SpringCloud快速上手
微服务介绍
-
- SpringCloud介绍
- Eureka服务注册与发现
- Eureka如何管理服务调用
- 服务续约、下线、剔除
- Eureka和Zookeeper区别
- 搭建Eureka服务
- 服务注册
- 客户端负载均衡
- Ribbon源码分析
- feign详解
-
- Feign简介
- RestTemplate和feign区别
- Feign使用
- Hystrix详解
-
- 服务雪崩的过程
- 为什么需要断路器?
- Hystrix特性:
- Hystrix流程结构解析
- 集成Hystrix功能
- 路由网关(zuul)
-
- 为什么需要服务网关
- 什么是网关?
- 使用zuul
- zuul过滤器
- 分布式配置中心
-
- 为什么需要分布式配置中心?
- 有哪些开源配置中心
- 技术路线兼容性
- 可用性与易用性
- 最佳选择
- 快速入门springcloud-config
-
- config-server配置
- config-client配置流程
- Config+Bus实现动态刷新
说到微服务,我们先来看看dubbo官网得一张图,相信大家对这张图也并不陌生
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dUViNOgd-1598519218675)(assets/20180804200802511.png)]
单一应用架构
当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本
ORM
用于简化增删改查工作流的,数据访问框架ORM是关键
优点:开发简单,部署也很简单
缺点:
1.扩展不容易,需要将整合应用进行打包
2.协同开发不容易,多人一起改,容易出错
3.当应用增大时,性能提升极慢
垂直应用架构
当访问量逐渐增大,单一应用增加机器带来的加速度越来越小 将应用拆分成互不干扰的几个应用,以提升效率
MVC
用于加速前端页面开发的,Web框架MVC是关键
优点:解决了单体应用得缺点问题
缺点:
1.无法做到界面+业务逻辑的实现分离
2.应用不可能完全独立,大量的应用之间需要交互
分布式服务架构
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务
逐渐形成稳定的服务中心,使前端应用能更快速的响应,多变的市场需求
RPC:远程服务调用
用于提高业务复用及整合的,分布式服务框架RPC是关键

流动计算架构
当服务越来越多,容量的评估,小服务的资源浪费等问题,逐渐明显
此时,需要增加一个调度中心 ,基于访问压力实时管理集群容量,提高集群利用率
SOA
用于提高 及其利用率的,资源调度和治理中心SOA是关键
微服务
-
微服务是一种架构风格,也是一种服务;
-
微服务的颗粒比较小,一个大型复杂软件应用由多个微服务组成,比如Netflix目前由500多个的微服务组成;
-
它采用UNIX设计的哲学,每种服务只做一件事,是一种松耦合的能够被独立开发和部署的无状态化服务(独立扩展、升级和可替换)
微服务和soa的区别
如果一句话来谈SOA和微服务的区别,即微服务不再强调传统SOA架构里面比较重的ESB企业服务总线,同时SOA的思想进入到单个业务系统内部实现真正的组件化。
微服务架构强调的第一个重点就是业务系统需要彻底的组件化和服务化,原有的单个业务系统会拆分为多个可以独立开发,设计,运行和运维的小应用。
这些小应用之间通过服务完成交互和集成。
每个小应用从前端webui,到控制层,逻辑层,数据库访问,数据库都完全是独立的一套。
在这里不用组件而用小应用这个词更加合适,每个小应用除了完成自身本身的业务功能外,重点就是还需要消费外部其它应用暴露的服务,同时自身也将自身的能力朝外部发布为服务。
面试题:什么是微服务?
但通常而言,微服务架构是—种架构模式或者说是一种架构风格,它提倡将单一应用程序划分成-一组小的服务,每个服务运行在其独立的自己的进程中,服务之间互相协调、互相配合,为用户提供最终价值。服务之间采用轻量级的通信机制互相沟通(通常是基于HTTP的REST ful API)。毎个服务都围绕着貝体业务进行构建,并且能够被独立地部罟到生产环境、类生产环境等另外,应尽量避免统一的、集中式的服务管理机制,对具体的_个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构建,可以有一个非常轻量级的集中式管理来协调这些服务,可以使用不同的语言来编写服务,也可以使用不同的数据存储。
微服务架构图
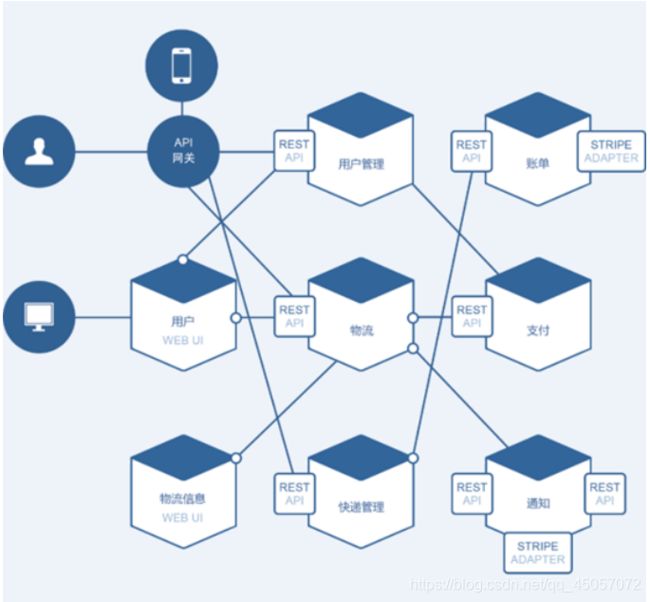
微服务的好处
-
技术异构性:在一个由多个服务相互协作的系统中,可以在不同的服务中使用最适合该服务的技术。
-
弹性:如果系统中的一个组件不可用了,但并没有导致级联故障,那么系统的其他部分还可以正常运行。
-
扩展:可以只对那些需要扩展的服务进行扩展。
-
简化部署:各个服务的部署是独立的,这样就可以更快地对特定部分的代码进行部署。
-
与组织结构相匹配:可以很好地将架构与组织结构相匹配,避免出现过大的代码库,从而获得理想团队大
小及生产力。
-
可组合性:不同服务模块的接口可以再进行重用,成为其他产品中的一个组件;
-
对可替代性的优化:可以在需要时轻易地重写服务,或者删除不再使用的服务
微服务的缺点
- 运维开销 更多的服务也就意味着更多的运维,产品团队需要保证所有的相关服务都有完善的监控等基础设
施,传统的架构开发者只需要保证一个应用正常运行,而现在却需要保证几十甚至上百道工序高效运转,
这是一个艰巨的任务。
- DevOps要求 使用微服务架构后,开发团队需要保证一个Tomcat集群可用,保证一个数据库可用,这就意
味着团队需要高品质的DevOps和自动化技术。而现在,这样的全栈式人才很少。
- 隐式接口 服务和服务之间通过接口来“联系”,当某一个服务更改接口格式时,可能涉及到此接口的所有服
