MySQL优化学习笔记
文章目录
- 前言
- 一、Linux下的MySQL配置
-
- 1.安装mysql
- 2.基础配置
- 3.日志配置
- 4.主从复制
- 二、MySQL架构
- 三、MySQL索引
-
- 1.索引简介
- 2.索引创建原则
- 3.索引失效
- 4.复杂查询、排序和分组优化
- 四、MySQL优化
-
- 1.sql语句执行顺序
- 2.sql性能下降原因
- 3.MySQL性能分析
- 4.SQL优化建议
- 5.show profile分析
- 五、MySQL函数与锁相关内容
-
- 1.创建函数和存储过程
- 2.数据库锁
- 总结
前言
本文记录尚硅谷MySQL数据库高级课程学习笔记,学习内容源自b站。
视频中的测试表和测试数据sql参考另外一位博主的文章链接。
本文仅作为共享的个人笔记,内容章节比较散乱,如有好的建议望指教。
一、Linux下的MySQL配置
1.安装mysql
使用rpm安装mysql
#使用rpm查询系统是否已经安装mysql
rpm -qa|grep -i mysql
#使用rpm安装mysql-server
rpm -ivh MySQL-server-5.5.48-1.linux2.6.x86_64.rpm
#使用rpm安装mysql-client
rpm -ivh MySQL-client-5.5.48-1.linux2.6.x86_64.rpm
#查看mysql的密码配置和用户组,用于判断是否安装成功
cat /etc/passwd|grep mysql
cat /etc/group|grep mysql
#查看版本
mysqladmin --version
2.基础配置
1.安装后的初始配置:
#root用户密码配置(安装后没有默认密码):
/usr/bin/mysqladmin -u root password root
#没有密码的情况下直接使用 mysql 就可以连接服务,配置密码后连接mysql的指令为:
mysql -u root -p
#设置开机自启动:
chkconfig mysql on
#查看mysql自启动配置:
chkconfig --list|grep mysql
2.mysql安装目录:

3.修改默认配置文件和字符集编码:
#进入配置文件目录,拷贝my-huge.cnf到etc目录下:
#注:5.5版本中my-huge.cnf为mysql默认配置文件,5.6版本名字为:my-default.cnf
cd /usr/share/mysql/
cp my-huge.cnf /etc/my.cnf
#使用默认配置插入中文会出现乱码,需要修改默认字符集
#查看字符集配置:
show variables like '%char%';
#在my.cnf中添加默认字符集:
vi /etc/my.cnf
#在[client]下添加:
default-character-set=utf8
#在[mysqld]下添加:
character_set_server=utf8
character_set_client=utf8
collation-server=utf8_general_ci
#在[mysql]下添加:
default-character-set=utf8
4.基础sql语句:
// 创建数据库test11
create database test11;
// 使用数据库test11
use test11;
// 创建表user_test
create table user_test(id int not null, name varchar(20));
// 插入数据
insert into user_test values(1,'z3');
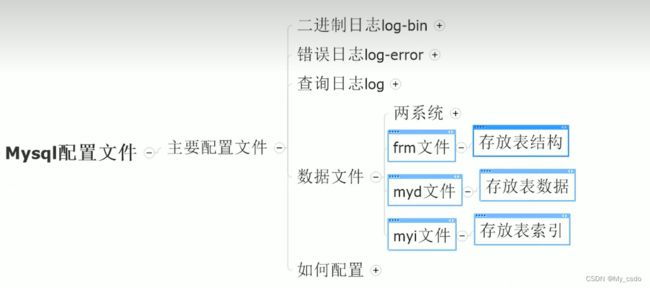
5.mysql主要配置文件:
3.日志配置
1.查询日志
// 想要给数据库加上查询日志,将其保存到 /data/log/mysql/logfile/
// 步骤如下
1.执行shell命令 mkdir -p /data/log/mysql/logfile/
2.编辑 my.cnf 的 [mysqld]节,设置 general_log=1
general_log_file=/data/log/mysql/logfile/general_statement.log
log_output=FILE
3.重启mysql服务;
// 使用命令设置全局查询日志
set global general_log=1;
set global log_output='TABLE';
// 之后可以在mysql库查询到日志
select * from mysql.general_log;
2.慢查询日志:
系统默认不开启慢sql日志,需要手动来设置这个参数。如果不是调优需要的话不建议启用该参数,会影响性能。
// 查看是否开启慢sql日志
show variables like '%slow_query_log%';
// 使用此设置开启慢查询日志只对当前数据库有效,且mysql重启后会失效
set global slow_query_log=1;
// 若永久开启,则在配置文件中的[mysqld]下增加或修改参数,然后重启服务。
slow_query_log=1
slow_query_log_file=/var/lib/mysql/localhost-slow.log
// 默认的慢查询是超过10s,可通过下面查询;注意是大于,不是大于等于。
show variables like '%long_query_time%';
// 修改慢查询阈值,设置后需重连才能看到修改;
set global long_query_time=3;
// 查看有多少慢查询
show global status like '%Slow_queries%';
慢sql日志分析工具mysqldumpslow

