数据库 SQL Server 数据表操作 创建表 修改表结构 删除表 索引
文章目录
-
- 1 使用命令方式创建表
- 2 修改表结构
- 2.1 增加字段
- 2.2 修改字段的数据类型
- 2.3 修改表名
- 3 删除表
- 4 表的索引
- 4.1 索引的作用
- 4.2 索引的缺点
- 4.3 索引的分类
- 4.4 创建索引
- 4.5 禁用索引
- 4.6 重新生成索引
- 4.7 删除索引
- 总结
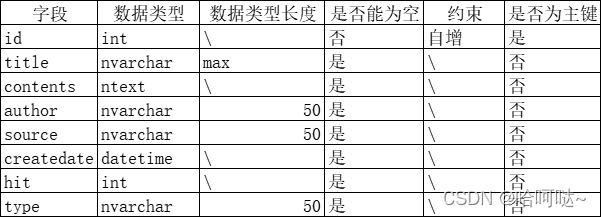
表的定义
表是关系数据库中最重要、最基本、最核心的对象。
表是数据的集合,是用来存储数据和操作数据的逻辑结构。其他数据库对象,如索引、视图等,都是依附于表对象而存在的。
关系数据库的表由行和列组成。行也称为记录、元组,列也称为字段、属性、域。
表的分类
普通表
是存储用户数据的,是最基本、最重要的,其他表是为普通表服务的。
临时表
是临时创建的,可以续存到SQL Server实例断开连接为止。
已分区表
是将数据表水平划分成多个单元的表。这些单元可以分布到数据库的多个文件组里,实现对这些单元数据的并行访问。如果表中的数据量非常庞大,并且这些数据经常被以不同的使用方式来访问,那么建立已分区表是一个有效的选择。
系统表
存储SQL Server服务器的配置、数据库配置、用户和表的描述等信息。一般由DBA使用。
1 使用命令方式创建表
语法格式:
create table 表名(
字段1 字段1数据类型 [primary key] [ identity] null/not null,
字段2,字段2数据类型,null/not null,
…
字段n,字段n数据类型,null/not null,
)
create table news(
id int primary key identity(1,1),
title nvarchar(max) null,
contents ntext null,
author nvarchar(50) null,
source nvarchar(50) null,
createdate datetime null,
hit int null,
type nvarchar(50) null,
)
注:identity(m,n)。从m开始,每次增加n。
例如:identity(2,2),从2开始,每次增加2。即2,4,6,8,10,……,2n。
若identity不加参数则默认为identity(1,1)。
2 修改表结构
2.1 增加字段
语法格式:
alter table 表名 add 添加的字段 字段数据类型
alter table news add num int
2.2 修改字段的数据类型
语法格式:
alter table 表名 alter column 修改的字段 字段数据类型
alter table news alter column title varchar(100)
2.3 修改表名
语法格式:
exec sp_rename ‘旧表名’,‘新表名’
exec sp_rename 'news2','news'
3 删除表
语法格式:
drop table 表名;
drop table news
4 表的索引
索引相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
4.1 索引的作用
快速取数据;保证数据记录的唯一性;实现表与表之间的参照完整性;在使用order by、group by子句进行数据检索时,利用索引可以减少排序和分组时间。
4.2 索引的缺点
索引需要占物理空间;当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度。
4.3 索引的分类
普通索引:使用字段关键字建立的索引,主要是提高查询速度。
唯一索引 (唯一约束自动创建) :字段数据是唯一的,数据内容里面能否为 null,在一张表里面,是可以添加多个唯一索引。
主键索引 (主键约束自动创建):数据记录里面不能有 null,数据内容不能重复,在一张表里面不能有多个主键索引。SQL Server 中,主键默认是聚集索引。一个表只能有一个聚集索引。
聚集索引:聚集索引是指数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同。聚集索引和数据在物理上是按序排列在数据页上的,索引和数据在物理上都是顺序连续的,一旦找到第一个键值的行,后面都将是连在一起,不必在进一步的搜索,避免大范围的扫描,可以提高查询速度。
4.4 创建索引
语法格式:
create index 索引名 on 表名(字段)
create index ix_news_createdate on news(createdate)
4.5 禁用索引
语法格式:
alter index 索引名 on 表名(字段) disable
alter index ix_news_createdate on news disable
4.6 重新生成索引
语法格式:
alter index 索引名 on 表名(字段) rebuild
alter index ix_news_createdate on news rebuild
4.7 删除索引
语法格式:
drop index 索引名 on 表名(字段)
drop index ix_news_createdate on news
总结
create用来创建新对象,包括数据库、表、视图、过程、触发器和函数等常见的数据库对象。
alter用来修改已有对象的结构。根据用途不同,这些对象使用ALTER语句的语法也不同。
drop用于删除已有的对象。有些对象是无法删除的,因为它们是与模式捆绑的。