基于DB-GPT与Google Bard构建知识库问答系统
背景

在人类发展历史上,有两样东西是持续伴随整个人类发展的, 1. 知识 2. 工具。大模型出现之后,尤其是ChatGPT发布之后,因其具备的推理、逻辑能力,尤其是说不明,道不清的涌现能力,把AI的能力推向了一个新的层次。不仅仅引爆了整个科技圈,也随着媒体铺天盖地的宣传与渲染,被越来越多的用户所了解。 随着围绕大模型的产品与应用的不断推出,非常多用户感受到了AI的魅力。在自然语言领域,各种知识库、写作、文档工具正在改变大家的学习知识、文档检索与撰写的方式。 在多模态领域,Midjourney,stable diffustion的表现也非常火热,很多图形、设计类的工作也在发生者巨大的改变。
更令人惊喜的是最近秒鸭相机的出圈,让围绕大模型的应用与落地充满了期待。 一个崭新的时代,正在加速拉开帷幕,为我们贡献精彩绝伦的表演。 处在时代中的我们,是多么的幸运,尤其是处在这个时代的开发者们,我们正在见证也在深度参与一个伟大的时代,也亲眼目睹它的到来。
AIGC的大航海时代已经开启,热血的开发者们,想要大模型带来的财宝吗? 想要的话就去追逐吧,所有的财宝已经被放在大模型里面了,去解开它的秘密吧。扬起你的帆船,带上你的伙伴,去找吧~
One piece, we are coming~

扯远了,我们言归正传 ,在本文中,我们主要介绍DB-GPT的一些能力以及简要的使用手册,同时如何基于DB-GPT与Google Bard在本地跑一个知识库问答系统。
功能概览
目前DB-GPT已经发布了多种关键的特性:
- SQL 语言能力, SQL生成、诊断
- 私域问答与数据处理
- 知识库管理(目前支持 txt, pdf, md, html, doc, ppt, and url)
- 数据库知识问答
- 数据处理
- 数据库对话
- Chat2Dashboard
- 插件模型
- 支持自定义插件执行任务,原生支持Auto-GPT插件。如:
- SQL自动执行,获取查询结果
- 自动爬取学习知识
- 知识库统一向量存储/索引
- 非结构化数据支持包括PDF、MarkDown、CSV、Word、Txt、PPT、WebURL等等
- 多模型支持, 支持多种大语言模型, 当前已支持如下模型:
- Vicuna(7b,13b)
- ChatGLM-6b(int4,int8)
- guanaco(7b,13b,33b)
- Gorilla(7b,13b)
- llama-2(7b,13b,70b)
- baichuan(7b,13b)
开源地址: https://github.com/eosphoros-ai
原生对话
原生对话是指大模型提供的原生能力,通过DB-GPT提供的统一对话界面可以实现与大模型的流式对话体验,感受大模型的能力。原生对话无需选择任何场景,直接在下方的输入框当中进行提问,即可感受原生对话的能力。 通过DB-GPT提供的统一ChatUI,可以丝滑体验大模型的能力。
