《走近大数据之Hive进阶》学习笔记(2)
建议:请先看一下鄙人另一篇学习笔记《走近大数据之Hive入门》,再看这个进阶的效果更好!
http://blog.csdn.net/to_Baidu/article/details/52432217
第一章 课程简介
1-1 课程简介
Hive不支持传统数据库中insert插入操作,可通过load语句和sqoop进行数据的导入。
学习目标:
1. hive的数据导入;
2. hive的数据查询;
3. hive的java客户端和自定义函数。
学习的必备基础:
- hive的体系结构和基本操作
- java编程
- Linux的基本操作
第二章 Hive数据的导入
2-1 使用load语句执行数据的导入
使用load语句
-语法:load data [local] inpath ‘filepath’ [overwrite] into table tablename [partition (partcol1=val1, partcol2=val2,“`)]
例如:
–将student01.txt导入t2:
Load data local inpath ‘/root/data/student01.txt’ into table t2;
上面的这种方式一次只能导入一个文件,下面可实现多文件导入。
例如:
–将/root/data下的所有数据文件导入t3表中,并且覆盖原来的数据:
load data local inpath ‘/root/data/’ overwrite into table t3;
目录只要写到相关目录即可,不必具体指定到某个文件。
–将HDFS中/input/student01.txt导入到t3,此时不需要加local关键字:
load data inpath ‘/input/student01.txt’ overwrite into table t3;
–将data1.txt导入partition_table
load data local inpath ‘/root/data/data1.txt’ into table partition_table partition (gender=’M’);
2-2 使用sqoop进行数据的导入
Sqoop是apache下的一个框架,专门做数据的导入和导出。
Sqoop要先安装:下载,tar包安装,再设置两个环境变量即可。
Linux解压tar包的命令 :tar –zxvf 包名
#export HADOOP_COMMON_HOME-~hadoop的安装目录
#export HADOOP_MAPRED_HOME-~hadoop的安装目录
① 使用sqoop导入oracle数据到HDFS中,sqoop语句中的‘–’表示变量
./sqoop import –connect jdbc:oracle:thin:@192.168.56.101:1521:orcl –username scott –password tiger –table emp –columns ‘empno,ename,job,sal’ -m 1 –target-dir ‘/sqoop/emp’
注释:-m表示mapreduce的进程数,如次数进程数是一个
②使用sqoop导入oracle数据到hive中
./sqoop import –hive-import –connect jdbc:oracle:thin:@192.168.56.101:1521:orcl –username scott –password tiger –table emp –m 1 –columns ‘empno,ename,job,sal’
③使用sqoop导入oracle数据到hive中,并且指定表名
./sqoop import –hive-import –connect jdbc:oracle:thin:@192.168.56.101:1521:o**重点内容**rcl –username scott –password tiger –table emp –m 1 –columns ‘empno,ename,job,sal’ –hive-table emp1
④ 使用sqoop导入oracle数据到hive中,并使用where条件
./sqoop import –hive-import –connect jdbc:oracle:thin:@192.168.56.101:1521:orcl –username scott –password tiger –table emp –m 1 –columns ‘empno,ename,job,sal’ –hive-table emp2 –where ‘DEPTNO=10’
⑤ 使用sqoop导入oracle数据到hive中,并使用查询语句
./sqoop import –hive-import –connect jdbc:oracle:thin:@192.168.56.101:1521:orcl –username scott –password tiger –m 1 –query ‘select * from emp where SAL<2000 AND $CONDITIONS’ –target-dir ‘/sqoop/emp5’ –hive-table emp5
注意:必须有AND $CONDITIONS,固定格式
⑥ 使用sqoop将hive中的数据导出到oracle中。
./sqoop export –connect jdbc:oracle:thin:@192.168.56.101:1521:orcl –username scott –password tiger -m 1 –table myemp –export-dir **
注意:需要oracle数据库中先有myemp这个表,并且格式跟*中的一样。
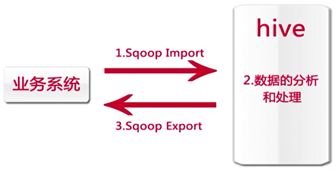
正真的企业级环境数据迁移如下图:
第三章 Hive的数据查询
3-1简单查询和fetch task
Hive中很多查询会转换成mapreduce的作业来执行,但有少量的查询语句不用转换成MapReduce作业。如select * from student。
为什么当在hive中执行比较简单的查询语句时,有时速度比传统的oracle速度还要慢?
