分析CDNow的用户消费行为
CDNow网站的用户消费行为分析
本文的数据来源CDNow网站的用户购买明细,一共包括用户ID,购买日期,购买数量,购买金额四个字段。
【数据源】百度网盘链接:https://pan.baidu.com/s/1I3EF8wKaFvCrJmM0Sviqew
提取码:p345
分析思路
- 导入和清洗数据
- 按月分析用户消费趋势
- 用户个体消费分析
- 用户消费行为分析
1.导入清洗数据
1.1导入常用第三方包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')
数据集来源于CDnow网站的用户购买行为,数据集一共包含四个字段:
user_id: 用户ID
order_dt: 购买日期
order_products: 购买产品数量
order_amount: 购买金额
1.2导入数据
columns=['user_id','order_dt','order_products','order_amount'] #创建列表columns来放置列名
df=pd.read_csv(r'C:\Users\me\Desktop\CDNOW_master.txt',names=columns,sep='\s+') #读取文件,names设定创建列名,分隔符设定\s+,表示多个空格
加载包和数据,文件是txt,用read_csv方法打开,因为原始数据不包含表头,所以需要赋予。字符串是空格分割,用\s+表示匹配任意空白符。
print(df.head()) #查看数据前6行

观察数据,order_dt表示时间,但现在是字符串的形式,后续分析需要对其进行转换为时间类型。另外购买金额的数据类型为浮点型。
值得注意的是,这些数值都不具有唯一性,比如一个用户在一天内可能购买多次,用户ID为2的用户就在1月12日买了两次,这个细节不要遗漏。
查看数据类型
print(df.info())

用df.info()函数来查看数据表的基本信息(维度、列名称、数据格式、所占空间等),运行结果显示没有空值,很干净的数据。
查看描述性统计
print(df.describe())

描述性统计分析结果得出,用户平均每笔订单购买2.4个商品,标准差在2.3,稍稍具有波动性。中位数在2个商品,75%分位数在3个商品,说明绝大部分订单的购买量都不多。最大值在99个,数字比较高。购买金额的情况差不多,大部分订单都集中在小额,。
一般而言,消费类的数据分布,都是长尾形态。大部分用户都是小额,然而小部分用户贡献了收入的大头,俗称二八分布。
时间转换
df['order_dt']=pd.to_datetime(df.order_dt,format="%Y%m%d") #转换为时间类型
df['month']=df.order_dt.values.astype('datetime64[M]') #创建新的列,显示购买月份
print(df.head())
 pd.to_datetime可以将特定的字符串或者数字转换成时间格式,其中的format参数用于匹配。例如19970101,%Y匹配前四位数字1997,如果y小写只匹配两位数字97,%m匹配01,%d匹配01。
pd.to_datetime可以将特定的字符串或者数字转换成时间格式,其中的format参数用于匹配。例如19970101,%Y匹配前四位数字1997,如果y小写只匹配两位数字97,%m匹配01,%d匹配01。
另外,小时是%h,分钟是%M,注意和月的大小写不一致,秒是%s。若是1997-01-01这形式,则是%Y-%m-%d,以此类推。上图是转化后的格式。月份依旧显示日,只是变为月初的形式。
astype也可以将时间格式进行转换,在转换前,必须先用values转为数组。本文室使用datetime64[M]将其转化成月份。后续分析我们将以月份作为主要单位,对数据进行分析。
2.按月分析用户消费趋势
- 每位用户的消费情况
- 每月的消费总金额
- 每月的消费次数
- 每月的产品购买量
- 每月的消费人数
2.1 每位用户的消费情况
按用户对数据进行聚合
user_consume=df.groupby('user_id').sum()[['order_products','order_amount']]
print(df.head())

user_consume.describe()

从用户角度看,每位用户平均购买7张CD,最多的用户购买了1033张,属于狂热用户了。用户的平均消费金额(客单价)100元,标准差是240,结合分位数和最大值看,平均值和75%分位数更接近,应该是存在小部分的高额消费用户。
2.2 每月的消费总金额
order_month_amount=df.groupby('month').order_amount.sum()
print(order_month_amount.head())
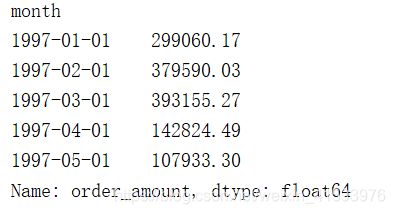
月份-消费总金额关系折线图
order_month_amount.plot()
plt.show()

