怎么通过UI自动化方式获取文章信息?
出于学习研究,对某账号的文章、视频分析一翻,尝试使用自动化方式看能否获取相应信息。
获取某号的文章有多重方法:
第一种是通过搜狗浏览器搜索账号(这种方式每天只能获取一篇文章,基本上没啥用。):

第二种方式需要自己注册一个订阅号,注册账号有限制:
1、同一个邮箱只能申请1个账号;
2、同一个手机号码可绑定5个账号;
3、同一身份证注册个人类型账号数量上限为1个;
4、同一企业、个体工商户、其他组织资料注册账号数量上限为2个;
5、同一政府、媒体类型可注册和认证50个账号;
6、同一境外主体注册账号数量上限为1个。
意思是一个人只能注册一个号体,申请一个媒体或政府可以有50个,研究学习的话,一个够用了。
注册流程就不说了,注册登录好后,点击“草稿箱”—>‘写新图文’—>点击顶部的‘超链接’ -->账号处点击‘选择其他账号’—>输入需要获取文章的账号名称,点击查询,这时候可以看到,会把该账号的所有文章都获取到:

比如我们查询“央视网”,文章会按照发布日期倒序显示,这就是我们要获取的数据。我们自动化操作也就模拟到这个地方,剩下的就分析接口就行:
通过请求分析,获取文章的请求为:
https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=35&count=5&fakeid=MTI0MDU3NDYwMQ==&type=9&query=&token=441171486&lang=zh_CN&f=json&ajax=1
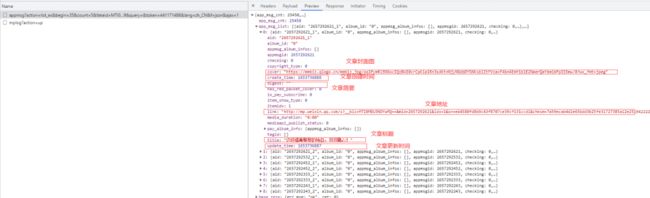
接口返回数据很全,基本想要的数据都有了。
我们要做的事:
1.自动化模拟用户操作到当前动作,再获取请求连接,分析请求数据
2.直接调用这个接口获取数据,那么就要构造这个接口的请求参数,比如账号的id,cookie等,登录维护等。
比较两种方式,都有相应的好处,自动化只要登录后,输入账号名称即可,调用接口的话,不同的账号需要事先维护相应id等,直接调用接口更容易被封。
目前研究到的封禁规则为:每个号体可以调用接口60次,到了60次会被封禁1个小时,换IP也没用,1个小时候可以继续,多次被封禁后,封禁时间会变长,最长为24小时。
有人说,不调用接口,自动化后怎么获取这些请求?有两种方式:
安装mitmproxy,相比Charles、fiddler的优点在于,它可以命令行方式或脚本的方式进行mock
mitmproxy不仅可以像Charles那样抓包,还可以对请求数据进行二次开发,进入高度二次定制
大家可以先查看下官网的相关文档
mitmproxy 官网:https://www.mitmproxy.org/
mitmproxy很强大,但这个地方我们倒用不着。
1.seleniumwire
Selenium Wire 扩展了Selenium 的Python 绑定,让您可以访问浏览器发出的底层请求。您编写代码的方式与编写 Selenium 的方式相同,但您会获得额外的 API 来检查请求和响应并动态更改它们。mitmproxy 官网:
https://github.com/wkeeling/selenium-wire
Pure Python, user-friendly API
HTTP and HTTPS requests captured
Intercept requests and responses
Modify headers, parameters, body content on the fly
Capture websocket messages
HAR format supported
Proxy server support
seleniumwire 就完全够我们使用了。
知道怎么做后,我们梳理一下我们需要准备什么东西:
1.环境安装
(1)python环境(略)
(2)chromedriver驱动下载:
http://chromedriver.storage.googleapis.com/index.html
(3)mysql环境(略)
2.数据库设计
(1)weichat_news:新闻主表
CREATE TABLE `weichat_news` (
`id` int NOT NULL AUTO_INCREMENT,
`news_title` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '文章名称',
`news_cover` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '文章封面图',
`news_digest` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '文章简要',
`news_content_link` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '文章内容连接',
`account_id` int NOT NULL COMMENT '微信账号id',
`weichat_name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '微信账号名称',
`news_create_time` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '文章创建时间',
`news_update_time` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '文章更新时间',
`update_time` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '更新时间',
`insert_time` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '文章插入时间',
`is_video` int NOT NULL DEFAULT '0' COMMENT '是否执行video扫描',
`have_video` int NOT NULL DEFAULT '0' COMMENT '是否含有视频',
`is_content` int NOT NULL DEFAULT '0' COMMENT '是否获取内容',
`is_push` int DEFAULT '0',
`is_delete` int NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `title` (`news_title`) USING BTREE,
