用Python爬下6万共享单车数据,谈谈单车热潮中的城市
来源: 钱塘大数据 作者:数据挖掘与实战 链接:
http://mp.weixin.qq.com/s/c4ZPXJ3VJHuqaS7oGN-FFg
共享经济的浪潮席卷着各行各业,而出行行业是这股大潮中的主要分支。如今,在城市中随处可见共享单车的身影,给人们的生活出行带来了便利。相信大家总会遇到这样的窘境,在APP中能看到很多单车,但走到那里的时候,才发现车并不在那里。有些车不知道藏到了哪里;有些车或许是在高楼的后面,由于有GPS的误差而找不到了;有些车被放到了小区里面,一墙之隔让骑车人无法获得到车。
那么有没有一个办法通过获得这些单车的数据,来分析这些车是否变成了僵尸车?是否有人故意放到小区里面让人无法获取呢?带着这些问题,笔者开始了研究如何获取这些数据。后台回复“摩拜”,获取完整源码。
从哪里获得数据
如果你能够看到数据,那么我们总有办法自动化的获取到这些数据。只不过获取数据的方式方法决定了获取数据的效率。
对于摩拜单车的数据分析这个任务而言,这个爬虫要能够在短时间内(通常是10分钟左右)获取到更多的数据,对于数据分析才有用处。那么数据来源于哪里?
最直接的来源是摩拜单车的APP。现代的软件设计都讲究前后端分离,而且服务端会同时服务于APP、网页等。在这种趋势下我们只需要搞清楚软件的HTTP请求就好了。一般而言有以下一些工具可以帮忙:
直接抓包:
用代理进行HTTP请求抓包及调试:
由于我的手机没有root,在路由器上抓包又太多的干扰,对于https也不好弄。所以只能首先采用Fiddler或者Charles的方式试试。
挂上Fiddler的代理,然后在手机端不停的移动位置,看有没有新的请求。但遗憾的是似乎请求都是去拿高德地图的,并没有和摩拜车相关的数据。
那怎么一回事?试试手机端的。换成Packet Capture后果然就有流量了,在请求中找到了我最关心的那个:
这个API请求一看就很显然了,在postman中试了一下能够正确的返回信息,看来就是你了!
高兴得太早。
连续爬了几天的数据,将数据进行一分析,发现摩拜单车的GPS似乎一直在跳动,有时候跳动会超过几公里的距离,显然不是一个正常的值。
难道是他们的接口做了手脚返回的是假数据?我观察到即便在APP中,单车返回的数据也有跳动。有某一天凌晨到第二天早上,我隔段时间刷新一下我家附近的车,看看是否真的如此。
图片我找不到了,但是观察后得出的结论是,APP中返回的位置确实有问题。有一台车放在一个很偏僻的位置,一会儿就不见了,待会儿又回来了,和我抓下来的数据吻合。
而且这个跳动和手机、手机号、甚至移动运营商没有关系,说明这个跳动是摩拜接口的问题,也可以从另一方面解释为什么有时候看到车但其实那里没有车。
这是之前发的一个朋友圈的视频截图,可以看到在营门口附近有一个尖,在那里其实车是停住的,但是GPS轨迹显示短时间内在附近攒动,甚至攒动到很远,又回到那个位置。
这样的数据对于数据分析来讲根本没法用,我差点就放弃了。
随着微信小程序的火爆,摩拜单车也在第一时间出了小程序。我一看就笑了,不错,又给我来了一个数据源,试试。
用Packet Capture抓了一次数据后很容易确定API。抓取后爬取了两三天的数据,发现出现了转机,数据符合正常的单车的轨迹。
剩下事情,就是提高爬虫的效率了。
其他尝试
有时候直接分析APP的源代码会很方便的找到API入口,将摩拜的Android端的APP进行反编译,但发现里面除了一些资源文件有用外,其他的文件都是用奇虎360的混淆器加壳的。网上有文章分析如何进行脱壳,但我没有太多时间去钻研,也就算了。
摩拜单车的API之所以很容易抓取和分析,很大程度上来讲是由于API设计的太简陋:
如果大家有兴趣,可以试着看一下小蓝单车APP的request,他们使用https请求,对数据的request进行了加密,要抓取到他们的数据难度会增加非常多。
当然了,如果摩拜单车官方并不care数据的事情的话,这样的API设计也是ok的。
声明:
此爬虫仅用于学习、研究用途,请不要用于非法用途。任何由此引发的法律纠纷自行负责。
没耐心看文章的请直接:公众号菜单栏回复“摩拜”获取完整源码
目录结构
\analysis - jupyter做数据分析
\influx-importer - 导入到influxdb,但之前没怎么弄好
\modules - 代理模块
\web - 实时图形化显示模块,当时只是为了学一下react而已,效果请见这里
crawler.py - 爬虫核心代码
importToDb.py - 导入到postgres数据库中进行分析
sql.sql - 创建表的sql
start.sh - 持续运行的脚本
思路
核心代码放在crawler.py中,数据首先存储在sqlite3数据库中,然后去重复后导出到csv文件中以节约空间。
摩拜单车的API返回的是一个正方形区域中的单车,我只要按照一块一块的区域移动就能抓取到整个大区域的数据。
left,top,right,bottom定义了抓取的范围,目前是成都市绕城高速之内以及南至南湖的正方形区域。offset定义了抓取的间隔,现在以0.002为基准,在DigitalOcean 5$的服务器上能够15分钟内抓取一次。
def start(self): left = 30.7828453209 top = 103.9213455517 right = 30.4781772402 bottom = 104.2178123382 offset = 0.002 if os.path.isfile(self.db_name): os.remove(self.db_name) try: with sqlite3.connect(self.db_name) as c: c.execute('''CREATE TABLE mobike (Time DATETIME, bikeIds VARCHAR(12), bikeType TINYINT,distId INTEGER,distNum TINYINT, type TINYINT, x DOUBLE, y DOUBLE)''') except Exception as ex: pass
left = 30.7828453209
top = 103.9213455517
right = 30.4781772402
bottom = 104.2178123382
offset = 0.002
if os.path.isfile(self.db_name):
os.remove(self.db_name)
try:
with sqlite3.connect(self.db_name) as c:
c.execute('''CREATE TABLE mobike
(Time DATETIME, bikeIds VARCHAR(12), bikeType TINYINT,distId INTEGER,distNum TINYINT, type TINYINT, x DOUBLE, y DOUBLE)''')
except Exception as ex:
pass然后就启动了250个线程,至于你要问我为什么没有用协程,哼哼~~我当时没学~~~其实是可以的,说不定效率更高。
由于抓取后需要对数据进行去重,以便消除小正方形区域之间重复的部分,最后的group_data正是做这个事情。