知识库(Chat Knowledge)
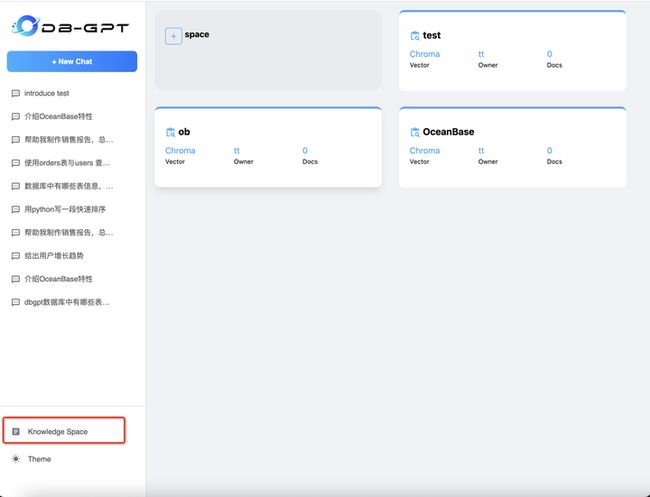
DB-GPT中知识库,是指基于私域文档、数据进行问答与数据处理的能力,目前已支持 txt、pdf、markdown、html、doc、ppt、csv多种文档类型。 同时在知识库管理上,DB-GPT提供了知识空间(Knowledge Space)。 在使用时首先通过知识空间,将文档、数据上传到知识空间做向量化。
然后通过DB-GPT提供的知识库对话的能力,进行知识库对话。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
在进行具体的知识库对话时,进入到对话场景之后,需要选择对应的知识库空间。选中知识库空间之后,即可根据具体的知识库进行对话。
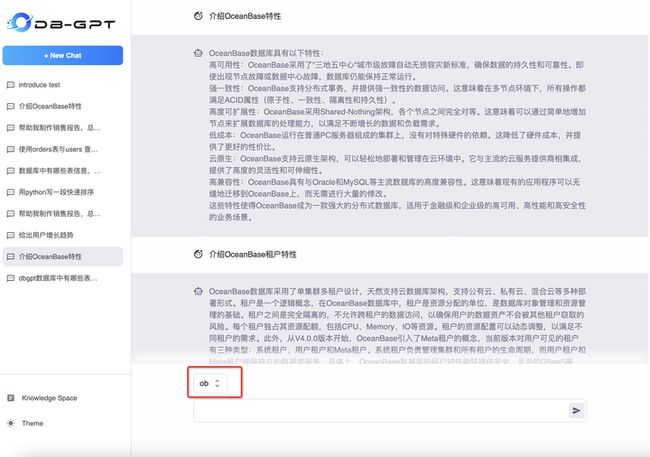
数据库对话(ChatDB)
数据库对话是指根据数据库当中的元数据信息,例如表信息、索引信息、列信息等进行对话的能力。在实际使用过程中,可以基于这些元数据信息进行对话,可以生产可执行SQL、对指定SQL进行诊断、给出优化建议,SQL改写等。
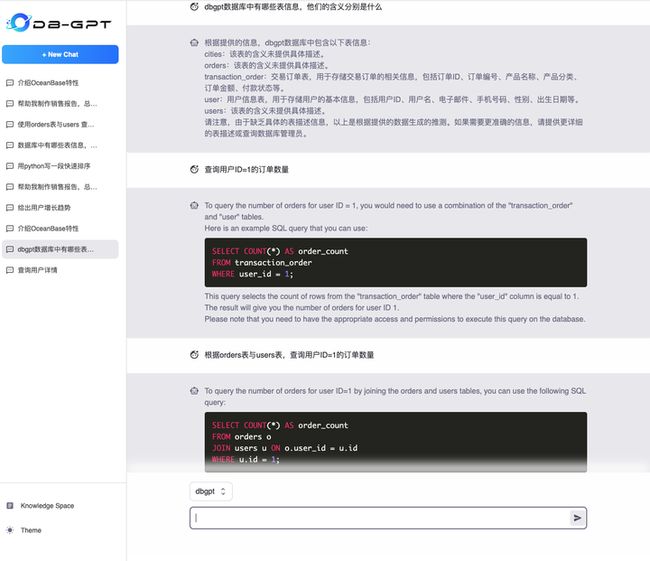
如果需要切换数据库,在左下角进行切换即可。 基于数据库对话的能力,可以极大提高DBA、研发的提效。
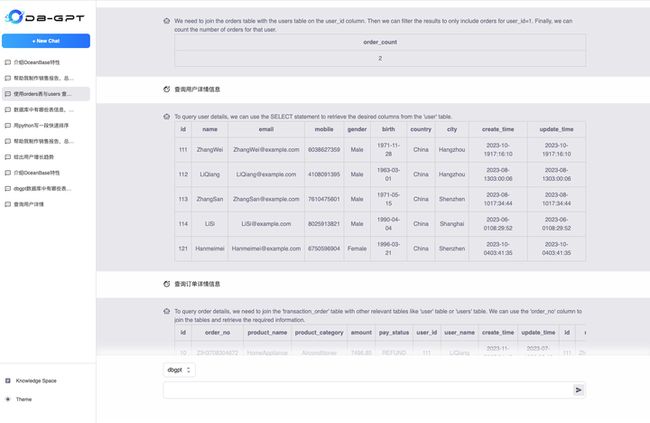
数据对话(ChatData)
ChatData提供的数据对话的能力,是对ChatDB的能力做进一步自动化,即通过插件能力自动执行结果。 通过ChatData的能力,我们可以更好的实现与数据库的交互,提升日常使用数据库时的效率,降低数据库使用门槛。
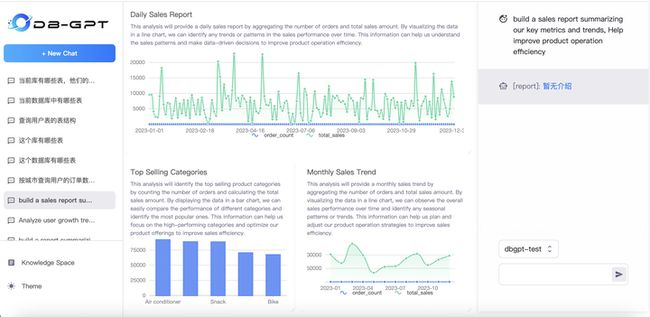
数据分析(ChatDashboard)
ChatDashboard的能力也就是数据分析能力。我们可以通过自然语言交互的方式,实现报表制作,报表分析等能力。当前ChatDashboard的能力受限与模型能力,在开源模型上的表现还非常差,需要切换到ChatGPT、Bard等代理模型才会有较好的表现效果。
插件(Plugin)
插件能力目前已支持Auto-GPT插件模型,但考虑到开源模型在插件能力上较差的表现,相关能力暂未开放。
知识库能力介绍
当前能力
前面已经简单介绍了知识库相关能力的演示。 接下来我们详细介绍一下知识库能力,并在没有GPU的情况下,如何基于Google Bard 来构建自己的本地的知识库系统?
在DB-GPT项目中已经提供了AutoDL的镜像,如果想本地化部署开源大模型的同学,可以按照镜像在对应的平台上完成部署。 AutoDL镜像教程, 在DB-GPT中,关于知识库提供了完整的管理能力,包括:
- 知识空间管理、文档上传、删除
