GaussDB数据库行列存表锁机制差异对于sql编写的影响
目录
一、列存表与行存表性能分析
二、行列表存储差异
2.1 行存表存储原理
2.2 列存表存储原理
三、行列存储带来锁机制的差异
3.1 行存表处理流程
3.2 列存表处理流程
3.3 行列存表锁机制差异总结
四、列行存表锁机制差异带来的影响
4.1 并发删除或更新不同元组数据
4.2 并发删除或更新同一元组数据
4.3 行列存表并发删除或更新总结
五、列存表并发删除或更新报错解决方案
GaussDB数据库支持行列混合存储模式。行存储是指将表按行存储到硬盘分区上,即一行数据是连续存储。列存储是指将表按列存储到硬盘分区上,即一列所有数据是连续存储的。同一张表分别按行存储和按列存储的结果,如图1所示。
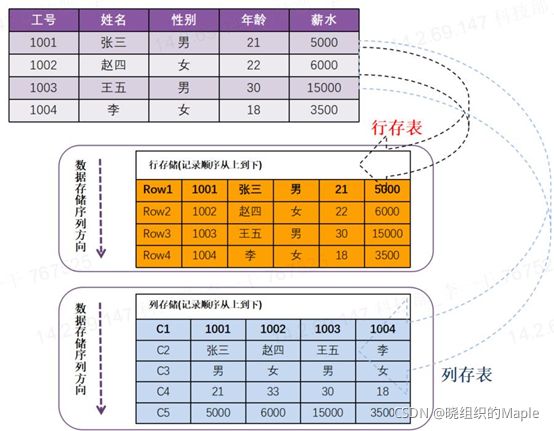
图1行存储和列存储的差异
与行存表相比,列存表在数据量大、查询复杂的OLAP 场景下具有更加明显的优势。GaussDB数据库可以使用列存储模式对表进行存储,带来更加优异性能的同时也对sql编写者带来了新的要求。本文首先从行列存储原理入手对锁机制进行全面的分析,最后辅助以案例应对行列锁机制差异。
一、列存表与行存表性能分析
1.执行不同的脚本并发操作同一张表,比较CPU使用率,在不同的并发数下,列存表CPU使用都有明显降低,CPU使用率仅为行存表的一半。
2.执行不同的脚本并发操作同一张表,比较脚本的运行时长,列存表在10并发以下具有明显的优势,随着并发操作的增长,列存表的优势不再明显,在我们的实验中,当并发为40时性能劣化为27%。目前在大部分的业务场景中,同一时间针对同一张表的并发数较少,处于列存表优势范围内,采用列存表对于总体性能的提升具有明显的收益。
二、行列表存储差异
在GaussDB数据库中,表里的数据总是存放在一个或多个物理的数据文件中。相应的数据文件又分为多个固定大小的数据块,数据存放在这些数据块中。
2.1 行存表存储原理
在传统的行存储中,数据块的大小默认是8KB,一个数据块中可以存放多行的数据。数据块以块头为起始,块头中记录了块的checksum值、空闲空间的起始位置和结束位置、行内容偏移量等,其后按顺序记录了这个数据块中各个数据行的指针(按从前往后顺序排列),而实际存储的数据行内容从块尾向前反向排列,行数据指针与行数据之间的部分则是空闲空间,如图2所示。

图2 数据块的结构图
由上图结构可以看出,当需要读取某列时,需要将这列前面的所有列都进行deform,所以访问第一列和访问最后一列的成本实际上是不一样的,使得读取任意列的成本不一样,越靠后的列,成本越高。在添加有默认值的字段时,进行REWRITE表,需要对全表进行REWRITE。
2.2 列存表存储原理
对于列存表中,以存储单元CU作为存储单位,每个CU存储着一列数据,单个CU最多存储1列60000行数据。一个存储单元中可以包含多行数据的单列数据,下图中的列C和列D可以表示数据表中如姓名、性别两个任意字段,如图3所示。

图3 列存表存储结构
由上图的CU存储结构可以看到,当读取任一列时,都不需要读取排在前面列的数据,读取任意一列的成本是一样,但如果要读取多列,需要访问多个文件,访问的列越多,开销越大。每个CU存放的是具有相同格式的数据(即同一字段),使其更容易进行向量化和更高的压缩比。向量化的数据,在进行大批量数据访问和统计方面具有更高的效率。更高的压缩比也意味着,相同的数据,列存表占用的磁盘空间更少。
三、行列存储带来锁机制的差异
当业务进行并发操作时: 为了防止同一个元组被两个事务同时更新或删除,在进行update/delete时,都会加上行级锁,对于行存来说是对一行数据加锁,对于列存来说就是对一个CU加锁, 当一个事务update/delete未提交时,其他事务是无法同时去更新同一CU的数据的。对于事务T0和事务T1同时操作一张表时,行存表和列存表处理流程如下:
3.1 行存表处理流程
1.事务T0删除工号=1001的操作,此时工号=1001,姓名=张三该行被RowExclusive锁住,状态执行中。
2.事务T1开始执行删除工号=1001的操作,状态等锁中。
3.事务T0完成并提交,状态commit。
4.Recheck操作:事务T1获取到工号=1001该行的锁,并进行recheck操作,检查是否满足操作条件,发现不满足,则该行已不存在,反馈delete 0信息。
3.2 列存表处理流程
1.事务T0删除工号=1001的操作,此时工号=1001,姓名=张三列所在的CU被RowExclusive锁住,状态执行中。
2.事务T1开始执行 删除工号=1001的操作,状态等锁中。
3.事务T0完成并提交,状态commit。
4.事务T1获取到工号=1001,姓名=张三列所在CU的锁,进入CU进行删除操作,发现数据已删除报错ERROR: These rows have been deleted or updated。
3.3 行列存表锁机制差异总结

