vite 预编译实现
直入正题,前段时间, vite 做了一个优化 – 依赖预编译。本文就来逐步分析预编译的逻辑和代码实现。
那什么是依赖预编译呢?这一过程简而言之,就是在 DevServer 启动前对须编译的依赖,进行预先编译,而后在模块使用导入(import)时,会直接引用预编译过的依赖。
我们先来看张图,梳理一下整体的预编译逻辑。在 DevServer 启动前,在模块使用导入(import)时,vite 会解析该依赖是否有缓存,如果存在,则判断缓存是否失效,若失效则加入预编译列表;如未失效则利用 node_modules/.vite 目录下对应编译后的依赖;如果不存在,为首次预编译,则加入预编译列表中,等所有预编译依赖收集完成后进行预编译。
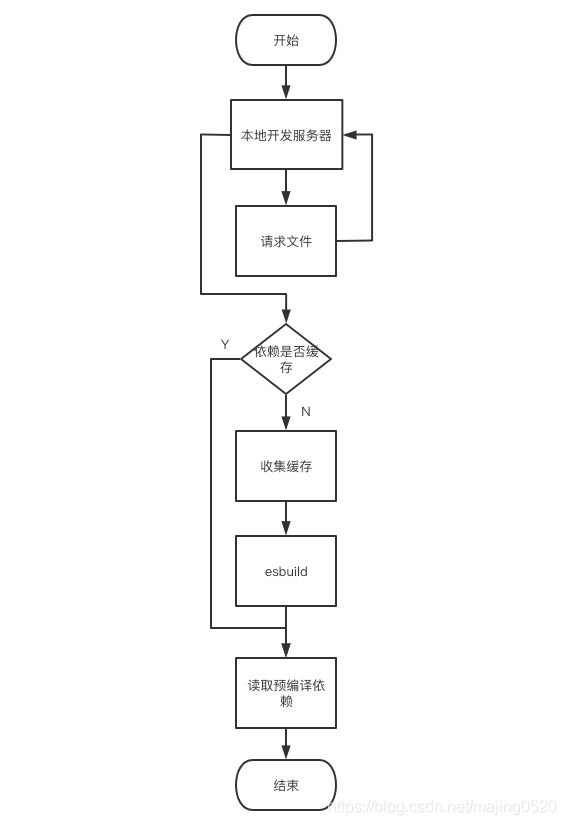
接下来我们分块梳理。
1. createServer
首先,vite 会创建一个本地开发服务器,这个过程由 createServer 函数完成。
监听端口,执行其他服务之前,会执行 optimizeDeps 方法,即优化依赖。vite 将这部分优化叫做依赖预打包 Dependency Pre-Bundling,这么做的理由有两个:一是将非 ES module转化为可被浏览器导入的 ESM;二是将 ESM 依赖的多个内部模块转化为一个模块,以减少浏览器请求从而提升页面加载速度。
createServer 方法中包含初了始化配置,HMR,预打包 等功能。我们重点关注预打包代码。
createServer 函数:
export async function createServer(
inlineConfig: inlineConfig = {}
): Promise<ViteDevServer> {
...
if (!middlewareMode && httpServer) {
// 重写 DevServer 的 listen,保证在 DevServer 启动前进行依赖预编译
const listen = httpServer.listen.bind(httpServer)
httpServer.listen = (async (port: number, ...args: any[]) => {
try {
...
// 依赖预编译
await runOptimize()
}
...
}) as any
...
} else {
await runOptimize()
}
...
}
createServer 代码里可以看到,在服务器启动前,会先调用 runOptimize 函数,来处理依赖预编译相关的逻辑。
2. runOptimize
一起看看 runOptimize 函数:
const runOptimize = async () => {
// config.optimzizeCacheDir 指的是 node_modules/.vite 文件下的内容,用来存放预编译的文件
if (config.optimizeCacheDir) {
...
try {
// 进行依赖预编译
server._optimizeDepsMetadata = await optimizeDeps(config)
}
...