KEY `link` (`news_content_link`) USING BTREE,
KEY `idx_account_id` (`account_id`) USING BTREE,
KEY `idx_1` (`have_video`,`is_delete`,`is_push`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='文章';
(2)weichat_account:需要获取的账号表
CREATE TABLE `weichat_account` (
`id` int NOT NULL AUTO_INCREMENT,
`account` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '账号名称',
`collection_id` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`is_delete` int DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='账号';
(3)run_account:账号执行情况表
CREATE TABLE `run_account` (
`id` int NOT NULL AUTO_INCREMENT,
`account_id` int NOT NULL COMMENT '账号id',
`account` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '账号名称',
`patch` int DEFAULT NULL,
`run_time` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '执行时间',
`is_delete` int DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='执行情况';
(4)news_video:视频表
CREATE TABLE `news_video` (
`id` int NOT NULL AUTO_INCREMENT,
`news_id` int NOT NULL COMMENT '文章id',
`news_title` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '文章名称',
`account_id` int NOT NULL COMMENT '公众id',
`account` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '账号名称',
`original_url` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '原视频url',
`cover` varchar(300) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`vid` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`width` int NOT NULL COMMENT '视频宽度',
`height` int NOT NULL COMMENT '视频高度',
`video_quality_level` int NOT NULL COMMENT '视频级别',
`video_quality_wording` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '清晰度',
`qiniu_url` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '七牛转存url',
`insert_time` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '插入时间',
`is_delete` int DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='视频';
(5)news_content:新闻内容表
CREATE TABLE `news_content` (
`id` int NOT NULL AUTO_INCREMENT,
`news_id` int NOT NULL,
`news_title` varchar(100) CHARACTER SET utf8mb3 COLLATE utf8_general_ci DEFAULT NULL,
`content` longtext CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci,
`insert_time` datetime DEFAULT NULL,
`source` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`is_delete` int DEFAULT '0',
PRIMARY KEY (`id`),
UNIQUE KEY `news_id` (`news_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='文章详情表';
(6)account_token:用于存储账号后台的表
CREATE TABLE `account_token` (
`id` int NOT NULL AUTO_INCREMENT,
`account` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '账号名称',
`token` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '登录token',
`update_time` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 'token更新时间',
`freq_control_time` datetime DEFAULT NULL,
`is_delete` int DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='采集所用账号token';
3. 分模块设计
(1)通过自动化获取基础文章信息,比如:封面图,文章访问连接,文章时间等
(2)自动化打开文章连接获取该文章含有视频的地址,文章详情中的视频有两类:
A. 文章详情普通视频,一般可以直接分析请求下载到(如下文章详情中比较中规中矩的视频):

