11 启用高可用特性
11 启用高可用特性
容错和Greenplum数据的高可用性功能可配置。
有关用于启用高可用性的实用程序的信息,请参阅Greenplum的数据库实用程序指南。
11.1 关于GPDB的高可用
一个Greenplum的数据库集群可以制成通过提供容错的硬件平台,通过支持Greenplum数据的高可用性功能高可用性,并通过执行定期监测及操作规程维修,确保所有系统组件的运行状况。
无论是正常失效还是意外情况,硬件组件将最终失效。断电会造成系统的暂时不可用。系统可用通过启用冗余的备用组件来实现当发生故障时可用提供不间断的服务。在一些情况下,维护高可用的成本高于服务失效时用户能忍受的程度。在这种情况下,目标就变成所有的服务都能被恢复,并且是在可预期的时间窗口内被恢复。
对于GPDB,容错性和数据可用性可以通过如下方式达到:
• 硬件RAID级别保护
• Greenplum 段镜像
• 主节点镜像
• 双集群
• 数据库备份及恢复
硬件RAID层次
最好的做法Greenplum数据部署使用硬件级别的RAID提供单个磁盘故障的高性能冗余,而不必进入数据库级别的容错。这提供了在磁盘级的容错。
段镜像
Greenplum的数据库存储在多个数据段,每一个都是Greenplum数据Postgres的实例。每个表的数据都是基于表在创建时所定义的散列策略而在不同的段上进行散列。启用段镜像后,每个段都有一个主段和一个镜像段。主段和镜像段执行相同的IO操作和存储相同的数据副本。
每段的镜像实例通常初始化为gpinitsystem实用程序或gpexpand实用程序。镜子二^ erent主机比主实例从一台机器出现故障保护上运行。有用于向主机分配的镜子不同的策略。当选择初选和镜子的布局,它要考虑的故障情况,以确保处理歪斜在一台机器出现故障的情况下,最小化是很重要的。
每个段实例的镜像都是通过gpinitsystem实用程序或gpexpand实用程序进行实例化的。镜像段运行在主段之外的其他主机上,从而避免单机失效。选择主段的镜像段有两种不同的策略。在选择主段和镜像段是,需要考虑单个主机失效的场景下,处理数据倾斜的代价最小。
master节点镜像
有两个大师高可用性群集,一所小学和一个备用。至于段,主备应在不同主机上部署,使集群能够容忍单个主机故障。客户端连接到主主查询只能在主主执行。
辅助主通过复制从主写日志(WAL)到二次跟上最新。
如果主站出现故障,管理员运行gpactivatestandby工具有备用主接替为新的主主。您可以配置主服务器和备用虚拟IP地址,这样客户端程序不必切换到不同的网络地址时,当前的主变化。如果主主机出现故障,虚拟IP地址可以被交换到他的实际表演大师。
在一个高可用的集群中有两个可用的master节点,一主一备。主备节点必须部署在不同的主机上使得集群可以容忍单节点失效。客户端连接到主节点上,所有的查询也在主节点上执行。
备用主节点通过从主节点复制WAL(write-ahead log)到备用节点以实现和主节点同步。如果主节点失效,管理员运行gpactivatestandby使得热备节点代替失效的节点。你可以为主节点和热备节点配置一个虚拟IP,这样当主节点失效时,虚拟IP可以转移到实际活动的节点上。
双集群
冗余的额外水平可以通过维护两个Greenplum数据群集,既存储相同数据来提供。
保持双集群同步的数据有两种方法“双重ETL”和“备份/恢复”。
双ETL提供相同的数据作为主群集的完整备用集群。 ETL(提取,转换和加载)是指清洗的过程,转化,验证和输入数据加载到数据仓库中。具有双ETL,并行执行该过程两次,一次每个群集上,每一次验证。它还允许数据在两个群集上进行查询,查询吞吐量翻一番。应用程序可以利用这两个集群的优势,也保证了ETL是成功的,在两个群集验证。
为了保持与备份双群集/恢复方法,创建主集群的备份和辅助群集上恢复它们。这种方法需要更长的时间,以比双ETL策略辅助群集上的数据进行同步的,但需要较少的应用程序逻辑被开发。填充与备份的第二个集群是在数据的修改和ETL每天或不常执行用例的理想选择。
另一种方式是维护两个GPDB集群,即在两个集群上存储相同的数据。确保双集群数据同步的方法有两种,分别是“双重ETL”和“备份/恢复”。
双重ETL提供了一个和主集群数据完全相同的热备集群。ETL(提取,转换和加载)是指清洗的过程,转化,验证和输入数据加载到数据仓库中。如启用双重ETL,则操作过程需要分别在主集群和热备集群上并行执行。它也支持数据在两个集群上查询,查询的吞吐量也翻了一番。应用程序可以充分利用双集群的优势,同事也需要严格的校验,以确保ETL在两个集群上的执行都是成功的。
