企业级日志分析系统ELK(Elasticsearch , Logstash, Kibana)
企业级日志分析系统ELK(Elasticsearch , Logstash, Kibana)
- 前言
- 一、ELK概述
-
- 1、ELK日志分析系统
- 2、ELK日志处理特点
- 3、Elasticsearch概述
-
- (1)Elasticsearch的特性
- (2)分片和副本
- 4、LogStash概述
- 5、Kibana概述
- 二、部署ELK日志分析系统
-
- 1、配置elasticsearch环境
- 2、部署elasticsearch软件
-
- (1)安装elasticsearch—rpm包
- (2)加载系统服务
- (3)更改elasticsearch主配置文件
- (4)创建数据存放路径并授权
- (5)启动elasticsearch并查看是否成功开启
- (6)查看节点信息
- (7)检验集群健康状态
- (8)查看集群状态
- 3、安装elasticsearch-head插件
-
- (1)编译安装node组件依赖包
- (2)安装phantomjs(前端框架)
- (3)安装elasticsearch-head(数据可视化工具)
- (4)修改主配置文件
- (5)启动elasticsearch-head
- (6)使用elasticsearch-head插件查看集群状态
- (7)创建索引
- 4、安装logstash
-
- (1)安装Apahce服务(httpd)
- (2)安装Java环境
- (3)安装logstash
- (4)测试logstash命令
- (5)在Apache主机上做对接配置
- 5、安装kibana
-
- (6)对接Apache主机的Apache 日志文件(访问日志、错误日志)
- 总结
前言
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一、ELK概述
1、ELK日志分析系统
ELK是由Elasticsearch、Logstash、Kiban三个开源软件的组合。在实时数据检索和分析场合,三者通常是配合共用,而且又都先后归于 Elastic.co 公司名下,故有此简称。
2、ELK日志处理特点
一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的日志数据——将日志进行集中化管理(beats)
- 传输-能够稳定的把日志数据传输到中央系统——将日志格式化(Logstash),然后将格式化后的数据输出到Elasticsearch
- 存储-如何存储日志数据——对格式化后的数据进行索引和存储(Elasticsearch)
- 分析-可以支持 UI 分析——前端数据的展示(Kibana) 警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。
3、Elasticsearch概述
Elasticsearch是一个基于Lucene的搜索服务器。它基于RESTful web接口提供了一个分布式多用户能力的全文搜索引擎。
Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
(1)Elasticsearch的特性
接近实时的搜索
集群
节点
索引
索引(库)→类型(表)→文档(记录)
分片和副本
(2)分片和副本
在上述特性中,最重要的就是分片和副本,也是让es数据库(Elasticsearch)成为百度这些主流搜索引擎的主要原因,理论上能提升4倍的性能。
结合实际情况分析:索引存储的数据可能超过单个节点的硬件限制,如一个10亿文档需1TB空间可能不适合存储在单个节点的磁盘上,或者从单个节点搜索请求太慢了,为了解决这个问题,elasticsearch提供将索引分成多个分片的功能,当在创建索引时,可以定义想要分片的数量。每个分片就是一个全功能的独立索引,可以位于集群中任何节点上。
分片的特点:
水平分割扩展,增大存储量
分布式并行跨分片操作,提供性能和吞吐量
分布式分片的机制和搜索请求的文档如何汇总完全是有elasticsearch控制的,这些对用户而言是透明的
网络问题等等其他问题可以在任何时候不期而至,为了健壮性,强烈建议要有个故障切换机制,无论何种故障以防止分片或者节点不可用,为此,elasticsearch让我们将索引分片复制一份或多份,称为分片副本或副本
副本的特点:
高可用性,以应对分片或者节点故障,出于这个原因,分片副本要在不同的节点上
性能加强,增加吞吐量,搜索可以并行在所有副本上执行
4、LogStash概述
一款强大的数据处理工具
可实现数据传输、格式处理、格式化输出
数据输入、数据加工(如过滤,改写等)以及数据输出
常用插件:Input、Filter Plugin、Output
- Input:收集源数据(访问日志、错误日志等)
- Filter Plugin:用于过滤日志和格式处理
- Output:输出日志
5、Kibana概述
一个针对Elasticsearch的开源分析及可视化平台
搜索、查看存储在Elasticsearch索引中的数据
通过各种图表进行高级数据分析及展示
Kibana主要功能
- Elasticsearch无缝之集成
Kibana架构为Elasticsearch定制,可以将任何结构化和非结构化数据加入Elasticsearch索引。Kibana还充分利用了Elasticsearch强大的搜索和分析功能。
- 整合数据
Kibana能够更好地处理海量数据,并据此创建柱形图、折线图、散点图、直方图、饼图和地图。
- 复杂数据分析
Kibana提升了Elasticsearch分析能力,能够更加智能地分析数据,执行数学转换并且根据要求对数据切割分块。
- 让更多团队成员收益
强大的数据库可视化接口让各业务岗位都能够从数据集合受益。
- 接口灵活,分享更容易
使用Kibana可以更加方便地创建、保存、分享数据,并将可视化数据快速交流。
- 配置简单
Kibana的配置和启用非常简单,用户体验非常友好。Kibana自带Web服务器,可以快速启动运行。
- 可视化多数据源
Kibana可以非常方便地把来自Logstash、ES-Hadoop、Beats或第三方技术的数据整合到Elasticsearch,支持的第三方技术包括Apache flume、 Fluentd 等。
- 简单数据导出
Kibana可以方便地导出感兴趣的数据,与其它数据集合并融合后快速建模分析,发现新结果。
二、部署ELK日志分析系统
实验ELK拓扑图
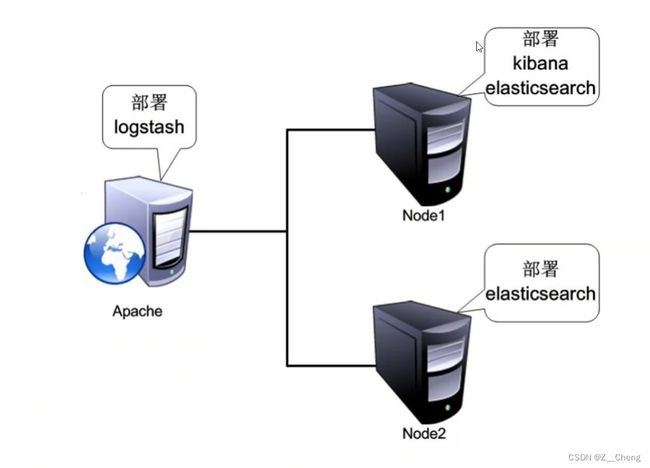
- 需求描述
配置ELK日志分析集群
使用Logstash收集日志
使用Kibana查看分析日志
- 此次ELK环境搭建
配置和安装ELK日志分析系统,安装集群方式,2个elasticsearch节点,并监控apache服务器日志
| 主机 | IP地址 | 软件 |
|---|---|---|
| node1 | 192.168.140.11 | Elasticsearch/Kibana |
| node2 | 192.168.140.12 | Elasticsearch |
| apache | 192.168.140.13 | httpd / Logstash |
| 客户机(宿主机) | 192.168.140.10 |
实验准备
关防火墙和系统安全机制
更改主机名