如何理解第三范式?
参考视频:https://www.bilibili.com/video/av17299750?from=search&seid=12104319042651596413
范式简介
数据库范式分为第一范式(1NF),第二范式(2NF),第三范式(3NF),BCNF,4NF,5NF,一般设计数据库结构的时候最多只要满足BCNF就可以了。
第一范式
数据表中的所有字段都是不可分割的原子值,符合1NF关系中的每个属性不可以再分。通俗讲就是能拆分的属性(字段)的尽量都拆分。
例如:
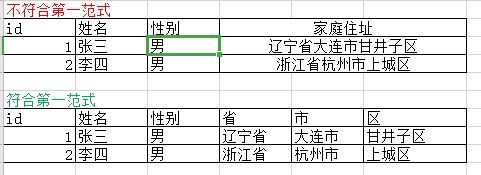
如果以后增加需求,需要对人员进行省,市,区进行分类查询,显然不拆分的表统计起来很麻烦。
注意:
-- 字段值还可以继续拆分的,就不满足第一范式。
-- 范式,设计的越详细,对于某些实际操作可能越好,但是不一定都是好处。
-- 通俗讲就是:一个字段只存储一项信息。
第二范式
在第一范式的基础上,消除了非主属性对于码的部分函数依赖。通俗讲就是任意一个字段都只依赖表中的同一个字段 。
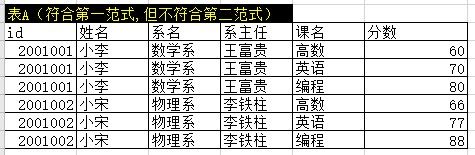

在解释第二范式前,需要先了解几个概念(注:以下概念解释部分含有个人理解,非官方概念,欢迎指正):
1.元组:表中的一行就是一个元组。
2.码:一个表中,可以唯一决定一个元组的属性"集合"。假设k为表中的某个属性,在k确定的情况下,这个表中的其他属性都可以确定,那么k就叫做候选码,也叫码。
例如:表A中通过id可以获取到姓名,系名,系主任名,但不确定课名和分数,而通过课名可以确定分数,所以id和课名就是码。
id --- 姓名,系名,系主任
课名 --- 分数
(id,课名)这个属性组就叫做码。
3.主属性:码里面的属性就是主属性。表A中(id,课名)是主属性。
4.非主属性:除主属性外的就是非主属性,表A中(姓名,系名,系主任,分数)是非主属性。
5.函数依赖:函数y=f(x),表示给定一个x值,可以确定y值,那么就说y函数依赖于x,写作x--y。
表A中id确定,可以得到这个学生的姓名,那么说姓名函数依赖于id。
表中的函数依赖:id--姓名 id--系名 id--系主任 (id,课名)--分数
6.完全函数依赖:y中含有(a,b)这两个属性,通过y可以确定c,单独通过a或b无法确定c,我们称c对于y是完全函数依赖。
7.部分函数依赖:y中含有(a,b)这两个元素,但是通过a可以确定f,通过b是无法确定f的,这时我们称f对y的部分函数依赖。
2NF判断方式:看数据表中是否存在非主属性对于码的部分函数依赖.不存在,则符合2NF要求。
-- 第一步:找出数据表A中的码。(id,课名)
-- 第二步:根据第一步所得到的码,找到所有的主属性。(id,课名)
-- 第三步:数据表中,除去所有主属性,剩下的就是非主属性.(姓名,系名,系主任,分数)
-- 第四步:查看是否存在非主属性对于码的部分函数依赖.不存在,则符合。
-- 表中的姓名,系名,系主任根据id就可以确定,但是根据课名无法确定,所以姓名,系名,系主任对于表中的码(id,课名)
是部分函数依赖,即不满足2NF。
这时,可以把表A拆分成表B和表C,就满足2NF了。
2NF缺点:插入异常,例如,在表A中如果要新建一个系,并且有系主任.但是因为还没有学生来学习,所以主键是空的,肯定也不能插入。
第三范式
在2NF的基础上,消除了非主属性对于码的传递函数依赖。即,如果存在非主属性对于码的传递函数依赖,则不符合3NF。
传递函数依赖:z=f(y),y=f(x),即z依赖y,y依赖x,这时z也可以说依赖于x,那么z传递函数依赖于x。
表C中系主任依赖于系名,系名依赖于id,系主任传递函数依赖于id,所以不满足3NF。
这时,把表C拆分成下图中的表,就满足3NF了。

在设计表结构时,不是说一定要满足三范式,需要根据自身业务需求进行设计。有些时候,满足三范式会降低表操作的效率,增加sql语句的难度。以上就是本人对1NF,2NF,3NF的理解了,希望对大家理解范式有帮助。