如果采用备份/恢复的方式来维护双集群,则需要在主集群上执行备份操作,并在热备集群上执行恢复操作。这种方式需要更长的操作时间,但程序的逻辑开发量较少。对于数据修改很少或ETL任务很少的情况下,采用备份/恢复的方式来维护一个热备集群是不错的主意。
备份和恢复
除非是数据库可以从原始数据很快的重构出来,否则建议对数据库进行定期备份。备份必须能避免操作错误、软件错误和硬件错误。
使用GPDB提供的gpcrondump来备份数据库。gpcrondump可以跨段进行并行备份,因此随着集群的扩展,备份性能也水平扩展。
在设计备份策略时,首要考虑的是在哪存储备份数据。各个段管理的数据可以存储在段的本地存储上,但是不应该在那永久存储。备份不但降低了能提供给段使用的硬盘空间,并且更重要的是,一个硬件故障可以同时破坏段的在线数据和备份数据。
当执行完备份后,备份文件必须从集群中转移到一个独立的、安全的存储上。当然你也可以直接将备份存储到独立的存储设备上。
备份数据库的额外选项如下:
数据域
通过本机API集成备份可以传输到EMC的Data Domain的设备。的NetBackup
通过本机API整合,备份可以传输到赛门铁克NetBackup集群。
NFS
如果NFS挂载在集群中的每个Greenplum数据主机上创建,备份可以直接写入NFS挂载。推荐使用向外扩展解决方案,NFS,以确保备份不会对IO吞吐量NFS设备的瓶颈。 EMC Isilon公司是可以沿着侧向外扩展的集群Greenplum的一个例子。Through native API integration backups can be streamed to an EMC DataDomain appliance. NetBackup
增量备份
GPDB支持在分区层面对追加优化表和列存储表进行增量备份。当你执行增量备份时,只有数据发生变化的追加优化表和列存储表被备份了。(堆表总是全量备份)。恢复一个增量备份,只需要重新恢复以前的一个全量备份和后续的增量备份。
当数据库包含很大的分区表,并且只有很少数的分区数据发生变化时,采用增量备份是最好的。增量备份至存储发生变化的分区和堆表。因为无需对未变化的分区进行备份,使得备份文件的大小和备份时间都大大缩短。
当一个非常大的非分区的事实表发生1行数据新增或修改时,整个表都会被备份,这样既浪费空间又浪费时间。因此,仅推荐对包含非常大的分区表和数据量很小的维表的数据库进行增量备份。(典型的数据仓库应用场景,大事实表+小维表)
如果你使用增量备份来维护双集群,则可以对第二个集群使用增量备份。使用--noplan选项可以加快从主站点备份的速度。
11.1.1段镜像概述
当启用GPDB的高可用,有两种类型的段:主段和镜像。每个主段都有一个相应的镜像段。主段接收master发出的请求,改变自身数据库的数据状态,并将这些变化复制到对应镜像段上。如果主段不可用,则数据库查询故障迁移到镜像段上。
段镜像通过物理文件复制模式-在主段上的数据文件I/O被复制到镜像节点上,因此镜像节点的数据文件等同于主段的文件。在GPDB中的数据表现为表和元组,实际上被封装为块。数据库的表在磁盘上的文件由一个或多个数据块组成。到一个元组的变化被保存到该块中,然后写入到主段并通过网络复制到镜像上。镜像更新其文件副本相应的数据块。
对于堆表,块保存在内存的缓存中,直到它们被移出以便腾出空间给新更改的数据块。这样系统无需执行昂贵的磁盘I/O就可以在内存中多次更新数据块。当其从内存中移出时,将数据写入到磁盘并复制到镜像上。当块在缓存中时,主段和镜像段持有该段的不同的状态。但是数据库仍然是一致的,因为事务日志已被复制到镜像上。当镜像段接替发生故障的主段时,在日志中的交易数据就被应用到数据库表上。
其他数据库对象 - 例如文件空间,这是与内部代表的表空间的目录,也可以使用文件复制到以同步的方式进行各种文件操作。
Append-optimized tables do not use the in-memorycaching mechanism. Changes made to append- optimized table blocks arereplicated to the mirror immediately. Typically, file write operations areasynchronous, while opening, creating, and synchronizing files are "sync-replicated,"which means the primary blocks until it receives the acknowledgment from thesecondary.
