PyG MessagePassing机制源码分析
PyG MessagePassing机制源码分析

Google在2017发表的论文Neural Message Passing for Quantum Chemistry中提到的Message Passing Neural Networks机制成为了后来图机器学习计算的标准范式实现。
而PyG提供了信息传递(邻居聚合) 操作的框架模型。

其中,
□ \square □表示 可微、排列不变 的函数,比如说sum、mean、max
γ \gamma γ 和 ϕ \phi ϕ 表示 可微 的函数,比如说 MLP
在propagate中,依次会调用message,aggregate,update函数。
其中,
message为公式中 ϕ \phi ϕ 部分,表示特征传递
aggregate为公式中 □ \square □ 部分,表示特征聚合
update为公式中 γ \gamma γ 部分,表示特征更新
MessagePassing类
PyG使用MessagePassing类作为实现 信息传递 机制的基类。我们只需要继承其即可。
下面,我们以GCN为例子
GCN信息传递公式如下:
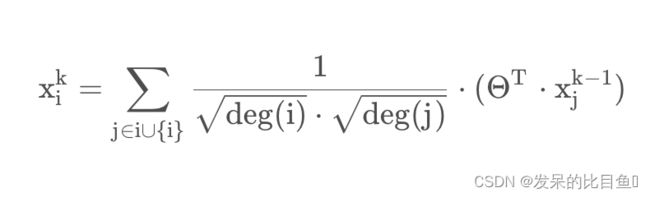
源码分析
一般的图卷积层是通过的forward函数进行调用的,通常的调用顺序如下,那么是如何将自定义的参数kwargs与后续的函数的入参进行对应的呢?(图来源:https://blog.csdn.net/minemine999/article/details/119514944)
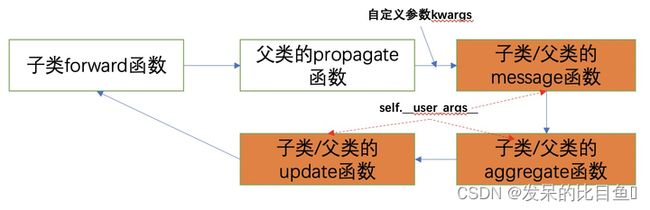
MessagePassing初始化构建了Inspector类, 其主要的作用是对子类中自定义的message,aggregate,message_and_aggregate,以及update函数的参数的提取。
class MessagePassing(torch.nn.Module):
special_args: Set[str] = {
'edge_index', 'adj_t', 'edge_index_i', 'edge_index_j', 'size',
'size_i', 'size_j', 'ptr', 'index', 'dim_size'
}
def __init__(self, aggr: Optional[str] = "add",
flow: str = "source_to_target", node_dim: int = -2,
decomposed_layers: int = 1):
super().__init__()
self.aggr = aggr
assert self.aggr in ['add', 'sum', 'mean', 'min', 'max', 'mul', None]
self.flow = flow
assert self.flow in ['source_to_target', 'target_to_source']
self.node_dim = node_dim
self.decomposed_layers = decomposed_layers
self.inspector = Inspector(self)
self.inspector.inspect(self.message)
self.inspector.inspect(self.aggregate, pop_first=True)
self.inspector.inspect(self.message_and_aggregate, pop_first=True)
self.inspector.inspect(self.update, pop_first=True)
self.inspector.inspect(self.edge_update)
self.__user_args__ = self.inspector.keys(
['message', 'aggregate', 'update']).difference(self.special_args)
self.__fused_user_args__ = self.inspector.keys(
['message_and_aggregate', 'update']).difference(self.special_args)
self.__edge_user_args__ = self.inspector.keys(
['edge_update']).difference(self.special_args)
inspect函数中,inspect.signature(func).parameters, 获取了子类的函数入参,比如当func="message"时,params = inspect.signature(‘message’).parameters就会获得子类自定义message函数的参数,
class Inspector(object):
def __init__(self, base_class: Any):
self.base_class: Any = base_class
self.params: Dict[str, Dict[str, Any]] = {}
def inspect(self, func: Callable,
pop_first: bool = False) -> Dict[str, Any]:
## 注册func函数的入参,并建立func与入参之间的对应关系
params = inspect.signature(func).parameters
params = OrderedDict(params)
if pop_first:
参数的传递过程:
从上图可知,参数是从forward传递进来的,而propagate将参数传递后面到对应的函数中,这部分的参数对应关系主要由MessagePassing类的__collect__函数进行参数收集和数据赋值。