因为:1、跟自己机器的配置有关系;2、使用hive要操作数据仓库,当仓库中的数据比较多时,使用hive的速度会比较快。
查询表达式中可以进行一些算术操作,并且可以用hive中的内置函数nvl()将值为null的字段转换成0。
例如:
-查询员工信息:员工号,姓名,月薪,年薪。奖金,年收入
select empno,ename,sal,sal*12,comm,sal*12+nvl(comm,0) from emp;
-查询奖金为null的员工:
select * from emp where comm=null ×错误 应该是:select * from emp where comm is null
distinct:去重,并且作用后面的所有列(组合起来的重复)
简单查询的fetch task功能
- 从hive0.10.0版本开始支持
- 配置方式(3种方式):
1、set hive.fetch.task.conversion=more; (只在当前会话中有效)
2、hive –hiveconf hive.fetch.task.conversion=more; (只在当前会话中有效)
3、修改hive-site.xml文件 (永久有效)
作用:开启该功能可在查询时不生成MapReduce的作业,提高查询效率。
注意:官网上说Hive 0.10.0到0.13.1版本默认为minimal, 而Hive 0.14.0之后的版本已经中默认为more了,不需要修改fetch.task。
3-2 在查询中使用过滤
过滤即where子句
例如:
–模糊查询:查询名字以s开头的员工:
select empno,ename,sal from emp where ename like ‘s%’;
–模糊查询:查询名字含有下划线的员工:
select empno,ename,sal from emp where ename like ‘%\_%’;
3-3 在查询中使用排序
降序:desc
order by 后面跟:列,表达式,别名,序号
表达式:select empno,ename,sal, sal*12 from emp order by sal*12;
别名:select empno,ename,sal,sal*12 annsal from emp order by annsal;
序号:select empno,ename,sal,sal*12 annsal from emp order by 4;
**但之使用序号前要设置一个参数:set hive.groupby.orderby.position.alias=true;
空值是如何进行排序:
- 升序:null在最前面
- 降序:null在最后面**
第四章 Hive的内置函数
4-1 数学函数
round:四舍五入
例如:
select round(45.926,2), round(45.926,1), round(45.926,0), round(45.926,-1), round(45.926,-2)
结果为:45.93 45.9 46.0 50.0 0.0
注意:round函数有两个参数,第一个是要被四舍五入的数值,第二个是精确位数(例如2表示精确到小数点后两位,1表示精确到小数点后一位,0表示精确到小数点(个位),-1表示精确到十位,2表示精确到百位,以此类推)
ceil:向上取整
floor:向下取整
4-2 字符函数
**lower:把字符串转成小写
upper:把字符串转成大写
length:字符串长度(字符数)**
例如:
length(‘Hello World’), length(‘你好’),
上面的结果为:11 2
**concat:拼接字符串
substr:求字符串的子串**
substr(a,b):从a中,字符为b的位开始取,取右边所有的字符
substr(a,b,c):从a中,字符为b的位开始取,取c个字符
**trim:去掉字符串前后的空格
lpad:左填充**
例如:
select lpad(‘abcd’,10,’’); –对abcd进行左填充,填充到10位,多出位用 填充。
结果为: ******abcd
rpad:右填充
4-3 收集函数和转换函数
收集函数:size -求map集合元素个数
例如:
select size(map(1,’Tom’,2,’Mary’));
结果为: 2
转换函数:cast
例如:
select cast(1 as bigint), cast(1 as float), cast(‘2015-04-10’ as data);
结果为: 1 1.0 2015-04-10
4-4 日期函数
to_data:取出一个字符串中日期的部分
例如:
select to_data(‘2015-04-23 11:23:11’)
结果为: 2015-04-23
year:取出一个日期中的年YYYY
month:取出一个日期中的月MM
day:取出一个日期中的日DD
weekofyear:返回一个日期在一年中是第几个星期
datadiff:两个日期相减,返回他们相差的天数
data_add:在一个日期值上加上多少天
data_sub:在一个日期值上减去多少天
4-5 条件函数
coalesce:从左到右返回第一个不为null的值
case… when… :条件表达式
-CASE a WHEN b THEN c [WHEN d THEN e]*[ELSE f] END
例如:
给员工涨工资,总裁涨1000 经理涨800 其他涨400
select ename, job, sal,
case job when ‘PRESIDENT’ then sal+1000
when ‘MANAGER’ then sal+800
else sal+400
end4-6 聚合函数和表生成函数
聚合函数:比较简单
Count
sum
min
avg
表生成函数
explode:把一个map集合或者数组中的每个元素单独生成一个行。
总结:

第五章 Hive的表连接
5-1 等值连接和不等值连接
在进行多表查询时习惯给表取个别名
不等值连接:
例如:between … and …
5-3 外连接
通过外链接可以将对于连接条件不成立的记录任然包含在最后的结果中:
- 左外链接
- 右外链接
- 全外链接
5-4 自链接
自连接的核心:通过表的别名将同一张表视为多张表。
例如:
-查询员工的姓名和员工的老板姓名(员工的老板也是公司的员工):
select e.ename, b.ename
from emp e,emp b //把emp表看成两张表
where e.mgr=b.empno;
第六章 Hive的子查询
6-1 hive中的子查询
Hive只支持:form和where子句中的子查询
http://cwiki.apache.org/confluence/display/Hive/LanguageManual+SubQueries
书写子查询时要注意的问题:
- 语法中的括号不要忘了
- 合理的书写风格,方便阅读查询语句
- Hive中只支持where和from子句中的子查询
- 主查询和子查询可以不是同一张表
- 子查询中的空值问题
select * from emp e where e.empno not in (select mgr from emp e1); //可能出错,因为若子查询返回的结果中含有空值,则不能使用not in,没有空值则可以使用not in。所以因应改为select * from emp e where e.empno not in (select mgr from emp e1 where e1.mgr is not null);
第七章 Hive的客户端操作
7-1 hive的JDBC客户端操作
启动hive的远程服务
- #hive –service hiveserver
启动成功会出现:Starting Hive Thrift Server
步骤:
获取连接——》创建运行环境——》执行HQL——》处理结果——》释放资源
例如:
JDBCUtils.java文件的源代码
package demo.utils;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class JDBCUtils {
private static String driver = "org.apache.hadoop.hive.jdbc.HiveDriver";
private static String url = "jdbc:hive://192.168.56.31:10000/default";
//注册驱动
static{
try {
Class.forName(driver);
} catch (ClassNotFoundException e) {
throw new ExceptionInInitializerError(e);
}
}
//获取连接
public static Connection getConnection(){
try {
return DriverManager.getConnection(url);
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
//释放资源
public static void release(Connection conn,Statement st,ResultSet rs){
if(rs != null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}finally{
rs = null;
}
}
if(st != null){
try {
st.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
st = null;
}
}
if(conn != null){
try {
conn.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
conn = null;
}
}
}
}
HiveJDBCDemo.java文件的源代码:
package demo.hive;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import demo.utils.JDBCUtils;
public class HiveJDBCDemo {
/**
* @param args
*/
public static void main(String[] args) {
Connection conn = null;
Statement st = null;
ResultSet rs = null;
String sql = "select * from emp";
try {
//获取连接
conn = JDBCUtils.getConnection();
//创建运行环境
st = conn.createStatement();
//运行HQL
rs = st.executeQuery(sql);
//处理数据
while(rs.next()){
//取出员工的姓名和薪水
String name = rs.getString(2);
double sal = rs.getDouble(6);
System.out.println(name+"\t"+sal);
}
} catch (Exception e) {
e.printStackTrace();
}finally{
JDBCUtils.release(conn, st, rs);
}
}
}
7-2 hive的Thrift客户端操作
例如
HiveThriftClient.java文件的源代码
package demo.hive;
import java.util.List;
import org.apache.hadoop.hive.service.HiveClient;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.protocol.TProtocol;
import org.apache.thrift.transport.TSocket;
public class HiveThriftClient {
public static void main(String[] args) throws Exception{
//创建Socket;连接
final TSocket tSocket = new TSocket("192.168.56.31", 10000);
//创建一个协议
final TProtocol tProtcal = new TBinaryProtocol(tSocket);
//创建Hive Client
final HiveClient client = new HiveClient(tProtcal);
//打开Socket
tSocket.open();
//执行HQL
client.execute("desc emp");
//处理结果
List columns = client.fetchAll();
for(String col:columns){
System.out.println(col);
}
//释放资源
tSocket.close();
}
} 第八章 开发hive的自定义函数
8-1 hive中的自定义函数简介
Hive的自定义函数(UDF):User Defined Function
可以直接应用于select语句,对查询结果做格式化处理后,再输出内容
Hive自定义函数的是实现细节:
- 自定义UDF需要继承org.apache.hadoop.hive.ql.UDF
- 需要实现evaluate函数,evaluate函数支持重载
Hive自定义函数部署运行:
- 把程序打包放到目标机器上去
- 进入hive客户端,添加jar包:-hive>add jar /root/training/udfjar/udf_test.jar
- 创建临时函数:-hive>CREATE TEMPORARY FUNCCTION <函数名> AS ‘Java类名’
注意:临时函数的生命周期只在当前会话中。
Hive自定义函数的使用:
- select <函数名> from table;
销毁临时函数:
- hive>DEOP TEMPORARY FUNCTION <函数名>;
8-2 hive的自定义函数案例
ConcatString.java文件源代码:
package demo.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class ConcatString extends UDF {
public Text evaluate(Text a,Text b){ //这里不能使用string,因为string不能在hadoop集群中进行通信
return new Text(a.toString() +"****" + b.toString());
}
}
CheckSalaryGrade.java文件源代码:
package demo.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class CheckSalaryGrade extends UDF {
public Text evaluate(Text salary){
//定义返回的级别
Text grade = null;
double sal = Double.parseDouble(salary.toString());
//判断薪水的范围
if(sal < 1000){
grade = new Text("Grade A");
}else if(sal>=1000 && sal < 3000){
grade = new Text("Grade B");
}else{
grade = new Text("Grade C");
}
return grade;
}
}
第九章 课程总结
9-1 课程总结
通过元数据对表进行管理:嵌入模式、本地模式、远程模式。
Hive的编程接口:JDBC、客户端、自定义函数