追加优化表不使用内存缓存机制。对追加优化表的数据块的更改将立即复制到镜像上。典型的,文件写操作是异步的,而文件的打开、创建和同步是“同步复制”的,这意味着主段的数据块必须接到镜像块的确认。
如果主段发生故障,则文件复制过程停止,镜像段自动启动为活动的段实例。这个活动的镜像系统开始记录更改,也就是说镜像段在主段不可用的这段时间内维护系统表和所有的块的更改日志。当失效的主段被修复并重新联机时,管理员启动恢复过程,系统进入重新同步状态,恢复进程接收适用于修复主段的记录更改,当恢复过程完毕后,系统状态变为同步。
当主段在激活的状态下而镜像段失效或不可用,则主段的系统状态变为更改追踪(ChangeTracking),记录需要施加到镜像恢复时所需的所有变化。
镜像段和主段的实例必须运行在不同主机上,但镜像段可以有不同的配置方式。每个主机都必须有相同数量的主段和镜像段,默认的镜像配置是分组镜像,也就是说一个主机的主段的镜像都部署在另外一个主机上。如果一个主机失效,则镜像段所在的主机活动主段的数量就会增加一倍。图7:在GPDB中的分组镜像 演示了分组镜像的配置。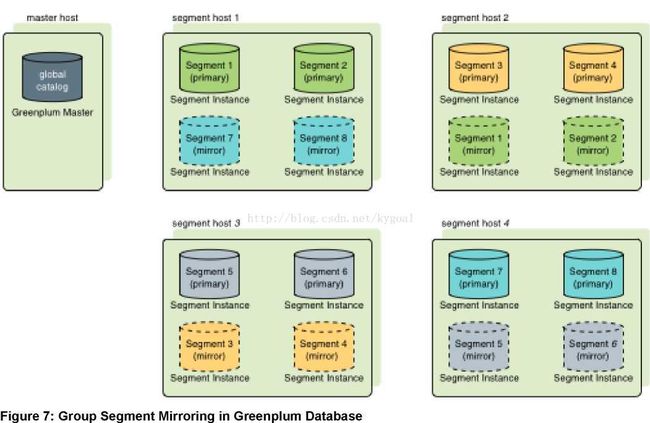
传播镜像策略把每个主机的镜像分布到不同的主机上以防单个主机失效。除了主节点,剩余每个节点都最多有一个段镜像。传播镜像策略要求节点的个数大于单个主机上主段的个数。图8:在GPDB中的传播镜像 演示了在启用传播镜像模式后镜像的分布情况。

The Greenplum Database utilities that create mirrorsegments support group and spread segment configurations. Custom mirroringconfigurations can be described in a configuration file and passed on thecommand line.
GPDB的实用程序可以建立分组镜像和扩散镜像。定制的镜像配置可以在配置文件中进行描述,并在命令行中执行。
11.1.2Master镜像概述
你可以在单独的主机上部署master实例或在同一个主机上。备份master或standby master被用作热备master。当主master不可用时,就能用热备master来顶替master。当主master在线时,你可以创建一个standby master.