- 多文档类型支持,包括PDF、MarkDown、CSV、Word、Txt、PPT、WebURL等
- 知识向量操作与任务管理
- 文档Embedding以及Chunk详情查看
知识库架构
在DB-GPT当中,对于知识库相关的能力,我们是通过ICL的方式进行设计与开发,为了能够让知识库的能力更强大,同时充分具备可拓展的能力,我们在DB-GPT当中设计了一套Embedding的引擎。 如同所示,各类知识经过DB-GPT-Embedding Engine之后,通过Embedding Engine提供的Loader-> Reader-> Process -> Embedding 整个数据管道的能力,可以轻松的实现各类数据的Embedding, 同时整个引擎也提供了可拓展的能力,可以按需进行自定义与拓展。
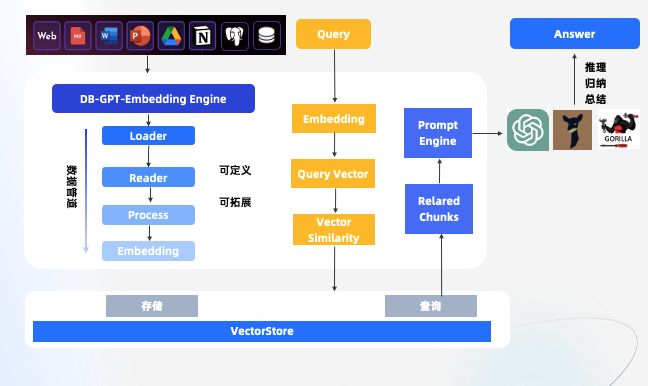
关于ICL,下面也有一张更详细的介绍图,大家可以据此来理解整个ICL的过程。这种模式在知识问答里面属于端对端模式,对传统的两阶段方法知识问答做了升级。传统的两阶段方法主要分为召回阶段和阅读理解阶段。召回阶段中,使用传统的TF-IDF的方式返回评分最高的Top-K个文章片段。阅读理解阶段中,采用神经网络模型RNN将问题转化为序列标注问题,即对于给定文档中出现的每个词,判断是否出现在答案中。
大模型时代外挂本地知识库模式下在召回阶段用向量检索方式代替传统的TF-IDF的方式进行召回,用向量去召回是指将所有知识问答通过Embedding映射到一个固定维度的向量空间。当用户进行提问时,可以将这个问题通过相同的Embedding模型映射到同样维度的向量空间。在相同维度的向量空间中找到与问题语义相似的Top-K文档进行召回作为答案的候选项。在阅读理解阶段,通过大语言模型对收集到的问题+外挂知识统一吐给模型让其进行理解并返回最终的答案。

围绕着上面的外挂本地知识库方法论,DB-GPT在知识库也构建了知识库使用的api,使用文档。
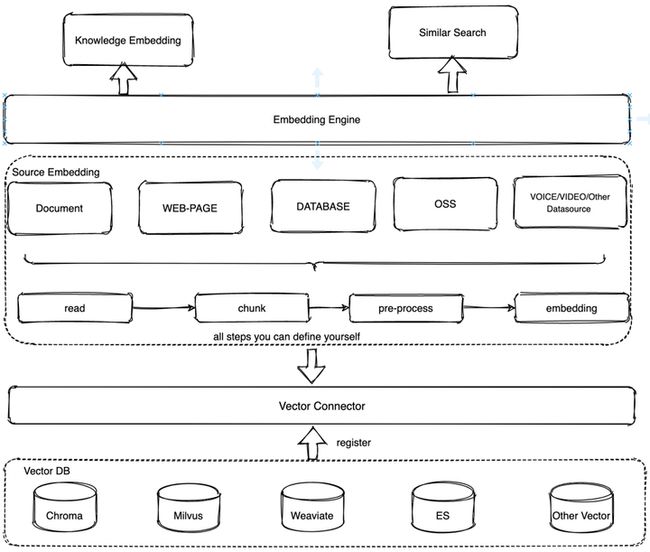
如图所示, 整个知识库的架构主要分为3层:
embedding engine层
知识embedding客户端,包括如何将文档知识knowledge_embedding方法导入向量数据库以及通过similar_search方法根据用户提问向量检索出相似度高的知识片段。
document_path = "your_path/test.md"
embedding_engine = EmbeddingEngine(
knowledge_source=document_path,
knowledge_type=KnowledgeType.DOCUMENT.value,
model_name=embedding_model,
vector_store_config=vector_store_config)
embedding_engine.knowledge_embedding()