B.文章详情插入的TX视频,该格式是m3u8格式,需要下载ts文件合成mp4,如果是TX视频,自动化时候首先要去点击一下播放按钮,不然获取不到m3u8地址:

两种视频处理方式不一样,我的处理思路是:所有文章都拿连接去自动化,用selenium的显示等待方式,如果发现视频按钮,就去点击一下,然后获取所有的请求数据后续分析。
(3)直接请求原文章地址,通过bs4、lxml解析内容
A. 去除不需要的格式
B. 图片转存七牛 (转存后替换原内容中图片)
C. 提取原视频标签(后边视频下载转存七牛并转码后需要替换这里)
D. 提取其他标签,比如新闻来源、编辑、记者等字段
(4) 既然账号有封禁,可以考虑加入过个账号,一旦账号被封禁,则退出当前账号,用新的账号登录,把登录二维码发送到钉钉供扫码
A. 自动化时,账号被封禁了查询文章时没有数据,接口返回也是有提示“freq control”
B. 当账号被封禁时,往表中插入一条记录,并更新封禁时间,取账号时,判断封禁时间大于1小时才取。
C. 其实用那个账号取决于用手机扫描的是谁,浏览器有登录缓存的,账号没被封禁前,我们一直用的浏览器缓存,这样自动化时候,我们就不用每次去扫二维码了,后边会讲。
D. 需要登录时,把二维码截图发到钉钉群,这里页面自动化等待时间可以设置长一点,比如10分钟。
主要模块分类:

部分代码分享:
1 获取文章主方法:
def get_news_main():
"""
获取文章
:return:
"""
# 查询需要的号
wei_account = read_sql.deal_mysql("get_account.sql")
max_patch = read_sql.deal_mysql("get_max_patch.sql")[0][0]
if max_patch is None:
max_patch = 1
else:
if len(wei_account) == 0:
max_patch = max_patch + 1
wei_account = read_sql.deal_mysql("get_account_all.sql")
for i in wei_account:
# now() > DATE_ADD(freq_control_time, INTERVAL 1 HOUR) // 这里获取没有被封禁的账号继续执行任务
crawl_account_l = read_sql.deal_mysql("get_account_token.sql")
if crawl_account_l:
# 随机取一个用于爬取的账号
crawl = random.randrange(len(crawl_account_l))
# 所用来爬取账号的id
crawl_account_id = crawl_account_l[crawl][0]
# 所用来爬取账号的账号
crawl_account = crawl_account_l[crawl][1]
# # 所用来爬取账号的登录token
crawl_token = crawl_account_l[crawl][2]
# 待爬取的账号id
account_id = i[0]
# 待爬取的账号名称
account_name = i[1]
# 需要爬取的页数 //为1爬取两页,0开始
page = 0
# 自动化操作路径
driver = news.get_news(crawl_token, account_name, page, crawl_account_id, crawl_account)
try:
time.sleep(1)
# 获取文章数据
news_data, freq = analyze_news.analyze_news(driver)
# 数据插入数据库
in_news.insert_news(account_id, account_name, news_data)
# 获取了的账号存入run_account表
in_run.insert_run_account(account_id, account_name, max_patch)
# 如果账号被封禁则更新被禁时间,并退出当前账号
if freq is True:
ua.update_account_token_freq(crawl_account_id)
# 被封禁的账号退出登录
driver = lg.login_out(driver)
except Exception as e:
print(e)
finally:
driver.quit()
else:
print('账号封禁中,暂不能执行任务!!')
break
(1)自动化获取方法
# -*- coding = utf-8 -*-
# ------------------------------
# @time: 2022/5/5 17:11
# @Author: drew_gg
# @File: get_wei_chat_news.py
# @Software: wei_chat_news
# ------------------------------
import os
import time
import random
import configparser
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from get_news import get_login_token as gt
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
pl = os.getcwd().split('wei_chat_news')
# chromedriver地址
driver_path = pl[0] + "wei_chat_news\\charomedriver\\chromedriver.exe"
# 主配置文件地址
config_path = pl[0] + "wei_chat_news\\common_config\\main_config.ini"
config = configparser.ConfigParser()
config.read(config_path)
def get_news(token, account_name, page_num, crawl_account_id, crawl_account):
"""
获取新闻
:param token: 登录后token
:param account_name: 获取文章的账号
:param page_num: 获取文章的页数
:param crawl_account_id: 用于获取的账号id
:param crawl_account: 用于获取的账号
:return:
"""