主master在为用户提供服务的同时,相应的事务快照已创建。这些业务快照被应用到standby master上,同时主master的改变也被记录。当业务快照被应用到stadby master之后,standby master就会应用相应的跟新以便和主master同步。当主master和standby master完成同步后,standby master就采用walsender和walreceiver复制过程保持最新状态。该walreceiver是一个备用主过程。
该walsender过程是一个主master的进程。这两个进程使用基于WAL-流复制到保持主备master的同步。
因在master上不保存用户数据,只有系统目录表需在主master和热备master之间同步。当这些表更新后,相应的变化会自动复制到standby master以便保持两者完全同步。
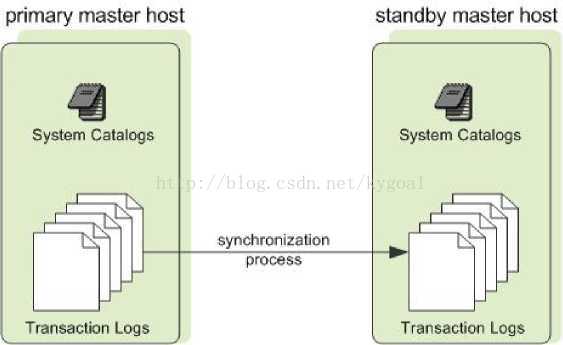
Figure 9: Master Mirroring in Greenplum Database
如果主master失效,则复制过程停止,管理员可以激活standby master。当standby master激活后,复制日志会重建在上次成功提交后主master的状态。此后,standby master就作为GPDB的主master,在standbymaster初始化时设定的端口上接受连接。
11.1.3 故障检测和恢复概述
GPDB服务器(postgres)启用名为ftsprobe的子进程来做故障检测。Ftsprobe监控Greenplum数据库阵列。它会在你可配置的时间间隔内连接到所有的段以及数据库上进行扫描。如果ftsprobe无法连接到一个段,那它就在GPDB的系统目录里将这个段标记为“关闭”。这个段会保持无法操作状态直至管理员启动恢复进程。
当镜像启用后,GPDB会在主段不可用时自动故障转移到镜像段上。如果段实例或主机的所有数据都在,则GPDB系统就可以继续运行。为了恢复失效的段,管理员需要运行gprecoverseg recovery。这个实用程序会定位到失效的段,验证它们是有效的,并且其失效阶段在活跃段上执行的事务进行重现。Gprecoverseg从活跃的段上同步变化的数据库文件并将其联机。
管理员在GPDB正在运行时执行恢复操作。
镜像禁用后,如果段实例失效,则系统自动关闭。管理员必须手工恢复所有的失效段后,系统才能恢复使用。
参看检测失败的段用于故障检测和恢复过程和配置选项的更详细的说明。
11.2 在GPDB中启用镜像
你可以在安装时使用gpinitsystem来启用镜像,或安装后通过使用gpaddmirrors 和 gpinitstandby来启用镜像。
如下话题假设你要对一个现有的没有启用镜像的系统来增添镜像功能。
你可以启用如下类型的镜像:
• 启用段镜像
• 启用master镜像
11.2.1启用段镜像
镜像段可以在主段不可用时进行故障转移到备份段。默认的情况下,镜像段被配置在和这段相同的阵列中。你可以选择一套完全不同的主机来部署这些镜像段,使它们不与任何主段公用机器。
重要事项:在这在线数据复制的过程中,GPDB应该处于静止状态,工作负载或其他查询都不要运行。
11.2.1.1 为现有系统添加段镜像 (和主段相同的主机)
1. 在所有的段主机上为镜像段分配存储区域,这些存储区域必须和主段的存储区域不同。
2. 使用gpssh-exkeys以确保段上的主机可以在没有密码提示SSH和SCP对方。
3. 运行gpaddmirrors实用工具来在你的GPDB系统中启用镜像,例如,在主段的端口上添加10000 以便计算镜像段的端口:
$ gpaddmirrors -p 10000
-p 指定了在主段端口上增加的数字,镜像就会按照默认的分组镜像配置方式添加到系统中。
11.2.1.2 为现有系统添加段镜像(不同于主段的主机)
1. 确保GPDB软件在所有的主机上都已安装,详细步骤见Greenplum的数据库安装指南。
2. 在所有的段主机上分配存储空间.
3. 使用gpssh-exkeys以确保段上的主机可以在没有密码提示SSH和SCP对方.
4. 创建列出主机名,端口和数据目录文件的配置文件。如果需要从示例文件创建,命令如下:
$ gpaddmirrors -o filename
The format of the mirror configuration file is:
filespaceOrder=[filespace1_fsname[:filespace2_fsname:...]
mirror[content]=content:address:port:mir_replication_port:
pri_replication_port:fselocation[:fselocation:...]