务都需要做调整。
- 重复劳动 在很多服务中可能都会使用到同一个功能,而这一功能点没有足够大到提供一个服务的程度,这
个时候可能不同的服务团队都会单独开发这一功能,重复的业务逻辑,这违背了良好的软件工程中的很多
原则。
- 分布式系统的复杂性 微服务通过REST API或消息来将不同的服务联系起来,这在之前可能只是一个简单的
远程过程调用。分布式系统也就意味着开发者需要考虑网络延迟、容错、消息序列化、不可靠的网络、异
步、版本控制、负载等,而面对如此多的微服务都需要分布式时,整个产品需要有一整套完整的机制来保
证各个服务可以正常运转。
- 事务、异步、测试面临挑战 跨进程之间的事务、大量的异步处理、多个微服务之间的整体测试都需要有一
整套的解决方案,而现在看起来,这些技术并没有特别成熟。
SpringCloud介绍
springcloud是微服务架构的集大成者,将一系列优秀的组件进行了整合。基于springboot构建,对我们熟悉spring的程序员来说,上手比较容易。
通过一些简单的注解,我们就可以快速的在应用中配置一下常用模块并构建庞大的分布式系统。
SpringCloud的组件相当繁杂,拥有诸多子项目。重点关注Netflflix
下面简单介绍下经常用的5个
服务发现——Netflflix Eureka
客服端负载均衡——Netflflix Ribbon
断路器——Netflflix Hystrix
服务网关——Netflflix Zuul
分布式配置——Spring Cloud Confifig
Eureka

作用:实现服务治理(服务注册与发现)
简介:Spring Cloud Eureka是Spring Cloud Netflflix项目下的服务治理模块。
由两个组件组成:Eureka服务端和Eureka客户端。
Eureka服务端用作服务注册中心。支持集群部署。
Eureka客户端是一个java客户端,用来处理服务注册与发现。
在应用启动时,Eureka客户端向服务端注册自己的服务信息,同时将服务端的服务信息缓存到本地。客户端会和服
务端周期性的进行心跳交互,以更新服务租约和服务信息。
Ribbon
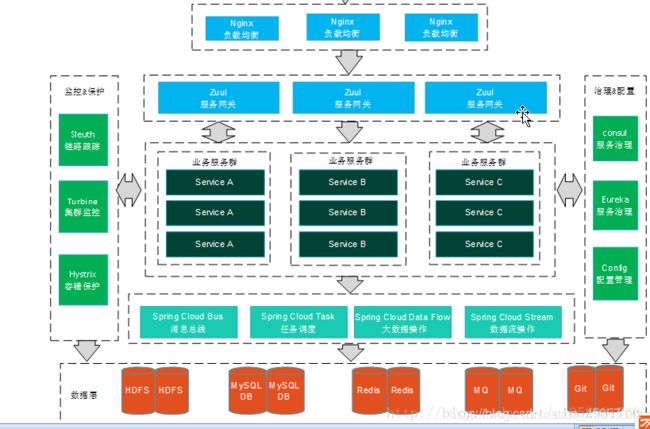
作用:Ribbon,主要提供客户侧的软件负载均衡算法。
简介:Spring Cloud Ribbon是一个基于HTTP和TCP的客户端负载均衡工具,它基于Netflflix Ribbon实现。通过
Spring Cloud的封装,可以让我们轻松地将面向服务的REST模版请求自动转换成客户端负载均衡的服务调用。
注意看上图,关键点就是将外界的rest调用,根据负载均衡策略转换为微服务调用。Ribbon有比较多的负载均衡策略,以后专门讲解。
Hystrix
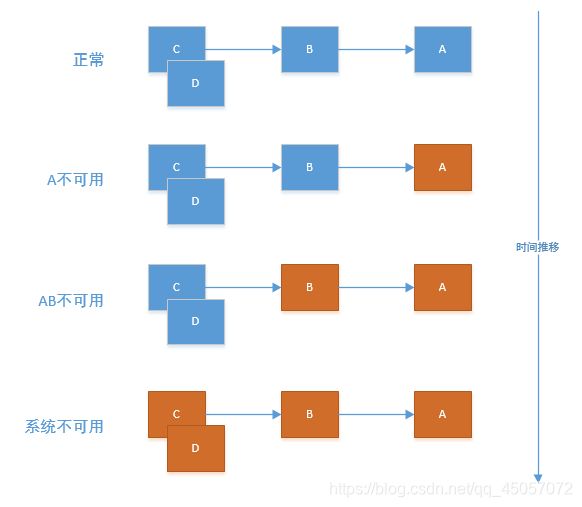
作用:断路器,保护系统,控制故障范围。
简介:为了保证其高可用,单个服务通常会集群部署。由于网络原因或者自身的原因,服务并不能保证100%可用, 如果单个服务出现问题,调用这个服务就会出现线程阻塞,此时若有大量的请求涌入,Servlet容器的线程资源会被消耗完毕,导致服务瘫痪。服务与服务之间的依赖性,故障会传播,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的“雪崩”效应。
Zuul
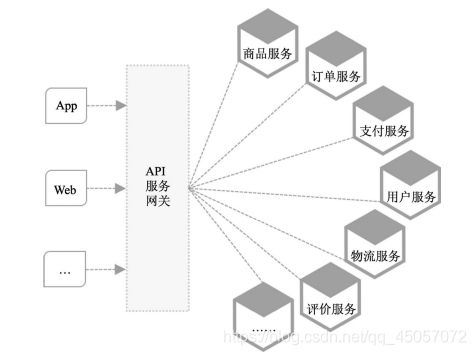
作用:api网关,路由,负载均衡等多种作用
简介:类似nginx,反向代理的功能,不过netflix自己增加了一些配合其他组件的特性。
在微服务架构中,后端服务往往不直接开放给调用端,而是通过一个API网关根据请求的url,路由到相应的服务。当添加API网关后,在第三方调用端和服务提供方之间就创建了一面墙,这面墙直接与调用方通信进行权限控制,后将请求均衡分发给后台服务端。
Config
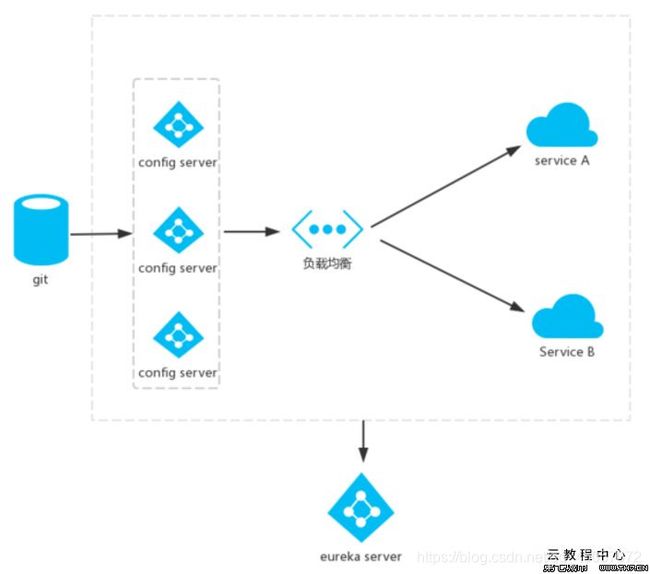
作用:配置管理
简介:SpringCloud Confifig提供服务器端和客户端。服务器存储后端的默认实现使用git,因此它轻松支持标签版本的 配置环境,以及可以访问用于管理内容的各种工具。
这个还是静态的,得配合Spring Cloud Bus实现动态的配置更新。
相关组件架构图

从上图可以看出Spring Cloud各个组件相互配合,合作支持了一套完整的微服务架构。
• 其中Eureka负责服务的注册与发现,很好将各服务连接起来
• Hystrix 负责监控服务之间的调用情况,连续多次失败进行熔断保护。
• Hystrix dashboard,Turbine 负责监控 Hystrix的熔断情况,并给予图形化的展示
• Spring Cloud Confifig 提供了统一的配置中心服务
• 当配置文件发生变化的时候,Spring Cloud Bus 负责通知各服务去获取最新的配置信息
• 所有对外的请求和服务,我们都通过Zuul来进行转发,起到API网关的作用
• 最后我们使用Sleuth+Zipkin将所有的请求数据记录下来,方便我们进行后续分析
为什么要使用SpringCloud?
Spring Cloud从设计之初就考虑了绝大多数互联网公司架构演化所需的功能,如服务发现注册、配置中心、消息总
线、负载均衡、断路器、数据监控等。这些功能都是以插拔的形式提供出来,方便我们系统架构演进的过程中,可以 合理的选择需要的组件进行集成,从而在架构演进的过程中会更加平滑、顺利。
微服务架构是一种趋势,Spring Cloud提供了标准化的、全站式的技术方案,意义可能会堪比当前Servlet规范的诞 生,有效推进服务端软件系统技术水平的进步。
SpringCloud官网
Spring Cloud中文文档
官方文档
面试题:微服务之间是如何独立通讯的spring Cloud和Dubbo有哪些区別?