//注册依赖预编译
server._registerMissingImport = createMissingImpoterRegisterFn(server)
}
}
通过代码知道,runOptimize 函数主要做两件事:
-
执行依赖的预编译方法
-
注册新依赖的预编译
2.1 依赖预编译
runOptimize 告诉我们,执行预编译的核心函数由 optimizeDeps 方法完成。
optimizeDeps 的实现在第三章具体分析,这里先整体表述 optimizeDeps 逻辑。 optimizeDeps 会根据配置文件 vite.config.js 的 optimizeDeps 对象内容和 package.json 的 dependencies 进行第一次预编译;对于没有配置的依赖,vite 会先解析 AST 语法树里面使用到的依赖,再将该依赖进行预编译。
预编译结束后,在 node_moduels/.vite 文件下生成一份 _metadata.json 对象文件,主要用来存储预编译依赖的详细信息。如下图:

里面每个属性的含义:
- hash 获取该文件此时 hash,主要利用文件签名以及 config 属性是否改变来判断,是否须要从新编译;
- browserHash 由 hash 和在运行时发现的额定的依赖生成的,主要用于优化请求数量,避免太多的请求影响性能;
- optimized 包含每个进行过预编译的依赖,其对应的属性会描述依赖源文件路径 src 和编译后所在路径 file;
- needsInterop 主要用于在 vite 进行依赖性导入分析,它会重写需要预编译且为 commonJS 的依赖。例如:
import { debounce } from 'lodash';
// 重写为
import $viteCjsImport1_lodash from "/@modules/lodash.js";
const Lodash = $viteCjsImport1_lodash;
const debounce = $viteCjsImport1_lodash["debounce"];
2.2 注册依赖预编译
runOptimize 告诉我们,注册依赖预编译调用 createMissingImporterRegisterFn 函数实现,主要是注册新的依赖预编译。
createMissingImporterRegisterFn 函数:
//在触发前等待新依赖项的请求数量
export function createMissingImporterRegisterFn(server: ViteDevServer){
...
async function rerun(){
...
try{
server._isRunningOptimizer = true;
server._optimizeDepsMetadata = null;
const newData = (server._optimizeDepsMetadata = await optimizeDeps(
server.config,
true,
false,
newDeps
))
}
...
}
return function registerMissingImport(id:string, resolved: string){
...
handle = setTimeout(rerun,100);
...
}
...
}
它会返回一个函数,函数内部调用 optimizeDeps 函数进行预编译。与第一次预编译不同的是,新预编译会传入一个 newDeps,即新的需要预编译的依赖。
通过对 runOptimize 里执行依赖的预编译方法和注册依赖预编译代码的梳理,看到均由 optimizeDeps 函数来实现依赖预编译。接下来,划重点 optimizeDeps。
3. optimizeDeps
optimizeDeps 是预编译的核心内容,由于内部逻辑比较复杂,我们拆分为三大步,依赖是否失效 -> 收集依赖 -> esbuild 打包。具体的逻辑如下图所示。
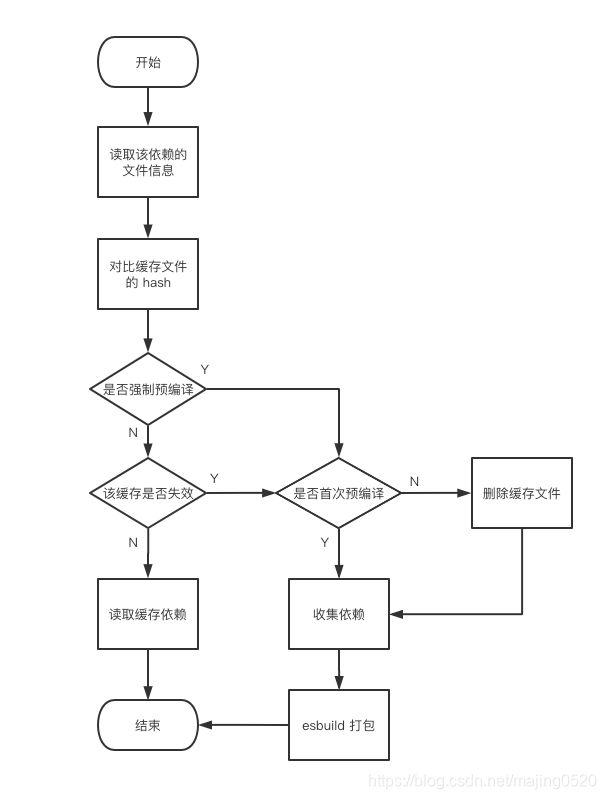
3.1 依赖是否生效
在代码里依赖失效与否,主要通过文件内容对应的 hash 值来判断,以便于判断依赖是否失效以及依赖发生变化时,能够重新编译,应用最新的编译文件。
第一步,需要读取缓存的文件信息。
3.1.1 读取 hash
每次编译都需要读取该依赖的当前文件信息,调用 getDepHash 方法,拿到对应的 hash 值。
具体代码如下:
// 获取该文件此时的 hash
const mainHash = getDepHash(root, config)
const data: DepOptimizationMetadata = {
hash: mainHash,
browserHash: mainHash,
optimized: {}
}
第二步,判断 hash 值是否失效。
3.1.2 对比 hash
对比当前文件的 hash 和 _metadata.json文件的 hash 是否一致,如果一致,则缓存未失效,直接返回上次依赖缓存的信息,optimizeDeps 方法也至此结束;如果不一致,则缓存失效,需要重新进行预编译。
具体代码如下:
const { root, optimizeCacheDir: cacheDir } = config
const dataPath = path.join(cacheDir, '_metadata.json')
// 当没有使用 --force 命令,没有要求强制重新打包
if (!force) {
let prevData
try {
// 获取到此时缓存中编译的文件信息
prevData = JSON.parse(fs.readFileSync(dataPath, 'utf-8'))
} catch (e) {}
// hash 一致时无需重新编译
if (prevData && prevData.hash === data.hash) {
log('Hash is consistent. Skipping. Use --force to override.')