例如,对于有两个段的主机和每个主机两个段,且除默认pg_system文件空间外无其他额外文件空间的配置文件如下:
filespaceOrder=
mirror0=0:sdw1-1:52001:53001:54001:/gpdata/mir1/gp0
mirror1=1:sdw1-2:52002:53002:54002:/gpdata/mir1/gp1
mirror2=2:sdw2-1:52001:53001:54001:/gpdata/mir1/gp2
mirror3=3:sdw2-2:52002:53002:54002:/gpdata/mir1/gp3
5. 运行gpaddmirrors实用工具,启用Greenplum数据系统镜像:
$ gpaddmirrors -i mirror_config_file
Where -i names the mirror configuration file youcreated.
11.2.2启用master镜像
你可以在创建GPDB数据库时使用gpinitsystem或者在后期通过gpinitstandby启用master镜像。
本主题假定你要在初始化时没有启用的情况下添加一个standby master.
. 有关实用程序的信息gpinitsystem和gpinitstandby,看到Greenplum的数据库实用序指南。
11.2.2.1 为现有系统添加一个standby master
1. 确认standby master主机已按如下要求安装和配置:gpadminsystem user已创建, Greenplum Database 二进制文件已安装, 环境变量已设置好, SSH keys exchange,数据目录也已创建.Greenplum Database
2. 在当前活动的primary master主机上运行gpinitstandby实用程序以添加standby master 主机到你的数据库系统。例如:
$ gpinitstandby -s smdw
Where -s specifies the standby master host name.
3. 如果要切换到standby master, seeRecovering a FailedMaster.
11.2.2.2 检查master镜像的进程状态 (optional)
你可以在系统视图pg_stat_replication中查询相应的信息. 该视图列出了有关用于Greenplum数据主镜像walsender过程的信息。例如,该命令将显示walsender进程的进程ID和状态:
$ psql dbname -c 'SELECT procpid, state FROMpg_stat_replication;'
有关pg_stat_replication系统视图的信息,请参阅Greenplum数据参考指南。
11.3 检测故障段Detecting aFailed Segment
使用镜像启用后,当主段出现故障Greenplum数据引擎会自动故障转移到镜像段。在提供仅有的一个段实例在线的情况下,用户可能没有意识到段已经关闭。发生故障时,如果事务正在进行,则正在进的事务会回滚,并且在重新配置的段上重新启动。如果整个数据库因段错误(如镜像没启用或没有足够的在线的段来访问用户所有的数据)而变得不可操作。的用户尝试连接到数据库时回出现错误。错误返回给客户端程序可以指示故障。 例如:
错误:所有段的数据库不可用
ERROR: All segment databases are unavailable
11.3.1段故障如何检测和管理
在GPDB的主节点上,Postgres的postmaster进程启用一个错误探测进程,ftsprobe。这有时被称为FTS(容错服务器)的过程。如果FTS失败,则postmaster进程会重新启动它。
If no issues are detected, a positive reply is sentto the FTS and no action is taken for that segment database.
FTS运行过程中,在每个循环间都有休眠过程。在每次循环中,FTS通过使用在gp_segment_configuration表中登记的主机名和端口TCP套接字连接到数据库段探针每个主段的数据库。如果连接成功,段执行一些简单的检查,并报告给FTS。这些检查包括执行关键段目录中的统计系统调用和检查在段实例内部故障。如果未检测到问题,则发给FTS一个肯定答复并且对此段的数据库不采取任何行动。
如果无法连接,或者在时间窗口内答复没有被接收。则尝试重新连接这个段服务器。如果探测尝试到配置的最大失败次数时,FTS探测其段的镜像以确保段镜像是活动的,然后更新gp_segment_configuration表,将主段标记为“关闭”并将镜像设置为主。FTS在执行完此操作后更新gp_configuration_history表。
如果主段是活动的并且对应的镜像段是被关闭的,则主段进入到更改记录模式"Change Tracking Mode"。在这种模式下,段的所有更改都被记录,镜像段可以在无需完全复制主段的数据下进行同步。
gprecoverseg是用来将关闭的镜像启动,默认情况下,gprecoverseg执行增量恢复,将镜像进入重新同步模式,开始重做从主记录的修改到镜像。如果增量恢复不能完成,恢复失败。Gprecoverseg应当再次启动并且加上-F选项来运行,以执行完全恢复。这使主段的所有数据复制到镜像段。