最大区别: SpringCloud抛弃了 Dubbo的RPC通信,采用的是基于HTP的REST方式。
严格来说,这两种方式各有优劣。虽然从一定程度上来说,后者牺牲了服务调用的性能,但也避兔了上面提到的原生RPC带来的问题。
而且REST相比RPC更为灵活,服务提供方和调用方的依赖只依靠一纸契约,不存在代码级别的强依赖,这在强调快速演化的微服务环境下,显得更加合适
选择题:以下哪些方式可以实现微服务:
A:SpringBoot
B:SpringBoot+SpringCloud
C:SpringCloud(不能独立存在的,必须要依赖SpringBoot)
D:Dubbo+Zookeeper
扩展:
dubbo是一个分布式服务框架,是阿里巴巴SOA服务化治理方案的核心框架。zookeeper是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。zookeeper可以作为dubbo服务的注册中心,两者结合起来可以实现微服务中的 服务注册、发现、负载均衡和健康检查,容错,动态配置管理的功能。由于dubbo没有提供前端路由的功能,所以我们还需实现一个具备监控、安全认证、限流、服务反向路由功能的网关组件才能实现完整的微服务,这个组件实现起来比较复杂。
Eureka服务注册与发现
为什么需要服务中心
过去,每个应用都是一个CPU,一个主机上的单一系统。然而今天,随着大数据和云计算时代的到来,任何独立的程序都可以运行在多个计算机上。并且随着业务的发展,访问用户量的增加,开发人员或小组的增加,系统会被拆分成多个功能模块。拆分后每个功能模块可以作为一个独立的子系统提供其职责范围内的功能。而多个子系统中,由于职责不同并且会存在相互调用,同时可能每个子系统还需要多个实例部署在多台服务器或者镜像中,导致了子系统间的相互调用形成了一个错综复杂的网状结构。用几幅图说明一下:
单体应用:

随着业务的发展,经过了多个系统架构的演变,变成了这样(拿百度的功能举个栗子):
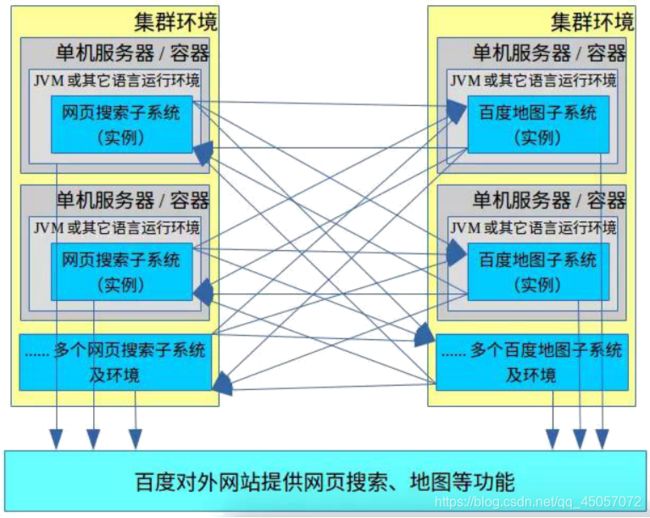
图中,每个网页搜索子系统和百度地图子系统的实例都可以视同为一个微服务。网页搜索子系统为百度地图子系统提供了“用户查询内容、用户IP地址”等信息提供的服务接口,为百度地图子系统定位用户地理信息情况提供数据依据。
百度地图子系统提供了“根据内容查询出地图信息”的接口提供给其他子系统调用,而这里网页搜索子系统调用了这个接口,获取地图相关信息。
网页搜索子系统和百度地图子系统又提供了各自对外用户调用的网页搜索、地图搜索等各自的对外服务。这个过程就形成了以上错综复杂的网状结构。而实际上这样还远远不够,因为每个子系统往往会提供多个对内的其他子系统调用的服务接口,同时也会调用多个不同子系统提供的多个服务接口,还会对外提供多个各自的服务接口。所以实际中上图的网状调用结构将会成几何倍的扩张。而且随着用户量的增加,每个子系统还需要继续增加更多的实例来提供服务,从而导致了凌乱的加剧。
对于微服务之间错综复杂的调用关系,通过eureka来管理,可以让每个服务之间不用关心如何调用的问题,专注于自己的业务功能实现。
Eureka的管理:
基于以上概念,使用Eureka管理时会具备几个特性:
→服务需要有一个统一的名称(或服务ID)并且是唯一标识,以便于接口调用时各个接口的区分。并且需要将其注册到Eureka Server中,其他服务调用该接口时,也是根据这个唯一标识来获取。
→服务下有多个实例,每个实例也有一个自己的唯一实例ID。因为它们各自有自己的基础信息如:不同的IP。所以它们的信息也需要注册到Eureka Server中,其他服务调用它们的服务接口时,可以查看到多个该服务的实例信息,根据负载策略提供某个实例的调用信息后,调用者根据信息直接调用该实例。
Eureka如何管理服务调用
eureka如何管理服务调用的?我们先来看个图:

→在Eureka Client启动的时候,将自身的服务的信息发送到Eureka Server。然后进行2调用当前服务器节点中的其他服务信息,保存到Eureka Client中。当服务间相互调用其它服务时,在Eureka Client中获取服务信息(如服务地址,端口等)后,进行第3步,根据信息直接调用服务。(注:服务的调用通过http(s)调用)
→当某个服务仅需要调用其他服务,自身不提供服务调用时。在Eureka Client启动后会拉取Eureka Server的其他服务信息,需要调用时,在Eureka Client的本地缓存中获取信息,调用服务。
→Eureka Client通过向Eureka Serve发送心跳(默认每30秒)来续约服务的。 如果客户端持续不能续约,那么,它将在大约90秒内从服务器注册表中删除。 注册信息和续订被复制到集群中的Eureka Serve所有节点。 以此来确保当前服务还“活着”,可以被调用。
Eureka Server和Eureka Client
Eureka Server:
- 提供服务注册:各个微服务启动时,会通过Eureka Client向Eureka Server进行注册自己的信息(例如服务信息和网络信息),Eureka Server会存储该服务的信息。
- 提供服务信息提供:服务消费者在调用服务时,本地Eureka Client没有的情况下,会到Eureka Server拉取信息。
- 提供服务管理:通过Eureka Client的Cancel、心跳监控、renew等方式来维护该服务提供的信息以确保该服务可用以及服务的更新。
- 信息同步:每个Eureka Server同时也是Eureka Client,多个Eureka Server之间通过P2P复制的方式完成服务注册表的同步。
Eureka Client
- Eureka Client是一个Java客户端,用于简化与Eureka Server的交互。并且管理当前微服务,同时为当前的微服务提供服务提供者信息。
- Eureka Client会拉取、更新和缓存Eureka Server中的信息。即使所有的Eureka Server节点都宕掉,服务消费者依然可以使用缓存中的信息找到服务提供者。
- Eureka Client在微服务启动后,会周期性地向Eureka Server发送心跳(默认周期为30秒)以续约自己的信息。如果Eureka Server在一定时间内没有接收到某个微服务节点的心跳,Eureka Server将会注销该微服务节点(默认90秒)。
- 来自任何区域的Eureka Client都可以查找注册表信息(每30秒发生一次),以此来确保调用到的服务是“活的”。并且当某个服务被更新或者新加进来,也可以调用到新的服务。
服务续约、下线、剔除
服务续约
Application Service内的Eureka Client后台启动一个定时任务,跟Eureka Server保持一个心跳续约任务,每隔一段时间(默认30S)向Eureka Server发送一次renew请求,进行续约,告诉Eureka Server我还活着,防止被Eureka Server的Evict任务剔除。
服务下线
Application Service应用停止后,向Eureka Server发送一个cancel请求,告诉注册中心我已经退出了,Eureka Server接收到之后会将其移出注册列表,后面再有获取注册服务列表的时候就获取不到了,防止消费端消费不可用的服务。
服务剔除
Eureka Server启动后在后台启动一个Evict任务,对一定时间内没有续约的服务进行剔除。
服务通讯方式
服务间使用标准的REST方式通讯,所以Eureka服务注册中心并不仅适用于Java平台,其他平台也可以纳入到服务治理平台里面。
自我保护
本地调试Eureka的程序时,会出现:
![]()
该警告是触发了Eureka Server的自我保护机制。
Eureka Server在运行期间,会统计心跳失败的比例在15分钟之内是否低于85%,如果低于,就会将当前实例注册信息保护起来,让实例不会过期,尽可能保护这些注册信息。
但是如果在保护期间,实例出现问题,那么客户端很容易拿到实际已经不存在的服务实例,会出现调用失败。这个时候客户端的容错机制就很重要了。(重新请求,断路器)
保护机制,可能会导致服务实例不能够被正确剔除。
在本地开发时,可使用:eureka.server.enable-self-preservation=false关闭保护机制,使不可用实例能够正常下线。
Eureka和Zookeeper区别
- Eureka:可以在发生因网络问题导致的各节点失去联系也不会暂停服务,但是最新的数据可能不统一。
- Zookeeper:如果发生网络问题导致的Master和其他节点失去联系,就会使得其他的节点推选出新的Master,但是推选的时间内无法提供服务,但是可以保证任何时候的数据都是统一的。
搭建Eureka服务
使用idea快速构建SpringCloud微服务项目
因为本次项目是作为一个分布式得微服务项目,那我们肯定是启用模块化得方式创建我们得项目




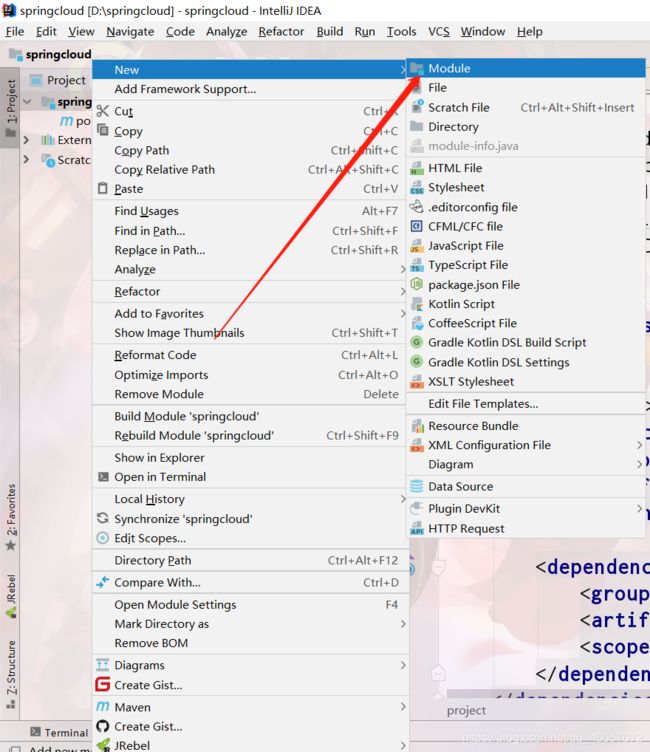
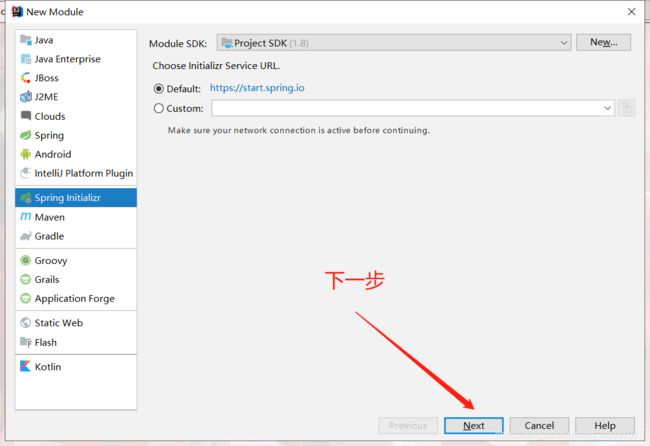
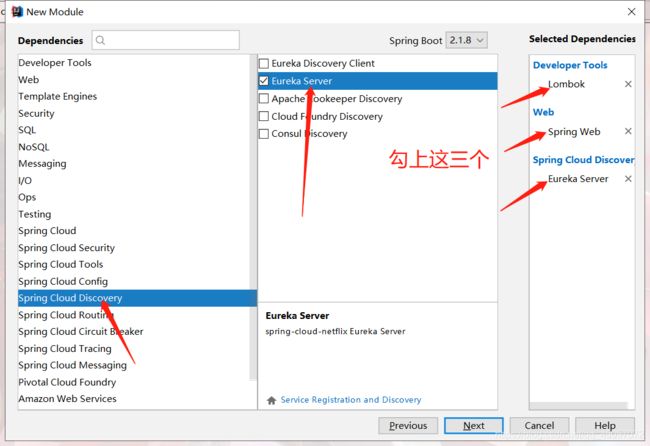
创建完项目之后,配置项目的yml信息
###设置项目名称
spring:
application:
name: eureka-server
###设置端口号(因为是微服务的项目,一个项目中有多个子模块,每个子模块都是独立的)
server:
port: 8080
###配置eureka的基本信息
eureka:
instance:
hostname: localhost
client:
service-url:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
###因为自己是为注册中心,是否向服务注册中心注册自己
register-with-eureka: false
###因为自己是为注册中心,是否检索服务
fetch-registry: false
配置完毕之后,一定要在启动类上加上一个注解
@SpringBootApplication
/*开启Eureka的服务*/
@EnableEurekaServer
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
开始访问
http://localhost:8080/
出现

说明Eureka配置成功
服务注册
eureka-grade
spring:
application:
name: eureka-grade
server:
port: 8081
eureka:
client:
register-with-eureka: true
fetch-registry: true
service-url:
defaultZone: http://localhost:8080/eureka