//如果新旧依赖的 Hash 值相等的时候,则返回旧的依赖内容
return prevData
}
}
第三步,缓存失效或不存在,需要重新预编译。
3.1.3 缓存失效或不存在
如果缓存失效,则删除缓存文件夹即 node_modules/.vite ;还有一种情况,缓存文件不存在,即第一次进行预编译,需新建缓存文件夹。
先来看判断缓存是否失效代码:
const { root, optimizeCacheDir: cacheDir } = config
// 判断缓存是否失效
// cacheDir 即 node_modules/.vite
if (fs.existsSync(cacheDir)) {
// 失效则删除缓存文件夹
emptyDir(cacheDir)
} else {
// 首次进行依赖预编译(缓存文件夹不存在),需创建 cacheDir 文件夹
fs.mkdirSync(cacheDir, { recursive: true })
}
当然了,更新缓存后,需要及时地更新 hash。
//更新 browser hash
data.browserHash = createHash('sha256')
.update(data.hash + JSON.stringify(deps))
.digest('hex')
.substr(0, 8)
3.2 收集依赖
在上述判断缓存失效后,就需要收集依赖。主要为两大类依赖,编译依赖和指定依赖。
3.2.1 收集编译依赖
依赖收集情况分为两种:首次预编译和后续更新依赖。这两者的区别在于,后续更新会传入一个 newDep 来表示需预编译模块。代码如下:
let deps: Record<string, string>, missing: Record<string, string>
if (!newDeps) {
// 首次预编译
;({ missing,deps } = await scanImports(config))
} else {
// 后续更新依赖
// 直接将需要更新的依赖赋给 deps,此时不存在 missing 依赖
deps = newDeps
missing = {}
}
通过代码知道,如果是第一次预编译,则会调用 scanImports 函数来找出需要预编译的依赖 deps 和 missing。
missing 为引入但不能成功解析的模块,即在 node_modules 中没找到的依赖;deps 是一个对象,主要用来存储模块路径,结构如下:
{
lodash:'/Users/user/Documents/user/code/vite/vite-project/node_modules/lodash/lodash.js'
}
3.1.2 收集指定依赖
预编译的依赖除了 import 引入也会由 vite.config.js 的 optimizeDeps 选项指定以来。所以在处理完 import 的依赖后,需要处理 optimizeDeps 配置的依赖。
此时,会遍历、从 dependencies 获取到的 deps,判断 optimizeDeps.iclude(数组)所指定的依赖是否存在,若存在就省去此次制定编译;若不存在,则加入强制执行编译依赖中。
// 拿到 vite.config.js 的 optimizeDeps
const include = config.optimizeDeps?.include
if (include) {
// 解析依赖
const resolve = config.createResolver({ asSrc: false })
for (const id of include) {
// 制定依赖是否存在 deps 中
if (!deps[id]) {
const entry = await resolve(id)
if (entry) {
deps[id] = entry
} else {
throw new Error(
`Failed to resolve force included dependency: ${chalk.cyan(id)}`
)
}
}
}
}
3.3 ESbuild 打包
在确认需要预构建的依赖后,就到了最后一步,使用 esbuild 对依赖进行编译打包。代码如下:
const esbuildService = await ensureService()
await esbuildService.build({
entryPoints: Object.keys(flatIdDeps),
bundle: true,
format: 'esm',
...
})
ensureService 函数是 vite 外部封装的 util,ensureService 实质是创立一个 esbuild 的 service,应用 service.build 函数来实现编译过程。
flatIdDeps 参数是一个对象,它是由上述的 deps 收集好的依赖创立,它的作用是为 esbuild 进行编译的时候提供多路口,flatIdDeps 对象:
{
lodash-es:'/Users/user/Documents/FE/demos/vite2.0-demo/node_modules/lodash-es/lodash.js'
}
至此,我们分析了 vite 的预编译逻辑和代码实现。vite 通过对依赖进行预编译和预编译缓存,防止重复预编译,可以减少不必要的等待项目重启或模块更新时间,从而缩短冷启动,使得开发人员拥有更良好的开发体验,加快开发进度。