【SQLite3】使用 SQLite 为模型训练中的并行 dataloader 节省内存
0x00 前言
我的训练数据读到内存里就有好几个 G 那么大了,
多进程 dataloader 跑并行训练的时候内存都被打满了怎么办啊?!
解决方案: 基于 SQLite 无限数量的并行读取做一个 dataset 呗
在做模型并行化训练的时候,我们通常会做多个 dataloader 为 一张卡提供数据预处理,如果数据处理速度是瓶颈时,单张卡所需的 dataloader 也会更多。
当卡数再提升起来,一次训练所需要的 dataloader 数量将呈线性增长。
这里就会有个问题:
—— 内存不够用了
比如 dataloader 有 128 个,那比起单卡单 dataloader 而言内存消耗就是 128 倍。
—— 他们用的数据不能放同一块内存一起读嘛?
多个进程读同台机器上同一块内存,要用我之前实现过的 SMQueue 倒是可以解决,但都要基于C语言来定制化了,不觉得麻烦嘛?
唉?数据恒定,无限读取。让他们读数据库不就完事了吗?
0x01 原理介绍
我们知道,多进程的时候相当于每个进程会 fork 一下主要函数,
并且 复制 一份里面的资源和计算流程去开一个新进程来计算。
dataloader 们在训练时其实是这样的流程:
- 主进程 main 从文件中读取完整数据 N 条
- 子进程们 sub1, sub2, sub3, … 把这 N 条都复制了之后带走
- 每个子进程,例如 sub1 可以根据任意下标获取所需 id 对应的样本
- 为 GPU0 工作的 s u b 1 , s u b 2 , . . . s u b k sub_1, sub_2, ... sub_k sub1,sub2,...subk 会从这 N 条中选择 M 条;为 GPU1 工作的 s u b k + 1 , s u b k + 2 , . . . s u b 2 k sub_{k+1}, sub_{k+2}, ... sub_{2k} subk+1,subk+2,...sub2k 从这 N N N 条中选择 M M M 条,所有的子进程加在一起把 N N N 条样本遍历完 (ddp mode,K 为每个 GPU 需要由多少 dataloader 供应)。
- 内存占用为 N 条数据 × \times × GPU 数量 × \times × K
简而言之,第一个 dataset 被读入内存后,所有的 dataloader 实际复制了 K 份去了。
先说说其它方法把,比如目前一个常用的解法是 分割数据
分割数据的方法:将数据根据 GPU 数量均分为几份,每个 GPU 的 dataloaders 读对应 GPU 编号的那份数据
这样在上述流程中的第 2 步中,每一份被复制的基本单元从完整数据的 N 条,变成了原来的几分之一。
这样好吗?这样不好,为什么,因为我们的场景是模型训练,每轮训练的时候要 shuffle 的嘛。
一旦提前对数据做分割,那么每轮训练的过程中的每个 dataloader 看到的数据就一样了,泛化性要受影响。
那我们怎么做呢?
最好还是所有 dataloader 一起看同一组数据,就像是本来人手一本书,现在都给我看大屏幕。
这个大屏幕用什么合适呢,能单进程写、无限进程读的 数据库 就不错。
借助数据库的方法:将数据写入数据库中,为每个数据设定编号key,dataloader 读数据的时候根据下标读取
这么一来,数据从内存块变成了数据库。
每个 dataloader 的取第 i 个样本的操作从在内存里取下标 datasets[i] 变成了
select data from samples where sid = '{}'.format(i)
看到这里,有聪明的就要问了,我内存取值不比你数据库查询快?
哎?还真不一定噢,比单个速度不行,但胜在人多取胜,
实际上,4 worker 的内存取值速度是不如 16 worker 的数据库取值速度。
于此同时,对于一个 50M samples 的数据集:
带有 6 GPU x 4 memory worker 的模型需要 200G 内存
而带有 6 GPU x 32 sqlite worker 的同模型只需要 4G 内存
高下立判。
本文中我们选用的是 Python 中比较好操作的 SQLite3 库来操作 SQLite。
0x02 难点介绍
我们简单实现了一个版本(旧版本就不放出了防止误导),发现存在一个问题:
当进程数过多的时候,会出现 database dist image is malformed 的报错
当时多番尝试无果,四处求援的我:
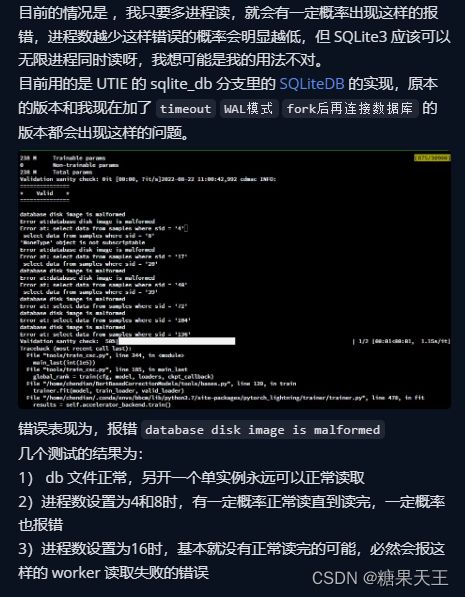
感谢 @caoyixuan1993 帮忙提供了建设性的意见:
Problem was due to connection to database was opened before fork().