@SpringBootApplication
@EnableEurekaClient
public class EurekaGradeApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaGradeApplication.class, args);
}
}
@RestController
public class GradeController {
@RequestMapping("/get/{id}")
public String getGrade(@PathVariable("id") Integer id){
return id==1?"一期":id==2?"二期":"N期";
}
}
eureka-student
spring:
application:
name: eureka-student
server:
port: 8082
eureka:
client:
register-with-eureka: true
fetch-registry: true
service-url:
defaultZone: http://localhost:8080/eureka
@SpringBootApplication
@EnableEurekaClient
public class EurekaStudentApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaStudentApplication.class, args);
}
@Bean
@LoadBalanced
RestTemplate restTemplate(){
return new RestTemplate();
}
}
//具体参考:https://blog.csdn.net/u011063112/article/details/81295376
@Service
public class StudentService {
@Autowired
private RestTemplate restTemplate;
public String getMsg(Integer id) {
String url = "http://eureka-grade/get/{id}";
return restTemplate.getForObject(url,String.class,id);
}
}
@RestController
public class StudentController {
@Autowired
private StudentService studentService;
@RequestMapping("/getMsg")
public String getMsg(String name,Integer id){
String gradeName = studentService.getMsg(id);
return "欢迎来自"+gradeName+"的"+name+"同学";
}
}
面试题:请说说eureka和 zookeeper,两个的区別?
首先我们先说下:
RDBMS==>(MySql,Oracle,SqlServer等关系型数据库)遵循的原则是:ACID原则(A:原子性。C:一致性。I:独立性。D:持久性。)。
NoSql==> (redis,Mogodb等非关系型数据库)遵循的原则是:CAP原则(C:强一致性。A:可用性。P:分区容错性)。
首先 说CAP 是什么 所谓的CAP C强一致性 A可用性 P 分区容错性
Zookeeper保证了CP(C:一致性,P:分区容错性),Eureka保证了AP(A:高可用)
Zookeeper的设计理念就是分布式协调服务,保证数据(配置数据,状态数据)在多个服务系统之间保证一致性,这也不难看出Zookeeper是属于CP特性(Zookeeper的核心算法是Zab,保证分布式系统下,数据如何在多个服务之间保证数据同步)。Eureka是吸取Zookeeper问题的经验,先保证可用性。
客户端负载均衡
负载均衡在系统架构中是一个非常重要,并且是不得不去实施的内容。因为负载均衡是对系统的高可用、网络压力的缓解和处理能力扩容的重要手段之一。我们通常所说的负载均衡都指的是服务端负载均衡,其中分为硬件负载均衡和软件负载均衡。硬件负载均衡主要通过在服务器节点之间按照专门用于负载均衡的设备,比如F5等;而软件负载均衡则是通过在服务器上安装一些用于负载均衡功能或模块等软件来完成请求分发工作,比如Nginx等。不论采用硬件负载均衡还是软件负载均衡,只要是服务端都能以类似下图的架构方式构建起来:

负载均衡架构图
硬件负载均衡的设备或是软件负载均衡的软件模块都会维护一个下挂可用的服务端清单,通过心跳检测来剔除故障的服务端节点以保证清单中都是可以正常访问的服务端节点。当客户端发送请求到负载均衡设备的时候,该设备按某种算法(比如线性轮询、按权重负载、按流量负载等)从维护的可用服务端清单中取出一台服务端端地址,然后进行转发。
而客户端负载均衡和服务端负载均衡最大的不同点在于上面所提到服务清单所存储的位置。在客户端负载均衡中,所有客户端节点都维护着自己要访问的服务端清单,而这些服务端端清单来自于服务注册中心,比如上一章我们介绍的Eureka服务端。同服务端负载均衡的架构类似,在客户端负载均衡中也需要心跳去维护服务端清单的健康性,默认会创建针对各个服务治理框架的Ribbon自动化整合配置,
比如Eureka中的org.springframework.cloud.netflix.ribbon.eureka.RibbonEurekaAutoConfiguration,
Consul中的org.springframework.cloud.consul.discovery.RibbonConsulAutoConfiguration。
在实际使用的时候,我们可以通过查看这两个类的实现,以找到它们的配置详情来帮助我们更好地使用它。
通过SpringCloud Ribbon的封装,我们在微服务架构中使用客户端负载均衡调用非常简单,只需要如下两步:
▪ 服务提供者只需要启动多个服务实例并注册到一个注册中心或是多个相关联的服务注册中心。
▪ 服务消费者直接通过调用被@LoadBalanced注解修饰过的RestTemplate来实现面向服务的接口调用。
这样,我们就可以将服务提供者的高可用以及服务消费者的负载均衡调用一起实现了。
| 内置负载均衡规则类 | 规则描述 |
|---|---|
| RoundRobinRule | 简单轮询服务列表来选择服务器。它是Ribbon默认的负载均衡规则 |
| AvailabilityFilteringRule | 对以下两种服务器进行忽略: (2)在默认情况下,这台服务器如果3次连接失败,这台服务器就会被设置 |
为“短路”状态。短路状态将持续30秒,如果再次连接失败,短路的持续时间
就会几何级地增加。
(2)并发数过高的服务器。如果一个服务器的并发连接数过高,配置了
AvailabilityFilteringRule规则的客户端也会将其忽略。并发连接数的上线,
可以由客户端的进行配置。
| WeightedResponseTimeRule | 为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重
就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择。 |
| ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分
类,这个Zone可以理解为一个机房、一个机架等。 |
| BestAvailableRule | 忽略哪些短路的服务器,并选择并发数较低的服务器 |
| RandomRule | 随机选择一个可用的服务器 |
| Retry | 重试机制的选择逻辑 |
修改负载均衡的配置
#自定义负载均衡策略,随机分配
#调用的服务名称为product-service(怕名字错误可直接看注册中心名字)
eureka-order:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
Ribbon源码分析
LoadBalancerAutoConfiguration.java为实现客户端负载均衡器的自动化配置类。
@Bean
@ConditionalOnMissingBean
public RestTemplateCustomizer restTemplateCustomizer(
final RetryLoadBalancerInterceptor loadBalancerInterceptor) {
return restTemplate -> {
List<ClientHttpRequestInterceptor> list = new ArrayList<>(
restTemplate.getInterceptors());
list.add(loadBalancerInterceptor);
restTemplate.setInterceptors(list);
};
}
在自动化配置中主要做三件事:
- 创建一个LoadBalancerInterceptor的Bean,用于实现对客户端发起请求时进行拦截,以实现客户端负载均衡。
- 创建一个RestTemplateCustomizer的Bean,用于给RestTemplate增加LoadBalancerInterceptor拦截器。
- 维护了一个被@LoadBalanced注解修饰的RestTemplate对象列表,并在这里进行初始化,通过调用RestTemplateCustomizer的实例来给需要客户端负载均衡的RestTemplate增加LoadBalancerInterceptor拦截器。
从@LoadBalanced注解码的注释中,可以知道该注解用来给RestTemplate标记,以使用负载均衡的客户端(LoadBalancerClient)来配置它。
- LoadBalancerClient
public interface LoadBalancerClient extends ServiceInstanceChooser {
<T> T execute(String var1, LoadBalancerRequest<T> var2) throws IOException;
//从负载均衡器中挑选出的服务实例来执行请求内容。
<T> T execute(String var1, ServiceInstance var2, LoadBalancerRequest<T> var3) throws IOException;
//为了给一些系统使用,创建一个带有真实host和port的URI。
//一些系统使用带有原服务名代替host的URI,比如http://myservice/path/to/service。
//该方法会从服务实例中取出host:port来替换这个服务名。