knowledge source层
提供根据不同知识类型进行读取->切片->数据处理->转向量的pipeline, 每一步可以按照默认的实现方式,也可以可自定义的进行个性化处理。 此层具备一定的拓展性,能够不断地扩展知识类型,包括但不限于文档、视频、音频、数据库、数仓、对象存储等等。扩展方法都是通过继承SourceEmbedding然后按需实现
read()->data_process()->index_to_store() 整个PipeLine
- read():知识的加载解析,这里可以使用langchain的各种Loader,也可以自定义Loader进行实现。
- data_proccess():数据预处理,可以按照自定义逻辑进行数据处理。
- index_to_store():存入向量数据库,通过vector_store_config配置向量数据库连接参数
class SourceEmbedding(ABC):
"""base class for read data source embedding pipeline.
include data read, data process, data split, data to vector, data index vector store
Implementations should implement the method
"""
def __init__(
self,
file_path,
vector_store_config: {},
source_reader: Optional = None,
text_splitter: Optional[TextSplitter] = None,
embedding_args: Optional[Dict] = None,
):
"""Initialize with Loader url, model_name, vector_store_config"""
self.file_path = file_path
self.vector_store_config = vector_store_config
self.source_reader = source_reader or None
self.text_splitter = text_splitter or None
self.embedding_args = embedding_args
self.embeddings = vector_store_config["embeddings"]
@abstractmethod
@register
def read(self) -> List[ABC]:
"""read datasource into document objects."""
@register
def data_process(self, text):
"""pre process data."""