分割线--------------------------------------------------------

# 常用的mysqldumpslow指令参考(截图上第一个)
# 得到返回记录集最多的10个sql
mysqldumpslow -s f -t 10 /var/lib/mysql/localhost-slow.log
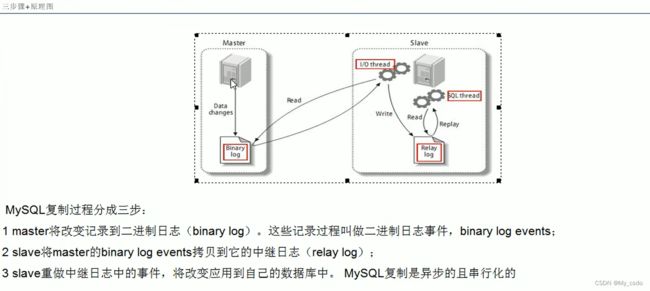
4.主从复制
- 基本原理:slave会从master读取binlog来进行数据同步。
- 步骤和原理:
- 基本原则:每个slave只有一个master;每个slave只能有一个唯一的服务器ID;每个master可以有多个slave;
- 一主一从常用配置:
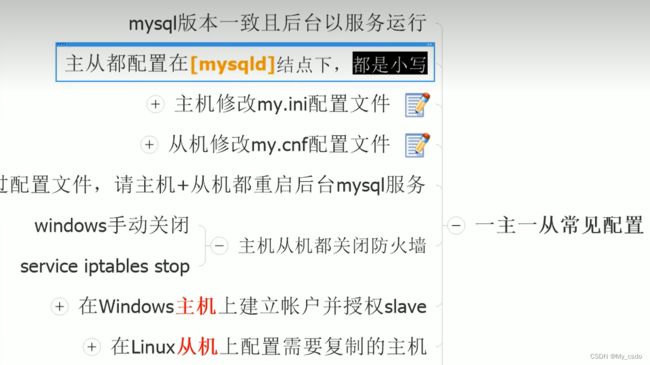
配置内容:
#主机配置
#1.id必须唯一(必须)
server-id=1
#2.启用二进制日志(必须)
log-bin=D:/devSoft/MySQLServer5.5/data/mysqlbin
#3.启用错误日志(可选)
log-err=D:/devSoft/MySQLServer5.5/data/mysqlerr
#4.根目录,临时目录,数据目录(可选)
basedir="D:/devSoft/MySQLServer5.5/"
tmpdir="D:/devSoft/MySQLServer5.5/"
datadir="D:/devSoft/MySQLServer5.5/Data/"
#5.主机读写都可以
read-only=0
#6.设置不需要复制的数据库,需要复制的数据库(可选)
binlog-ignore-db=mysql
binlog-do-db=需要复制的数据库
#从机只需要修改server-id即可
#改完后重启两个机器
#然后主机执行下面指令给从机创建授权用户
GRANT REPLICATION SLAVE ON *.* TO 'zhang3'@'从机ip' IDENTIFIED BY '123456';
flush privileges;
#查看主机状态,记录下File和Position的值
show master status;
#从机执行下面指令
CHANGE MASTER TO MASTER_HOST='主机ip',MASTER_USER='zhang3',MASTER_PASSWORD='123456',MASTER_LOG_FILE='File名字',MASTER_LOG_POS=Position数字;
#启动从机复制
start slave;
#查看从机状态,如果以下两个配置:Slave_IO_Running:Yes 和 SLAVE_SQL_Running:Yes 则主从配置成功
show slave status\G
#停止从服务复制功能
stop slave;
二、MySQL架构
1.mysql分层架构:连接层 -> 服务层 -> 引擎层 -> 存储层:

2.查看mysql存储引擎:
show engines;
// 查看默认存储引擎:
show variables like '%storage_engine%';
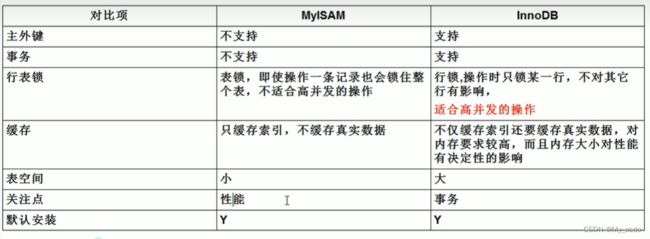
3.常用存储引擎innodb和myisam的区别:
三、MySQL索引
1.索引简介
MySQL官方对索引的定义为:索引是帮助MySQL高效获取数据的数据结构。(可以得出索引的本质是一种数据结构。可以简单理解为:排好序的便于快速查找的数据接结构。所以MySQL索引直接影响到where条件筛选和order by排序)
数据本身之外,数据库还维护着一个满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据结构的基础上实现高级查找算法,这种数据结构就是索引。下图就是一种可能的索引方式示例:
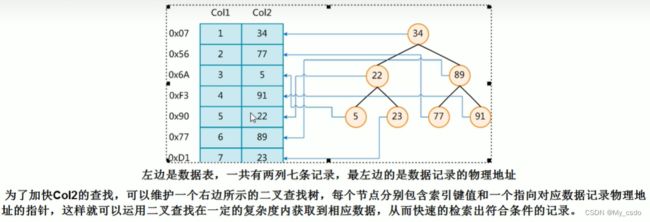
索引的优势: 1.提高数据检索的效率,降低数据库的IO成本;2.索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗;
索引的劣势: 实际上索引也是一张表,该表保存了主健与索引字段,并指向实体表的记录,所以索引列也是要占用空间的。虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化的索引信息。
索引分类: 1.单值索引:即一个索引只包含单个列,一个表可以有多个单列索引;
2.唯一索引:索引列的值必须唯一,允许有空值;
3.复合索引:一个索引包含多个列;
ps:覆盖索引,指查询的字段刚好与复合索引一致,顺序也一样。
基本语法:
-- 创建索引
-- 使用unique为唯一索引,使用index为普通索引。
create [unique] index indexName on mytable(columnName(length));
alter table mytable add [unique] index [indexName] on (columnName(length));
-- 删除索引
drop index [indexName] on mytable;
-- 查看索引
show index from table_name;