executor = ThreadPoolExecutor(max_workers=250) print("Start") self.total = 0 lat_range = np.arange(left, right, -offset) for lat in lat_range: lon_range = np.arange(top, bottom, offset) for lon in lon_range: self.total += 1 executor.submit(self.get_nearby_bikes, (lat, lon)) executor.shutdown() self.group_data()
print("Start")
self.total = 0
lat_range = np.arange(left, right, -offset)
for lat in lat_range:
lon_range = np.arange(top, bottom, offset)
for lon in lon_range:
self.total += 1
executor.submit(self.get_nearby_bikes, (lat, lon))
executor.shutdown()
self.group_data()最核心的API代码在这里。小程序的API接口,搞几个变量就可以了,十分简单。
def get_nearby_bikes(self, args): try: url = "https://mwx.mobike.com/mobike-api/rent/nearbyBikesInfo.do" payload = "latitude=%s&longitude=%s&errMsg=getMapCenterLocation" % (args[0], args[1]) headers = { 'charset': "utf-8", 'platform': "4", "referer":"https://servicewechat.com/wx40f112341ae33edb/1/", 'content-type': "application/x-www-form-urlencoded", 'user-agent': "MicroMessenger/6.5.4.1000 NetType/WIFI Language/zh_CN", 'host': "mwx.mobike.com", 'connection': "Keep-Alive", 'accept-encoding': "gzip", 'cache-control': "no-cache" } self.request(headers, payload, args, url) except Exception as ex: print(ex)
try:
url = "https://mwx.mobike.com/mobike-api/rent/nearbyBikesInfo.do"
payload = "latitude=%s&longitude=%s&errMsg=getMapCenterLocation" % (args[0], args[1])
headers = {
'charset': "utf-8",
'platform': "4",
"referer":"https://servicewechat.com/wx40f112341ae33edb/1/",
'content-type': "application/x-www-form-urlencoded",
'user-agent': "MicroMessenger/6.5.4.1000 NetType/WIFI Language/zh_CN",