Many processes used one connection. Now it’s opened after fork() and everything is ok.
—— StackOverflow
考虑到 fork 的特殊性,我们在初始化数据集的时候不能提前预设好数据库连接 conn 和数据库游标 cursor。
dataloader 在 fork 后的操作通常是 __get_item__,我们将 fork 后的第一次取值作为触发点,
此时为 fork 后的每个 dataloader 实例才建立起和数据库之间的连接 conn 和游标 cursor。
大功告成~
0x03 单文件源码实现
为了便于以后直接开箱可用,做一个单文件无依赖版的实现吧 =w=
性能:55M samples,db 大小是纯文本存储的样本文件大小的 1.2 倍,内存消耗减低为 2% 左右,速度提升约为 33%。
# coding=utf8
from __future__ import unicode_literals
from six import iteritems
import os
import time
import sqlite3
from tqdm import tqdm
from threading import Thread
import sys
PY2 = int(sys.version[0]) == 2
if PY2:
text_type = unicode # noqa
binary_type = str
string_types = (str, unicode) # noqa
unicode = unicode # noqa
basestring = basestring # noqa
else:
text_type = str
binary_type = bytes
string_types = (str,)
unicode = str
basestring = (str, bytes)
import json
import sqlite3
import numpy as np
def random_ints(n):
"""return n random ints that are distinct"""
assert n < 10**9, 'Too many distinct numbers asked.'
row_randoms = np.random.randint(0, np.iinfo(np.int64).max, 2*n)
uniques = np.unique(row_randoms)
while len(uniques) < n:
r = np.random.randint(0, np.iinfo(np.int64).max, 2*n)
uniques = np.unique(np.stack([uniques, r]))
return uniques[:n]
class TrainDBBase(object):
"""
An immutable dataset once write.
"""
def add_sindex(self, labels):
indexes = random_ints(len(labels))
for i, l in enumerate(labels):
l['info']['sindex'] = indexes[i]
self.sindex_to_sid_dict = {s['info']['sindex']: s['info']['sid'] for s in labels}
return labels
def write(self, samples):
"""save samples"""
raise NotImplementedError()
def get_by_sid(self, sid):
"""get sample by sid"""
raise NotImplementedError()
def sindex_to_sid(self, sindex):
""" return sid given sindex"""
raise NotImplementedError()
def __getitem__(self, item):
""" get sample by index in dataset"""
raise NotImplementedError()
def __len__(self):
"""return the number of samples in this dataset"""
raise NotImplementedError()
def __iter__(self):
self.n = 0
return self
def next(self):
if self.n == self.__len__():
raise StopIteration
n = self.n
self.n += 1
return self[n]
def __next__(self):
return self.next()
@property
def all_samples(self):
"""return all samples in this dataset"""
return [self[i] for i in range(len(self))]
class SQLiteDB(TrainDBBase):
def __init__(self, db_path, n_samples=None, read_only=True, load_now=False):
self.samples = None
self.n_samples = n_samples
self.sids = None
self.sid_to_sample = None
self.db_path = db_path
self.sindexes = None
self.sindex_to_sid_dict =None
self.sid_to_sindex_dict =None
self.conn = None
self.cursor = None
self.saved_length = None
self.pure_text_samples = True # True for CSC tasks.