@register
def text_splitter(self, text_splitter: TextSplitter):
"""add text split chunk"""
pass
@register
def text_to_vector(self, docs):
"""transform vector"""
pass
@register
def index_to_store(self, docs):
"""index to vector store"""
self.vector_client = VectorStoreConnector(
self.vector_store_config["vector_store_type"], self.vector_store_config
)
return self.vector_client.load_document(docs)
vector connector层
主要提供知识向量和向量数据库交互的能力,每一种具体的向量数据库注册到vector connector,让用户并不感知具体向量数据库的实现底层细节。同样地vector connector底层目前也只实现了Chroma, Milvus, Weaviate向量数据库,更多的向量数据库也可以通过横向扩展注册到vector connector中。
- load_document():加载文档导入到向量数据库
- similar_search():文档相似性搜索
- vector_name_exists:判断向量数据库名是否已存在
class VectorStoreConnector:
"""VectorStoreConnector, can connect different vector db provided load document api_v1 and similar search api_v1.
1.load_document:knowledge document source into vector store.(Chroma, Milvus, Weaviate)
2.similar_search: similarity search from vector_store
how to use reference:https://db-gpt.readthedocs.io/en/latest/modules/vector.html
how to integrate:https://db-gpt.readthedocs.io/en/latest/modules/vector/milvus/milvus.html
"""
def __init__(self, vector_store_type, ctx: {}) -> None:
"""initialize vector store connector."""
self.ctx = ctx
self.connector_class = connector[vector_store_type]
self.client = self.connector_class(ctx)
def load_document(self, docs):
"""load document in vector database."""
return self.client.load_document(docs)
def similar_search(self, docs, topk):
"""similar search in vector database."""
return self.client.similar_search(docs, topk)
def vector_name_exists(self):
"""is vector store name exist."""
return self.client.vector_name_exists()
本地实践
本文中,为了让开发者可以在本地丝滑的构建知识库的能力,我们提供了基于Bard-Proxy的构建方案。接下来,我们来详细看看如何通过Bard-Proxy与DB-GPT快速搭建超赞的本地的知识库系统。
Bard Proxy部署
在开始部署Bard Proxy之前,我们简单讲一下为什么要用Bard,Google Bard最近支持了中文,同时Google Bard不像ChatGPT需要注册才能使用,Google Bard通过VPN代理即可直接使用, 在使用过程中也不需要付费,没有严格的使用次数上限。因此在本地使用中,Google Bard是一个不错的选择。
Bard-Proxy部署非常简单,唯一需要关注的点是,需要找一台可以访问Google的外网服务器,在腾讯云或者阿里云购买一台国外的服务器,然后部署Bard-Proxy即可完成代理部署。 Bard-Proxy的源码地址: https://github.com/eosphoros-ai/Bard-Proxy
1. 下载源码
