AI全栈大模型工程师(二)课程大纲
文章目录
-
- 这节课会带给你
- 一、解读本课大纲
-
- 1.1、我们的初心
- 1.2、大纲解读
- 1.3、定自己的目标
- 1.4、FAQ
- 用好 AI 需要很多数学知识吗?
- 有的知识太深,我理解不了怎么办
- 感觉讲的太浅了,没学到知识怎么办
- 课听懂了,实际工作中还是不会用怎么办
- 二、什么是 AI?
- 三、ChatGPT 能干什么?
-
- 3.1、既然是通用 AI,我怎么用它解决业务问题?
- 案例:从文字中识别快递地址、收件人、电话
- 更多举例
- 3.2、从 AI 的视角,怎么定义我遇到的业务问题
- 业务问题分类
-
- **分类问题**
- **聚类问题**
- **回归问题**
- **决策问题**
- **概率密度估计**
- 复杂问题的两个视角
- 四、以上问题,ChatGPT能解决哪些,不能解决哪些?
-
- 4.1、分类问题
- 4.2、聚类问题
- 4.3、回归问题
- 4.4、决策问题
- 4.5、但它很擅长任务规划
- 4.6、遇到 ChatGPT 解决不了的问题怎么办?
- 五、它是怎么生成结果的?
-
- 5.1、大语言模型(LLM):GPT,Transformer
- 六、OpenAI API初探
-
- 6.1、安装Python库
- 6.2、查看可调用的模型
- 6.3、发一条消息
- 彩蛋
- 作业
- 后记
这节课会带给你
- 通俗了解大模型的工作原理,秒赢 99% 其他人的认知
- 了解指令工程的强大,不只是「说人话」那么简单
- 浅尝 OpenAI API 的调用
开始上课!
一、解读本课大纲
- 课程大纲的设计初心
- 每部分能给你带来什么
- 做自己的选择,定自己的目标
1.1、我们的初心
我们相信,懂 AI、懂编程、懂业务的超级个体,会是 AGI 时代最重要的人。所以我们提出了「AI 全栈工程师」这个概念,让它显得不那么浮夸。
这门课的目标,就是培养「AI 全栈」。
当然,「全栈」涉及的知识面非常广,我们这区区一门课不可能全部涉及。我们能做到的是,在各个方向上都为大家打开一扇门,带大家入门。想走得更深更远,要靠大家自己,和我们的社群。
但是,「入门」并不代表简单、肤浅。我们的课程会在三个层次发力:
- 原理
- 实践
- 认知
不懂原理就不会举一反三,走不了太远。
不懂实践就只能纸上谈兵,做事不落地。
认知不高就无法做对决策,天花板太低。
1.2、大纲解读
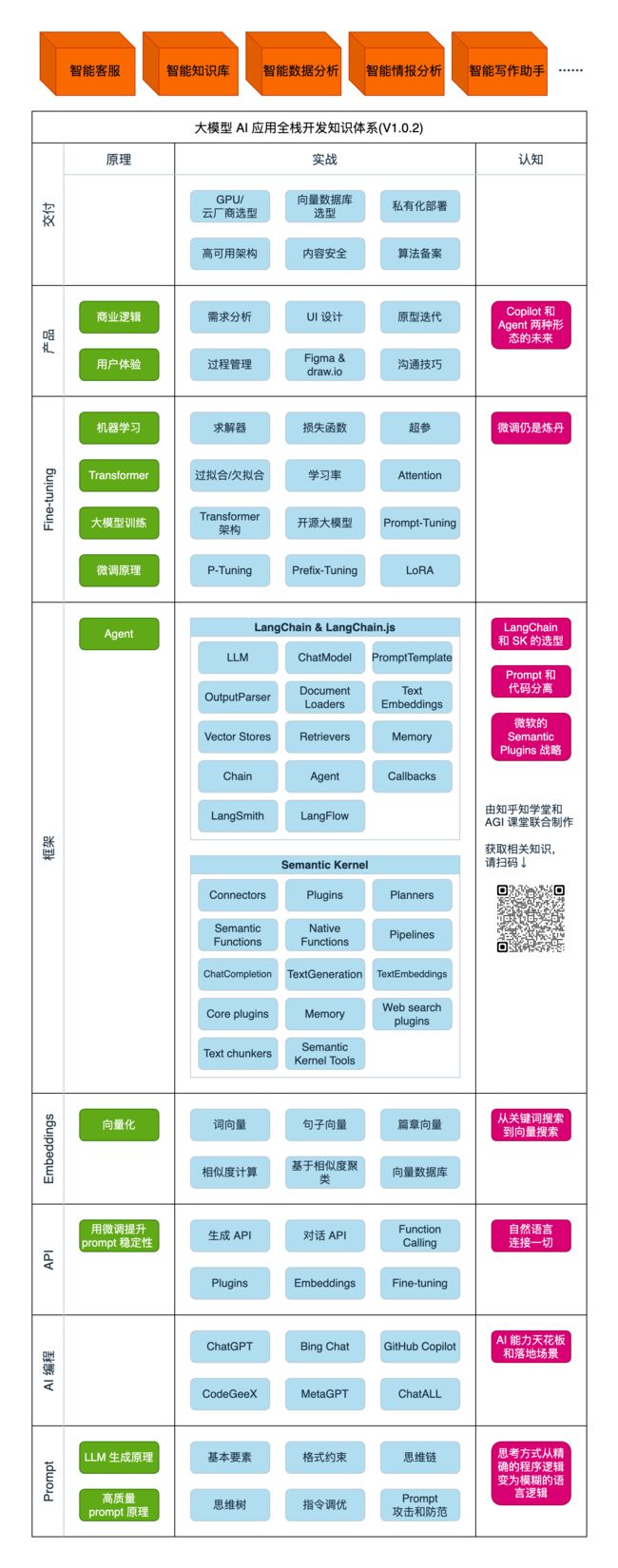
| 模块 | 目的 | 原理 | 实践 | 认知 |
|---|---|---|---|---|
| AI 大模型基础介绍 | 对大模型有直观的、基础的了解,以展开后续课程学习 | 大模型最基础的原理 | 搞定环境搭建和工具的使用 | 大模型并不神奇,也不神秘 |
