gns3中两个路由器分别连接主机然后分析ip数据转发报文arp协议_技术盛宴 | IPv6系列应用篇——数据中心IPv4/IPv6双栈架构探讨...
背景
2017年,工业和信息化部发布了《推进互联网协议第六版(IPv6)规模部署行动计划》的通知,从国家层面推动下一代IP技术——IPv6的普及和应用。目标到2020年末,IPv6活跃用户数超过5亿,在互联网用户中的占比超过50%,新增网络地址不再使用私有IPv4地址。这就要求从互联网应用、网络基础设施、应用基础设施和网络安全等各个维度推动IPv6的改造和建设。
互联网业务的IPv6改造不会一蹴而就,这还受限终端及运营商网络的IPv6能力,所以IPv4业务和IPv6业务并存将会持续很长时间。而数据中心作为应用基础设施的重要部分,需要同时支撑IPv4业务和IPv6业务,双栈部署是最重要的技术手段。今天就跟大家聊聊数据中心IPv4/IPv6网络双栈架构的一些实践。双栈部署涉及很多方面,由于受限文章长度,本次主要聚焦IPv6组网下的PXE装机及IPv6服务器双归冗余架构的实现。
在展开具体分析之前,先带大家先回顾IPv6地址分类(含规划建议)和IPv6地址的分配原则,帮助大家更好的理解本文内容。
IPv6地址分类及规划建议
数据中心基础网络主要使用IPv6单播地址,涉及服务器业务地址、服务器管理地址、交换机互联地址、交换机管理地址的分配。
IPv6单播地址可分为全球单播地址、唯一本地地址以及链路本地地址,如下图所示。

▲图一 IPv6单播地址分类
服务器业务地址、服务器管理地址以及 交换机管理地址建议采用唯一本地地址,并使用64位掩码长度。空间大:• 64位掩码空间拥有2,814,749亿个地址空间。
节省交换机硬件表项:• 交换机用于存放表项的硬件资源十分有限;
• 64位掩码的网段路由相比128位掩码的主机路由,需要更小的匹配域(源IP、目的IP),消耗更少的硬件资源。
使用64位掩码的网段也会带来一些小问题,我会在IPv6服务器双归冗余架构章节详细介绍。
交换机互联地址建议使用唯一本地地址。唯一本地地址空间足够大,这个上面已说明;OSPF、BGP等路由协议对链路本地地址的支持还不够成熟。IPv6地址分配原则
如下图所示,IPv6地址分配方式可分为手工配置和自动配置,自动配置又分为有状态地址自动分配(DHCPv6)以及无状态地址自动分配。

▲图二 IPv6地址配置方式
有状态地址分配方式和DHCPv4类似,依赖DHCPv6协议从DHCPv6 Server的地址池中获取可用的IPv6地址,而无状态地址自动配置摆脱了复杂的DHCPv6协议,依赖ND(Neighbor Discovery,邻居发现)协议即可完成地址自动配置。下图是服务器无状态地址自动配置的过程:

▲图三 无状态地址自动配置过程
服务器主动发送RS(Router Solicitation,路由器请求)报文,RS报文的源IP是服务器的Link-local地址,目的IP是组播IP;
交换机收到RS报文后,进行RA(Router Advertisement,路由器公告)报文的封装及发送,源IP是网关的Link-local地址,目的IP是组播IP。需要重点关注的是RA报文的M标志位以及O标志位,M标志位的值为0,服务器才会走无状态地址配置流程;
服务器收到RA报文后,会将RA报文的源IP设置为默认网关,并解析RA报文的M、O标志位,如果M标志位为0则解析RA报文携带的路由前缀内容,接口ID使用EUI-64格式生成。
RA报文中M以及O标志位的具体含义如下:
M:管理地址标志位(Managed Address Configuration)。置0表示无状态地址分配,客户通过无状态协议获取IPv6地址;置1表示有状态地址分配,客户端通过有状态协议(DHCPv6)获取IPv6地址。O:其他状态标志位(Other stateful Configuration)。置0表示客户端通过无状态获取除地址外的其他配置信息;置1表示客户端通过有状态获取其他配置信息(如DNS、SIP服务器等);若M标志位为1,则O标志位也必须为1。相比有状态地址自动配置,无状态地址自动配置的优势如下:
真正的即插即用
主机连接到一个没有DHCP服务器的网络时,无须手动配置地址等参数即可访问网络;
网络迁移方便
当一个站点的网络前缀发生变化时,主机能够方便地进行重新编址而不影响网络连接;
降低网络复杂度
不需要部署独立的DHCPv6服务器,所以简化了网络规划及运维难度;
提高网络可靠性
服务器地址获取不依赖集中的DHCPv6服务器,从而提高整体的可靠性。
IPv6服务器PXE装机方式
在数据中心内部,服务器装机是必不可少的环节,传统的PXE(Preboot Execute Environment,预启动执行环境)装机流程如下:

▲图四 传统PXE装机示意图
整体分两个阶段:
PXE阶段:服务器需要通过DHCP协议获得配置信息,包括IP地址,默认网关以及File Server地址。 安装阶段:服务器请求File Server的软件镜像以及配置信息,下载完成后通过内嵌装机软件,完成系统安装,配置下发等一系列动作。对比IPv4的PXE装机流程,有状态地址自动配置环境下的IPv6服务器装机变得更加复杂。
当然你可以继续沿用现有的IPv4网络对IPv6服务器进行装机,不过考虑到最终要演进到IPv6 only,IPv6装机是必不可少的。下面具体阐述有状态地址自动配置环境下IPv6服务器装机复杂在哪里?

▲图五 IPv6有状态PXE装机
有状态地址自动配置环境下的IPv6 PXE装机也分为两个大阶段:
PXE阶段:服务器需要通过ND(Neighbor Discovery,邻居发现)协议或者DHCPv6协议获取IP地址;通过ND协议完成服务器的“默认网关”配置;通过DHCPv6 完成File Server地址配置。 安装阶段:拿到File Server地址配置后,通过TFTP或者FTP下载镜像以及配置信息,通过内嵌装机软件完成系统安装。IPv6服务器PXE装机的复杂主要体现在需要同时依赖ND协议及DHCPv6的有状态地址自动配置两种技术。
必须依赖ND协议获取默认网关的相关配置 默认网关信息必须依赖ND协议的RA消息:• RA消息的源IP(默认是网关的Link-local地址)是下联服务器的默认网关。
必须通过RA消息中O标志位获取DHCPv6 Server信息。需要依赖DHCPv6服务器获取File Server地址等信息服务器必须向DHCPv6 server获取File server地址以及DNS等信息。从上面的过程不难看出,ND协议是对于IPv6主机是必不可少的组件,所以要降低IPv6服务器PXE装机的复杂度,只能想办法实现去掉DHCPv6协议。
深入分析有状态PXE装机方案,只需要解除通过DHCPv6获取File Server地址配置这一个限制即可。具体就是通过RA+DNS的方式实现,这个方案我们称之为无状态地址装机方案。
定义RA消息的URL Option扩展属性,携带File Server的域名;
主机通过RA消息获得DNS 服务器地址(DNS服务器地址手工配置在交换机);
通过DNS域名解析,获得File Server的地址。
基于无状态地址自动配置的IPv6服务器PXE装机整体流程如下图所示:

▲图六 IPv6无状态PXE方案
服务器发送RS报文请求,交换机应答RA(哑终端则等待设备定期发送RA),服务器根据RA报文完成自动配置,包括:IP地址、默认网关、DNS Server、以及File Server的URL;
服务器获取地址后,发送DAD报文进行地址冲突检测;
服务器发送NS报文请求网关ND,交换机通过NS报文学习服务器ND信息,并发送NA应答;
服务器向DNS Server发送域名解析URL请求,然后从File Server下载bootfile,执行装机。
显然基于无状态地址的IPv6 PXE装机方案去掉了繁重的DHCPv6协议,不需要额外消耗DHCP Server资源,更简单、更轻量,也简化了网络的规划。有状态的DHCPv6装机方案,地址池的计算、管理全部在DHCPv6服务器端,这种方式出错成本很高,即DHCP服务器的地址池维护分配如果出现问题,整个集群的服务器PXE装机都会受影响,而无状态地址装机则更为简单,简单意味着可靠和稳定。
IPv6服务器双归冗余架构
在聊IPv6服务器双归冗余架构之前,我们先看看IDC双栈方案的整体组网架构。