URI reconstructURI(ServiceInstance var1, URI var2);
}
- 父接口ServiceInstanceChooser
public interface ServiceInstanceChooser {
/**
*Choose a ServiceInstance from the LoadBalancer for the specified service
*@param serviceId the service id to look up the LoadBalancer
*@return a ServiceInstance that matches the serviceId
*/
//根据传入的服务名serviceId,从负载均衡器中挑选一个对应服务的实例。
ServiceInstance choose(String serviceId);
}
- RibbonLoadBalancerClient 实现类代码
@Override
public <T> T execute(String serviceId, LoadBalancerRequest<T> request) throws IOException {
//获取负载均衡策略
ILoadBalancer loadBalancer = getLoadBalancer(serviceId);
//根据负载均衡策略,获取一个服务器
Server server = getServer(loadBalancer);
if (server == null) {
throw new IllegalStateException("No instances available for " + serviceId);
}
RibbonServer ribbonServer = new RibbonServer(serviceId, server, isSecure(server, serviceId),
serverIntrospector(serviceId).getMetadata(server));
return execute(serviceId, ribbonServer, request);
}
- ILoadBalancer接口
public interface ILoadBalancer {
//向负载均衡器的实例列表中增加实例
public void addServers(List<Server> newServers);
//通过某种策略,从负载均衡器中选择一个具体的实例
public Server chooseServer(Object key);
//用来通知和标识负载均衡器中某个具体实例已经停止服务,不然负载均衡器在下一次获取服务实例清单前都会 认为服务实例均是正常服务的。
public void markServerDown(Server server);
//获取正常服务列表
public List<Server> getReachableServers();
//所有已知实例列表
public List<Server> getAllServers();
}
- LoadBalancerContext类中实现
//转换host:port形式的请求地址。
public URI reconstructURIWithServer(Server server, URI original) {
String host = server.getHost();
int port = server.getPort();
String scheme = server.getScheme();
if (host.equals(original.getHost())
&& port == original.getPort()
&& scheme == original.getScheme()) {
return original;
}
if (scheme == null) {
scheme = original.getScheme();
}
if (scheme == null) {
scheme = deriveSchemeAndPortFromPartialUri(original).first();
}
try {
StringBuilder sb = new StringBuilder();
sb.append(scheme).append("://");
if (!Strings.isNullOrEmpty(original.getRawUserInfo())) {
sb.append(original.getRawUserInfo()).append("@");
}
sb.append(host);
if (port >= 0) {
sb.append(":").append(port);
}
sb.append(original.getRawPath());
if (!Strings.isNullOrEmpty(original.getRawQuery())) {
sb.append("?").append(original.getRawQuery());
}
if (!Strings.isNullOrEmpty(original.getRawFragment())) {
sb.append("#").append(original.getRawFragment());
}
URI newURI = new URI(sb.toString());
return newURI;
} catch (URISyntaxException e) {
throw new RuntimeException(e);
}
}
feign详解
Feign简介
Feign是Netflix开发的声明式、模板化的HTTP客户端, Feign可以帮助我们更快捷、优雅地调用HTTP API。
Feign是一个声明式的伪Http客户端,它使得写Http客户端变得更简单。使用Feign,只需要创建一个接口并注解。Feign默认集成了Ribbon,并和Eureka结合,默认实现了负载均衡的效果。
简而言之:
Feign 采用的是基于接口的注解
RestTemplate和feign区别
使用 RestTemplate时 ,URL参数是以编程方式构造的,数据被发送到其他服务。
Feign是Spring Cloud Netflix库,用于在基于REST的服务调用上提供更高级别的抽象。Spring Cloud Feign在声明性原则上工作。使用Feign时,我们在客户端编写声明式REST服务接口,并使用这些接口来编写客户端程序。开发人员不用担心这个接口的实现。
再说,就是简化了编写,RestTemplate还需要写上服务器IP这些信息等等,而FeignClient则不用。
Feign使用
github Feign:https://github.com/OpenFeign/feign
- 添加pom文件
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-openfeignartifactId>
<version>2.1.1.RELEASEversion>
dependency>
- 在启动类上,添加开feign注解
@SpringBootApplication
@EnableEurekaClient
@EnableFeignClients
public class EurekaGoodApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaGoodApplication.class, args);
}
@Bean
@LoadBalanced
RestTemplate restTemplate(){
return new RestTemplate();
}
}
- 使用Feign
@FeignClient(value = "eureka-order")
public interface FeignService {
@RequestMapping(value = "/getOrderNum",method = RequestMethod.GET)
String getOrderNum();
@RequestMapping(value = "/postOrder",method = RequestMethod.POST)
String postOrder(Order order);
}
- controller中
@RestController
public class GoodController {
@Autowired
private GoodService goodService;
@Autowired
private FeignService feignService;
@RequestMapping("/getGoodNum")
public String getGoodNum(String goodName) {
return "商品" + goodName + "的订单号是:" + goodService.getOrderNum();
}
@RequestMapping("/getGoodNum2")
public String getGoodNum2(String goodName) {
return "商品" + goodName + "的订单号是:" + feignService.getOrderNum();
}
@RequestMapping("/postOrder")
public String postOrder() {
Order order = new Order();
order.setId(1);
order.setOrderName("青木的包裹");
String s = feignService.postOrder(order);
return "生成订单"+s;
}
}
Hystrix详解
服务雪崩的过程
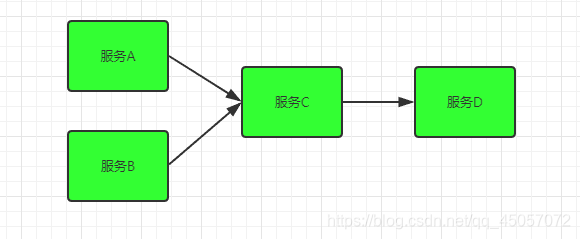
上面是一组简单的服务依赖关系A,B服务同时依赖于基础服务C,基础服务C又调用了服务D
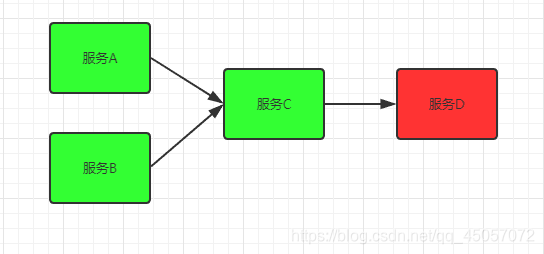
服务D是一个辅助类型服务,整个业务不依赖于D服务,某天D服务突然响应时间变长,导致了核心服务C响应时间变长,其上请求越积越多,C服务也出现了响应变慢的情况,由于A,B强依赖于服务C,故而一个无关紧要的服务却影响了整个系统的可用
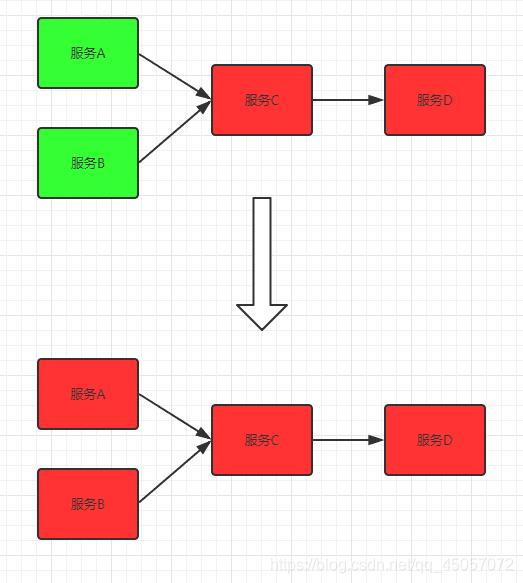
雪崩是系统中的蝴蝶效应导致其发生的原因多种多样,有不合理的容量设计,或者是高并发下某一个方法响应变慢,亦或是某台机器的资源耗尽。从源头上我们无法完全杜绝雪崩源头的发生,但是雪崩的根本原因来源于服务之间的强依赖,所以我们可以提前评估,做好熔断,隔离,限流。
为什么需要断路器?