| Prompt Engineering | 操纵大模型的基础方法 | 让 prompt 更大概率生效的原理 | 使用 prompt 和调用 OpenAI API | 程序思维从确定性到模糊性的变化 |
| Function Calling & Plugins | Prompt 和编程结合的当前最高级手段 | Fine-tuning 比 prompt 更稳定 | 使用 Function Calling 解决问题 | 人机接口和机器接口的演化方向 |
| AI 编程 | 学会用 AI 辅助编程,助力接下来的学习 | AI 编程也是 prompt engineering | 使用 AI 编程解决问题 | 从 AI 编程看提示工程和 AI 能力的天花板 |
| LangChain | 用 LangChain 开发大模型应用 | 什么是 embeddings | 使用 LangChain 开发应用 | 各种大模型应用的技术套路 |
| Semantic Kernel | LangChain 之外的另一个选择 | - | 使用 Semantic Kernel 开发应用 | Prompt 和代码分离的思想 |
| Fine-tuning | 学会大模型应用技术的天花板 | 机器学习基础 | 训练出自己的独特大模型 | 大模型、GPU 选型 |
| AI 产品设计 | 独立完成 AI 产品设计,成为 AI 全栈 | 商业、美学、用户体验的基本原理 | 设计商业模式,绘制原型图,快速做出 demo | 什么是好的产品。技术含量高不代表产品好 |
| 业务沟通锦囊 | 没有产品经理帮忙,也能直面业务同事 | 与人沟通的基本原理 | 高效收集需求和反馈 | 做得好,多数时候确实不如说得妙 |
| AI 绘画 | AI 绘画,陶冶情操 | 文生图的原理 | 使用 prompt 绘画 | - |
1.3、定自己的目标
在全栈的知识面上,一个人短期把三层全占满是不太可能的。
每个人要根据自己的特点、目标和机遇,选择自己的方向。
1.4、FAQ
用好 AI 需要很多数学知识吗?
- 以前真需要,以后可能不那么需要了
有的知识太深,我理解不了怎么办
- 「用到再讲、学以致用」是我们的教学理念。很多知识,用着用着就理解了
- 少部分基础数学知识主要在数据和模型训练部分,可以根据自身情况选择性理解。不理解,也不大影响使用
感觉讲的太浅了,没学到知识怎么办
- 我们尽量在每节课里都涉及一少部分有深度的知识
- 如果感觉不解渴,欢迎在互动环节积极提问,我们现场解答
课听懂了,实际工作中还是不会用怎么办
- NLP的实际问题通常不是端到端由一个算法解决的,我们把拆解问题的思路融入课程中,用心体会
- 既然花钱来上课了,问我!
- 本课毕竟全球首创,且 AI 领域日新周异高速迭代,必有大量不足之处
- 我们会不断改进,欢迎随时提出宝贵意见。
二、什么是 AI?