__collect__函数中的args主要对应子类中相关函数(message,aggregate,update等)的自定义参数self.__user_args__,kwargs为子类的forward函数中调用propagate传递进来的参数。
self.__user_args__中_i和_j后缀是非常重要的参数,其中i表示与target节点相关的参数,j表示source节点相关的参数,其图上的指向为j->i for j 属于N(i),后缀不包含_i和_j的参数直接被透传。(默认:self.flow==source_to_target)
def __collect__(self, args, edge_index, size, kwargs):
i, j = (1, 0) if self.flow == 'source_to_target' else (0, 1)
out = {}
for arg in args:# 遍历自定义函数中的参数
if arg[-2:] not in ['_i', '_j']: # 不包含_i和_j的自定义参数直接透传
out[arg] = kwargs.get(arg, Parameter.empty) # 从用户传递进来的kwargs参数中获取值
else:
dim = 0 if arg[-2:] == '_j' else 1 # 注意这里的取值维度
data = kwargs.get(arg[:-2], Parameter.empty) # 取用户传递进来的kwargs前缀arg[:-2]的数据
if isinstance(data, (tuple, list)):
assert len(data) == 2
if isinstance(data[1 - dim], Tensor):
self.__set_size__(size, 1 - dim, data[1 - dim])
data = data[dim]
if isinstance(data, Tensor):
self.__set_size__(size, dim, data)
data = self.__lift__(data, edge_index,
j if arg[-2:] == '_j' else i)
out[arg] = data
if isinstance(edge_index, Tensor):
out['adj_t'] = None
out['edge_index'] = edge_index
out['edge_index_i'] = edge_index[i]
out['edge_index_j'] = edge_index[j]
out['ptr'] = None
elif isinstance(edge_index, SparseTensor):
out['adj_t'] = edge_index
out['edge_index'] = None
out['edge_index_i'] = edge_index.storage.row()
out['edge_index_j'] = edge_index.storage.col()
out['ptr'] = edge_index.storage.rowptr()
out['edge_weight'] = edge_index.storage.value()
out['edge_attr'] = edge_index.storage.value()
out['edge_type'] = edge_index.storage.value()
out['index'] = out['edge_index_i']
out['size'] = size
out['size_i'] = size[1] or size[0]
out['size_j'] = size[0] or size[1]
out['dim_size'] = out['size_i']
return out
propagate中依次从coll_dict中获取与message,aggregate,update函数的参数进行调用。注意这里获取的参数是通过上述的self.inspector.distribute函数进行获取的。
def propagate(self,..):
##...
##...
msg_kwargs = self.inspector.distribute('message', coll_dict)
out = self.message(**msg_kwargs)
##...
##...
aggr_kwargs = self.inspector.distribute('aggregate', coll_dict)
out = self.aggregate(out, **aggr_kwargs)
update_kwargs = self.inspector.distribute('update', coll_dict)
return self.update(out, **update_kwargs)
自定义 message , aggregate , update
def message(self, x_i, x_j, norm):
# x_j ::= x[edge_index[0]] shape = [E, out_channels]
# x_i ::= x[edge_index[1]] shape = [E, out_channels]
print("x_j", x_j.shape, x_j)
print("x_i: ", x_i.shape, x_i)
# norm.view(-1, 1).shape = [E, 1]
# Step 4: Normalize node features.
return norm.view(-1, 1) * x_j
def aggregate(self, inputs: Tensor, index: Tensor,
ptr: Optional[Tensor] = None,
dim_size: Optional[int] = None) -> Tensor:
# 第一个参数不能变化
# index ::= edge_index[1]
# dim_size ::= [number of node]
print("agg_index: ",index)
print("agg_dim_size: ",dim_size)