表5行列存表锁机制差异
行列存表差异总结如表5所示。当事务T0和事务T1同时并发操作时,对于列存表,在事务T0提交之后,事务T0释放行级锁,事务T1继续执行时没有recheck操作,导致事务T1进入被锁CU时,发现数据内容已经被删除或者更新,数据库报出ERROR错误。
四、列行存表锁机制差异带来的影响
4.1 并发删除或更新不同元组数据
对于行存表,同时提交T0和T1事务删除同一张表的不同元组,T0和T1事务会对各自删除的元组添加RowExclusive,相互不影响,删除完毕后,各自释放各自的RowExclusive。
在对列存表进行相同操作时,事务T0先对删除元组所在的CU添加RowExclusive,将整个CU所在的数据全部锁住。单个CU最多可以存储1列60000行数据,如果事务T1删除的数据也在被加锁的CU中时,事务T1将会等待事务T0删除完成并释放锁之后再进行操作。等待锁释放时间超过update_lockwait_timeout设定的阈值将会报错,在目前GaussDB数据库中,update_lockwait_timeout被默认设定为2min。
4.2 并发删除或更新同一元组数据
在不同的事务并发删除或更新同一元组数据时,对于行存表和列存表都将遵循第三章的处理流程,后提交的事务T1需要等待先提交事务T0添加的RowExclusive锁。未超时将会继续执行事务T1,对于行存表,事务T1会反馈delete 0信息,但列存表中事务T1会报出ERROR: These rows have been deleted or updated。
4.3 行列存表并发删除或更新总结
根据4.1和4.2小节中的并发或更新流程可以总结并汇总成表6所示:

表6 并发删除或更新列行存表事务返回结果
在GaussDB数据库中,对于并发删除或更新同一元组数据,列存表相比于行存表列存表缺少recheck操作,在前面事务释放CU锁后,被锁住的事务继续执行。在执行过程中,后提交的事务发现被锁CU中需要操作的数据内容已经被删除或者更新,报出ERROR错误。对于并发删除或更新不同元组数据,行存表中不同的事务是对各自操作的元组加锁,相互之间并不影响,但在列存表中,不同的事务是对CU加锁,由于每个CU中存放多列数据,当不同事务所操作的元组在同一个CU时,后提交的事务也需要等待前面事务释放锁。
五、列存表并发删除或更新报错解决方案
通过前面的分析,对列存表进行并发操作时,只要不同事务更新或删除的数据是同一元组,GaussDB数据库都会报出ERRO信息,导致脚本报错退出,对于不同元组的并发更新或删除操作仅有极低概率造成锁等待问题,并不会产生报错。解决此类ERRO报错最为有效的方法是将并发操作改为串行操作执行,但简单地从任务调度中将不同脚本串行操作会大大增加高斯任务的运行时长。如何既解决列存表ERRO报错问题,又可以尽可能减少串行操作对批量运行时间的影响呢?
脚本中通常包含大量的sql,如创建临时表,统计信息收集,数据处理等等。针对目标表的并发操作往往只存在于脚本中的某一段sql,如果能够将不同脚本并发操作同一张表的sql串行执行,而不影响其他sql的并行执行,这样既可以避免ERRO报错的产生,又能提升脚本的运行效率。
我们通过增加一个行存表control_table(只有一个字段,字段的取值为要更新的目标表名taget_a)用以控制不同脚本并发更新或删除sql的串行执行。在对目标表进行delete/update操作的语句(对同一目标表进行修改)前,人工增加一个对control_table的行级锁语句,便能够实现只针对delete或update语句的串行执行。具体实现方法如下所示:
修改前的sql:
start transaction;
update test_1……
........
end transaction;修改后的sql:
start transaction;
select name from control_table where name = 'test_1' for update;
update test_1 ......
........
end transaction;原理分析:在其他sql执行完毕后,通过start transaction开启新事务,首先开启事务的事务T0会利用for update获取control_table表中对应记录的行级锁,其他并发任务等待该行级锁释放;等到事务T0提交完成后,释放control_table的行级锁,后序事务获取行存表control_table的行锁,再提交自身的update列存表语句。通过这种方式可以实现delete/update语句的串行执行,而不影响脚本中其他sql的并行执行。
该方案从sql层面将并发delete/update同一元组操作的串行执行,避免了在脚本调度层面的串行依赖,该方案使并发delete/update列存表同一元组的行为与行存表保持一致,后发起的事务将会等待前面事务行级锁释放,超过2分钟将会提示锁超时并报错。在并发delete/update列存表不同元组时,该方案都将使后发起的事务等待前面事务的锁,而不再是极小概率等待前者事务的锁。该方案可以做为目前并发处理列存表的解决方案,但应该注意的是,并发处理同一列存表的同一个元组都应该是需要提前避免的。