if load_now:
self.get_cursor()
self.load_sid_sindex()
self.cursor.close()
self.conn = None
self.cursor = None
def get_cursor(self):
if self.cursor is not None:
return
conn = sqlite3.connect( # WAL mode for multi-processing
self.db_path,
isolation_level=None, # https://www.cnblogs.com/Gaimo/p/16098045.html
check_same_thread=False, # https://codeantenna.com/a/VNKPkxjiFx
timeout=3)
conn.row_factory = sqlite3.Row
self.conn = conn
self.cursor = conn.cursor()
# WAL mode for multi-processing
self.cursor.execute('PRAGMA journal_mode=wal') # https://www.coder.work/article/2441365
self.cursor.execute('PRAGMA synchronous=OFF') #
def remove_file(self):
import os
os.remove(self.db_path)
def write(self, samples):
self.get_cursor()
# if os.path.exists(self.db_path):
# logging.warn('removing the existing dataset')
# os.remove(self.db_path)
# create table
self.cursor.execute(
'CREATE TABLE samples (sid TEXT PRIMARY KEY NOT NULL, data TEXT, sindex INT)')
self.conn.commit()
# execute
if self.pure_text_samples:
for i, s in tqdm(enumerate(samples)):
sid = unicode(f'{i}')
s = unicode(s.strip().replace("'", "''"))
try:
self.cursor.execute(
"insert into samples(sid, data, sindex) values ('{}', '{}', {})".format(sid, s, i))
# error:
# sqlite3.DatabaseError: database disk image is malformed
# https://blog.csdn.net/The_Time_Runner/article/details/106590571
except Exception as e:
print(e)
print(sid)
print(s)
print(i)
else:
# pre-processing
for s in tqdm(samples):
s['info']['sid'] = unicode(s['info']['sid'])
sample_dict = {s['info']['sid']: json.dumps(s) for s in samples}
i = 0
for sid, s in tqdm(iteritems(sample_dict)):
self.cursor.execute(
"insert into samples(sid, data, sindex) values ('{}', '{}', {})".format(sid, s, i))
i += 1
self.conn.commit()
def get_by_sid(self, sid):
self.load_sid_sindex()
sql = "select data from samples where sid = '{}' ".format(sid)
try:
ret = self.cursor.execute(sql).fetchone()[0]
# ret = self.cursor.execute(sql).fetchall()[0][0]
except Exception as e:
print(f"{e}\nError at:", sql)
raise ValueError()
if self.pure_text_samples:
sample = ret
else:
sample = json.loads(ret)
sample['info']['sindex'] = self.sid_to_sindex_dict[sid]
# time.sleep(0.05)
return sample
def load_sid_sindex(self):
if self.sids is not None:
return
self.get_cursor()
sid_sindex = self.cursor.execute(
"select sid, sindex from samples").fetchall()
if self.n_samples:
sid_sindex = sid_sindex[: self.n_samples]
self.sids, self.sindexes = zip(*sid_sindex)
assert len(set(self.sids)) == len(self.sids)
assert len(set(self.sindexes)) == len(self.sindexes)
# logging.warn(json.dumps(self.sindexes))
# logging.warn(json.dumps(self.sids))
self.sid_to_sindex_dict = {sid: sindex for sid, sindex in sid_sindex}
self.sindex_to_sid_dict = {sindex: sid for sid, sindex in sid_sindex}
# logging.warning(f"loaded {len(self.sids)} samples.")
self.saved_length = len(self.sids)
def sindex_to_sid(self, sindex):
self.get_cursor()
self.load_sid_sindex()
return self.sindex_to_sid_dict[sindex]
def __getitem__(self, item):
self.get_cursor()
self.load_sid_sindex()
sid = self.sids[item]
return self.get_by_sid(sid)
def __len__(self):
return self.saved_length
def write_existed_samples(txt_path, db_path):
db = SQLiteDB(db_path, load_now=False)
db.remove_file()
samples = open(txt_path, 'r')
db.write(samples)
def single_thread_load_samples(_id, dataset):
print(f"init {_id}-th subprocess.")
total_length = 0
for i in range(1000):
res = dataset[i]
total_length += res.__len__()
# print("Loaded {} charaters.".format(total_length))
def test_multiprocessing(dataset):
import multiprocessing
print('Run the main process (%s).' % (os.getpid()))
i = 0
n_cores = 32
for i in range(n_cores):
p = multiprocessing.Process(
target=single_thread_load_samples,
args=(i, dataset))
p.start()
print('Waiting for all subprocesses done ...')
if __name__ == "__main__":
import time
start_time = time.time()
test_path = '/data/chendian/cleaned_findoc_samples/autodoc_test.220424.txt'
test_db_path = '/data/chendian/cleaned_findoc_samples/autodoc_test.220424.db'
# write_existed_samples(test_path, test_db_path)
dataset = SQLiteDB(
test_db_path,
load_now=True)
print("Init SQLite Ends.", time.time() - start_time)
print("The first sample is:", dataset[0])
# test_multiprocessing(dataset)