'host': "mwx.mobike.com",
'connection': "Keep-Alive",
'accept-encoding': "gzip",
'cache-control': "no-cache"
}
self.request(headers, payload, args, url)
except Exception as ex:
print(ex)最后你可能要问频繁的抓取IP没有被封么?其实摩拜单车是有IP的访问速度限制的,只不过破解之道非常简单,就是用大量的代理。
我是有一个代理池,每天基本上有8000以上的代理。在ProxyProvider中直接获取到这个代理池然后提供一个pick函数用于随机选取得分前50的代理。
请注意,我的代理池是每小时更新的,但是代码中提供的jsonblob的代理列表仅仅是一个样例,过段时间后应该大部分都作废了。
在这里用到一个代理得分的机制。我并不是直接随机选择代理,而是将代理按照得分高低进行排序。每一次成功的请求将加分,而出错的请求将减分。
这样一会儿就能选出速度、质量最佳的代理。如果有需要还可以存下来下次继续用。
class ProxyProvider: def __init__(self, min_proxies=200): self._bad_proxies = {} self._minProxies = min_proxies self.lock = threading.RLock() self.get_list() def get_list(self): logger.debug("Getting proxy list") r = requests.get("https://jsonblob.com/31bf2dc8-00e6-11e7-a0ba-e39b7fdbe78b", timeout=10) proxies = ujson.decode(r.text) logger.debug("Got %s proxies", len(proxies)) self._proxies = list(map(lambda p: Proxy(p), proxies)) def pick(self): with self.lock: self._proxies.sort(key = lambda p: p.score, reverse=True) proxy_len = len(self._proxies) max_range = 50 if proxy_len > 50 else proxy_len proxy = self._proxies[random.randrange(1, max_range)] proxy.used() return proxy
def __init__(self, min_proxies=200):
self._bad_proxies = {}
self._minProxies = min_proxies
self.lock = threading.RLock()
self.get_list()
def get_list(self):
logger.debug("Getting proxy list")
r = requests.get("https://jsonblob.com/31bf2dc8-00e6-11e7-a0ba-e39b7fdbe78b", timeout=10)
proxies = ujson.decode(r.text)
logger.debug("Got %s proxies", len(proxies))