你可在gp_segment_configuration表中看到每个段的模式-“更改跟踪”,“重新同步”或“在同步”,以及段的状态“up”“down”。
这个gp_segment_configuration 表还有 role 和preferred_role这两列。对于p代表主段,m代表镜像段。role列显示这个段的数据库当前的角色状态,preferred_role显示这个段初始的角色。在一个平衡的系统中,role和preferred_role对所有的段都应当匹配。如果不匹配,则说明每个硬件服务器上的主段数量有倾斜。重新平衡群集,并把所有细分成自己喜欢的角色,在gprecoverseg命令可以使用-r选项来运行。
有一组的影响FTS行为服务器配置参数:
gp_fts_probe_threadcount
用于探测区段的线程数。默认值:16
gp_fts_probe_interval
多久,以秒为单位,开始一个新的循环FTS。例如,如果设置是60和探头循环需要10秒,FTS的过程休眠50秒。如果设置为60和探头循环需要75秒的进程睡眠0秒。默认值:60
gp_fts_probe_timeout
探测主段和镜像段的探测超时,以秒为单位,默认:20
gp_fts_probe_retries
探测一个段的尝试次数。例如,如果设置为5,则在第1次尝试失败后会再进行4次尝试,默认值:5
gp_log_fts
日志记录级别FTS。该值可能是“关”,“简洁”,“详细”,或“调试”。在“详细”
设置可以在生产中使用,以用于故障诊断提供有用的数据。 “调试”设置不应该在生产中使用。默认值:“简洁”
gp_segment_connect_timeout
允许段响应时间的最大值,以秒为单位。默认值:180
对于FTS执行的故障检查外,一个主区段是无法发送数据到其镜像段以将段的状态改为“关闭”。主段等候gp_segment_connect_timeout秒之后,确认镜像失败,这样会导致这个镜像被标记为“关闭”并且主段进入到“跟踪模式”。
11.3.2 启用警报和通知
要接收系统事件的通知,如段故障,启用电子邮件或SNMP警报。请参阅启用系统警报和通知。
11.3.3检查段失败
在启用段镜像后,在系统中可能有失败的段实例,但没有迹象表明正常的服务被中断,或有任何错误发生。你可以通过gpstate来检查系统的状态。gpstate提供了GPDB数据库系统的,包括主段,镜像段,master,standby master的状态。
11.3.3.1 检查失败的段
1. On the master, run the gpstate utility with the -eoption to show segments with error conditions:
$ gpstate -e
段在处于状态收集模式下,说明对应的段已经关闭。当一个段不是它预想的角色时,这个段不是在执行在它初始化时设定的角色。这就说明系统处于一个不均衡的状态,因为一些主机上的活动实例数已超过系统最优的设定状态。
SeeRecovering From SegmentFailures for instructions to fix this situation.
2. 要获取有关失败段的详细信息,请检查gp_segment_configuration置目录表。 例如:
$ psql -c "SELECT * FROMgp_segment_configuration WHERE status='d';"
3. 对于失败段的情况下,请注意主机,端口,首选的角色,和数据目录。这些信息将帮助确定主机和段实例解决。
4. 如要显示镜像段的相关信息,运行:
$ gpstate –m
11.3.3.2 Checking the Log Files for Failed Segments
日志文件可以提供信息,以帮助确定错误的原因。船长和段每个实例都在数据目录的pg_log自己的日志文件。主日志文件包含的信息最多,你应该总是先检查一下。
使用gpiogfilter实用程序,检查Greenplum的数据库日志文件以获取更多信息。要检查段的日志文件,使用gpssh网段主机上运行gplogfilter。
11.3.3.3 To check the log files
1. Use gpiogfilter to check the master log file for warning, error, fatal or panic log level messages:
$ gplogfilter -t
2. Use gpssh to check for warning, error, fatal, or panic log level messages on each segment instance. 例如:
$ gpssh -fseg_hosts_file -e 'source
/usr/local/greenplum-db/greenplum_path.sh; gplogfilter -t
/data1/primary/*/pg_log/gpdb*.log' > seglog.out
11.4 恢复一个失败的段

如果master无法连接到段实例上,说明这个段已经在GPDB的系统目录中被标记为“关闭”。这个段会保持离线状态,直到管理员采取措施使之恢复在线状态。恢复段实例或主机的步骤取决于造成失败的原因,并且包括镜像是否启用。一个段实例可能因多种原因造成无法使用:
• 一个段实例因为网络或硬件错误无法访问。
• 段实例没有运行,例如数据库监听器postgres没有运行
• 这个段的数据目录损坏或丢失。例如,数据无法访问,系统损坏,磁盘失效等。.