课程总监孙志岗老师曾和「深蓝」的创造者许峰雄博士 1v1 交流数小时。许说:「AI is bullshit。深蓝没用任何 AI 算法,就是硬件穷举棋步。」
三、ChatGPT 能干什么?
- 写文章
- 写邮件
- 出面试题
- 写代码
- 回答问题
- 陪聊天
- … …
我们来试试:https://chat.openai.com/
- 一定要有一个访问国外的「通道」,否则无法访问、实操本课大量资源。通道举例:Just My Socks
- 尽量找国外朋友帮忙认证 ChatGPT 手机号(一个手机号可以认证多次),不得已再从贩子手里买号
- 用 Bing Chat 也可以,邮箱注册就能用,且免费使用的模型就是宇宙最强的 GPT-4
3.1、既然是通用 AI,我怎么用它解决业务问题?
案例:从文字中识别快递地址、收件人、电话

代码都能写,写 JSON 当然不在话下!
更多举例
- **舆情分析:**从公司产品的评论中,分析哪些功能/元素是用户讨论最多的,评价是正向还是负向
- **坐席质检:**检查客服/销售人员与用户的对话记录,判断是否有争吵、辱骂、不当言论,话术是否符合标准
- **故障解释:**根据系统报错信息,给出方便非技术人员阅读的故障说明
- **零代码开发/运维:**自动规划任务,生成指令,自动执行
- **生成业务逻辑:**自定义一套业务描述语言(DSL),直接让ChatGPT写业务逻辑代码
3.2、从 AI 的视角,怎么定义我遇到的业务问题
首先,我们从三个角度来看待一个业务问题:
- **输人是什么:**文本、图像、语音信号…
- **输出是什么:**标签、数值、大段文字(包括代码、指令等)…
- 怎么量化衡量输出的对错/好坏?
业务问题分类
绝大多数业务问题,都可以归入如下至少一类。
分类问题
笼统的说,输出是标签。输出的标签是个有限集。输出的标签是预先定义好的有限集。
例如:分析一段评论是正向还是负向,是典型的分类问题。输出是两个标签之一:“正向”或“负向”。
更复杂的分类,比如,输入一篇新闻,输出是“政治”、“经济”、“体育”、“娱乐”、“科技”之一(或多个标签)。
聚类问题
没法提前规定有多少种标签,只能把同一类事物聚合在一起,到底能聚出多少类,是数据本身决定的。
例如:自动收集客户经常问到的问题。(我们无法预知客户有多少问题,只能把同一个意思的问题聚合在一起)
回归问题
输出是一个数值,更重要的是,评价输出好坏的标准是误差大小,而不是二元的对错。
举例:跟据专车司机每天工作的时段、时长、跑的公里数,预估他一天的净利润
决策问题
输出是连续的一系列动作,每一步动作都有代价或收益,每一步的动作本身没有对错,而是要最大化最终的收益
举例:打游戏、下棋、无人驾驶、对话、量化投资
概率密度估计
超纲了,本门课不讲。提一下就是为了严谨。
复杂问题的两个视角
- 信息抽取,实体识别,内容生成本质上都是分类问题
- 在 ChatGPT 时代,上述很多问题都可以从文本生成的角度解决
- 把 ChatGPT 看做是一个函数,给输入,生成输出
- 任何业务问题,都可以用语言描述,成为 ChatGPT 的输入,就能生成业务问题的结果
- 实际生成中,算法工程师通常需要根据业务know-how将上述基本问题串起来。理解问题本质,对拆解任务有很大帮助!
四、以上问题,ChatGPT能解决哪些,不能解决哪些?
试一下就知道了……
4.1、分类问题