▲图七 IDC双栈方案架构示意图
接入、汇聚、核心交换机之间建立双栈EBGP邻居;
直连端口配置双栈地址,IPv4 的BGP Session承载IPv4路由,IPv6 的BGP session承载IPv6路由;
服务器上行双归到接入交换机,两台接入交换机为一组,接入交换机实现去堆叠方案(类似IPv4下的去堆叠,具体参见【第六期】如何实现数据中心网络架构“去”堆叠。
IPv6服务器双归冗余架构就是IPv6环境下的接入交换机去堆叠,与IPv4下的去堆叠组网目标一致,但是具体细节上又有很多的不同。
广播风暴抑制在IPv6的去堆叠方案中,最重要的是避免广播风暴,需要在接入交换机下联口开启风暴抑制功能;IPv4场景组要指定隔离广播、组播、未知单播报文;IPv6取消广播的概念,只需隔离组播报文。 二层隔离+网关代答IPv4在二层隔离的场景下,同子网内主机的互通采用ARP Proxy方案,即ARP代答,对于主机ARP请求的任何IP地址都应答网关的MAC地址;IPv6在二层隔离的场景下,同子网内主机的互通有两种方案:• 部署ND Proxy来实现代答,类似IPv4的ARP Proxy方案;
• 通过RA消息(L-bit)标识置为0,通告下连地址段前缀为“off-link”,即非直连网段,所有报文的转发都必须通过网关。
ND Proxy方案详解

ND Proxy方案的复杂度在交换机侧,不依赖于服务器的协议栈。
交换机需要实现同网段通信走三层转发。即交换机对服务器发出所有NS请求,都以网关的MAC地址进行应答,并在硬件出方向不转发服务器的NS报文,包括目的服务器和源服务器是同网段。
ND-Proxy网关代答详细流程如下图:
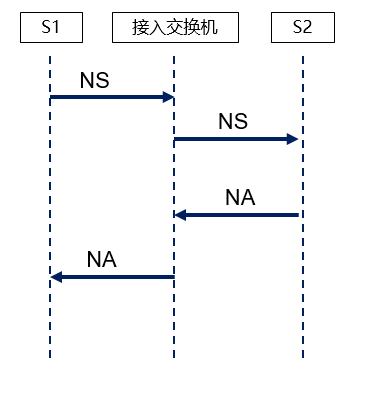
▲图八 ND-proxy代答时序图
服务器S1主动发NS报文来获取服务器S2的MAC地址;
交换机配置了ND Proxy,所以NS报文直接被上送到CPU,判断本机是否存在S2的ND表项,如果存在则直接代答NA报文;
如果不存在S2的ND表项,为了确保S2当前是真实在线的,交换机CPU会主动发源IP是网关IP、目的IP是服务器S2的NS报文;
S2收到NS后应答NA报文,交换机收到S2的NA报文后在本地生成S2的ND表项并代答NA报文给S1;
如果S2发生故障或者不在线,则网关不会代答NA报文给服务器S1,否则会造成黑洞丢包。
设置硬件出方向不转发NS报文的原因是避免ND表项泄露。
这个问题跟IPv4场景的去堆叠场景类似,如果不做出方向ARP报文的抑制会导致ARP泄露,从而导致服务器双挂变单挂的故障场景下,部分业务流会一直断流。

▲图九 Server1双挂变单挂示意图
如上图所示,如果不做ARP或者ND在出方向的抑制,当广播风暴抑制不生效时,S2会学到S1的ARP以及ND记录,则S2发往S1的报文封装的MAC地址是S1的真实MAC地址,而不是网关的MAC地址,当S1发生单上联口故障时,S2到S1走交换机-1的流量会被全部丢弃。
接入交换机硬件出方向应用ARP抑制完全没问题,但是出方向应用NS抑制会带来新问题,即同一台接入交换机下其他服务器无法收到DAD报文,导致DAD(Duplicate Address Detection,重复地址检测)检测失效。为解决此问题,交换机需要实现DAD报文学习ND的功能。流程如下图所示:

▲图十 DAD报文学习ND流程图
当交换机收到DAD报文时,会查看本机是否存在请求目的地址的ND表项;
如果没有则创建ND表项,并把ND状态置为Stale;
如果存在ND表项,则比较DAD报文的源MAC和该ND表项的MAC;
如果MAC不同,则说明检测到重复地址,发送NA报文通知发送端IP地址重复,IP地址不可用。
L-bit网关代答方案详解
基于L-bit的网关代答方案,通过RA报文中携带指定Prefix的off-link属性,使下联主机对与该Prefix同网段的通信请求,必须先经过网关。L-bit方案依赖服务器主机的协议栈行为,不是所有的服务器OS都天然支持。
L-bit网关代答方案的详细原理如下:
交换机上关闭RA抑制功能;
周期性通告RA消息给直连服务器,交换机配置指定前缀的On-link Flag为0;
主机收到RA后,通过解析指定前缀的On-link-flag是否为0;
如果On-link-flag为0,则表示到此前缀的所有流量直接发给默认网关;
服务器同时通过解析RA报文获取默认网关IP,并查询ND表项,发往此前缀的所有流量的目的MAC会被封装成默认网关MAC。
简单对比ND-Proxy以及L-bit这两种网关代答方案:

▲表一 两种网关代答方案优劣对比
显然在服务器OS满足要求的前提下,L-bit方案更好。不过网络无法对业务服务器灌装版本做严格的要求,所以建议采用ND-Proxy方案、L-bit方案同时开启。如果服务器OS支持L-bit能力,则不会走到ND-Proxy的代答流程;如果服务器OS不支持L-bit,交换机的ND-proxy功能可以保证代答转发。
在第一章节讲IPv6地址规划时,我们遗留了一个问题,即采用64位掩码长度网段的问题,其实这也不算是问题,只是在服务器双归部署时,需要进行一些特殊的处理,这就牵扯到一个重要的特性——ND指定前缀转路由。
在理解ND指定前缀转路由概念之前,我们先要讲一下关于去堆叠场景ARP/ND转主机路由的需求。如果一组接入交换机各自发布相同的主机网段路由,那么当其中一台接入交换机与某台主机的上行链路故障时,访问这台主机的流量可能会丢失一半的流量。只有把ARP/ND转成主机路由,面对上面的问题,接入交换机在发现下行连接某个主机的链路故障时,它会快速撤销其对应的主机路由,就不会发生断流问题了。这里面的关键就在于ARP/ND生成的主机路由是如何占用硬件表项的?
IPv4环境:接入交换机会把ARP转成32位长度的主机路由;IPv4主机路由表项是复用ARP硬件表项资源的;所以并没有因为生成主机路由占用双份的资源。 IPv6环境:ND转成的主机路由算是网段路由,占用交换机ALPM表项;ND本身占用的是L3_entry表项;ND转成的主机路由与ND表项不复用;如果直接把ND转成对应128位长度的主机路由,一条128位的主机路由在ALPM硬件资源中需要占用两个表项(210 bit),对于本来就紧张的APLM硬件资源就是极大的浪费。所以,在IPv6服务器双归冗余架构下,为了最大化节约交换机ALPM硬件表项的资源,需要压缩ND转成的主机路由长度,指定ND转成主机路由的前缀长度,这就是ND指定前缀转路由。而64位掩码长度是最优的选择,因为64位掩码长度的网络路由在ALPM硬件资源中只占用一条表项(105 bit)。这也就是在第一章讲IPv6地址规划时,为什么建议采用64位掩码长度的原因。
下面我们举个例子来说明。
假设终端的IPv6地址为fc00:1:1010:35::1124,按照统一的64位网段规划,接入交换机学到ND后转fc00:1:1010:35::1124/64网络路由,按照下联48台服务器,每台服务器1虚30的能力来计算,直连ND表项的数量为48*30 = 1440个,只占ALPM表容量的1%左右(以Broadcom Trident3估算),假设一个POD有30组接入交换机,那么每台接入交换机上从网络学到ND转成64位掩码长度的网络路由会占用了29 * 1% = 29%的ALPM硬件资源,设想下,如果不压缩ND转成的主机路由长度,那么从网络学到的128位主机路由就会很轻易的用掉58%的ALPM硬件资源。
总 结
本文重点针对IPv4/IPv6双栈环境下的地址规划、PXE装机及服务器双归部署进行了简单的讨论。总结起来,因为IPv6相关协议及地址长度的变化,再叠加原有的IPv4,IPv4/IPv6双栈架构对网络运维、网络安全,以及交换机硬件表项都带来不小的挑战,部署双栈后如何应对这些挑战,后面会继续跟大家分享。
附专业术语解释:

本期作者:陈冬林
锐捷网络互联网系统部行业咨询
往期精彩回顾▌ 【第二十期】IPv6系列基础篇(上)——地址与报文格式
▌ 【第二十一期】IPv6系列基础篇(下)——邻居发现协议NDP
▌ 【第二十二期】IPv6系列安全篇——SAVI技术解析
▌ 【第二十三期】IPv6系列安全篇——园区网IPv6的接入安全策略
【技术盛宴】专栏
锐捷网络自2018年起精心打造《技术盛宴》专栏,围绕热点技术、行业趋势定期分享网络通信领域的技术干货。
从前沿理论到应用实践,从知识科普到深度解析,为您带来网络技术的饕餮盛宴。
点击“阅读原文”,了解更多互联网行业解决方案