• 图10:段故障排除矩阵显示了每个前故障场景的高级步骤。
Figure 10: Segment Failure Troubleshooting Matrix
11.4.1段失败恢复
段主机失效会造成多个段的失败:这个主机的所有的主段或镜像段都会被标记为“关闭”。如果没用启用镜像,并且一个段关闭,则整个系统都变为不可用。
11.4.2从启用镜像的方式恢复
1. 确认你无法从master主机访问段主机,例如:
$ ping failed_seg_host_address
2. 排除master主机连接到段主机的问题。例如段主机可能需要重启或更换。
3. 段主机在线并且能连接后,在master上执行gprecoverseg实用程序来激活失败的段实例。例如:
$ gprecoverseg
4. 恢复进程启动失败的段实例,并且识别哪些更改后的文件需要进同步。这个过程会需要一些时间,在此过程中,数据库写操作被挂起。
5. gprecoverseg 完成后,系统进入重新同步模式,并开始复制更改的文件。这个过程在后台运行,同时系统联机并接受查询请求。
6. 当同步过程完成后,系统的状态是同步(Synchronized)的。可以执行gpstate来核实。
$ gpstate -m
11.4.3将所有的段更改为其首选的角色
当一个主段关闭后,镜像段被激活并成为主段。在重新执行gprecoverseg后,当前活动的段仍为主段并且失败的段转为镜像段。这些段实例无法回到其在初始化时设定的首选角色。这就意味着系统处于一个不均衡的状态,可能有些主机上的活动实例超过了系统最佳实例数。为了检查这些不不均衡的实例并且将系统重新均衡,执行:
$ gpstate -e
所有的段都必须在线并且已完成同步才能完成系统的重平衡。数据库连接在重平衡时仍然连接,但是所有正在执行的查询都被取消并且回滚。
1. 执行 gpstate -m 以确认系统是 Synchronized.
$ gpstate -m
2. 如果有任何镜像是处于 Resynchronizing 模式,耐心等待直到其完成。
3. 执行 gprecoverseg -r 使得所有的角色都回到其首选橘色.
$ gprecoverseg -r
4. 在重新平衡后,运行gpstate -e 以确认所有的角色都是其首选角色.
$ gpstate -e
11.4.4To recover from a double fault
对于一个double fault,主段和镜像段都已关闭。在不同段上的主机同时发生主机硬件故障时会发生这种情况。GPDB在这种情况下无法使用,处理措施如下:
1. 重新启动数据库:
$ gpstop -r
2. After the system restarts, run gprecoverseg:
$ gprecoverseg
3. After gprecoverseg completes, use gpstate to checkthe status of your mirrors:
$ gpstate -m
4. If you still have segments in Change Tracking mode,run a full copy recovery:
$ gprecoverseg -F
如果一段主机是不可恢复的,你已经失去了一个或多个片段。则必须从Greenplum的备份中重新恢复数据库系统。请参阅备份和还原数据库。
11.4.5To recover without mirroringenabled
1. 确认你能连接到段主机,例如:
$ ping failed_seg_host_address
2. 排除master主机连接到段主机的问题。例如段主机可能需要重启或更换。
3. 当主机联机后,确认你能连接并重启GPDB数据库系统,例如:
$ gpstop -r
4. 重新执行 gpstate 以确认所有的段都在线。
$ gpstate
11.4.6当一个段无法恢复时
如果主机不可操作,例如,由于硬件故障,恢复到段备用组硬件资源。如果镜像启用,您可以使用gprecoverseg恢复其镜段上的备用主机。 例如:
$ gprecoverseg -i recover_config_file
Where the format of recover_config_file is:
filespaceOrder=[filespace1_name[:filespace2_name:...]failed_host_address:
port:fselocation[recovery_host_address:port:replication_port:fselocation
[:fselocation:...]]