self._proxies = list(map(lambda p: Proxy(p), proxies))
def pick(self):
with self.lock:
self._proxies.sort(key = lambda p: p.score, reverse=True)
proxy_len = len(self._proxies)
max_range = 50 if proxy_len > 50 else proxy_len
proxy = self._proxies[random.randrange(1, max_range)]
proxy.used()
return proxy在实际使用中,通过proxyProvider.pick()选择代理,然后使用。如果代理出现任何问题,则直接用proxy.fatal_error()降低评分,这样后续就不会选择到这个代理了。
def request(self, headers, payload, args, url): while True: proxy = self.proxyProvider.pick() try: response = requests.request( "POST", url, data=payload, headers=headers, proxies={"https": proxy.url}, timeout=5,verify=False ) with self.lock: with sqlite3.connect(self.db_name) as c: try: print(response.text) decoded = ujson.decode(response.text)['object'] self.done += 1 for x in decoded: c.execute("INSERT INTO mobike VALUES (%d,'%s',%d,%d,%s,%s,%f,%f)" % ( int(time.time()) * 1000, x['bikeIds'], int(x['biketype']), int(x['distId']), x['distNum'], x['type'], x['distX'], x['distY'])) timespend = datetime.datetime.now() - self.start_time percent = self.done / self.total total = timespend / percent print(args, self.done, percent * 100, self.done / timespend.total_seconds() * 60, total, total - timespend) except Exception as ex: print(ex) break except Exception as ex: proxy.fatal_error()
while True:
proxy = self.proxyProvider.pick()
try:
response = requests.request(
"POST", url, data=payload, headers=headers,
proxies={"https": proxy.url},
timeout=5,verify=False
)
with self.lock:
with sqlite3.connect(self.db_name) as c:
try:
print(response.text)
decoded = ujson.decode(response.text)['object']