✅成功
4.2、聚类问题

✅成功
4.3、回归问题

❌失败
4.4、决策问题

✅成功 or ❌失败?
4.5、但它很擅长任务规划
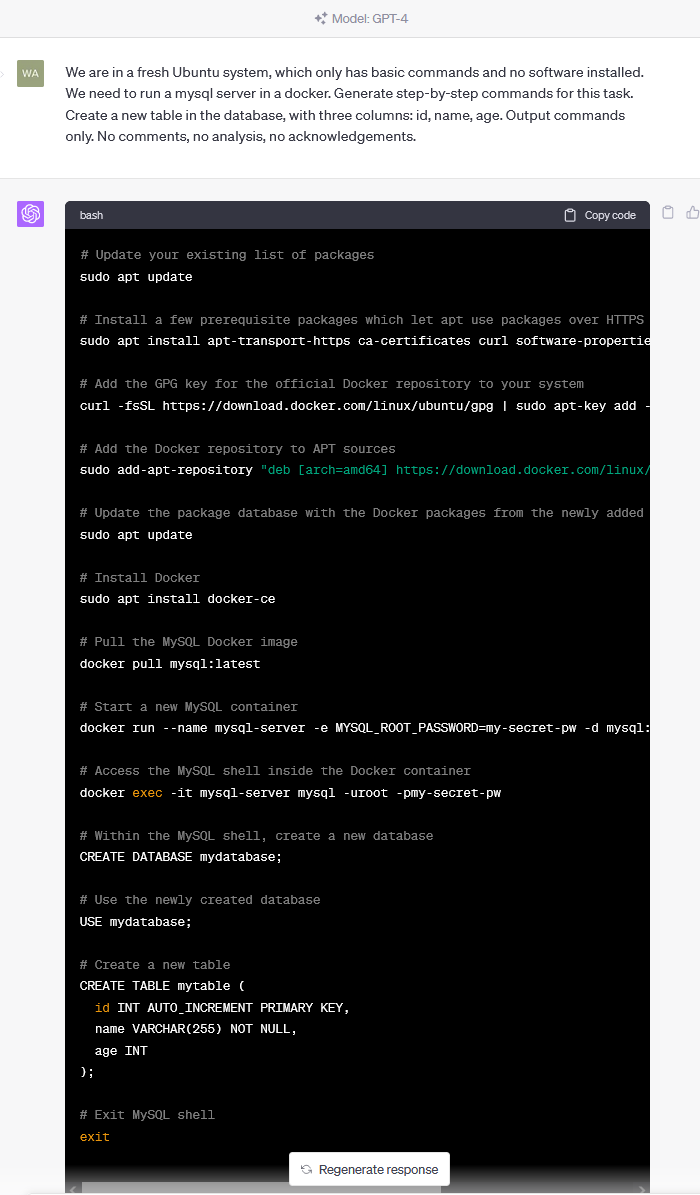
4.6、遇到 ChatGPT 解决不了的问题怎么办?
- 学好后面自己训练模型那几节课(有些深度)
- 真学会了,身价倍增,加油!
五、它是怎么生成结果的?
其实,它只是根据上文,猜下一个词(的概率)……

OpenAI 的接口名就叫「completion」,也证明了其只会「生成」的本质。
下面用程序演示「生成下一个字」。你可以自己修改 prompt 试试。还可以使用相同的 prompt 运行多次。
import openai
import os
import time
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
openai.api_key = os.getenv('OPENAI_API_KEY')
prompt='今天我很'
response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt,
max_tokens=40,
temperature=0,
stream=True
)
#print(response.choices[0].text)
for chunk in response:
print(chunk.choices[0].text, end='')
time.sleep(0.2)
- GPT「大模型」阅读了人类曾说过的所有的话。这就是「学习」
- 把一串词后面跟着的不同词的概率记下来。记下的就是「参数」,也叫「权重」
- 当我们给它若干词,GPT 就能算出概率最高的下一个词是什么。这就是「生成」
- 用生成的词,再加上上文,就能继续生成下一个词。以此类推,生成更多文字
5.1、大语言模型(LLM):GPT,Transformer
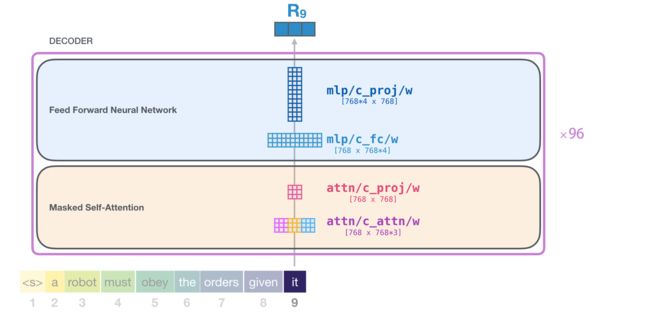
六、OpenAI API初探
6.1、安装Python库
pip install --upgrade openai
6.2、查看可调用的模型
import openai
import os
# 加载 .env 文件
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
# 从环境变量中获得你的 OpenAI Key
openai.api_key = os.getenv('OPENAI_API_KEY')
# 模型列表
models = openai.Model.list()
for model in models.data:
print(model.id)
6.3、发一条消息
# 消息格式
messages=[
{
"role": "system",
"content": "你是AI助手小瓜.你是AGIClass的助教。这门课每周二、四上课。"
},
{
"role": "user",
"content": "你是干什么的?什么时间上课"
},
]
# 调用ChatGPT-3.5
chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages)
# 输出回复
print(chat_completion.choices[0].message.content)
彩蛋
我们开发的大模型提效利器:ChatALL。某前端工程师用后表示:「1 小时的调试工作缩短到 5 分钟」。
作业
为保证后续课程能正常跟进,请完成如下作业:
- 能正常使用 ChatGPT 或 Bing Chat 至少之一
- 下载安装 ChatALL,通过它体验 ChatGPT 或/和 Bing Chat
- 在 GitHub 给 ChatALL 加个星星(此条自愿完成)
后记
博客主页:https://manor.blog.csdn.net
欢迎点赞 收藏 ⭐留言 如有错误敬请指正!
本文由 Maynor 原创,首发于 CSDN博客
不能老盯着手机屏幕,要不时地抬起头,看看老板的位置⭐
专栏持续更新,欢迎订阅:https://blog.csdn.net/xianyu120/category_12471942.html