git clone https://github.com/eosphoros-ai/Bard-Proxy.git
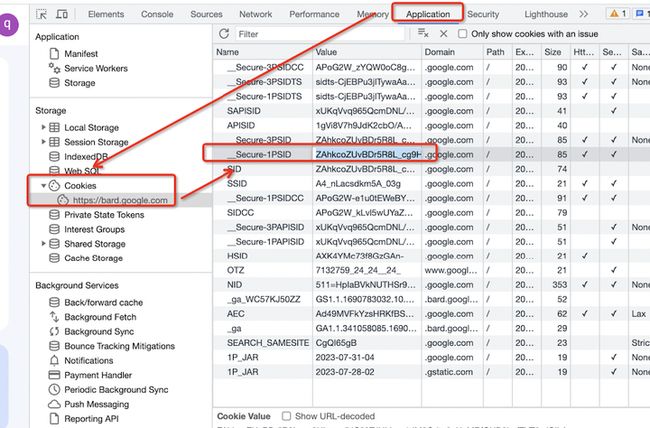
2. 登陆代理,查看自己的Bard Key,打开浏览器开发者模式(F12),在Application -> Cookies 下面找到对应的Key
打开https://bard.google.com/ 网站,或者对应的Cookie信息。
3. 通过Docker在阿里云或者腾讯云的外网服务器上部署Bard-Proxy
docker run -d --name bard_proxy -p 8671:8671 -e BARD_PROXY_API_KEY=YOUR-BARD-KEY shinexy/bard_proxy
通过上述步骤,我们即完成整个Bard-Proxy的部署,接下来,我们看看如何在DB-GPT中部署使用。
DB-GPT + Bard + 本地知识库
1. DB-GPT 代理模式部署
在开始之前,首先我们安装一下DB-GPT依赖的MySQL,同样是通过Docker进行安装。
1.1. 安装MySQL
$ docker run --name=mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=aa12345678 -dit mysql
# 初始化数据库信息
$ mysql -h127.0.0.1 -uroot -paa12345678 < ./assets/schema/knowledge_management.sql
1.2. 安装Python依赖
python>=3.10
conda create -n dbgpt_env python=3.10
conda activate dbgpt_env
pip install -r requirements.txt
1.3. 知识库前置依赖安装
python -m spacy download zh_core_web_sm
1.4. 下载Embedding向量模型
git clone https://huggingface.co/GanymedeNil/text2vec-base-chinese
在代理模式下,Embedding过程,即知识向量化的过程还是本地进行的,所以需要一个embedding模型,text2vec-base-chinese 模型是中文场景下表现较好的模型。如果本地电脑配置较高,可以使用text2vec-large-chinese模型。
1.5. 环境变量配置
cp .env.template .env
# 修改变量值
LLM_MODEL=bard_proxyllm
EMBEDDING_MODEL=text2vec-base
PROXY_SERVER_URL=http://{bard_proxy服务器公网ip}:8671/api/bard/v1/chat/completions
1.6. 启动dbgpt-server
python pilot/server/dbgpt_server.py
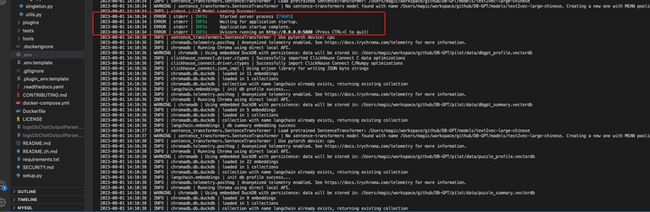
如图所示,5000端口启动成功之后,即可访问DB-GPT了, http://127.0.0.1:5000

以上即基于Bard-Proxy部署DB-GPT的教程。 接下来,我们简单介绍一下具体的使用。
使用指南
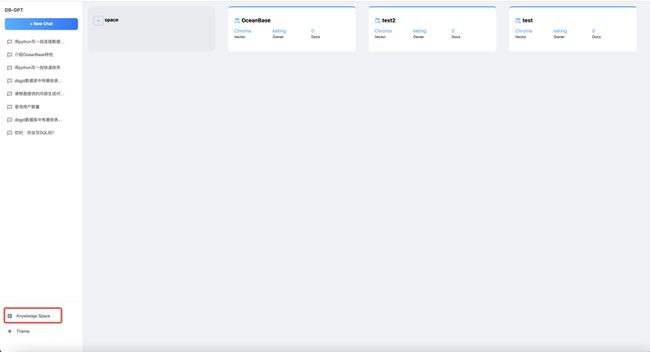
创建知识库
通过Knowledge Space,可以创建知识库。
导入知识文档
这里知识文档目前分为3类,Text纯文本,WebUrl链接和文档类型,文档类型包括PDF, Markdown, Word, PPT, HTML和CSV,上传文档成功后后台会自动将文档内容进行读取,切片,然后导入到向量数据库中。


导入知识成功后,返回首页选择Chat Knowledge,然后与知识库进行对话问答。

不足与改进
当前DB-GPT在知识问答效果上具备了知识库问答的能力,并提供了通用的底层模块,对于相对简单的问答场景,有较好的表现。但是在稍微复杂的问答场景上面,效果还比较差,主要体现在:
- 直接将问题 + 相似性搜索出文档当作上下文,常常由于提出问题的模糊性搜索出匹配不相关的文档。这些不相关的文档会让模型推理出的答案有误。比如
Q:问题MySQL支持哪些时间函数? A: 除了时间函数还有其他函数。
这里有个思路就是准备一个问题集与答案集,将问题集向量化到向量数据库,根据用户提供的问题从问题集检索到最贴近的几个问题,然后获取每个问题集对应的答案,再将问题和答案交给大模型进行推理总结,这种方案的优点:能够一定程度提高模型答案的准确性,能够解决问题模糊性带来不相干文档的干扰。缺点:需要预先准备大量的问题集和答案集。
- 对于一些复杂问题比如多知识点的比较问答,比如:
Q: 对比MySQL、OceanBase分别在部署架构、事务以及高可用上面的优缺点?