# ************************************************** #
# 由于微信账号的限制,一个账号只能爬取60页的数据,封禁1小时!!
# ************************************************** #
# seleniumwire:浏览器请求分析插件
# 浏览器缓存文件地址(谷歌浏览器)
profile_directory = r'--user-data-dir=%s' % config.get('wei_chat', 'chromedriver_user_data')
# *******配置自动化参数*********#
options = webdriver.ChromeOptions()
# 加载浏览器缓存
options.add_argument(profile_directory)
# 避免代理跳转错误
options.add_argument('--ignore-certificate-errors-spki-list')
options.add_argument('--ignore-ssl-errors')
options.add_argument('--ignore-ssl-errors')
# 不打开浏览器运行
# options.add_argument("headless")
# *******配置自动化参数*********#
driver = webdriver.Chrome(executable_path=driver_path, options=options)
# 最大化浏览器
driver.maximize_window()
wei_chat_url = config.get('wei_chat', 'wei_chat_url') + token
# 微信账号地址
driver.get(wei_chat_url)
try:
# 点击草稿箱 //如果找不到则认为是没有登录成功
WebDriverWait(driver, 5, 0.2).until(EC.presence_of_element_located((By.XPATH, "//a[@title='草稿箱']"))).click()
except Exception as e:
# 调用扫码登录
driver = gt.get_login_token(driver, wei_chat_url, crawl_account_id, crawl_account)
print(e)
try:
# 点击草稿箱
WebDriverWait(driver, 5, 0.2).until(EC.presence_of_element_located((By.XPATH, "//a[@title='草稿箱']"))).click()
# 点击“新的创作”
WebDriverWait(driver, 5, 0.2).until(EC.presence_of_element_located((By.CLASS_NAME, "weui-desktop-card__icon-add"))).click()
# 点击“写新图文”
WebDriverWait(driver, 5, 0.2).until(EC.presence_of_element_located((By.CLASS_NAME, "icon-svg-editor-appmsg"))).click()
time.sleep(1)
# 切换到新窗口
driver.switch_to.window(driver.window_handles[1])
# 点击“超链接”
WebDriverWait(driver, 5, 0.2).until(EC.presence_of_element_located((By.ID, "js_editor_insertlink"))).click()
# 点击“其他账号”
WebDriverWait(driver, 5, 0.2).until(EC.presence_of_element_located((By.XPATH, "//button[text()='选择其他账号']"))).click()
# 输入“账号名称”
driver.find_element(By.XPATH, value="//input[contains(@placeholder, '微信号')]").send_keys(account_name)
# 回车查询
driver.find_element(By.XPATH, value="//input[contains(@placeholder, '微信号')]").send_keys(Keys.ENTER)
# 点击确认账号
# 吃掉本次异常,不影响后续任务
except Exception as e:
print(e)
try:
e_v = "//*[@class='inner_link_account_nickname'][text()='%s']" % account_name
WebDriverWait(driver, 5, 0.2).until(EC.presence_of_element_located((By.XPATH, e_v))).click()
except Exception as e:
ee = e
print('没有该账号:', account_name)
return driver
for i in range(page_num):
time.sleep(random.randrange(1, 3))
try:
WebDriverWait(driver, 5, 0.2).until(EC.presence_of_element_located((By.XPATH, "//a[text()='下一页']"))).click()
try:
# 暂无数据 //可能该账号没有文章,也可能被封了,直接返回!
no_data_e = "//div[@class='weui-desktop-media-tips weui-desktop-tips'][text()='暂无数据']"
nde = WebDriverWait(driver, 5, 0.2).until(EC.presence_of_element_located((By.XPATH, no_data_e)))
if nde:
return driver
except Exception as e:
ee = e
except Exception as e:
ee = e
return driver
return driver
今天的知识就分享到这里,有问题欢迎留言互动,下一期分享获取视频信息的方式
再次说明:以上仅供分享学习,请不要用于恶意爬虫!!
资源分享
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走…
喜欢软件测试的小伙伴们,如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “点赞” “评论” “收藏” 一 键三连哦!