2.索引创建原则
1.单表查询创建索引需要注意索引字段最好覆盖select后的字段,这样可以用到覆盖索引;索引字段的范围查询会导致后面的索引失效,所以不建议在范围查询字段上加索引;学习视频中的例子如下:
explain select id,category_id from article where category_id = 1 and comments > 1 order by views desc limit 1;
// 对于上面的查询,下面第一个索引不如第二个
create index idx_article_ccv on article(category_id,comments,views);
create index idx_article_cv on article(category_id,views);
2.两张表连接查询,如果是内连接,索引加在任何一个表的外键上都可以;如果是左连接或者右连接,则加在副表外键上;
select * from book inner join class on book.card = class.card;
// 上面这种情况可以创建以下任意一种索引,两种效果一样
create index book_y on book(card);
create index class_y on class(card);
// 左连接可以在class表上创建card字段的索引
select * from book left join class on book.card = class.card;
// 右连接可以在book表上创建card字段的索引
select * from book right join class on book.card = class.card;
// 如果索引是创建好的不好修改,可以调整表关联的前后顺序比如
// book left join class 改成 class left join book,前提是可以得到同样的结果
为什么左连接查询索引最好建在右表的外键上,解释如下(右连接同理):

3. 三表关联查询优化的结论与上面两张表关联查询结论一致,可以查看四-4结论。
3.索引失效
索引失效的一些情况:

ps:使用 like 模糊查询只有在%在右边的情况下可以使索引生效,其他情况下索引会失效;
4.复杂查询、排序和分组优化
1.in和exists的选择:in是由子查询结果驱动,exists由主查询驱动,优先选择小表驱动大表;

2.使用order by 排序要尽量避免extra中的fileSort(文件排序),排序字段需要使用索引字段,次序也需要和创建组合索引的次序一致,保证最左前缀原则;排序时避免使用select * ,降低io负担也可以避免sortBuffer容量不足导致的查询效率低下;
3.group by 分组也会先排序,所以分组的索引优化逻辑参照排序。 
四、MySQL优化
1.sql语句执行顺序
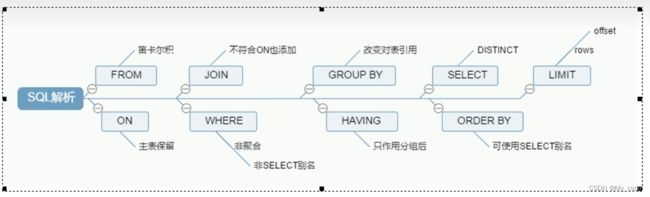
2.sql性能下降原因
服务响应慢时,首先要复现场景,然后定位原因。如果确定是sql的问题,则先分析出问题原因:查询语句写的烂;索引失效;关联查询太多join(设计缺陷,或不得已的需求);服务器调优及各个参数设置(缓冲、线程数等)。
3.MySQL性能分析
mysql常见的性能瓶颈:

explain的作用: 分析表的读取顺序,数据读取操作的操作类型;哪些索引可以使用;哪些索引被实际使用;表之间的引用;每张表有多少行被优化器查询。
explain包含的信息:

字段说明:
1、id:根据id大小可以判断表的查询读取顺序,id越大越先查询;id如果相同,从上往下顺序执行;
2、select_type:查询类型,包含SIMPLE、PRIMARY、SUBQUERY、DERIVED、UNION、UNION RESULT六种取值,主要是区分普通查询,联合查询,子查询等查询类型;

3、type:显示查询使用了哪种访问类型,常用的为以下几种:system>const>eq_ref>ref>range>index>ALL
一般来说至少要达到range级别,最好达到ref。

4、possible_keys:显示可能应用在这张表中的索引,一个或多个。查询涉及到的字段上若存在索引,则该索引列将被列出,但不一定实际使用到。
5、key:实际使用到的索引,如果为null,则没有使用到索引。
6、key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引长度。在不损失精确性的情况下,长度越短越好。key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的。
7、ref:显示索引的哪一列被使用了,哪些列或常量被用于查找索引列上的值。
8、rows:估算出查处结果需要扫描的行数。
9、extra:显示其他额外的重要信息。extra主要信息说明:点击链接
4.SQL优化建议