由上图可知,前三个月的销量上涨很快,数据较为异常。而从第四个月开始显著下降,后续的销量整体比较稳定,呈轻微下降趋势。
2.3 每月的消费总金额
月份-消费次数关系折线图
order_month_products=df.groupby('month').order_products.sum().plot()
plt.show()
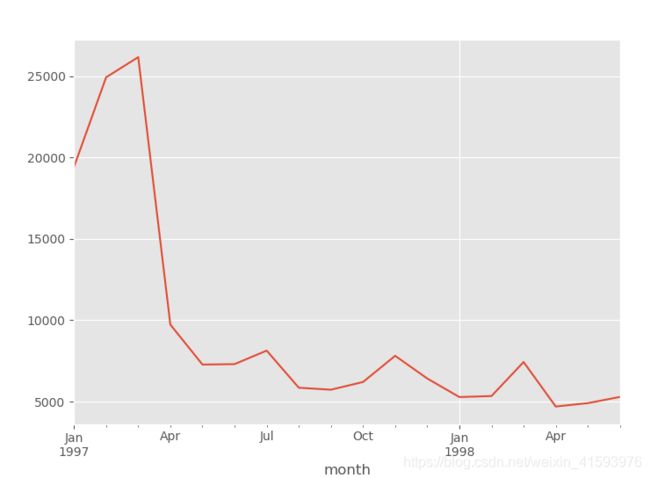
由上图可知,前三个月产品购买量逐步上升,然后急剧下降趋向平稳。我们假设是用户身上出了问题,早期时间段的用户中有异常值,第二假设是各类促销营销,但这里只有消费数据,所以无法判断。
2.4 每月的消费人数
grouped_month=df.groupby('month') #按月分组
grouped_month.user_id.apply(lambda x:len(x.drop_duplicates())).plot() #先对user_id去重,再用len行进行计数,得到人数
plt.show()

由上表可知,前三个月消费人数约在8000-10000人。后续月份消费人数急剧下降,并趋向稳定。
2.5 每月用户的平均消费金额
(order_month_amount/grouped_month.user_id.apply(lambda x : len(x.drop_duplicates()))).plot()
plt.show()
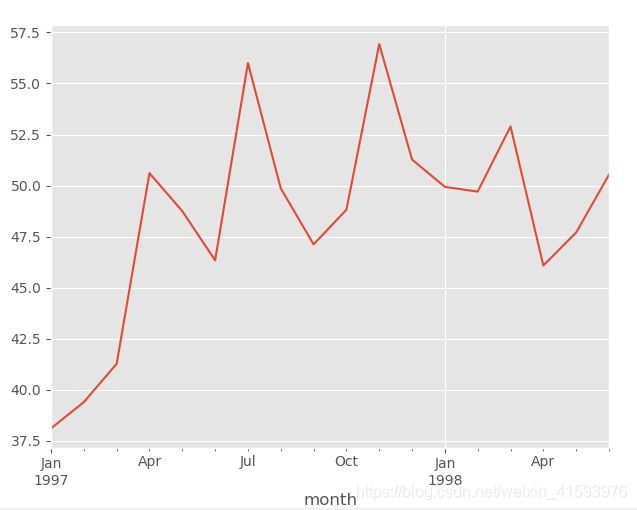
2.6 每月用户的平均消费次数
(grouped_month.user_id.count()/grouped_month.user_id.apply(lambda x : len(x.drop_duplicates()))).plot() #订单数应该用count计数,不能用sum
plt.show()
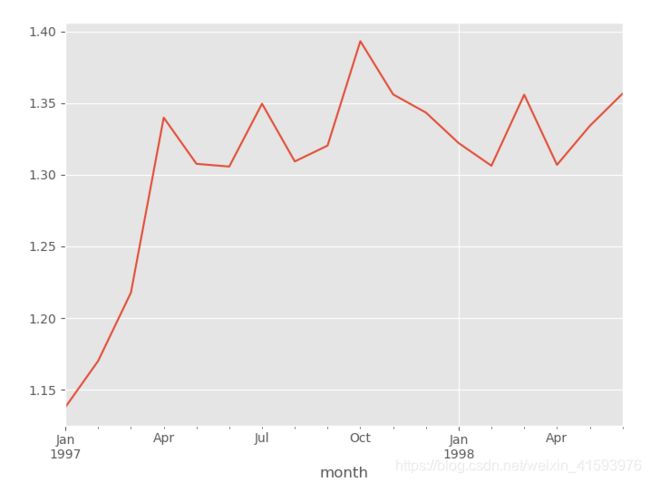
对数据集按月进行数据透视
print(df.pivot_table(index='month',
values=['order_products','order_amount','user_id'],
aggfunc={
'order_products':'sum',
'order_amount':'sum'