在微服务架构中,根据业务来拆分成一个个的服务,服务与服务之间可以相互调用,在Spring Cloud可以用RestTemplate+Ribbon和Feign来调用。为了保证其高可用,单个服务通常会集群部署。由于网络原因或者自身的原因,服务并不能保证100%可用,如果单个服务出现问题,调用这个服务就会出现线程阻塞,此时若有大量的请求涌入,Servlet容器的线程资源会被消耗完毕,导致服务瘫痪。服务与服务之间的依赖性,故障会传播,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的“雪崩”效应。
为了解决这个问题,业界提出了断路器模型。
断路器简介
Netflix开源了Hystrix组件,实现了断路器模式,SpringCloud对这一组件进行了整合。 在微服务架构中,一个请求需要调用多个服务是非常常见的,如下图:

较底层的服务如果出现故障,会导致连锁故障。当对特定的服务的调用的不可用达到一个阀值(Hystric 是5秒20次) 断路器将会被打开。
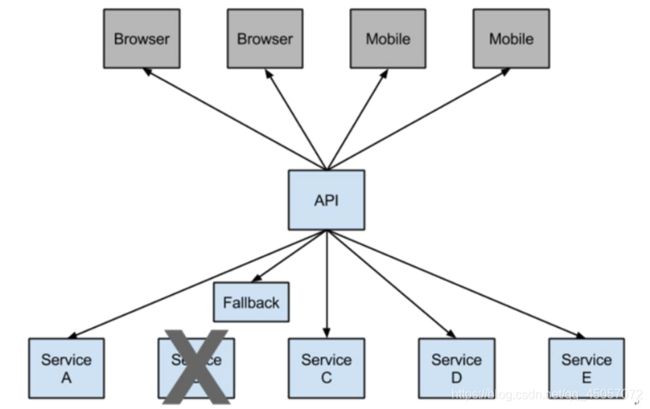
断路打开后,可用避免连锁故障,fallback方法可以直接返回一个固定值。
Hystrix特性:
-
请求熔断: 当Hystrix Command请求后端服务失败数量超过一定比例(默认50%), 断路器会切换到开路状态 (Open). 这时所有请求会直接失败而不会发送到后端服务. 断路器保持在开路状态一段时间后(默认5秒), 自动切换到半开路状态(HALF-OPEN).这时会判断下一次请求的返回情况, 如果请求成功, 断路器切回闭路状态(CLOSED), 否则重新切换到开路状态 (OPEN). Hystrix的断路器就像我们家庭电路中的保险丝, 一旦后端服务不可用, 断路器会直接切断请求链, 避免发送大量无效请求影响系统吞吐量, 并且断路器有自我检测并恢复的能力.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ycyqjrql-1598519218720)(D:\youruike\SpringCloud\assets\13293655-3bc682c84d8d6318-1571312898578.png)]
1.请求错误率达到某一阈值,熔断器全开,产生熔断(熔断期间会对所有请求采用降级处理)
2.到熔断时间窗口之后,熔断器会进入半开状态,此时hystrix会放过1个试验性请求
3.如果该试验性请求成功,熔断器进入关闭状态
4.如果该试验性请求失败,熔断器重新进入全开状态
-
服务降级:Fallback相当于是降级操作. 对于查询操作, 我们可以实现一个fallback方法, 当请求后端服务出现异常的时候, 可以使用fallback方法返回的值. fallback方法的返回值一般是设置的默认值或者来自缓存.告知后面的请求服务不可用了,不要再来了。
-
依赖隔离(采用舱壁模式,Docker就是舱壁模式的一种):在Hystrix中, 主要通过线程池来实现资源隔离。通常在使用的时候我们会根据调用的远程服务划分出多个线程池。比如说,一个服务调用两外两个服务,你如果调用两个服务都用一个线程池,那么如果一个服务卡在哪里,资源没被释放,后面的请求又来了,导致后面的请求都卡在哪里等待,导致你依赖的A服务把你卡在哪里,耗尽了资源,也导致了你另外一个B服务也不可用了。这时如果依赖隔离,某一个服务调用A B两个服务,如果这时我有100个线程可用,我给A服务分配50个,给B服务分配50个,这样就算A服务挂了,我的B服务依然可以用。
-
请求缓存:比如一个请求过来请求我userId=1的数据,你后面的请求也过来请求同样的数据,这时我不会继续走原来的那条请求链路了,而是把第一次请求缓存过了,把第一次的请求结果返回给后面的请求。
-
请求合并:我依赖于某一个服务,我要调用N次,比如说查数据库的时候,我发了N条请求发了N条SQL然后拿到一堆结果,这时候我们可以把多个请求合并成一个请求,发送一个查询多条数据的SQL的请求,这样我们只需查询一次数据库,提升了效率。
Hystrix流程结构解析

- 流程说明
1:每次调用创建一个新的HystrixCommand,把依赖调用封装在run()方法中.
2:执行execute()/queue做同步或异步调用.
3:判断熔断器(circuit-breaker)是否打开,如果打开跳到步骤8,进行降级策略,如果关闭进入步骤.
4:判断线程池/队列/信号量是否跑满,如果跑满进入降级步骤8,否则继续后续步骤.
5:调用HystrixCommand的run方法.运行依赖逻辑
5a:依赖逻辑调用超时,进入步骤8.
6:判断逻辑是否调用成功
6a:返回成功调用结果
6b:调用出错,进入步骤8.
7:计算熔断器状态,所有的运行状态(成功, 失败, 拒绝,超时)上报给熔断器,用于统计从而判断熔断器状态.
8:getFallback()降级逻辑.
以下四种情况将触发getFallback调用:
(1):run()方法抛出非HystrixBadRequestException异常。
(2):run()方法调用超时
(3):熔断器开启拦截调用
(4):线程池/队列/信号量是否跑满
8a:没有实现getFallback的Command将直接抛出异常
8b:fallback降级逻辑调用成功直接返回
8c:降级逻辑调用失败抛出异常
9:返回执行成功结果
集成Hystrix功能
- 添加pom文件
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-hystrixartifactId>
dependency>
- 启动类中开启
@SpringBootApplication
@EnableEurekaClient
@EnableFeignClients
@EnableHystrix
public class EurekaGoodApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaGoodApplication.class, args);
}
@Bean
@LoadBalanced
RestTemplate restTemplate(){
return new RestTemplate();
}
}
- 添加fallback类
@Component
public class FeignServiceImpl implements FeignService{
@Override
public String getOrderNum() {
return "getOrderNum失败";
}
@Override
public String postOrder(Order order) {
return "postOrder失败";
}
}
- yml中的配置
feign:
hystrix:
enabled: true
- RestTemplate实现服务降级操作
@Service
public class GoodService {
@Autowired
private RestTemplate restTemplate;
@HystrixCommand(fallbackMethod = "getOrderNumFall")
public String getOrderNum(){
String url ="http://eureka-order/getOrderNum";
return restTemplate.getForObject(url,String.class,"");
}
//添加服务降级处理方法
public String getOrderNumFall(){
return "getOrderNumFall";
}
}
- 依赖隔离实现
添加GoodCommand
package com.ddmzx.eurekagood.service.pool;
import com.netflix.hystrix.*;
public class GoodCommand extends HystrixCommand<String> {
private String value;
public GoodCommand(String value) {
super(HystrixCommand.Setter.withGroupKey(
//服务分组
HystrixCommandGroupKey.Factory.asKey("GoodGroup"))
//线程分组
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("GoodPool"))
//线程池配置
.andThreadPoolPropertiesDefaults(HystrixThreadPoolProperties.Setter()
.withCoreSize(10)
.withKeepAliveTimeMinutes(5)
.withMaxQueueSize(10)
.withQueueSizeRejectionThreshold(10000))
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withExecutionIsolationStrategy(HystrixCommandProperties.ExecutionIsolationStrategy.THREAD)));
this.value = value;
}
@Override
protected String run() throws Exception {
String threadName = Thread.currentThread().getName();
return threadName + "--->" + value;
}
}
添加OrderCommand
package com.ddmzx.eurekagood.service.pool;
import com.netflix.hystrix.*;
public class OrderCommand extends HystrixCommand<String> {
private String value;
public OrderCommand(String value) {
super(Setter.withGroupKey(
//服务分组
HystrixCommandGroupKey.Factory.asKey("OrderGroup"))
//线程分组
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("OrderPool"))
//线程池配置
.andThreadPoolPropertiesDefaults(HystrixThreadPoolProperties.Setter()
.withCoreSize(10)
.withKeepAliveTimeMinutes(5)
.withMaxQueueSize(10)
.withQueueSizeRejectionThreshold(10000))
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withExecutionIsolationStrategy(HystrixCommandProperties.ExecutionIsolationStrategy.THREAD)));
this.value = value;
}
@Override
protected String run() throws Exception {
String threadName = Thread.currentThread().getName();
return threadName+"--->"+value;
}
}
在GoodService.java中添加测试方法
public String testPool() throws ExecutionException, InterruptedException {
GoodCommand good = new GoodCommand("小米");
OrderCommand order1 = new OrderCommand("001");
OrderCommand order2 = new OrderCommand("002");
//同步调用
String val1 = good.execute();
String val2 = order1.execute();
String val3 = order2.execute();
//异步调用
Future<String> f1 = good.queue();
Future<String> f2 = order1.queue();
Future<String> f3 = order2.queue();
//return "val1=" + val1 + "val2=" + val2 + "val3=" + val3;
return "f1=" + f1.get() + "f2=" + f2.get() + "f3=" + f3.get();
}
Controller.java中添加
@RequestMapping("/testPool")
public String testPool() {
return goodService.testPool();
}
请求合并是做什么的
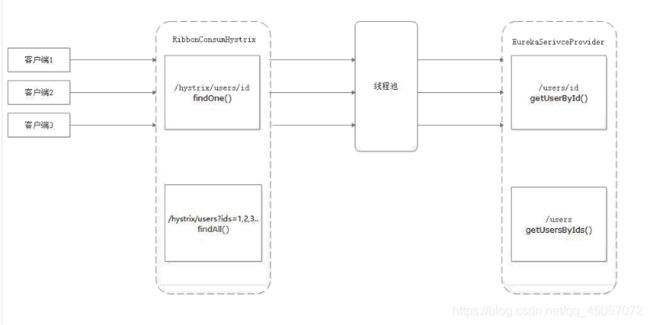
如图,多个客户端发送请求调用(消费者)项目中的findOne方法,这时候在这个项目中的线程池中会发申请与请求数量相同的线程数,对EurekaServiceProvider(服务提供者)的getUserById方法发起调用,每个线程都要调用一次,在高并发的场景下,这样势必会对服务提供者项目产生巨大的压力。
请求合并就是将单个请求合并成一个请求,去调用服务提供者,从而降低服务提供者负载的,一种应对高并发的解决办法
二、请求合并的原理
NetFlix在Hystrix为我们提供了应对高并发的解决方案----请求合并,如下图

通过请求合并器设置延迟时间,将时间内的,多个请求单个的对象的方法中的参数(id)取出来,拼成符合服务提供者的多个对象返回接口(getUsersByIds方法)的参数,指定调用这个接口(getUsersByIds方法),返回的对象List再通过一个方法(mapResponseToRequests方法),按照请求的次序将结果对象对应的装到Request对应的Response中返回结果。
三、请求合并适用的场景
在服务提供者提供了返回单个对象和多个对象的查询接口,并且单个对象的查询并发数很高,服务提供者负载较高的时候,我们就可以使用请求合并来降低服务提供者的负载
四、请求合并带来的问题
问题:即然请求合并这么好,我们是否就可以将所有返回单个结果的方法都用上请求合并呢?答案自然是否定的!
原因:
-
我们为这个请求人为的设置了延迟时间,这样在并发不高的接口上使用请求缓存,会降低响应速度
-
实现请求合并比较复杂
路由网关(zuul)
为什么需要服务网关

在分布式系统系统中,有商品、订单、用户、广告、支付等等一大批的服务,前端怎么调用呢?和每个服务一个个打交道?这显然是不可能的,这就需要有一个角色充当所有请求的入口,这个角色就是服务网关(API gateway)
客户端直接与微服务通讯的问题
-
客户端会多次请求不同的微服务,增加了客户端的复杂性。
-
存在跨域请求,在一定场景下处理相对复杂。
-
认证复杂,每个服务都需要独立认证。
-
难以重构,随着项目的迭代,可能需要重新划分微服务。例如,可能将多个服务合并成一个或者将一个服务拆分成多个。如果客户端直接与微服务通讯,那么重构将会很难实施。
网关的优点
-
易于监控。可在微服务网关收集监控数据并将其推送到外部系统进行分析。
-
易于认证。可在微服务网关上进行认证。然后再将请求转发到后端的微服务,而无须在每个微服务中进行认证。
-
减少了客户端与各个微服务之间的交互次数。
为了解决上面这些问题,我们需要将权限控制这样的东西从我们的服务单元中抽离出去,而最适合这些逻辑的地方就是处于对外访问最前端的地方,我们需要一个更强大一些的均衡负载器,它就是本文将来介绍的:服务网关
什么是网关?
服务网关是微服务架构中一个不可或缺的部分。通过服务网关统一向外系统提供REST API的过程中,除了具备服务路由、均衡负载功能之外,它还具备了权限控制等功能。Spring Cloud Netflix 中的 Zuul 就担任了这样的一个角色,为微服务架构提供了前门保护的作用,同时将权限控制这些较重的非业务逻辑内容迁移到服务路由层面,使得服务集群主体能够具备更高的可复用性和可测试性。
使用zuul
新建eureka-zuul的module的工程
在pom.xml中导入相应的依赖
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-serverartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-zuulartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
<exclusions>
<exclusion>
<groupId>org.junit.vintagegroupId>
<artifactId>junit-vintage-engineartifactId>
exclusion>
exclusions>
dependency>
dependencies>
在application.yml中配置相应的配置文件
spring:
application:
name: eureka-zuul
server:
port: 8081
eureka:
client:
service-url:
defaultZone: http://localhost:8088/eureka
zuul:
routes:
api-order:
path: /api-order/**
serviceId: eureka-order
api-good:
path: /api-good/**
serviceId: eureka-good
启动类中配置
@SpringBootApplication
/*开启Eureka的客户端功能*/
@EnableEurekaClient
/*开启zuul的代理功能*/
@EnableZuulProxy
public class EurekaZuulApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaZuulApplication.class, args);
}
}
测试路由访问:
http://localhost:8081/eureka-good/getGoodNum
http://localhost:8081/api-order/getOrderNum
配置统一前缀访问
spring:
application:
name: eureka-zuul
server:
port: 8081
eureka:
client:
service-url:
defaultZone: http://localhost:8088/eureka
zuul:
routes:
api-order:
path: /api-order/**
serviceId: eureka-order
api-good:
path: /api-good/**
serviceId: eureka-good
prefix: /ddm
ignored-services: "*"
忽略服务名serviceId访问
spring:
application:
name: eureka-zuul
server:
port: 8081
eureka:
client:
service-url:
defaultZone: http://localhost:8088/eureka
zuul:
routes:
api-order:
path: /api-order/**
serviceId: eureka-order
api-good:
path: /api-good/**
serviceId: eureka-good
prefix: /ddm
ignored-services: "*"
配url绑定映射
spring:
application:
name: eureka-zuul
server:
port: 8081
eureka:
client:
service-url:
defaultZone: http://localhost:8088/eureka
zuul:
routes:
ddm:
url: https://www.jd.com
path: /ddm/**
api-order:
path: /api-order/**
serviceId: eureka-order
api-good:
path: /api-good/**
serviceId: eureka-good
#prefix: /ddm
#ignored-services: "*"
配置URL映射负载
spring:
application:
name: eureka-zuul
server:
port: 8081
eureka:
client:
service-url:
defaultZone: http://localhost:8088/eureka
zuul:
routes:
ddm:
#url: https://www.jd.com
serviceId: eureka-order
path: /ddm/**
api-order:
path: /api-order/**
serviceId: eureka-order
api-good:
path: /api-good/**
serviceId: eureka-good
#prefix: /ddm
#ignored-services: "*"
eureka-order:
ribbon:
listOfServers: https://www.jd.com/,https://www.taobao.com/
ribbon:
eureka:
enabled: false
zuul过滤器
Zuul本身是一系列过滤器的集成,那么他当然也就提供了自定义过滤器的功能,zuul提供了四种过滤器:前置过滤器,路由过滤器,错误过滤器,简单过滤器,实现起来也十分简单,只需要编写一个类去实现zuul提供的接口。
使用zuul过滤器
@Component
public class MyZuulFilter extends ZuulFilter {
private Logger log= LoggerFactory.getLogger(MyZuulFilter.class);
/**
*类型包含 pre post route error
*pre 代表在路由代理之前执行
*route 代表代理的时候执行
*error 代表出现错的时候执行
*post 代表在route 或者是 error 执行完成后执行
*/
@Override
public String filterType() {
return FilterConstants.PRE_TYPE;
}
@Override
public int filterOrder() {
//优先级,数字越大,优先级越低
return 0;
}
@Override
public boolean shouldFilter() {
//是否执行该过滤器,true代表需要过滤
return true;
}
@Override
public Object run() throws ZuulException {
RequestContext ctx = RequestContext.getCurrentContext();
HttpServletRequest request = ctx.getRequest();
log.info(String.format("%s >>> %s", request.getMethod(), request.getRequestURL().toString()));
Object accessToken = request.getParameter("token");
if(accessToken == null) {
log.warn("token is empty");
ctx.setSendZuulResponse(false);
ctx.setResponseStatusCode(401);
try {
ctx.getResponse().getWriter().write("token is empty");
}catch (Exception e){
e.printStackTrace();
}
return null;
}
log.info("ok");
return null;
}
}
分布式配置中心
为什么需要分布式配置中心?
在分布式系统中,由于服务数量巨多,为了方便服务配置文件统一管理,所以需要分布式配置中心组件。在Spring Cloud中,有分布式配置中心组件spring cloud config ,它支持配置服务放在配置服务的内存中(即本地),也支持放在远程Git仓库中。在spring cloud config 组件中,分两个角色,一是config server,二是config client。

没有使用统一配置中心时,所存在的问题
-
配置文件分散在各个项目里,不方便维护
-
配置内容安全与权限,实际开发中,开发人员是不知道线上环境的配置的
-
更新配置后,项目需要重启
有哪些开源配置中心
- spring-cloud/spring-cloud-config
https://github.com/spring-cloud/spring-cloud-config
spring出品,可以和spring cloud无缝配合 - 淘宝 diamond
https://github.com/takeseem/diamond
已经不维护 - disconf
https://github.com/knightliao/disconf
java开发,蚂蚁金服技术专家发起,业界使用广泛 - ctrip apollo(重量级的框架)
https://github.com/ctripcorp/apollo/
Apollo(阿波罗)是携程框架部门研发的开源配置管理中心,具备规范的权限、流程治理等特性。
可用性与易用性
| 功能点 | 优先级 | spring-cloud-config | ctrip apollo | disconf | 备注 |
|---|---|---|---|---|---|
| 静态配置管理 | 高 | 基于file | 支持 | 支持 | |
| 动态配置管理 | 高 | 支持 | 支持 | 支持 | |
| 统一管理 | 高 | 无,需要github | 支持 | 支持 | |
| 多环境 | 中 | 无,需要github | 支持 | 支持 | |
| 本地配置缓存 | 高 | 无 | 支持 | 支持 | |
| 配置锁 | 中 | 支持 | 不支持 | 不支持 | 不允许动态及远程更新 |
| 配置校验 | 中 | 无 | 无 | 无 | 如:ip地址校验,配置 |
| 配置生效时间 | 重启生效,或手动refresh生效 | 实时 | 实时 | 需要结合热加载管理, springcloudconfig需要 git webhook+rabbitmq 实时生效 | |
| 配置更新推送 | 高 | 需要手工触发 | 支持 | 支持 | |
| 配置定时拉取 | 高 | 无 | 支持 | 配置更新目前依赖事件驱动, client重启或者server端推送操作 | |
| 用户权限管理 | 中 | 无,需要github | 支持 | 支持 | 现阶段可以人工处理 |
| 授权、审核、审计 | 中 | 无,需要github | 支持 | 无 | 现阶段可以人工处理 |
| 配置版本管理 | 高 | Git做版本管理 | 界面上直接提供发布历史和回滚按钮 | 操作记录有落数据库,但无查询接口 | |
| 配置合规检测 | 高 | 不支持 | 支持(但还需完善) | ||
| 实例配置监控 | 高 | 需要结合springadmin | 支持 | 支持,可以查看每个配置在哪些机器上加载 | |
| 灰度发布 | 中 | 不支持 | 支持 | 不支持部分更新 | 现阶段可以人工处理 |
| 告警通知 | 中 | 不支持 | 支持,邮件方式告警 | 支持,邮件方式告警 | |
| 依赖关系 | 高 | 不支持 | 不支持 | 不支持 | 配置与系统版本的依赖系统运行时的依赖关系 |
技术路线兼容性
引入配置中心,需要考虑和现有项目的兼容性,以及是否引入额外的第三方组件。我们的java项目以SpringBoot为主,需要重点关注springboot支持性。
| 功能点 | 优先级 | spring-cloud-config | ctrip apollo | disconf | 备注 |
|---|---|---|---|---|---|
| SpringBoot支持 | 高 | 原生支持 | 支持 | 与spring boot无相关 | |
| SpringCloud支持 | 高 | 原生支持 | 支持 | 与spring cloud无相关 | |
| 客户端支持 | 低 | Java | Java、.Net | java | |
| 业务系统侵入性 | 高 | 侵入性弱 | 侵入性弱 | 侵入性弱,支持注解及xml方式 | |
| 依赖组件 | 高 | Eureka | Eureka | zookeeper |
可用性与易用性
引入配置中心后,所有的应用都需要依赖配置中心,因此可用性需要重点关注,另外管理的易用性也需要关注。
| 功能点 | 优先级 | spring-cloud-config | ctrip apollo | disconf | 备注 |
|---|---|---|---|---|---|
| 单点故障(SPOF) | 高 | 支持HA部署 | 支持HA部署 | 支持HA部署,高可用由zookeeper保证 | |
| 多数据中心部署 | 高 | 支持 | 支持 | 支持 | |
| 配置获取性能 | 高 | unkown | unkown(官方说比spring快) | ||
| 配置界面 | 中 | 无,需要通过git操作 | 统一界面(ng编写) | 统一界面 |
最佳选择
综上,ctrip applo是较好的选择方案,最终选择applo。
- 支持不同环境(开发、测试、生产)、不同集群
- 完善的管理系统,权限管理、发布审核、操作审计
- SpringBoot集成友好 ,较小的迁移成本
- 配置修改实时生效(热发布)
- 版本发布管理
快速入门springcloud-config
config-server配置
-
创建config-server
-
pom.xml中添加
<dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-config-serverartifactId> dependency> -
启动类中添加
@SpringBootApplication @EnableConfigServer public class ConfigServerApplication { public static void main(String[] args) { SpringApplication.run(ConfigServerApplication.class, args); } } -
创建gitee的仓库(记得添加readme.md文件)
-
application.yml中添加
spring: application: name: config-server cloud: config: server: git: ### git仓库得路径 uri: https://gitee.com/AngeGit/springcloud.git ### 仓库中所有得文件都是可以访问的 search-paths: /** ### 配置用户名和密码 username: password: ### 指定分支的类型 label: master server: port: 8091 -
创建测试的配置文件,配置规则如下
Config支持我们使用的请求的参数规则为: { 应用名 } / { 环境名 } [ / { 分支名 } ] { 应用名 } - { 环境名 }.yml { 应用名 } - { 环境名 }.properties { 分支名 } / { 应用名 } - { 环境名 }.yml { 分支名 } / { 应用名 } - { 环境名 }.properties 开发环境主要是四种: 开发环境-dev 生产环境-pro 测试环境-test 灰度环境-pre -
将配置文件上传到git中
访问测试地址: http://localhost:8091/order-dev.yml
config-client配置流程
-
修改对应服务的pom.xml
<dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-configartifactId> dependency> -
修改对应application.yml文件为bootstrap.yml文件(面试高频题)
bootstrap.yml(bootstrap.properties)用来程序引导时执行,应用于更加早期配置信息读取,如可以使用来配置application.yml中使用到参数等 application.yml(application.properties) 应用程序特有配置信息,可以用来配置后续各个模块中需使用的公共参数等。 bootstrap.yml 先于 application.yml 加载spring: cloud: config: label: master profile: dev uri: http://localhost:8091 application: name: order
Config+Bus实现动态刷新
Config服务端的配置
Config-server的pom.xml依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-config-serverartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-bus-amqpartifactId>
dependency>
ConfigServerApplication.java启动类
@SpringBootApplication
@EnableConfigServer
@EnableEurekaClient
public class ConfigServerApplication {
public static void main(String[] args) {
SpringApplication.run(ConfigServerApplication.class, args);
}
}
application.yml
spring:
application:
name: config-server
cloud:
config:
server:
git:
### git仓库得路径
uri: https://gitee.com/AngeGit/springcloudvip.git
### 仓库中所有得文件都是可以访问的
search-paths: /**
### 配置用户名和密码
username:
password:
skip-ssl-validation: true
### 指定分支的类型
label: master
rabbitmq:
host: 192.168.126.133
port: 5672
username: guest
password: guest
server:
port: 8084
eureka:
client:
service-url:
defaultZone: http://localhost:8080/eureka
management:
endpoints:
web:
exposure:
include: '*'
Config客户端配置
pom.xml中的配置
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-configartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-actuatorartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-bus-amqpartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
dependency>
客户端启动类
@SpringBootApplication
@EnableEurekaClient
public class EurekaGradeApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaGradeApplication.class, args);
}
}
application.yml
spring:
cloud:
config:
label: master
profile: dev
uri: http://localhost:8084
application:
name: grade
git中yml的配置文件
### 注册到eureka的服务名称
spring:
application:
name: eureka-grade
rabbitmq:
host: 192.168.126.133
port: 5672
username: guest
password: guest
server:
port: 8081
eureka:
client:
service-url:
defaultZone: http://localhost:8080/eureka
fetch-registry: true
register-with-eureka: true
需要刷新的文件加上@RefreshScope注解
@RestController
@RefreshScope
public class GradeController {
/*Value可以获取yml中或者properties中的内容*/
@Value("${server.port}")
private String port;
@RequestMapping("/getPort")
public String getPort(){
return port;
}
/*通过rest风格进行控制器的调用*/
@RequestMapping("/getGradeName/{id}")
public String getGradeNameById(@PathVariable("id") Integer id){
return id==1?"S1"+port:id==2?"S2"+port:"Y2"+port;
}
}
重启服务器和客户端
修改git中的内容
使用post请求发送: http://localhost:8084/actuator/bus-refresh
artifactId>spring-boot-starter-actuator
org.springframework.cloud
spring-cloud-starter-bus-amqp
org.springframework.boot
spring-boot-starter-web
org.springframework.cloud
spring-cloud-starter-netflix-eureka-client
客户端启动类
```java
@SpringBootApplication
@EnableEurekaClient
public class EurekaGradeApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaGradeApplication.class, args);
}
}
application.yml
spring:
cloud:
config:
label: master
profile: dev
uri: http://localhost:8084
application:
name: grade
git中yml的配置文件
### 注册到eureka的服务名称
spring:
application:
name: eureka-grade
rabbitmq:
host: 192.168.126.133
port: 5672
username: guest
password: guest
server:
port: 8081
eureka:
client:
service-url:
defaultZone: http://localhost:8080/eureka
fetch-registry: true
register-with-eureka: true
需要刷新的文件加上@RefreshScope注解
@RestController
@RefreshScope
public class GradeController {
/*Value可以获取yml中或者properties中的内容*/
@Value("${server.port}")
private String port;
@RequestMapping("/getPort")
public String getPort(){
return port;
}
/*通过rest风格进行控制器的调用*/
@RequestMapping("/getGradeName/{id}")
public String getGradeNameById(@PathVariable("id") Integer id){
return id==1?"S1"+port:id==2?"S2"+port:"Y2"+port;
}
}
重启服务器和客户端
修改git中的内容
使用post请求发送: http://localhost:8084/actuator/bus-refresh
验证是否成功