如果直接根据初始问题进行Embedding然后进行向量检索出知识片段然后再丢给模型推理,效果非常不理想,尤其是在开源大模型上的表现。其中一种可选的思路是将问题进行拆解,也可以说关键词提取,通过拆解的关键词分别进行向量检索,比如可以拆解成MySQL部署架构的优缺点,MySQL事务优缺点,MySQL高可用优缺点,OceanBase部署架构的优缺点,OceanBase事务优缺点,OceanBase高可用优缺点。
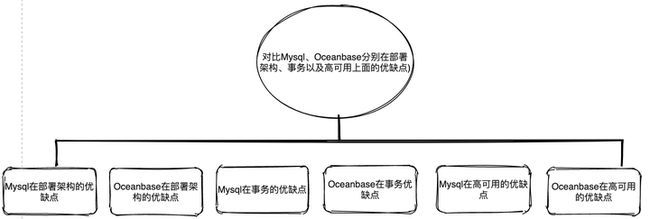
将拆解后的问题进行embedding后通过大模型推理出每个问题的答案,然后再将初始问题和拆解后的问题+答案一起再丢给大模型进行推理出最终答案。这里的涉及到的难点就是问题拆解以及多轮模型对话的交互,围绕以上问题我们也正在基于CoT、ToT这样的技术手段来构建工程化的能力。

- 目前开源模型回答还不够稳定。
这个问题是开源大模型的通病,首先不同的模型对于prompt上下文的敏感程度是不一样的,可能prompt一点点变化都会导致模型回答的效果产生变化。下面是DB-GPT知识库在开源的一些大语言模型下简单的评测(针对部分LLM模型测试结果如下的评测(更多模型在集成中,测试效果很差的模型没有列举出来)
| 模型 | ChatGLM-6B | ChatGLM2-6B | Vicuna-13B | baichuan-7b |
|---|---|---|---|---|
| 占用空间(G) | 24 | 24 | 50 | 27 |
| 支持中文 | 是 | 是 | 是 | 是 |
| 支持上下文token | 2k | 8k | 2k | 4k |
| 推理速度(字符/s) | 31.49 | 44.62 | ||
| 问答效果 | 优点:1.推理速度快2.用户可以在消费级的显卡上进行本地部署缺点:1.会胡说八道2.知识总结啰嗦 | 优点:1.推理速度快2.能接收更大的上下文3.知识总结不啰嗦4.用户可以在消费级的显卡上进行本地部署缺点:复杂问答效果不好 | 优点:1.复杂任务比如text2sql, text2json表现还不错缺点:1、推理速度慢2.总结性回答比较啰嗦3.上下文token支持太小,容易出现乱码 | 优点:1.推理速度比chatglm稍微慢一点2.能接收更大的上下文3.知识总结不啰嗦缺点:1.复杂问答效果不好2.受prompt影响较大 |
小结
本文中主要介绍了,基于DB-GPT跟Google Bard构建本地知识库系统的教程,对于GPU短缺的同学,快速了解并上手大模型的能力。 如果在部署过程中有任何问题,或者有相关方向的讨论,都可以来我们社区参与讨论,社区交流地址:
总的来说在中文知识库问答场景下,ChatGLM2-6B模型在推理速度,推理稳定性,总结文档效果目前是开源模型里面表现较好的,Vicuna-13b虽然逻辑正确性与准确率较高,但推理速度,token长度等都表现较差。 baichuan-13b在中文场景下,也具备一定的优势,但还有待提高, 开源模型目前跟ChatGPT、Google Bard、Claude等对比,差距还很明显。 后面我们也会通过工程 + 算法的能力将复杂场景的知识回答的效果做更多的提升。
参考
- https://zhuanlan.zhihu.com/p/647033456
- https://github.com/eosphoros-ai/Bard-Proxy
- https://github.com/eosphoros-ai/DB-GPT
- https://zhuanlan.zhihu.com/p/628750042
- https://stablediffusionweb.com/
- https://civitai.com/
- https://zhuanlan.zhihu.com/p/628750042
- https://zhuanlan.zhihu.com/p/629998078
- https://zhuanlan.zhihu.com/p/639359512
- https://zhuanlan.zhihu.com/p/642443023
- https://bard.google.com/