# Step 5: Aggregate the messages.
# out.shape = [number of node, out_channels]
out = scatter(inputs, index, dim=self.node_dim, dim_size=dim_size)
print("agg_out:",out.shape,out)
return out
def update(self, inputs: Tensor, x_i, x_j) -> Tensor:
# 第一个参数不能变化
# inputs ::= aggregate.out
# Step 6: Return new node embeddings.
print("update_x_i: ",x_i.shape,x_i)
print("update_x_j: ",x_j.shape,x_j)
print("update_inputs: ",inputs.shape, inputs)
return inputs
GCN Demo
from typing import Optional
from torch_scatter import scatter
import torch
import numpy as np
import random
import os
from torch import Tensor
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super().__init__(aggr='add') # "Add" aggregation (Step 5).
self.lin = torch.nn.Linear(in_channels, out_channels)
def forward(self, x, edge_index):
# x has shape [N, in_channels]
# edge_index has shape [2, E]
# Step 1: Add self-loops to the adjacency matrix.
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
# Step 2: Linearly transform node feature matrix.
x = self.lin(x) # x = lin(x)
# Step 3: Compute normalization.
row, col = edge_index # row, col is the [out index] and [in index]
deg = degree(col, x.size(0), dtype=x.dtype) # [in_degree] of each node, deg.shape = [N]
deg_inv_sqrt = deg.pow(-0.5)
deg_inv_sqrt[deg_inv_sqrt == float('inf')] = 0
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col] # deg_inv_sqrt.shape = [E]
# Step 4-6: Start propagating messages.
return self.propagate(edge_index, x=x, norm=norm)
def message(self, x_i, x_j, norm):
# x_j ::= x[edge_index[0]] shape = [E, out_channels]
# x_i ::= x[edge_index[1]] shape = [E, out_channels]
print("x_j", x_j.shape, x_j)
print("x_i: ", x_i.shape, x_i)
# norm.view(-1, 1).shape = [E, 1]
# Step 4: Normalize node features.
return norm.view(-1, 1) * x_j
def aggregate(self, inputs: Tensor, index: Tensor,
ptr: Optional[Tensor] = None,
dim_size: Optional[int] = None) -> Tensor:
# 第一个参数不能变化
# index ::= edge_index[1]
# dim_size ::= [number of node]
print("agg_index: ",index)
print("agg_dim_size: ",dim_size)
# Step 5: Aggregate the messages.
# out.shape = [number of node, out_channels]
out = scatter(inputs, index, dim=self.node_dim, dim_size=dim_size)
print("agg_out:",out.shape,out)
return out
def update(self, inputs: Tensor, x_i, x_j) -> Tensor:
# 第一个参数不能变化
# inputs ::= aggregate.out
# Step 6: Return new node embeddings.
print("update_x_i: ",x_i.shape,x_i)
print("update_x_j: ",x_j.shape,x_j)
print("update_inputs: ",inputs.shape, inputs)
return inputs
def set_seed(seed=1029):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed) # 为了禁止hash随机化,使得实验可复现
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
if __name__ == '__main__':
set_seed(0)
# x.shape = [5, 2]
x = torch.tensor([[1,2], [3,4], [3,5], [4,5], [2,6]], dtype=torch.float)
# edge_index.shape = [2, 6]
edge_index = torch.tensor([[0,1,2,3,1,4], [1,0,3,2,4,1]])
print("num_node: ",x.shape[0])
print("num_edge: ",edge_index.shape[1])
in_channels = x.shape[1]
out_channels = 3
gcn = GCNConv(in_channels, out_channels)
out = gcn(x, edge_index)
print(out)