器端保持状态的方案。同时我们也看到,由于才服务器端保持状态的方案在客户端也需要保存一个标识,所以session机制可能需要借助于cookie机制来达到保存标识的目的,但实际上还有其他选择,比如说重写URL和隐藏表单域。
简单的说就是cookie和session起到保存客户端状态的作用,但是它们并没有改变http协议本身这种无状态的性质,可以理解为在应用上做了状态保留。
作者:KB_MORE
链接:https://www.jianshu.com/p/5a088e3d78e0
来源:简书