5.show profile分析
1.show profile简介:是mysql提供可以用来分析当前会话中语句执行的资源消耗情况。可以用于SQL调优的测量。默认情况下,参数处于关闭状态,并保存最近15次的运行结果。
// 查看是否支持show profile分析
show variables like '%profiling%';
// 开启
set profiling=on;
// show profiles可以获取queryID,根据queryID再获取具体的查询执行消耗
show profiles;
show profile cpu,block io for query 1;
2.show profiles分析中需要注意的结果:

五、MySQL函数与锁相关内容
1.创建函数和存储过程
设置log_bin_trust_function_creators(开启慢查询日志后创建函数可能会报错,使用以下方法):

1.创建函数:
// 随机产生字符串(部门名称)
DELIMITER $$
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str = CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END $$
// 用于随机产生部门号
DELIMITER $$
CREATE FUNCTION rand_num() RETURNS INT(5)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(100+RAND()*10);
RETURN i;
END $$
// 删除函数
drop function rand_num;
2.创建存储过程
// 批量插入员工测试数据
DELIMITER $$
CREATE PROCEDURE insert_emp(IN START INT(10), IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO emp(empno,ename,job,mgr,hiredate,sal,comm,deptno) VALUES ((START+i), rand_string(6), 'SALESMAN', 0001,CURDATE(),2000,400,rand_num());
UNTIL i = max_num
END REPEAT;
COMMIT;
END $$
// 调用存储过程
CALL insert_emp(100,10);
2.数据库锁
1.MyISAM引擎,表锁:读锁(共享锁),写锁(排他锁)
针对同一份数据,加了读锁后多个读操作可以同时进行而不会相互影响;同一个session中只能进行读操作,不同session中的写操作会产生阻塞。
加了写锁之后,当前操作没有完成前会阻断其他写锁和读锁。
// 手动增加表锁
lock table table_name read(write), table_name2 read(write), ...;
// 查看哪些表有锁
show open tables;
// 解锁
unlock tables;
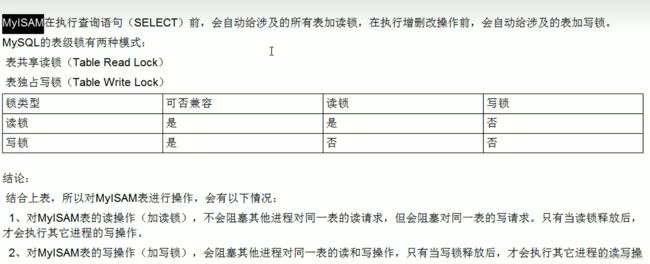
表锁相关参数查看:

2. 行锁,偏向InnoDB引擎,开销大,加锁慢;会出现死锁,锁定力度小,冲突概率最低,并发度也最高。错误的查询条件导致索引失效,全表扫描,会造成行锁变表锁,这样所有其他操作都会被阻塞。
innoDB事务会加行锁;

如何锁定一行:
begin;
select * from test_innodb_lock where a = 8 for update;
// 其他对数据的操作
.....
// 提交释放锁
commit;
行锁分析:
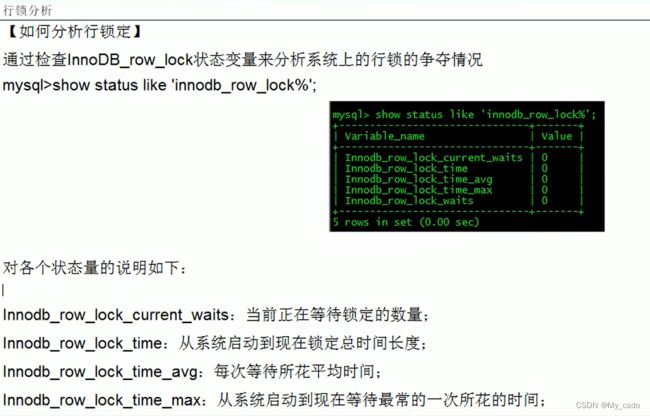
行锁优化建议:
