2.1 LeNet(霹雳吧啦Wz笔记)
代码链接:
deep-learning-for-image-processing/pytorch_classification/Test1_official_demo at 58cb021d67b8c77ce1d703322e159cd7c6d73b0b · WZMIAOMIAO/deep-learning-for-image-processing (github.com)


model.py
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5) # in_channels, out_channels, kernel_size
self.pool1 = nn.MaxPool2d(2, 2) # kernel_size, stride
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32 * 5 * 5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
代码解读
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5) # in_channels, out_channels, kernel_size
self.pool1 = nn.MaxPool2d(2, 2) # kernel_size, stride
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)结构定义
class LeNet(nn.Module):
定义一个类,继承来自于nn.Module这个父类
def __init__(self):
定义初始化函数
super(LeNet, self).__init__()
解决在多重继承中继承父类方法可能出现的一系列问题,涉及到多继承一般都会使用到这个函数。
self.conv1 = nn.Conv2d(3, 16, 5)
定义第一个卷积层,
第一个参数是输入特征层的深度,因为这里是彩色图片有R、G、B,三个通道,所以通道数量是3.
采用了16个卷积核,所以输出通道是16个,
卷积核的尺寸是5 X 5 的,所以这里是5。
self.pool1 = nn.MaxPool2d(2, 2)
表示使用2×2的池化核进行下采样,步长为2,进行最大池化操作。
正向传播过程
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32 * 5 * 5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x这里的x就是pytorch tensor的通道排列顺序:
如下:
x = F.relu(self.conv1(x))
因为输入的是(3, 32, 32)这样的图片,根据经卷积后的矩阵尺寸大小计算公式:
N = (W − F + 2P ) / S + 1
又,矩阵经卷积操作后的尺寸由以下几个因数决定:
输入图片大小 W×W
Filter大小 F×F
步长 S
padding的像素数 P
(32 - 5 + 0 )/1 +1 = 28
经过这个公式算出来是28,又因为用了16个卷积核,所以输出是16个通道,
所以输出图片的尺寸是(16, 28, 28)
x = self.pool1(x)
此处接受上一个卷积层的输出,即一个大小为(16, 28, 28)的图片,
因为池化层不影响深度,只改变宽高,所以把这个图片的宽高缩小两倍
输出(16, 14, 14)大小的图片。
下一层也是一样,就不重复。
x = x.view(-1, 32 * 5 * 5)
因为全连接需要的数据格式是一维向量,所以这个函数把把大小为(32, 5, 5)的图片,拉成32 * 5 * 5长度的向量。这里的-1代表第一个维度自动推理,也就是那个batch。
进入全连接层:
self.fc1 = nn.Linear(32 * 5 * 5, 120)
因为第一层的节点个数是120,所以这里的参数就是(32 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
因为第二层的输入是第一层的输出,又第一层有120个节点,第二层自己有84个节点,
所以参数是(120, 84)
self.fc3 = nn.Linear(84, 10)
同理这一层的输入是上一层的输出,上一层是84个节点,
又由于我们这里是分十类,所以最后的输出必须是10
所以参数是(84, 10)
参考下图(leNet结构里全连接层各数据表示情况)
这里的n就是32 * 5 * 5,当然我画的是两层的情况,leNet有三层。
不考虑第二层,只把第一层和第三层连接起来,然后输出,
那m就是84,k就是10

为什么这里最后没用softmax函数呢:
因为在训练网络时,在进行计算卷积交叉熵的过程中,在它的内部已经实现了更加高效的softmax方法
如图:

train.py
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
def main():
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=5000,
shuffle=False, num_workers=0)
val_data_iter = iter(val_loader)
val_image, val_label = next(val_data_iter)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(5): # loop over the dataset multiple times
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if step % 500 == 499: # print every 500 mini-batches
with torch.no_grad():
outputs = net(val_image) # [batch, 10]
predict_y = torch.max(outputs, dim=1)[1]
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0
print('Finished Training')
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
# # 简单展示数据集中的图片,随机展示4张图片并输出标签
# def imshow(img):
# # denormalize 反标准化,将图片转化为正常格式
# img = img / 2 + 0.5 # 前面transform部分进行标准化 output = (input=0.5)/0.2;此处为反标准化input=output*o.5+0.5=output/2+0.5
# nping = img.numpy()
# plt.imshow(np.transpose(nping, (1, 2, 0))) # H*W*C,图片原始shape格式
# plt.show()
#
# # print labels
# print(''.join('%5s' % classes[test_label[j]] for j in range(4)))
# # show images
# imshow(torchvision.utils.make_grid(val_image)) # 需要首先将测试数据集的数量改为4,简单读取查看
if __name__ == '__main__':
main()
代码解读
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)第一次使用时要将download设置为True才会自动去下载数据集,并下载在当前目录的data文件夹下,这个文件夹会自动生成。
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])transform这个函数的作用是对图像进行预处理
这个代码的意思是通过Compose方法将中括号内的
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
这两个预处理方法打包成一个整体。
两个方法的作用如下:

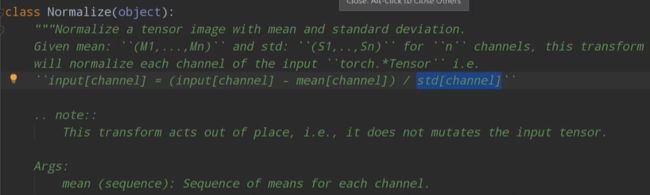
在这行代码中,(0.5, 0.5, 0.5)表示将每个通道的像素值都减去0.5,从而使其均值为0;(0.5, 0.5, 0.5)表示将每个通道的像素值都除以0.5,从而使其标准差为1。因此,这行代码的作用是对输入图像的每个通道进行归一化,使其像素值在[-1,1]之间。
需要注意的是,在进行归一化操作时,需要保证输入图像的像素值为浮点数类型,且范围在[0,1]之间。
为什么说0.5是RGB颜色通道的中间值
RGB颜色空间的范围是[0, 255],其中0表示最暗的颜色(黑色),255表示最亮的颜色(白色),因此颜色通道的中间值应该是(0+255)/2=127.5。在将像素值归一化到[-1,1]之前,如果将像素值除以255,得到的像素值范围就会变成[0,1],此时中间值为0.5。因此,0.5是将像素值归一化到[0,1]范围内时的中间值。
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)这个函数的作用是将前面的训练集导入进来,将它分成一个批次一个批次的形式,这里的batchz_size就是之前的batch.
这里的batch_size=36就是说每一批拿出36张图片进行训练
shuffle=True表示要将数据打乱后再抽取
num_workers=0 表示载入数据的线程数,windows 系统下必须为0,否则报错
下面是chatgpt的回答:
这行代码是针对训练数据集train_set定义了一个数据加载器(Data Loader),用于将训练数据按批次加载到模型中进行训练。具体来说,它的功能有以下几个:
将训练数据集train_set按照batch_size分成若干个小批次,每个小批次包含batch_size个样本;
在每个epoch开始时,将训练数据集打乱(shuffle=True),从而使得每个小批次的样本都是随机选择的;
使用num_workers参数指定加载数据所需的进程数,以加快数据加载速度。
在这行代码中,train_set是训练数据集,batch_size是每个小批次的样本数量,shuffle=True表示每个epoch开始时打乱训练数据集,num_workers是数据加载所需的进程数(这里设置为0,表示不使用多进程)。
值得注意的是,数据加载器中的每个小批次的样本数量通常会影响模型的训练效果。如果batch_size设置过小,每个小批次的样本数量太少,可能会导致模型欠拟合;如果batch_size设置过大,每个小批次的样本数量太多,可能会导致模型过拟合。因此,在进行模型训练时,需要根据实际情况适当调整batch_size的大小。
val_data_iter = iter(val_loader)
val_image, val_label = next(val_data_iter)这些代码是用于从验证数据集val_loader中获取一个小批次的数据用于模型验证的。具体来说,它的功能有以下几个:
使用iter()函数将val_loader转换为一个可迭代的对象val_data_iter;
使用next()函数从val_data_iter中获取下一个小批次的数据;
将获取到的小批次的图像数据val_image和标签数据val_label分别存储到变量中。
在这些代码中,val_loader是验证数据集,它通常由torch.utils.data.DataLoader()函数生成,用于将验证数据集按批次加载到模型中进行验证。val_data_iter是val_loader的一个可迭代对象,它可以通过调用next()函数来逐个获取小批次的数据。val_image是获取到的小批次的图像数据,val_label是获取到的小批次的标签数据。
需要注意的是,在进行模型验证时,通常需要将验证数据集的全部样本都输入到模型中进行验证,并计算模型在验证集上的性能指标。因此,上述代码通常会放在一个循环中,以逐个获取验证数据集中的所有小批次数据,进行模型验证和性能指标计算。
optimizer = optim.Adam(net.parameters(), lr=0.001)这行代码是用于定义优化器(Optimizer)的,用于优化神经网络模型的参数。具体来说,它的功能如下:
使用optim.Adam()函数创建一个Adam优化器对象optimizer;
将神经网络模型net的参数net.parameters()传递给优化器对象optimizer,用于优化模型的参数;
设置优化器的学习率(learning rate)为0.001,即在每次迭代中更新参数时的步长大小。
Adam优化器的工作原理如下:
初始化模型参数的梯度值为0;
从训练数据集中随机取出一个batch size的数据,将这些数据输入到神经网络模型中,并计算出模型在这些数据上的输出值;
计算输出值与真实标签之间的误差(即损失函数),并计算出损失函数对模型参数的梯度;
根据梯度和学习率(learning rate)计算出每个参数的更新量,并更新参数值;
重复以上步骤,直至训练集上的损失函数收敛或达到最大迭代次数。
在这些代码中,net是神经网络模型,它通常由torch.nn.Module()类定义。Adam优化器是一种基于梯度的优化器,通常用于神经网络的训练。在每次迭代中,Adam优化器使用当前的梯度信息来更新神经网络模型的参数,使得损失函数值最小化。学习率是优化器中的一个重要参数,它决定了每次参数更新的步长大小。通常需要根据实际情况适当调整学习率的大小,以获得最佳的模型训练效果。
for epoch in range(5): # loop over the dataset multiple times
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if step % 500 == 499: # print every 500 mini-batches
with torch.no_grad():
outputs = net(val_image) # [batch, 10]
predict_y = torch.max(outputs, dim=1)[1]
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0这些代码是用于训练和验证神经网络模型的。具体来说,它的功能有以下几个:
使用一个外层循环来控制训练的epoch数,即将整个训练集遍历多次;
在每个epoch开始时,初始化训练损失running_loss为0;
使用for循环遍历训练数据集train_loader,每次获取一个小批次的数据inputs和标签labels;
将优化器optimizer中的参数梯度清零optimizer.zero_grad(),避免上一次迭代的残余梯度对本次迭代造成影响;
将小批次数据inputs输入到神经网络模型net中,得到模型在小批次数据上的输出outputs;
使用损失函数loss_function计算模型在小批次数据上的损失loss;
使用反向传播算法计算损失关于模型参数的梯度loss.backward(),并使用优化器optimizer更新模型参数optimizer.step();
计算训练损失running_loss,用于后续的训练过程可视化;
在每个epoch的末尾,对验证集进行评估,计算模型在验证集上的准确率accuracy,并打印出当前epoch和训练过程中的训练损失与测试准确度。
在这些代码中,epoch是训练的轮数,train_loader是训练数据集的数据加载器,val_image和val_label是验证集的图像数据和标签数据。running_loss是训练过程中的训练损失,step是当前小批次的编号。accuracy是模型在验证集上的准确率,val_label.size(0)表示验证集的样本数量。