例如,要恢复到不同的主机比没有配置其他文件的空间故障主机(除了默认pg_system文件空间):
filespaceOrder=sdw5-2:50002:/gpdata/gpseg2sdw9-2:50002:53002:/gpdata/gpseg2
该gp_segment_configuration和pg_filespace_entry系统目录表可以帮助确定当前的段配置,这样你可以计划你的镜子恢复配置。例如,运行以下查询:
=# SELECTdbid, content, hostname, address, port,
replication_port,fselocation as datadir
FROMgp_segment_configuration, pg_filespace_entry
WHEREdbid=fsedbid
ORDER BY dbid;
新恢复的段主机必须预先安装了Greenplum的数据库软件,并且配置和现有的主机完全一样。
11.5 Recovering a Failed Master
如果 primary master失效,则日志复制停止。使用 gpstate –f命令来检查standby实例的状态。使用gpactivatestandby 激活 standby master. 当standby master激活后, Greenplum 数据库从上次成功提交的状态来重建master。
11.5.1To activate the standby master
1. 确认standby master 主机在系统中已配置。详情参见Enabling Master Mirroring.
2. 在standby master上执行gpactivatestandby.例如:
$ gpactivatestandby -d /data/master/gpseg-1
Where -d specifies the data directory of the masterhost you are activating.
当你激活standby之后,它在GPDB中就成为活动/主master
3. 操作完成后,重新运行gpstate以检查状态。
$ gpstate -f
新激活的主机的状态应该是活动Active。如果配置了新的备用主机,其状态是被动Passive的。如果没有配置备用主,找到了命令显示-No条目和消息表明备用主实例没有配置。
4. 切换到新的活动master之后,run analyze onit. 例如:
$ psql dbname -c 'ANALYZE;'
5. 可选:如果您在运行gpactivatestandby实用程序时没有指定新的备用主机上,使用gpinitstandby在稍后的时间来配置一个新的备用主。在活动主服务器主机上运行gpinitstandby。 例如:
$ gpinitstandby -s new_standby_master_hostname
11.5.2 Restoring Master Mirroring After a Recovery
当你因为恢复而激活standby master之后,standby master 成为primarymaster。你可以继续运行,将此实例作为作为primary master,如果它具备和原master相同的能力和可靠性。
你必须重新初始化一个新的standby master以继续提供master的镜像功能,除非你已经做了。在活动master上执行gpinitstandby用以配置一个新的standby master。
你可能在原来的主机上恢复primary master 和standby master。这个过程是交换primarymaster 和standby master的角色。除非你更倾向于在恢复前的配置状态,否则就按照现在的配置运行。
For informationabout the Greenplum Database utilities, see the Greenplum Database Utility Guide.
11.5.2.1 To restore the master and standby instances on original hosts(optional)
1. 确认初始的master数据处于可靠的运行状态,确认导致系统失效的错误都已修复。
2. 在原来的主机上,移动或删除数据目录gpseg-1. 在此例中是将其移动到 backup_gpseg-1:
$ mv /data/master/gpseg-1/data/master/backup_gpseg-1
一旦配置成功,你可以删除备份目录。
3. 在最初的主机上初始化standby master.例如,从当前的mastersmdw 执行命令:
$ gpinitstandby -s mdw
4. 当初始化结束后,检查standby master mdw的状态, rungpstate with the -f option to check the status:
$ gpstate -f
The status should be In Synch.
5. 在standby master上停用master实例. 例如:
$ gpstop -m
6. 在最初的master主机mdw,当前是standby master上运行gpactivatestandby。 例如:
$ gpactivatestandby -d $MASTER_DATA_DIRECTORY
Where the -d option specifies the data directory ofthe host you are activating.
7. 命令操作完毕后,重新执行gpstate以核实系统状态:
$ gpstate -f
必须确认先前的primary master状态是 Active. 当standby master没有配置时,命令会显示-No 条目被发现,说明standby master 没有启用。.
8. 在standby master 主机, 移动或删除 gpseg-1. 在此例中是移动到目录
$ mv /data/master/gpseg-1/data/master/backup_gpseg-1
一旦standby master配置成功,你可以删除备份目录。
9. 当最初的master主机运行primaryGreenplum Database master, 你可以在原来的standby master主机上初始化standbymaster 例如:
$ gpinitstandby -s smdw
11.5.2.2 To check the status of the master mirroring process (optional)
你可以在系统视图pg_stat_replication中查询相关信息。这个视图显示用于master镜像的walsender的相关状态。
例如, 这个命令显示了walsender 的process ID 和 state:
$ psql dbname -c 'SELECT procpid, state FROMpg_stat_replication;'