self.done += 1
for x in decoded:
c.execute("INSERT INTO mobike VALUES (%d,'%s',%d,%d,%s,%s,%f,%f)" % (
int(time.time()) * 1000, x['bikeIds'], int(x['biketype']), int(x['distId']),
x['distNum'], x['type'], x['distX'],
x['distY']))
timespend = datetime.datetime.now() - self.start_time
percent = self.done / self.total
total = timespend / percent
print(args, self.done, percent * 100, self.done / timespend.total_seconds() * 60, total,
total - timespend)
except Exception as ex:
print(ex)
break
except Exception as ex:
proxy.fatal_error()抓取了摩拜单车的数据并进行了大数据分析。以下数据分析自1月19日整日的数据,范围成都绕城区域以及至华阳附近(天府新区)内。成都的摩拜单车的整体情况如下:
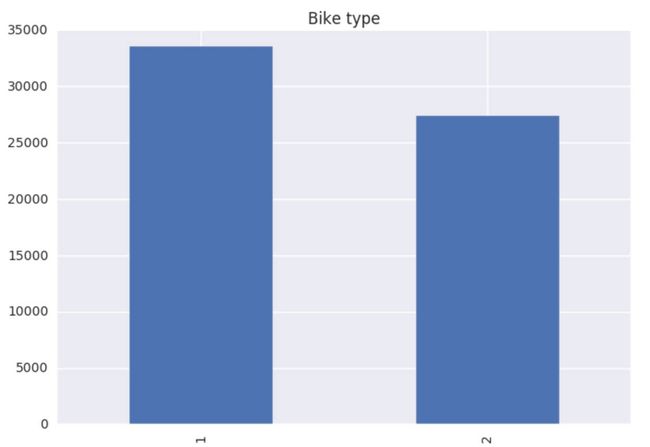
标准、Lite车型数量相当
摩拜单车在成都大约已经有6万多辆车,两种类型的车分别占有率为55%和44%,可见更为好骑的Lite版本的占有率在提高。(1为标准车,2为Lite车型)
三成左右的车没有移动过
数据分析显示,有三成的单车并没有任何移动,这说明这些单车有可能被放在不可获取或者偏僻地方。市民的素质还有待提高啊。
数据分析显示3公里以下的出行距离占据了87.2%,这也十分符合共享单车的定位。100米以下的距离也占据了大量的数据,但认为100米以下的数据为GPS的波动,所以予以排除。
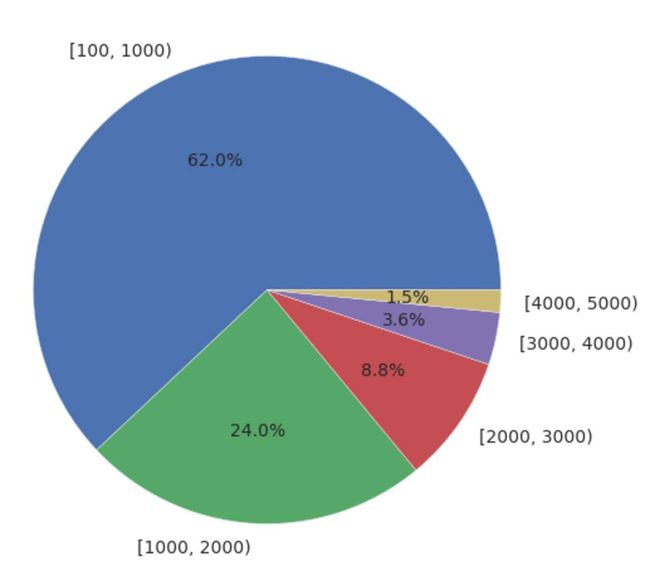
出行距离分布
骑行次数以5次以下居多
单车的使用频率越高共享的效果越好。从摩拜单车的数据看,在流动的单车中,5次以下占据了60%左右的出行。但1次、2次的也占据了30%左右的份额,说明摩拜单车的利用率也不是很高。
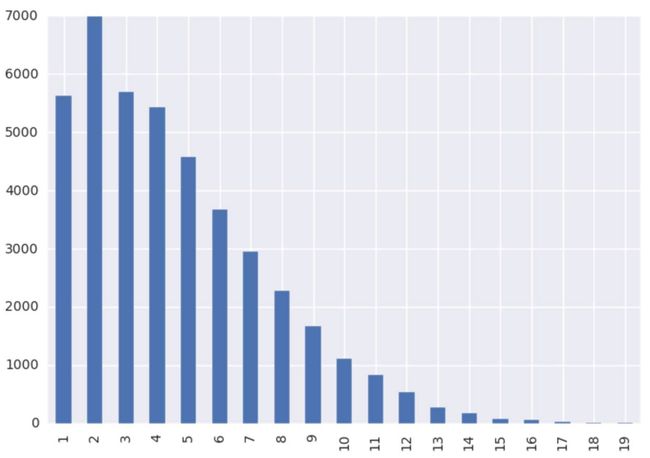
单车骑行次数
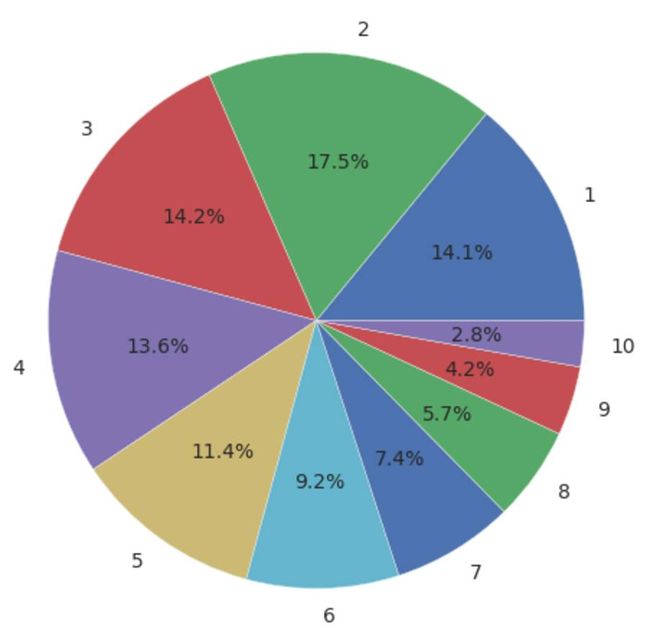 单车骑行次数
单车骑行次数
从单车看城市发展
从摩拜单车的热图分布来看,成都已经逐步呈现“双核”发展的态势,城市的新中心天府新区正在聚集更多的人和机会。
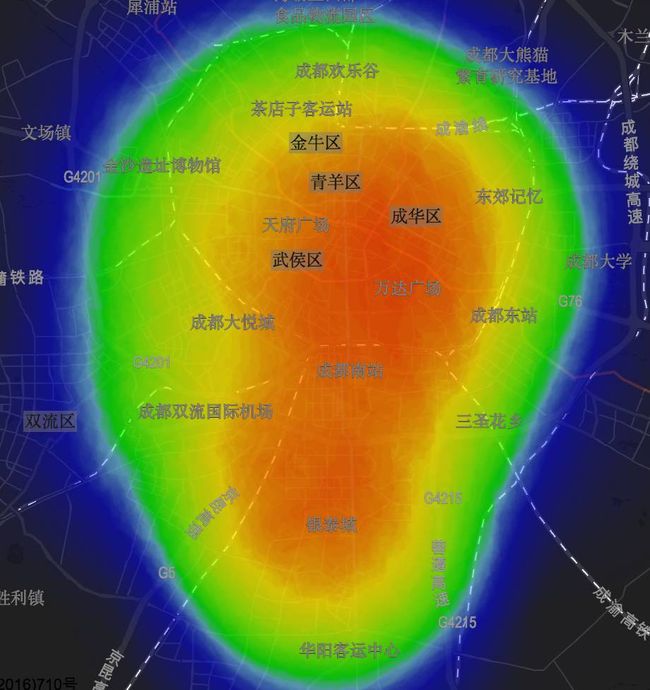
双核发展
原来的老城区占有大量的单车,在老城区,热图显示在东城区占有更多的单车,可能和这里的商业(春熙路、太古里、万达)及人口密集的小区有直接的联系。
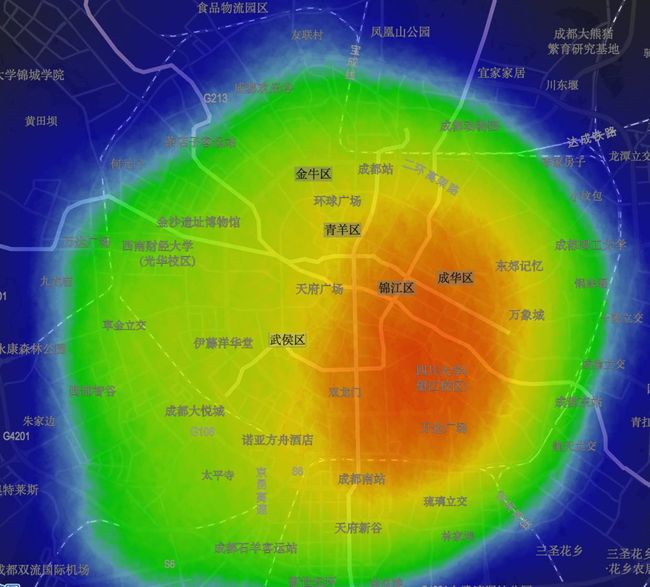
老城区
而在成都的南部天府新区越来越多也茁壮的发展起来,商业区域和住宅区域区分明显。在晚上,大量的单车聚集在华阳、世纪城、中和,而在上班时间,则大量聚集在软件园附近。
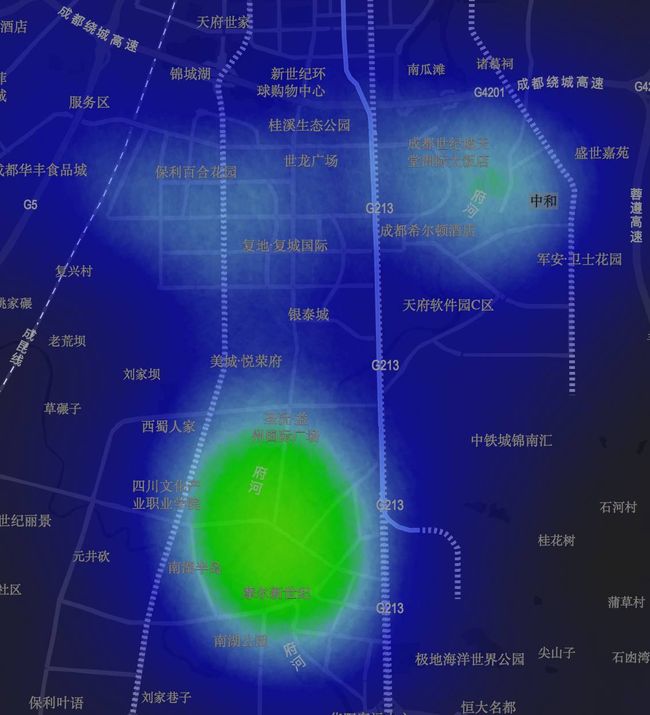
软件园夜间
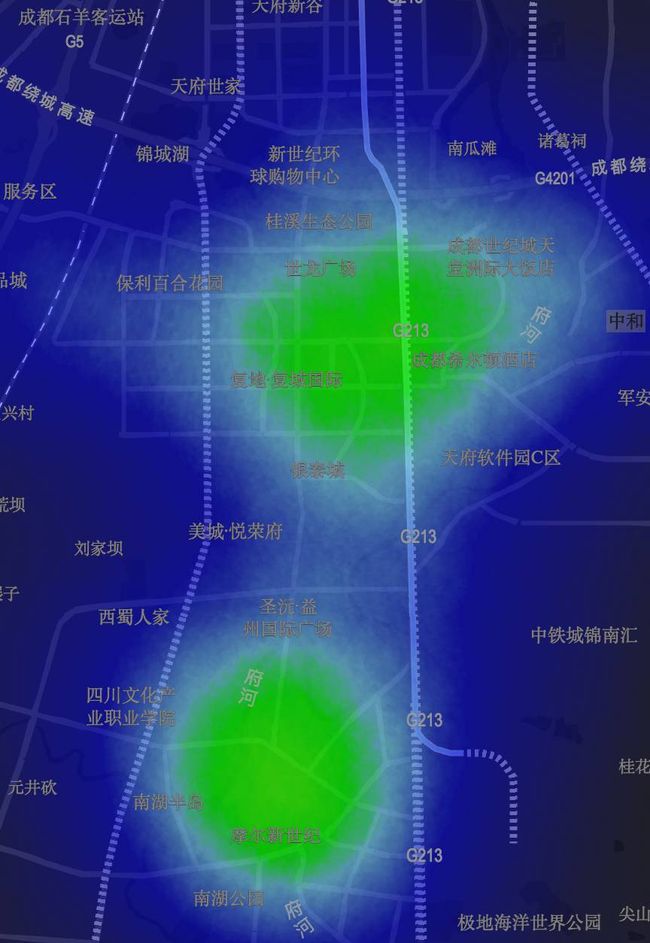
软件园白天
(完)