这里面的 loss.backward() 的作用
在神经网络模型的训练过程中,需要通过反向传播算法计算损失函数对模型参数的梯度,从而使用优化器来更新模型参数。这就是loss.backward()函数的作用所在。具体来说,它的功能有以下几个:
计算当前小批次数据上的损失函数loss关于神经网络模型中每个可训练参数(如权重和偏置)的梯度;
将计算得到的梯度存储在各个参数的.grad属性中;
计算完成后,可以使用优化器的step()函数来更新模型中的参数。
需要注意的是,反向传播算法是一个基于链式法则的求导过程,它将当前计算节点的梯度向前传递直至输入节点,从而计算出各个参数的梯度。在PyTorch中,可以通过调用loss.backward()函数来自动计算梯度,避免手动计算梯度的繁琐过程。
loss.backward()
optimizer.step()
这两行代码的作用机理就是,前者算出当前损失下的梯度,后者根据前者算出的梯度更新得到一个新的参数,然后根据这两个参数对应的loss值来决定怎么更新参数,即取当前的权重还是取更新后的权重。
running_loss += loss.item()这行代码是用于计算训练过程中的训练损失的。具体来说,它的功能有以下几个:
将当前小批次数据上的损失loss使用loss.item()函数转换为一个标量值,存储在变量loss_value中;
将loss_value加到训练损失running_loss中;
在训练过程中,running_loss记录了所有小批次数据的损失之和,用于后续的训练过程可视化。
在这些代码中,loss是神经网络模型在当前小批次数据上的损失函数值,它通常由损失函数(如交叉熵损失函数)计算得到。loss.item()函数将损失值转换为一个标量值,可以方便地进行后续的计算和处理。running_loss是一个累计变量,它记录了训练过程中所有小批次数据的损失之和,用于评估模型的训练效果。
with torch.no_grad():
outputs = net(val_image) # [batch, 10]
predict_y = torch.max(outputs, dim=1)[1]
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0dim=1指定沿着第1个维度(即列维度)进行最大值的查找,这样就可以得到每个输出向量中的最大值和对应的类别索引;
[1]表示取得每个最大值对应的类别索引,即输出矩阵outputs中每行最大值所在的列索引,得到一个一维张量predict_y。
这些代码是用于在模型训练过程中对模型在验证集上的性能进行评估的。具体来说,它的功能有以下几个:
使用torch.no_grad()语句创建一个上下文管理器,该上下文管理器可以禁用PyTorch自动求导机制,从而避免在评估模型时浪费内存和计算资源;因为这里的测试集数据一般都会非常大,这里的batch sieze 是5000:

如果不用with torch.no_grad():
那么就会自动取求这些数据的梯度,要知道我们训练集每个batch size是36.
将验证集的图像数据val_image输入到神经网络模型net中,得到模型在验证集上的输出outputs(每个输出都是一个10维向量,表示对应样本属于10个类别的概率);
使用torch.max()函数计算每个输出向量中的最大值以及对应的类别索引,得到模型对验证集上每个样本的预测值predict_y;
使用torch.eq()函数计算预测值predict_y与验证集标签val_label之间的匹配情况,得到正确预测的样本数量;
将正确预测的样本数量除以验证集的样本数量val_label.size(0),得到模型在验证集上的准确率accuracy。
在这些代码中,val_image是验证集的图像数据,val_label是验证集的标签数据。net是神经网络模型,outputs是模型在验证集上的输出,predict_y是模型对验证集上每个样本的预测值,accuracy是模型在验证集上的准确率。通过对模型在验证集上的性能进行评估,可以及时发现模型的过拟合和欠拟合等问题,从而调整模型的超参数和结构,提高模型的泛化能力。
predict.py
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
def main():
transform = transforms.Compose(
[transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
net.load_state_dict(torch.load('Lenet.pth'))
im = Image.open('1.jpg')
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # [N, C, H, W]
with torch.no_grad():
outputs = net(im)
predict = torch.max(outputs, dim=1)[1].numpy()
print(classes[int(predict)])
if __name__ == '__main__':
main()代码解读
import torch: 导入PyTorch库,一个用于深度学习的开源库。
import torchvision.transforms as transforms: 从torchvision库中导入transforms模块,用于对图像进行预处理。
from PIL import Image: 从PIL库中导入Image类,用于处理图像。
from model import LeNet: 从model模块中导入LeNet类,这是一个预先定义好的LeNet模型。
def main():: 定义主函数main。
transform = transforms.Compose([...]): 定义一个图像预处理的组合操作,包括:调整图像大小为32x32,将图像转换为张量,对图像进行归一化处理。
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'): 定义一个元组,包含10个类别的名称。
net = LeNet(): 创建一个LeNet模型实例。
net.load_state_dict(torch.load('Lenet.pth')): 加载预训练的模型权重。
im = Image.open('1.jpg'): 使用PIL库打开一张名为'1.jpg'的图像。但通过PIL打开的图片其格式一般是[ H, W ,C ]
im = transform(im): 对图像进行预处理。即把[ H, W ,C ]转换成[C, H, W]格式。
im = torch.unsqueeze(im, dim=0): 在图像张量的第0维(批量维度)上增加一个维度,就是转换成标准的pytorch tensor的格式,以便将其作为一个批量输入到模型中。
with torch.no_grad():: 使用torch.no_grad()上下文管理器,表示在接下来的代码块中,不需要计算梯度。
outputs = net(im): 将预处理后的图像输入到LeNet模型中,得到输出结果。
predict = torch.max(outputs, dim=1)[1].numpy(): 找到输出结果中概率最大的类别索引。
print(classes[int(predict)]): 根据索引在classes元组中找到对应的类别名称,并打印出来。
net.load_state_dict(torch.load('Lenet.pth'))torch.load('Lenet.pth'): 使用PyTorch的torch.load()函数从文件Lenet.pth中加载预训练的模型权重。这个文件通常是通过torch.save()函数保存的,包含了模型的参数(权重和偏置等)。Lenet.pth文件应该位于当前工作目录或者指定的文件路径下。
net.load_state_dict(...): 调用LeNet模型实例(net)的load_state_dict()方法,将加载到的预训练模型权重应用到当前模型实例上。load_state_dict()方法接受一个字典作为参数,该字典包含了模型的各个层的参数(权重和偏置等)。
im = Image.open('1.jpg')
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # [N, C, H, W]im = Image.open('1.jpg'): 使用PIL库的Image.open()函数打开名为'1.jpg'的图像文件,并将其赋值给变量im。这里,im是一个PIL图像对象。
im = transform(im): 对图像im进行预处理。transform是一个由torchvision.transforms.Compose()创建的预处理操作组合,包括调整图像大小为32x32,将图像转换为张量,以及对图像进行归一化处理。这些预处理操作是为了将图像转换为LeNet模型所期望的输入格式。经过预处理后,im变为一个形状为[C, H, W]的PyTorch张量,其中C表示通道数(颜色通道),H表示图像高度,W表示图像宽度。
im = torch.unsqueeze(im, dim=0): 使用PyTorch的torch.unsqueeze()函数在图像张量的第0维(批量维度)上增加一个维度。这是因为LeNet模型期望输入的张量形状为[N, C, H, W],其中N表示批量大小。通过在第0维上增加一个维度,我们将单张图像转换为一个包含1张图像的批量,以便将其输入到模型中。
这三行代码的工作原理是:首先打开一张图像,然后对其进行预处理,将其转换为LeNet模型所期望的输入格式,最后将单张图像转换为一个批量,以便将其输入到模型中进行分类。
pytorch tensor的通道排序
N:批量大小(Batch size),表示一批次中包含的样本数量。
C:通道数(Channel),表示图像的颜色通道(例如,对于彩色图像,通常有3个通道:红、绿、蓝)。
H:图像高度(Height),表示图像在垂直方向上的像素数量。
W:图像宽度(Width),表示图像在水平方向上的像素数量。
例如,一个形状为(64, 3, 32, 32)的张量表示一批次包含64张3通道(RGB)的32x32像素大小的图像。
一些小技巧
按住Ctrl键再左键函数名,
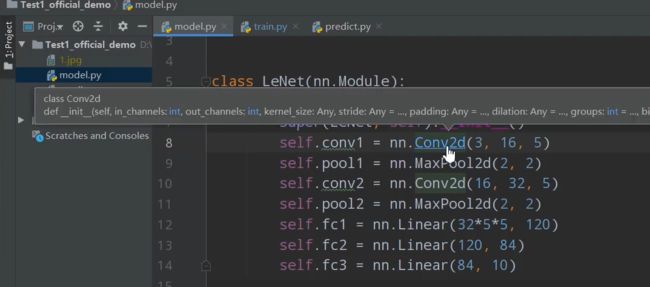
进入函数定义:

参数定义:

复制函数名到去官方查看官方文档